当前位置:网站首页>Slam d'attention: un slam visuel monoculaire appris de l'attention humaine
Slam d'attention: un slam visuel monoculaire appris de l'attention humaine
2022-07-07 00:41:00 【Atelier de vision 3D】
Cliquez en haut“3DAtelier visuel”,Sélectionner“Étoile”
Première livraison de marchandises sèches

Auteur 丨 chewing - gum au poivre mariné
Source 丨GiantPandaCV
0. Introduction
Quand les gens se promènent dans un environnement,Ils déplacent souvent leurs yeux pour se concentrer et se souvenir des points de repère évidents,Ces points de repère contiennent généralement les informations sémantiques les plus précieuses.Sur la base de cet instinct humain,"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"L'auteur deSLAMLe système simule le comportement de navigation humaine.Cet article est sémantiqueSLAMEt la Mission de vision par ordinateur propose un nouveau modèle.En outre,Les auteurs ont rendu public le fait qu'ils ont noté l'importanceEuRocEnsemble de données.
1. Informations sur le document
Titre:Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze
Auteur:Jinquan Li, Ling Pei, Danping Zou, Songpengcheng Xia, Qi Wu, Tao Li, Zhen Sun, Wenxian Yu
Source::2020 Computer Vision and Pattern Recognition (CVPR)
Lien vers le texte original:https://arxiv.org/abs/2009.06886v1
Liens de code:https://github.com/Li-Jinquan/Salient-Euroc
2. Résumé
Cet article présente un nouveau positionnement synchrone et un nouveau dessin (SLAM)Méthodes,C'est - à - dire:Attention-SLAM, Il combine le modèle de visibilité visuelle (SalNavNet) Et la vision monoculaire traditionnelle SLAM Pour simuler le mode de navigation humain .La plupartSLAM Méthodes toutes les caractéristiques extraites de l'image sont considérées comme d'égale importance dans le processus d'optimisation .Et pourtant, Les points saillants de la scène ont un impact plus important sur la navigation humaine .Donc,, Nous avons d'abord proposé un SalVavNet Modèle de signification visuelle , Où nous avons introduit un module de corrélation , Et propose une moyenne mobile exponentielle adaptative (EMA)Module. Ces modules atténuent la déviation centrale ,Pour faireSalNavNet Les graphiques saillants générés peuvent se concentrer davantage sur le même objet saillant .En outre, Les graphiques significatifs simulent le comportement humain ,Pour améliorerSLAMRésultats. Les points caractéristiques extraits des zones significatives ont un poids plus élevé dans le processus d'optimisation . Nous ajoutons des informations de signification sémantique à EurocEnsemble de données, Pour générer une visibilité Open Source SLAMEnsemble de données. Les résultats des tests combinés prouvent , Dans la plupart des cas d'essai ,Attention-SLAMEfficacité、 Meilleure précision et robustesse que Direct Sparse Odometry (DSO)、ORB-SLAMEtSalient DSOIsobase.
3. Analyse des algorithmes
Comme le montre la figure1 Ce qui est montré est présenté par l'auteur Attention-SLAMArchitecture, L'architecture est principalement basée sur des points caractéristiques dans un monoculaire visuel SLAM Ajouter des informations sémantiques significatives .Tout d'abord,, Les auteurs utilisent des modèles de signification pour générer Euroc Diagramme de signification correspondant de l'ensemble de données . Ces graphiques montrent les zones importantes de chaque image de la séquence d'images .Deuxièmement,, Les auteurs les utilisent comme poids , Faire en sorte que les points caractéristiques soient BA Poids différent dans le processus . Il aide le système à maintenir la cohérence sémantique . Lorsqu'il y a une texture similaire dans la séquence d'image , Traditionnel basé sur des points caractéristiques SLAM La méthode peut être mal appariée . Ces points d'inadéquation peuvent diminuer SLAM Précision du système .Donc,, Cette approche garantit que le système se concentre sur les points caractéristiques des zones les plus importantes , Amélioration de la précision et de l'efficacité .En outre, .Les auteurs utilisent également la théorie de l'information pour sélectionner les images clés et estimer l'incertitude de l'estimation de l'assiette .
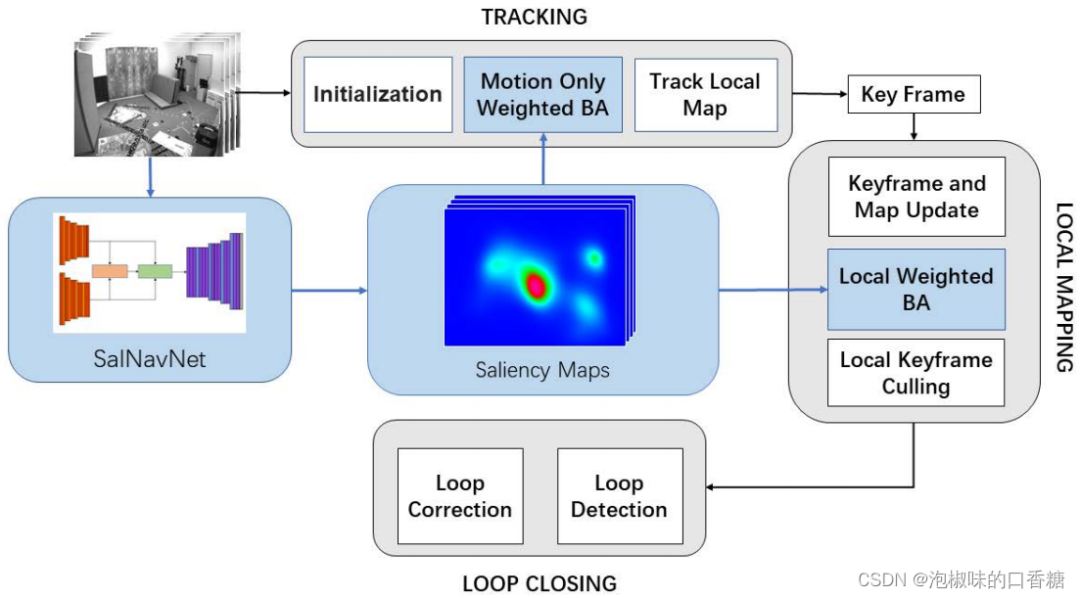
Fig.1 Attention-SLAMAperçu du schéma
Les principales contributions des auteurs sont les suivantes: :
(1) L'auteur propose une nouvelle SLAMArchitecture,C'est - à - dire:Attention-SLAM. Le schéma utilise une pondération BAPour remplacerSLAMLa traditionBA. Il peut réduire l'erreur de trajectoire plus efficacement . En apprenant l'attention humaine pendant la navigation , Les caractéristiques distinctives sont utilisées pour SLAMArrière - plan. Par rapport à l'étalonnage ,Attention-SLAM L'incertitude de l'estimation de l'assiette peut être réduite avec moins d'images clés , Et obtenir une plus grande précision .
(2) L'auteur propose unSalNavNet Un modèle de signification visuelle pour prédire les zones significatives d'un cadre .Principalement dansSalNavNet Un module d'association a été introduit dans , Et propose une adaptation EMAModule. .Ces modules peuvent atténuer la déviation centrale du modèle de signification , Et apprendre les informations de corrélation entre les cadres . En réduisant la déviation centrale de la plupart des modèles de signification visuelle ,SalNavNet L'information sémantique extraite de la signification visuelle peut aider Attention-SLAM Focalisation cohérente sur les points caractéristiques du même objet saillant .
(3) Par applicationSalNavNet, L'auteur a produit un EuRoc Ensemble de données de visibilité open source pour . Utilisation de la signification Euroc Preuve de l'évaluation de l'ensemble de données ,Attention-SLAMEfficacité、 Meilleure précision et robustesse que les repères .
3.1 SalNavNetArchitecture du réseau
Attention-SLAMSe compose de deux parties, La première partie est le prétraitement des données d'entrée , La deuxième partie est la vision SLAMSystème.Dans la première partie,L'auteur utilise leSalNavNet La génération correspond à SLAM Un graphique important de l'ensemble de données . Ces cartes sont utilisées comme entrées pour aider SLAM Le système trouve des points clés importants .
Dans la séquence des cadres , La position de l'objet saillant se déplace avec la lentille . En raison de la déviation centrale des modèles de signification existants , Seulement si ces objets saillants atteignent le Centre de l'image , Ce n'est que dans le modèle de signification qu'il est marqué comme une zone de signification . Quand ces objets se déplacent vers le bord de l'image , Le modèle de visibilité ignore ces objets . Le déplacement de l'attention fait que la vision SLAM Le système ne peut pas se concentrer uniformément sur les mêmes caractéristiques significatives .InAttention-SLAMMoyenne, Les auteurs espèrent que le modèle de signification pourra être continuellement focalisé sur les mêmes points caractéristiques , Qu'ils soient ou non au centre de l'image .Donc,, Application par l'auteur SalNavNetLa structure du réseau de2Comme indiqué,Il adopte une approcheSalEMAEtSalGAN Même structure d'encodeur et de décodeur , Où la partie encodeur est VGG-16, Le décodeur utilise une structure réseau dans l'ordre inverse de celui de l'encodeur .SalNavNet Peut se concentrer sur l'information contextuelle tout en , Évitez les changements rapides d'attention .
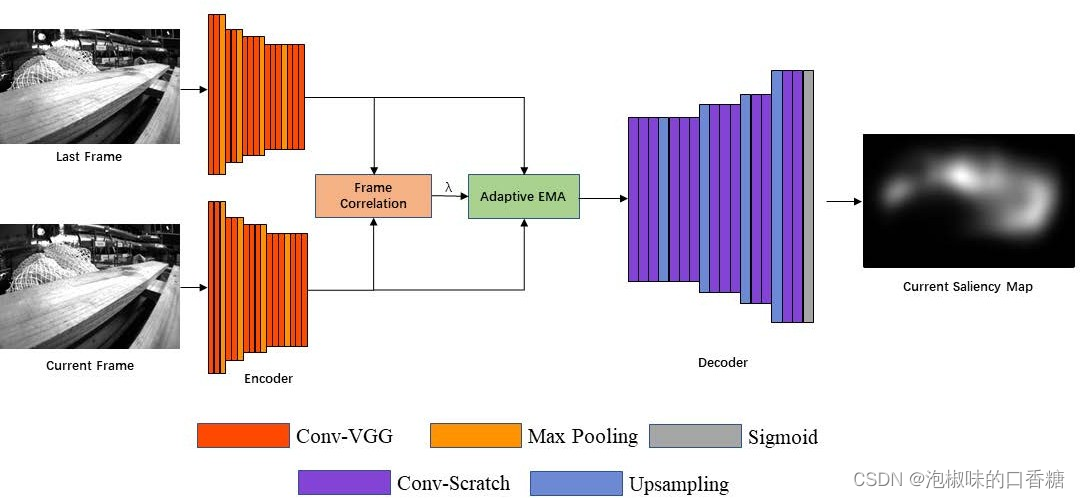
Fig.2 SalNavNetArchitecture
Pour apprendre l'information continue entre les cadres , L'auteur a d'abord utilisé le graphique 3 Modules liés au cadre montrés , Comparer les caractéristiques du cadre courant avec celles du cadre précédent via la sortie de l'encodeur .Enfin, Obtenir les coefficients de corrélation des deux cadres λ, Et introduire le coefficient de corrélation dans l'adaptation EMAModule.QuandλApproche1Heure, Indique qu'il n'y a pas de changement dans les deux graphiques caractéristiques . Lorsque la différence entre les caractéristiques adjacentes est importante ,Ça va faireλLa valeur diminue.Donc,, Lorsqu'il y a un grand changement entre deux caractéristiques adjacentes , Le modèle de signification produit des cartes de signification avec des changements d'attention rapides .
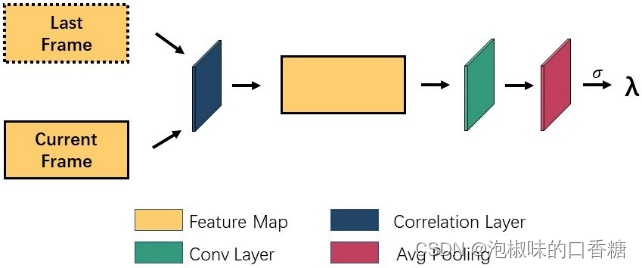
Fig.3 Architecture des modules liés au cadre
En outre, L'auteur a conçu une adaptation EMAModule,Comme le montre la figure4Comme indiqué.D'un côté,AdaptationEMA Le module permet au modèle d'apprendre des informations continues entre les cadres .D'un autre côté,Coefficient de similitudeλ L'introduction d'un modèle de réduction significative de la déviation centrale et des changements rapides d'attention . Dans le domaine de la visibilité visuelle , Les changements rapides d'attention peuvent mieux imiter les données réelles d'un ensemble de données .
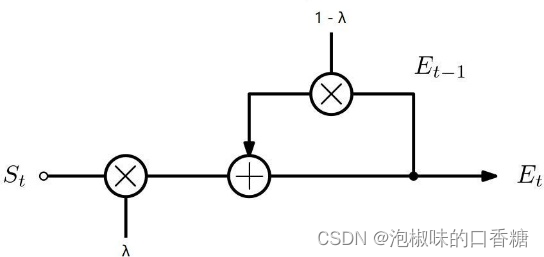
Fig.4 EMAArchitecture modulaire
3.2 PoidsBA Optimisation et sélection des images clés
Attention-SLAM .La deuxième partie du système utilise des graphiques significatifs pour améliorer la précision et l'efficacité de l'optimisation . L'auteur utilise le modèle généré par le modèle de signification visuelle comme poids . La carte de l'importance est une carte à l'échelle grise , Où la valeur de la partie blanche est 255, La valeur de la partie noire est 0. Pour utiliser la cartographie de la signification comme poids , L'auteur normalise ces cartes :
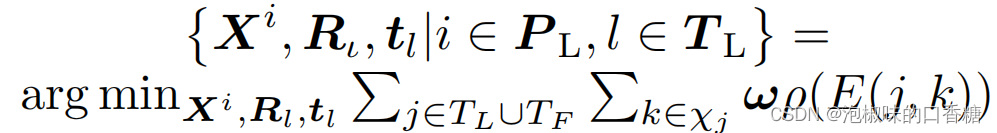
Parmi eux, La formule de calcul de l'erreur de projection est la suivante: :
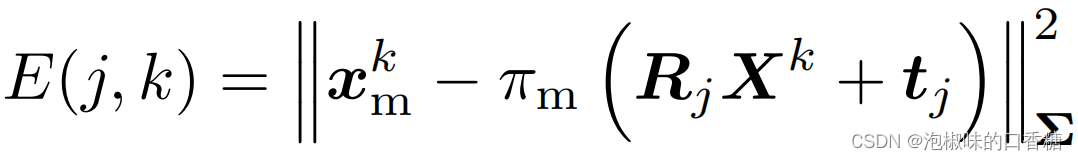
L'auteur utilise le concept de réduction de l'entropie comme critère de sélection des images clés , Pour améliorer encore Attention-SLAMPerformance du système. Plus précisément, il y a plusieurs étapes :
(1) Utiliser le rapport d'entropie pour sélectionner les images clés :InAttention-SLAM Dans le processus d'estimation des mouvements , Utilisez l'expression suivante pour calculer le rapport d'entropie :
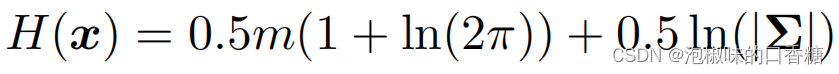
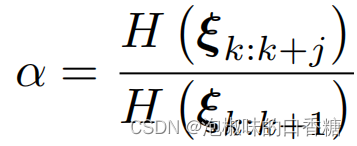
Dans le texte original, Paramètres de l'auteur αLe seuil pour0.9. Lorsque le rapport d'entropie d'un cadre dépasse 0.9Heure, Il ne sera pas sélectionné comme image clé . Parce que cela signifie que le cadre actuel ne réduit pas efficacement l'incertitude de l'estimation des mouvements .
(2) Évaluation de la réduction de l'entropie : Le modèle de signification extrait l'information sémantique de signification de l'environnement ,Ça pourrait faireAttention-SLAM La trajectoire estimée est plus proche de la valeur réelle de la trajectoire .Donc,, L'auteur analyse la théorie de l'information Attention-SLAM Effet sur l'incertitude de l'estimation de l'attitude .La formule de calcul est la suivante::
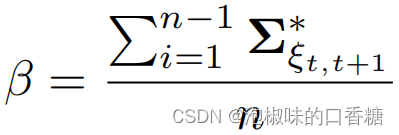
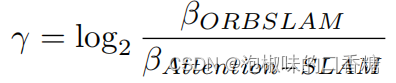
Parmi eux,n Pour le nombre d'images clés . L'auteur calcule principalement ORB-SLAMEtAttention-SLAM Réduction de l'entropie entre γ.SiAttention-SLAM L'incertitude dans l'estimation de l'assiette est inférieure à ORB-SLAM,Etγ Sera supérieur à zéro .
4.L'expérience
Les auteurs ont d'abord analysé les paires de cartes de signification générées par différents modèles de signification Attention-SLAMImpact de, Et un nouvel ensemble de données sur la signification a été généré à l'aide du modèle de signification , Appelé remarquable EuRoc.Et puis, L'auteur est remarquable EurocSur l'ensemble de donnéesAttention-SLAMAutresSOTALa vision deSLAMMéthodes de comparaison. L'appareil informatique utilisé par l'auteur est i5-9300H CPU (2.4 GHz)Et16G RAM.
4.1 Basé surAttention-SLAM Modèle de saillie d'image basé sur
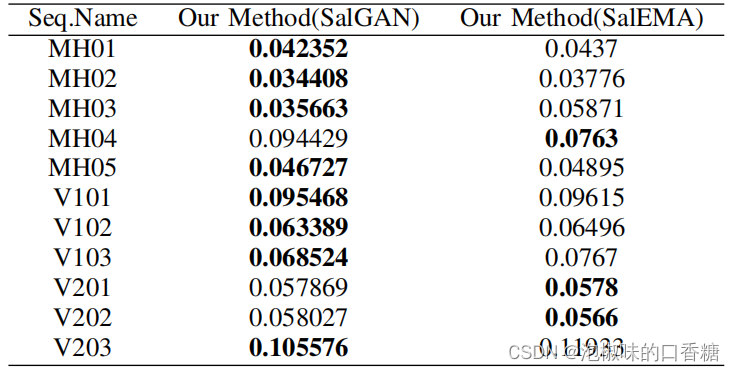
Comme le montre la figure5 Le modèle de signification est utilisé séparément SalGAN Et le modèle de signification SalEMA La génération correspond à Euroc Résultats des graphiques significatifs pour l'ensemble de données ,SalEMA La zone de surbrillance dans le graphique de surbrillance généré est très petite ,SalGAN La déviation centrale du graphique significatif généré est faible .Tableau1 Est l'erreur de trajectoire absolue calculée (ate)Racine carrée moyenne de(RMSE).Les résultats montrent,SalGAN Les cartes de visibilité générées aident Attention-SLAM Meilleure performance dans la plupart des séries de données , C'est - à - dire que le graphique significatif d'un décalage central faible fait Attention-SLAM Pour une plus grande précision .

Fig.5 Comparaison des graphiques significatifs :(a) Séquence d'image originale (b)SalEMA Carte de visibilité générée (c)SalGAN Carte de visibilité générée
Tableau1 Poids générés à l'aide de différents modèles de signification ,CalculORB-SLAMEtAttention-SLAM Erreur absolue de trajectoire entre RMSE
4.2 Le modèle de visibilité vidéo est comparé à SalNavNetComparaison
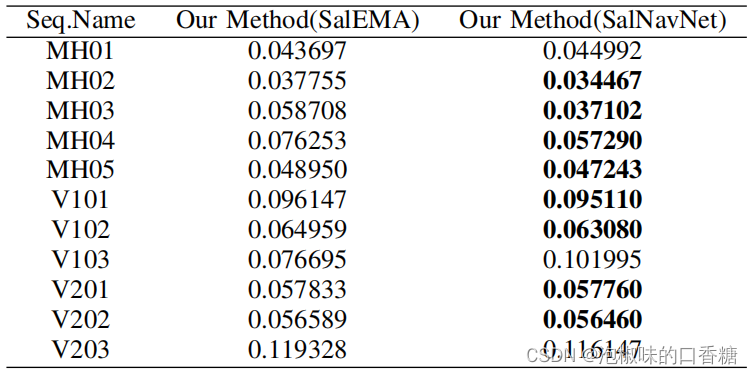
Comme le montre la figure6C'est comme ça.SalEMAAvecSalNavNet Comparaison des cartes significatives générées .Les résultats montrent,SalEMA Les graphiques significatifs qui en résultent présentent une forte déviation centrale . Bien que les trois images originales adjacentes n'aient pas beaucoup changé ,MaisSalEMA Les cartes significatives générées ont subi des changements significatifs .EtSalNavNet Les cartes significatives générées atténuent la déviation centrale .Comme indiqué dans le tableau2Comme indiqué,SalNavNet Meilleure performance dans la plupart des séries de données que SalEMA.Cela signifieSalNavNet Les cartes surlignées générées peuvent aider Attention-SLAMQueSalEMAObtenir de meilleures performances.

Fig.6 Comparaison des graphiques significatifs :(a) Séquence d'image originale (b)SalEMA Carte de visibilité générée (c)SalNavNet Carte de visibilité générée
Tableau2 En utilisant le modèle de signification le plus avancé SalEMAUtilisationSalNavNetDeAttention-slam Erreur absolue de trajectoire entre RMSE
4.3 ImportanceEurocEnsemble de données
Pour vérifierAttention-SLAMEfficacité,L'auteur estEuRoc L'ensemble de données est basé sur une nouvelle sémantique SLAMEnsemble de données.ImportanceEuRoc L'ensemble de données comprend l'ensemble de données original cam0Données、 Valeurs réelles et diagrammes de signification correspondants .Fig.7 Montre de l'importance Euroc Trois cadres consécutifs dans l'ensemble de données et leurs masques de visibilité visuelle correspondants .On peut le découvrir., L'attention change avec le mouvement de la caméra , Mais l'attention portée aux objets visibles est continue .

Fig.7 ImportanceEuRocEnsemble de données:(a)Image originale (b) Représentation de la signification correspondante , La partie blanche indique une plus grande attention (c) Le thermographe représente
4.4 AutresSLAMComparaison des méthodes
Fig.8C'est comme ça.Attention-SLAMInV101 Pistes 2D sur un ensemble de données .Les résultats montrent que,UtiliserAttention-SLAM Les trajectoires estimées sont plus proches de la vérité .Attention-SLAM Mettre davantage l'accent sur les caractéristiques distinctives , Ainsi, l'estimation de l'assiette est plus proche de la valeur réelle . Afin de mieux analyser l'exactitude des estimations d'assiette , Les auteurs sont présentés séparément dans la figure 9 Les valeurs estimées et réelles des poses 3D sont tracées dans . Et utiliser un cadre rouge pour agrandir une partie importante de la piste . Deux méthodes avant 40 La piste est bien tracée en quelques secondes , Mais ensuite, la méthode de base est XAxe etZ Grand décalage sur l'axe .In50-60En quelques secondes,Attention-SLAM Peut mieux suivre ZAxe.
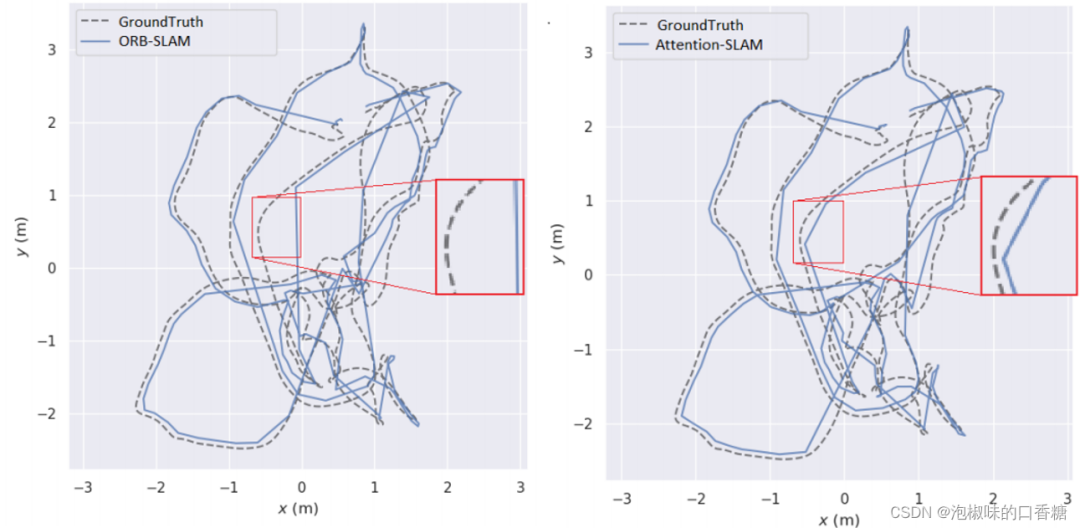
Fig.8 Inv101Sur l'ensemble de donnéesORB-SLAMEtAttention-SLAMDe2D Comparaison des trajectoires
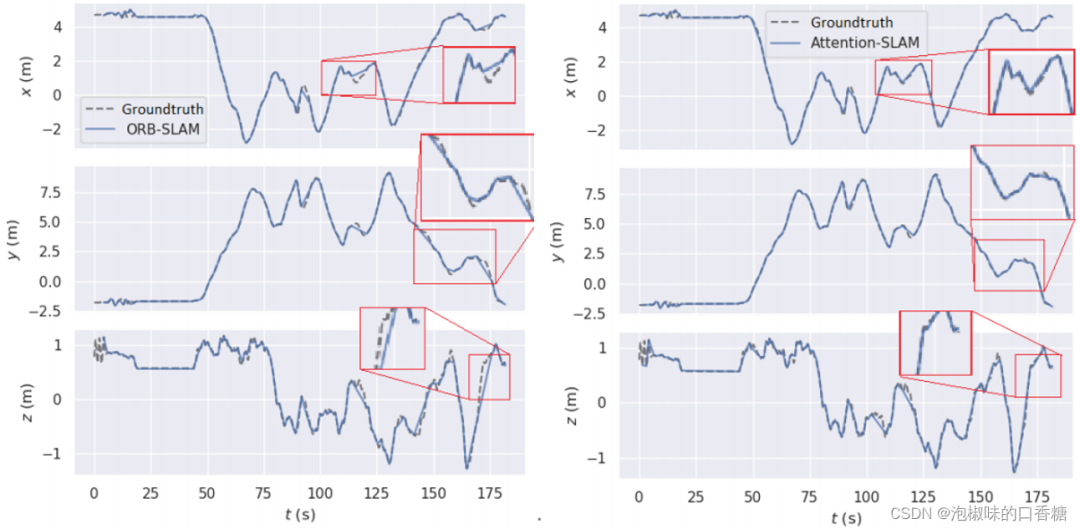
Fig.9 ORB-SLAMEtAttention-SLAMDe3DComparaison des trajectoires
Pour une évaluation plus approfondie Attention-SLAM,L'auteur a comparéAttention-SLAMEtDSOPerformance,Les résultats sont présentés dans le tableau ci - dessous.3Et tableaux4Comme indiqué.Les résultats montrent,Attention-SLAM Une grande précision a été obtenue dans la plupart des scénarios .
Tableau3 Méthodes et Attention-SLAM Erreur de trajectoire absolue moyenne de
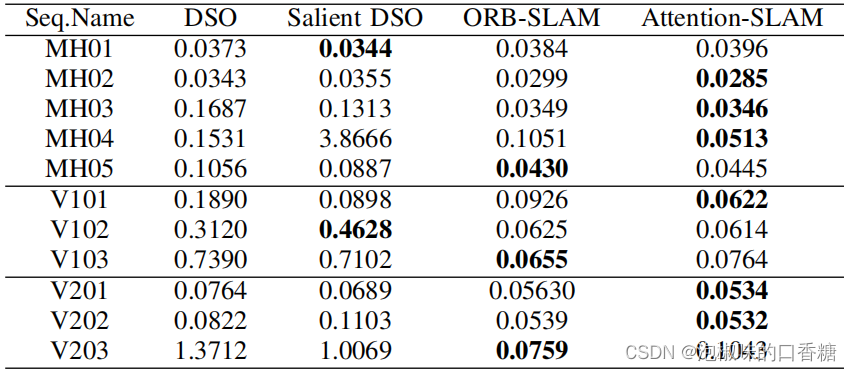
Tableau4 Méthodes et Attention-SLAMDeRMSEErreur absolue de trajectoire
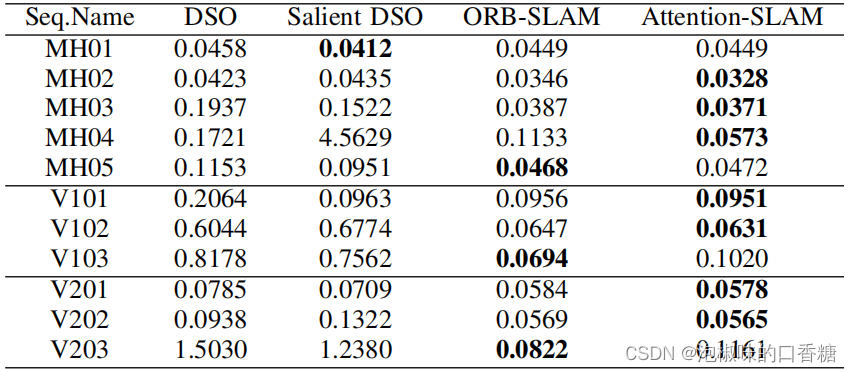
Tableau5C'est comme ça.ORB-SLAMEtAttention-SLAM Comparaison des images clés générées .Les résultats montrent,Attention-slam Bonne performance dans les séries de données les plus simples et modérément difficiles , Mais pas dans une séquence difficile ,Par exempleMH04、MH05、V203、V103.
Tableau5 Nombre d'images clés
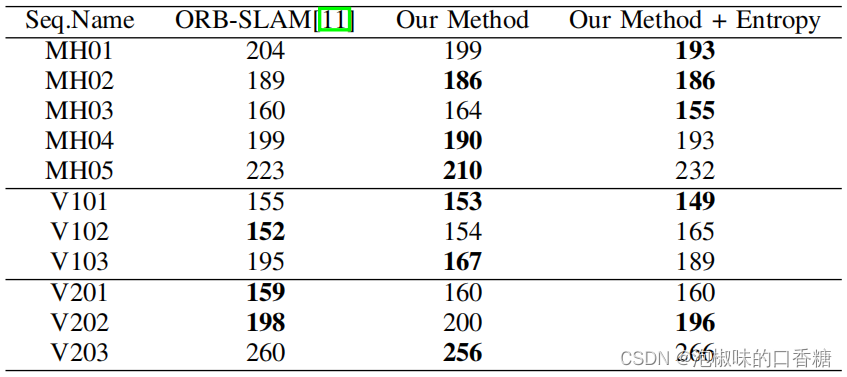
Mais après que l'auteur a ajouté la stratégie de sélection des clés d'entropie à Attention-SLAMAprès, Cette norme permet Attention-SLAM Sélectionnez plus d'images clés dans une séquence de données difficile .Comme indiqué dans le tableau6Comme indiqué, Ce critère permet de Attention-SLAM Meilleure performance dans des séquences de données difficiles .Donc,, La mesure du rapport d'entropie est Attention-SLAM Une stratégie importante pour . .Lorsque le modèle de signification ajoute suffisamment d'informations sémantiques au système , Permet au système de sélectionner moins d'images clés . Lorsque le modèle de signification ne réduit pas l'incertitude de l'estimation du Mouvement , Permet au système de sélectionner plus d'images clés pour une meilleure performance .
Tableau6 Ajouter le rapport d'entropie avant et après la sélection Attention-SLAMMoyenne deATEComparaison des performances
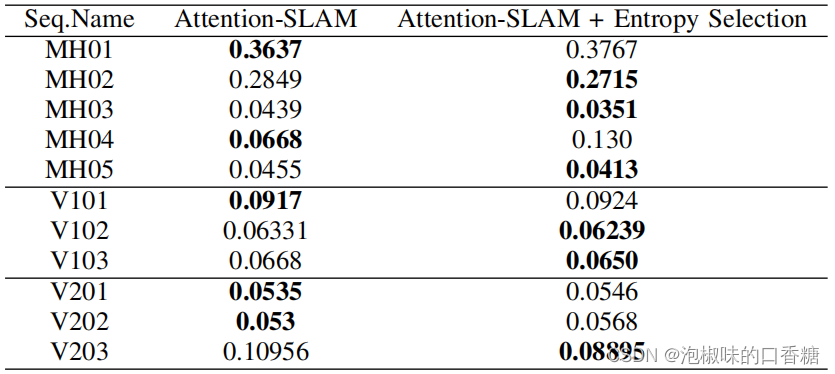
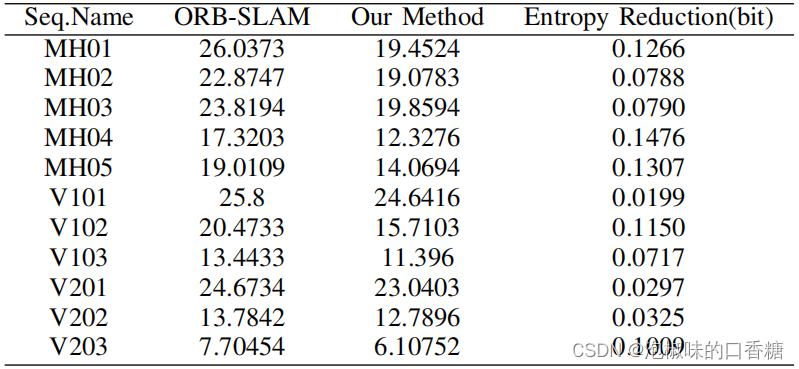
En outre,Comme indiqué dans le tableau7Comme indiqué,Attention-SLAM Réduction de l'incertitude des méthodes traditionnelles , La réduction de l'entropie est liée à Attention-SLAM La précision est positivement corrélée avec .
Tableau7 Comparaison de la réduction de l'entropie
5. Conclusions
In2020 CVPRDocuments"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"Moyenne,L'auteur propose une sorte deAttention-SLAMSémantique deSLAMMéthodes. Il combine l'information sémantique de la signification visuelle avec la vision SLAMSystème.Auteur basé surEuRoc L'ensemble de données établit une distinction EuRoc, C'est un message sémantique marqué SLAMEnsemble de données. Avec la vision monoculaire actuelle SLAMComparaison des méthodes, La méthode est plus efficace et plus précise , En même temps, l'incertitude de l'estimation de l'assiette peut être réduite .
Cet article n'est destiné qu'au partage académique,En cas d'infraction,Veuillez contacter delete.
3DSite officiel du cours boutique de l'atelier de vision:3dcver.com
1.Technologie de fusion de données multi - capteurs pour la conduite automatique
2.Pour la conduite automatique3DPiste d'apprentissage de la pile complète pour la détection d'objets en nuage ponctuel!(Mode unique+Multimodal/Données+Code)
3.Reconstruction 3D complète de la vision:Analyse des principes、Explication du Code、Optimisation et amélioration
4.Le premier cours de traitement en nuage point au niveau industriel en Chine
5.Laser-La vision-IMU-GPSIntégrationSLAMTri des algorithmes et explication du Code
6.Comprendre complètement la vision-InertieSLAM:Basé surVINS-FusionC'est officiel.
7.Comprendre complètement la baseLOAMCadre3DLaserSLAM: Analyse du code source à l'optimisation de l'algorithme
8.Analyse approfondie de la pièce、Laser extérieurSLAMPrincipe de l'algorithme clé、Code et pratique(cartographer+LOAM +LIO-SAM)
10.Méthode d'estimation de la profondeur monoculaire:Tri des algorithmes et mise en œuvre du Code
11.Déploiement d'un modèle d'apprentissage profond dans la conduite automatique
12.Modèle de caméra et étalonnage(Monoculaire+Binoculaire+Fisheye)
13.Poids lourd!Véhicule à quatre rotors:Algorithme et combat réel
14.ROS2De l'initiation à la maîtrise:Théorie et pratique
15.Le premier3DTutoriel de détection des défauts:Théorie、Code source et combat réel
16.Basé surOpen3D Introduction au Cloud point et tutoriels pratiques
Poids lourd!3DCVer-Contribution à la rédaction de documents universitaires Groupe ACCréé
Numériser le Code pour ajouter un petit assistant Wechat,MaisDemande d'adhésion3DAtelier visuel-Rédaction et contribution de documents universitaires Groupe de communication Wechat,Pour échanger des sommets、Haut de la page、SCI、EIQuestions relatives à la rédaction et à la contribution.
En même tempsVous pouvez également demander à rejoindre notre groupe de communication directionnelle,Actuellement, il y a principalement3DLa vision、CV&Apprentissage profond、SLAM、Reconstruction 3D、Point Cloud post - traitement、Conduite automatique、Fusion Multi - capteurs、CVIntroduction、Mesure tridimensionnelle、VR/AR、3DReconnaissance faciale、Imagerie médicale、Détection des défauts、Reconnaissance des piétons、Suivi des cibles、Produits visuels au sol、Concours de vision、Reconnaissance des plaques d'immatriculation、Sélection du matériel、Échanges universitaires、Échanges de recherche d'emploi、ORB-SLAMCommunication de code source série、Estimation de la profondeurGroupe isowechat.
N'oubliez pas de noter:Orientation de la recherche+L'école/Entreprises+Un surnom.,Par exemple:”3DLa vision + Shanghai Jiaotong University + Silence.“.Veuillez noter selon le format,Peut être rapidement passé et invité dans le Groupe.Contributions originalesVeuillez également contacter.

▲Presse longue plus Groupe Wechat ou contribution
▲Appuyez sur le bouton "attention au public"
3DLa vision passe de l'initiation à la maîtrise de la planète de la connaissance:Pour3DDans le domaine visuelCours de vidéoCheng(Série de reconstruction 3D、Série de nuages ponctuels 3D、Série de lumière structurée、Étalonnage main - oeil、Étalonnage de la caméra、Laser/La visionSLAM、AutomatiqueConduite, etc.)、Résumé des points de connaissance、Parcours d'apprentissage avancé d'entrée、Mise à jourpaperPartager、Réponses aux questionsCinq aspects du travail profond du sol,En outre, les ingénieurs d'algorithmes de toutes sortes de grandes usines fournissent des conseils techniques.En même temps,,Planet sera publié conjointement avec des entreprises bien connues3DInformation sur le poste de développement d'algorithmes visuels et l'amarrage des projets,Créer une zone de rassemblement de fans de fer intégrant la technologie et l'emploi,Proche4000Les membres de la planète créent de meilleuresAIProgrès communs dans le monde,Portail de la planète de la connaissance:
Apprendre3DTechnologie de base de la vision,Aperçu de la numérisation,3Remboursement inconditionnel dans les jours
Il y a des tutoriels de haute qualité dans le cercle、Répondre aux questions et répondre aux questions、Vous aider à résoudre vos problèmes efficacement
J'ai trouvé ça utile.,Un compliment, s'il vous plaît.~
边栏推荐
- 三维扫描体数据的VTK体绘制程序设计
- "Latex" Introduction to latex mathematical formula "suggestions collection"
- 如何判断一个数组中的元素包含一个对象的所有属性值
- Interesting wine culture
- Imeta | Chen Chengjie / Xia Rui of South China Agricultural University released a simple method of constructing Circos map by tbtools
- JS+SVG爱心扩散动画js特效
- 【软件逆向-求解flag】内存获取、逆变换操作、线性变换、约束求解
- Leecode brush questions record sword finger offer 11 Rotate the minimum number of the array
- Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
- 基于GO语言实现的X.509证书
猜你喜欢
从外企离开,我才知道什么叫尊重跟合规…
Understand the misunderstanding of programmers: Chinese programmers in the eyes of Western programmers
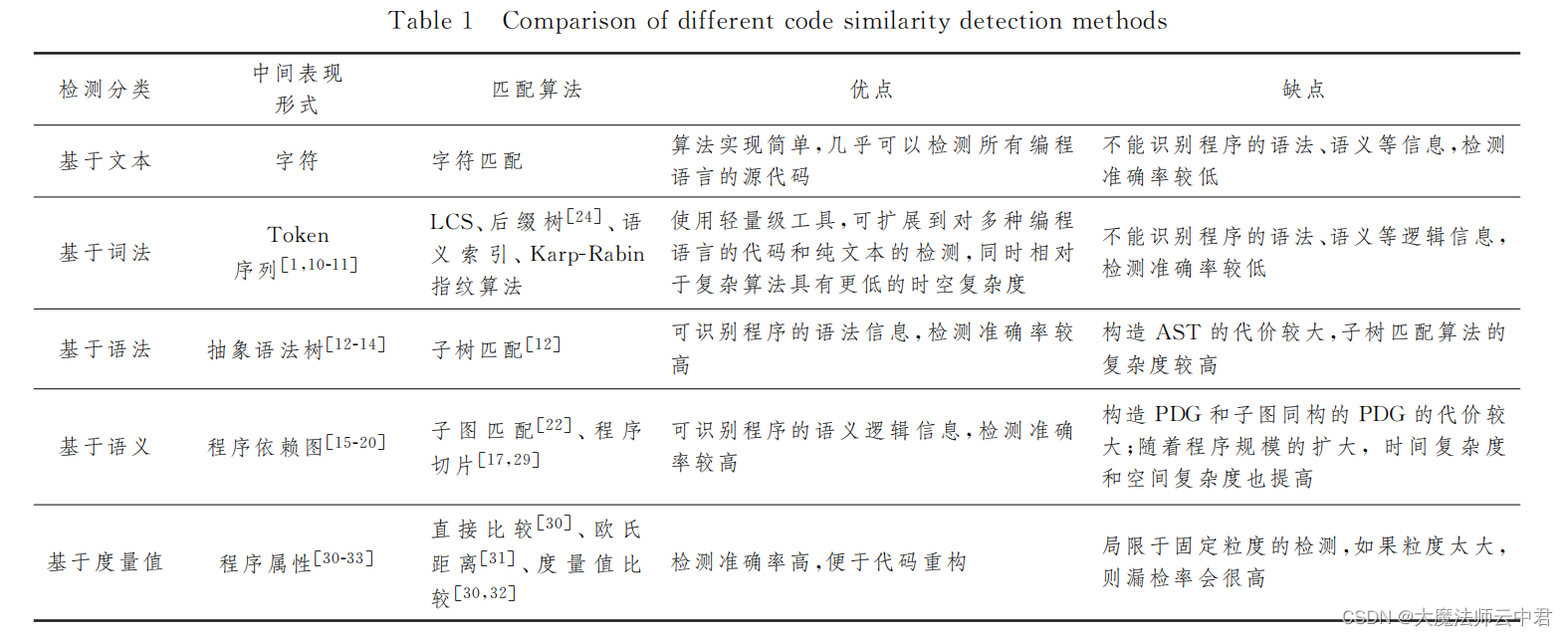
5种不同的代码相似性检测,以及代码相似性检测的发展趋势

What can the interactive slide screen demonstration bring to the enterprise exhibition hall

threejs图片变形放大全屏动画js特效
英雄联盟|王者|穿越火线 bgm AI配乐大赛分享
2022/2/10 summary

【软件逆向-自动化】逆向工具大全

alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
uniapp实现从本地上传头像并显示,同时将头像转化为base64格式存储在mysql数据库中
随机推荐
Matlab learning notes
Three application characteristics of immersive projection in offline display
Value Function Approximation
Why should a complete knapsack be traversed in sequence? Briefly explain
DAY TWO
Lombok makes ⽤ @data and @builder's pit at the same time. Are you hit?
rancher集成ldap,实现统一账号登录
Business process testing based on functional testing
陀螺仪的工作原理
Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
[vector retrieval research series] product introduction
The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge
Google, Baidu and Yahoo are general search engines developed by Chinese companies_ Baidu search engine URL
Liuyongxin report | microbiome data analysis and science communication (7:30 p.m.)
一图看懂对程序员的误解:西方程序员眼中的中国程序员
Markov decision process
Basic information of mujoco
iMeta | 华南农大陈程杰/夏瑞等发布TBtools构造Circos图的简单方法
Mujoco second order simple pendulum modeling and control
Introduction to GPIO