当前位置:网站首页>golang中的WaitGroup实现原理
golang中的WaitGroup实现原理
2022-07-06 17:22:00 【raoxiaoya】
原理解析
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers only guarantee that 64-bit fields are 32-bit aligned.
// For this reason on 32 bit architectures we need to check in state()
// if state1 is aligned or not, and dynamically "swap" the field order if
// needed.
state1 uint64
state2 uint32
}
其中 noCopy 是 golang 源码中检测禁止拷贝的技术。如果程序中有 WaitGroup 的赋值行为,使用 go vet 检查程序时,就会发现有报错。但需要注意的是,noCopy 不会影响程序正常的编译和运行。
state1字段
- 高32位为counter,代表目前尚未完成的协程个数。
- 低32位为waiter,代表目前已调用
Wait的 goroutine 的个数,因为wait可以被多个协程调用。
state2为信号量。
WaitGroup 的整个调用过程可以简单地描述成下面这样:
- 当调用
WaitGroup.Add(n)时,counter 将会自增:counter + n - 当调用
WaitGroup.Wait()时,会将waiter++。同时调用runtime_Semacquire(semap), 增加信号量,并挂起当前 goroutine。 - 当调用
WaitGroup.Done()时,将会counter--。如果自减后的 counter 等于 0,说明 WaitGroup 的等待过程已经结束,则需要调用runtime_Semrelease释放信号量,唤醒正在WaitGroup.Wait的 goroutine。
关于内存对其
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if unsafe.Alignof(wg.state1) == 8 || uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// state1 is 64-bit aligned: nothing to do.
return &wg.state1, &wg.state2
} else {
// state1 is 32-bit aligned but not 64-bit aligned: this means that
// (&state1)+4 is 64-bit aligned.
state := (*[3]uint32)(unsafe.Pointer(&wg.state1))
return (*uint64)(unsafe.Pointer(&state[1])), &state[0]
}
}
如果变量是 64 位对齐 (8 byte), 则该变量的起始地址是 8 的倍数。如果变量是 32 位对齐 (4 byte),则该变量的起始地址是 4 的倍数。
当 state1 是 32 位的时候,那么state1被当成是一个数组[3]uint32,数组的第一位是semap,第二三位存储着counter, waiter正好是64位。
为什么会有这种奇怪的设定呢?这里涉及两个前提:
前提 1:在 WaitGroup 的真实逻辑中, counter 和 waiter 被合在了一起,当成一个 64 位的整数对外使用。当需要变化 counter 和 waiter 的值的时候,也是通过 atomic 来原子操作这个 64 位整数。
前提 2:在 32 位系统下,如果使用 atomic 对 64 位变量进行原子操作,调用者需要自行保证变量的 64 位对齐,否则将会出现异常。golang 的官方文档 sync/atomic/#pkg-note-BUG 原文是这么说的:
On ARM, x86-32, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
因此,在前提 1 的情况下,WaitGroup 需要对 64 位进行原子操作。根据前提 2,WaitGroup 需要自行保证 count+waiter 的 64 位对齐。
这个方法非常的巧妙,只不过是改变 semap 的位置顺序,就既可以保证 counter+waiter 一定会 64 位对齐,也可以保证内存的高效利用。
注: 有些文章会讲到,WaitGroup 两种不同的内存布局方式是 32 位系统和 64 位系统的区别,这其实不太严谨。准确的说法是 32 位对齐和 64 位对齐的区别。因为在 32 位系统下,state1 变量也有可能恰好符合 64 位对齐。
在sync.mutex的源码中就没有出现内存对其的操作,虽然它也有大量的atomic操作,那是因为state int32。
在sync.mutex中也是将四个状态存在一个变量地址,其实这么做的目的就是为了实现原子操作,因为没有办法同时修改多个变量还要保证原子性。
WaitGroup 直接把 counter 和 waiter 看成了一个统一的 64 位变量。其中 counter 是这个变量的高 32 位,waiter 是这个变量的低 32 位。 在需要改变 counter 时, 通过将累加值左移 32 位的方式。
这里的原子操作并没有使用Mutex或者RWMutex这样的锁,主要是因为锁会带来不小的性能损耗,存在上下文切换,而对于单个内存地址的原子操作最好的方式是atomic,因为这是由底层硬件提供的支持(CPU指令),粒度更小,性能更高。
源码部分
func (wg *WaitGroup) Add(delta int) {
// wg.state()返回的是地址
statep, semap := wg.state()
// 原子操作,修改statep高32位的值,即counter的值
state := atomic.AddUint64(statep, uint64(delta)<<32)
// 右移32位,使高32位变成了低32,得到counter的值
v := int32(state >> 32)
// 直接取低32位,得到waiter的值
w := uint32(state)
// 不规范的操作
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// 不规范的操作
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// 这是正常的情况
if v > 0 || w == 0 {
return
}
// 剩下的就是 counter == 0 且 waiter != 0 的情况
// 在这个情况下,*statep 的值就是 waiter 的值,否则就有问题
// 在这个情况下,所有的任务都已经完成,可以将 *statep 整个置0
// 同时向所有的Waiter释放信号量
// This goroutine has set counter to 0 when waiters > 0.
// Now there can't be concurrent mutations of state:
// - Adds must not happen concurrently with Wait,
// - Wait does not increment waiters if it sees counter == 0.
// Still do a cheap sanity check to detect WaitGroup misuse.
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
func (wg *WaitGroup) Wait() {
// wg.state()返回的是地址
statep, semap := wg.state()
// for循环是配合CAS操作
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // counter
w := uint32(state) // waiter
// 如果counter为0,说明所有的任务在调用Wait的时候就已经完成了,直接退出
// 这就要求,必须在同步的情况下调用Add(),否则Wait可能先退出了
if v == 0 {
return
}
// waiter++,原子操作
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 如果自增成功,则获取信号量,此处信号量起到了同步的作用
runtime_Semacquire(semap)
return
}
}
}
总结一下,WaitGroup 的原理就五个点:内存对齐,原子操作,counter,waiter,信号量。
内存对齐的作用是为了原子操作。
counter的增减使用原子操作,counter的作用是一旦为0就释放全部信号量。
waiter的自增使用原子操作,waiter的作用是表明要释放多少信号量。
边栏推荐
- Stm32f407 ------- SPI communication
- Tensorflow 1.14 specify GPU running settings
- Segmenttree
- pyflink的安装和测试
- paddlehub应用出现paddle包报错的问题
- 「精致店主理人」青年创业孵化营·首期顺德场圆满结束!
- Telerik UI 2022 R2 SP1 Retail-Not Crack
- Maidong Internet won the bid of Beijing life insurance to boost customers' brand value
- UI控件Telerik UI for WinForms新主题——VS2022启发式主题
- Attention SLAM:一种从人类注意中学习的视觉单目SLAM
猜你喜欢

Data processing of deep learning

Batch obtain the latitude coordinates of all administrative regions in China (to the county level)
![[牛客] [NOIP2015]跳石头](/img/9f/b48f3c504e511e79935a481b15045e.png)
[牛客] [NOIP2015]跳石头

C9高校,博士生一作发Nature!

New feature of Oracle 19C: automatic DML redirection of ADG, enhanced read-write separation -- ADG_ REDIRECT_ DML
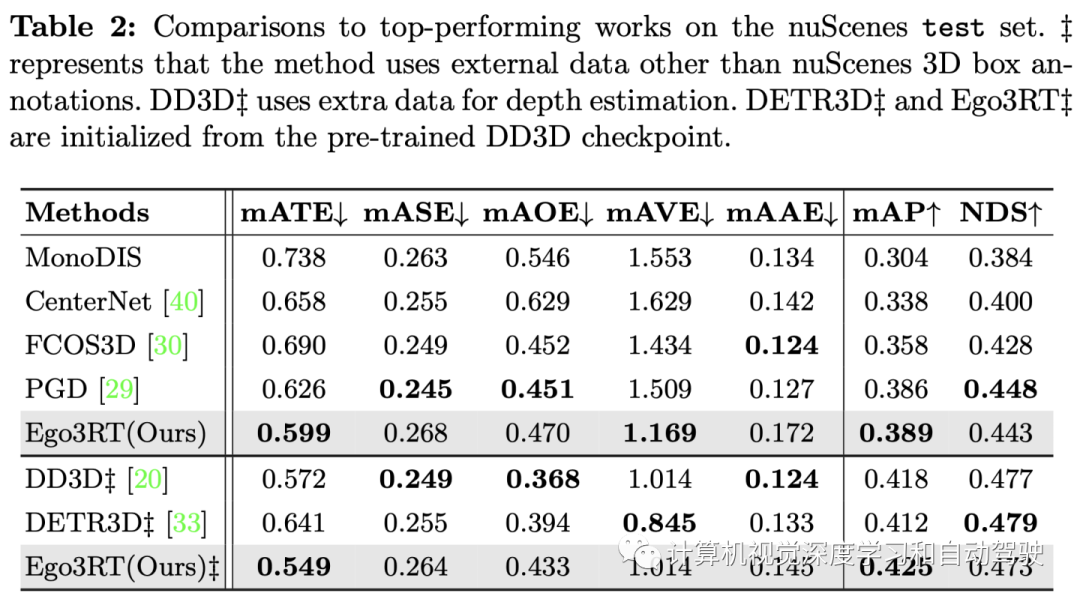
学习光线跟踪一样的自3D表征Ego3RT
第七篇,STM32串口通信编程
做微服务研发工程师的一年来的总结
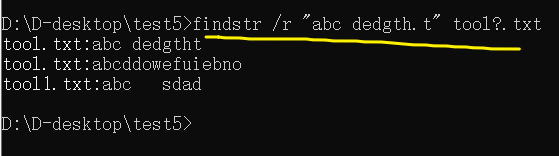
【批处理DOS-CMD命令-汇总和小结】-字符串搜索、查找、筛选命令(find、findstr),Find和findstr的区别和辨析
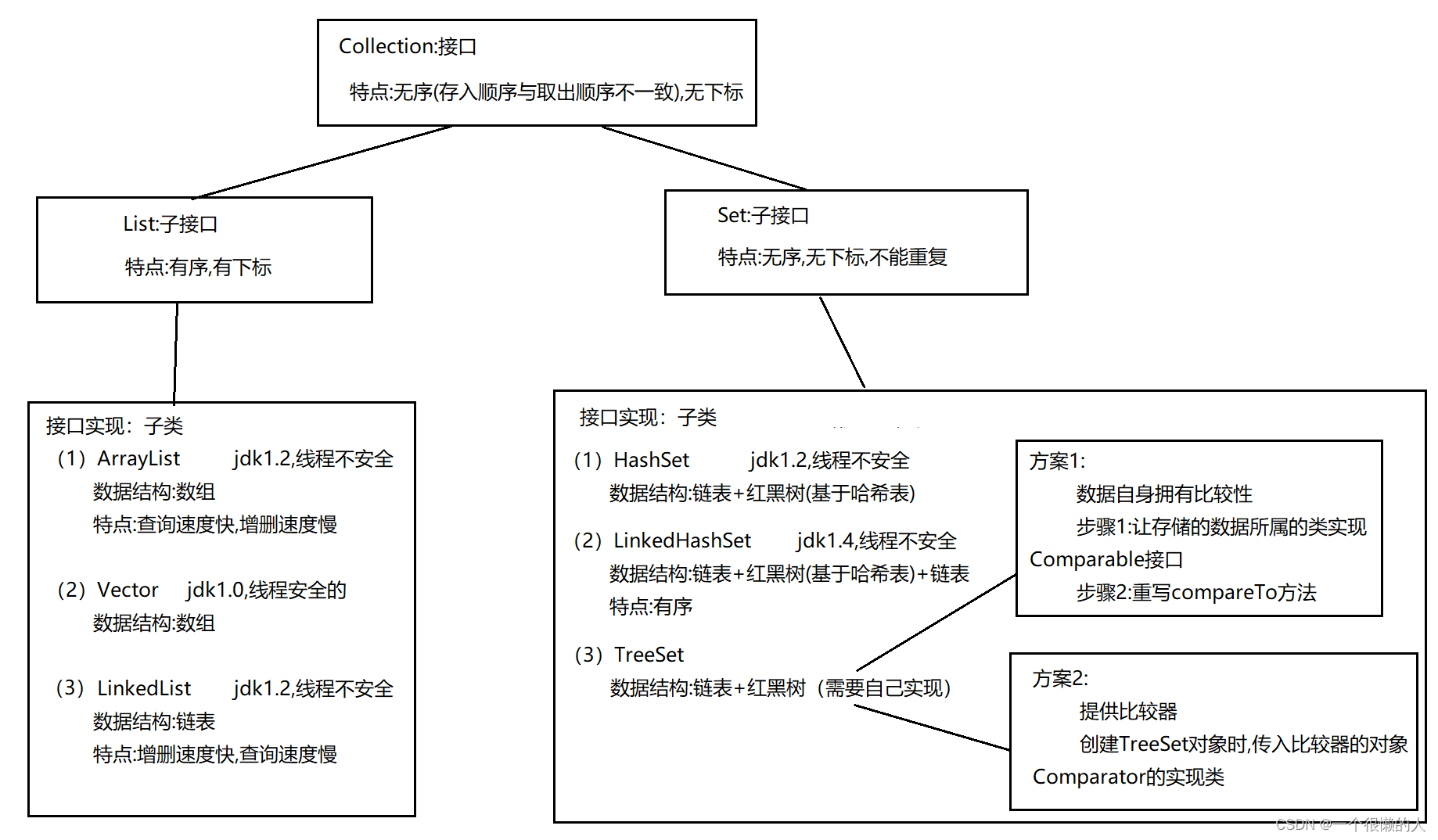
Set (generic & list & Set & custom sort)
随机推荐
There is an error in the paddehub application
windows安装mysql8(5分钟)
Explain in detail the matrix normalization function normalize() of OpenCV [norm or value range of the scoped matrix (normalization)], and attach norm_ Example code in the case of minmax
再聊聊我常用的15个数据源网站
Configuring the stub area of OSPF for Huawei devices
The printf function is realized through the serial port, and the serial port data reception is realized by interrupt
String comparison in batch file - string comparison in batch file
Do you understand this patch of the interface control devaxpress WinForms skin editor?
Telerik UI 2022 R2 SP1 Retail-Not Crack
Part V: STM32 system timer and general timer programming
[software reverse automation] complete collection of reverse tools
Installation and testing of pyflink
Learn to use code to generate beautiful interface documents!!!
Service asynchronous communication
[batch dos-cmd command - summary and summary] - jump, cycle, condition commands (goto, errorlevel, if, for [read, segment, extract string]), CMD command error summary, CMD error
C9高校,博士生一作发Nature!
[Niuke classic question 01] bit operation
pyflink的安装和测试
【批处理DOS-CMD命令-汇总和小结】-跳转、循环、条件命令(goto、errorlevel、if、for[读取、切分、提取字符串]、)cmd命令错误汇总,cmd错误
在jupyter中实现实时协同是一种什么体验