当前位置:网站首页>【736. Lisp 语法解析】
【736. Lisp 语法解析】
2022-07-06 22:14:00 【千北@】
来源:力扣(LeetCode)
描述:
给你一个类似 Lisp 语句的字符串表达式 expression,求出其计算结果。
表达式语法如下所示:
表达式可以为整数,let 表达式,add 表达式,mult 表达式,或赋值的变量。表达式的结果总是一个整数。(整数可以是正整数、负整数、0)
let 表达式采用
"(let v1 e1 v2 e2 ... vn en expr)"的形式,其中let总是以字符串"let"来表示,接下来会跟随一对或多对交替的变量和表达式,也就是说,第一个变量v1被分配为表达式e1的值,第二个变量v2被分配为表达式e2的值,依次类推;最终let表达式的值为expr表达式的值。add 表达式表示为
"(add e1 e2)",其中add总是以字符串"add"来表示,该表达式总是包含两个表达式e1、e2,最终结果是e1表达式的值与e2表达式的值之 和 。mult 表达式表示为
"(mult e1 e2)",其中mult总是以字符串"mult"表示,该表达式总是包含两个表达式e1、e2,最终结果是e1表达式的值与e2表达式的值之 积 。在该题目中,变量名以小写字符开始,之后跟随 0 个或多个小写字符或数字。为了方便,
"add","let","mult"会被定义为 “关键字” ,不会用作变量名。最后,要说一下作用域的概念。计算变量名所对应的表达式时,在计算上下文中,首先检查最内层作用域(按括号计),然后按顺序依次检查外部作用域。测试用例中每一个表达式都是合法的。有关作用域的更多详细信息,请参阅示例。
示例 1:
输入:expression = "(let x 2 (mult x (let x 3 y 4 (add x y))))"
输出:14
解释:
计算表达式 (add x y), 在检查变量 x 值时,
在变量的上下文中由最内层作用域依次向外检查。
首先找到 x = 3, 所以此处的 x 值是 3 。
示例 2:
输入:expression = "(let x 3 x 2 x)"
输出:2
解释:let 语句中的赋值运算按顺序处理即可。
示例 3:
输入:expression = "(let x 1 y 2 x (add x y) (add x y))"
输出:5
解释:
第一个 (add x y) 计算结果是 3,并且将此值赋给了 x 。
第二个 (add x y) 计算结果是 3 + 2 = 5 。
提示:
- 1 <= expression.length <= 2000
- exprssion 中不含前导和尾随空格
- expressoin 中的不同部分(token)之间用单个空格进行分隔
- 答案和所有中间计算结果都符合 32-bit 整数范围
- 测试用例中的表达式均为合法的且最终结果为整数
方法一:递归解析
对于一个表达式 expression,如果它的首字符不等于左括号 ‘ ( ’ ,那么它只能是一个整数或者变量;否则它是 let, add 和 mult 三种表达式之一。
定义函数 parseVar 用来解析变量以及函数 parseInt 用来解析整数。使用 scope 来记录作用域,每个变量都依次记录下它从外到内的所有值,查找时只需要查找最后一个数值。我们递归地解析表达式 expression。
expression的下一个字符不等于左括号‘ ( ’expression的下一个字符是小写字母,那么表达式是一个变量,使用函数parseVar解析变量,然后在scope中查找变量的最后一个数值即最内层作用域的值并返回结果。expression的下一个字符不是小写字母,那么表达式是一个整数,使用函数parseInt解析并返回结果。
去掉左括号后,
expression的下一个字符是‘ l ’,那么表达式是let表达式。对于let表达式,需要判断是否已经解析到最后一个expr表达式。- 如果下一个字符不是小写字母,或者解析变量后下一个字符是右括号
‘ ) ’,说明是最后一个expr表达式,计算它的值并返回结果。并且我们需要在scope中清除let表达式对应的作用域变量。 - 否则说明是交替的变量
vi和表达式ei,在scope将变量vi的数值列表增加表达式ei的数值。
- 如果下一个字符不是小写字母,或者解析变量后下一个字符是右括号
去掉左括号后,
expression的下一个字符是‘ a ’,那么表达式是add表达式。计算add表达式对应的两个表达式 e1 和 e2 的值,返回两者之和。去掉左括号后,
expression的下一个字符是‘ m ’,那么表达式是mult表达式。计算mult表达式对应的两个表达式 e1 和 e2 的值,返回两者之积。
代码:
class Solution {
private:
unordered_map<string, vector<int>> scope;
public:
int evaluate(string expression) {
int start = 0;
return innerEvaluate(expression, start);
}
int innerEvaluate(const string &expression, int &start) {
if (expression[start] != '(') {
// 非表达式,可能为:整数或变量
if (islower(expression[start])) {
string var = parseVar(expression, start); // 变量
return scope[var].back();
} else {
// 整数
return parseInt(expression, start);
}
}
int ret;
start++; // 移除左括号
if (expression[start] == 'l') {
// "let" 表达式
start += 4; // 移除 "let "
vector<string> vars;
while (true) {
if (!islower(expression[start])) {
ret = innerEvaluate(expression, start); // let 表达式的最后一个 expr 表达式的值
break;
}
string var = parseVar(expression, start);
if (expression[start] == ')') {
ret = scope[var].back(); // let 表达式的最后一个 expr 表达式的值
break;
}
vars.push_back(var);
start++; // 移除空格
int e = innerEvaluate(expression, start);
scope[var].push_back(e);
start++; // 移除空格
}
for (auto var : vars) {
scope[var].pop_back(); // 清除当前作用域的变量
}
} else if (expression[start] == 'a') {
// "add" 表达式
start += 4; // 移除 "add "
int e1 = innerEvaluate(expression, start);
start++; // 移除空格
int e2 = innerEvaluate(expression, start);
ret = e1 + e2;
} else {
// "mult" 表达式
start += 5; // 移除 "mult "
int e1 = innerEvaluate(expression, start);
start++; // 移除空格
int e2 = innerEvaluate(expression, start);
ret = e1 * e2;
}
start++; // 移除右括号
return ret;
}
int parseInt(const string &expression, int &start) {
// 解析整数
int n = expression.size();
int ret = 0, sign = 1;
if (expression[start] == '-') {
sign = -1;
start++;
}
while (start < n && isdigit(expression[start])) {
ret = ret * 10 + (expression[start] - '0');
start++;
}
return sign * ret;
}
string parseVar(const string &expression, int &start) {
// 解析变量
int n = expression.size();
string ret;
while (start < n && expression[start] != ' ' && expression[start] != ')') {
ret.push_back(expression[start]);
start++;
}
return ret;
}
};
执行用时:0 ms, 在所有 C++ 提交中击败了100.00%的用户
内存消耗:8.5 MB, 在所有 C++ 提交中击败了75.73%的用户
复杂度分析
时间复杂度: O(n),其中 n 是字符串 expression 的长度。递归调用函数 innerEvaluate 在某一层调用的时间复杂度为 O(k),其中 k 为指针 start 在该层调用的移动次数。在整个递归调用过程中,指针 start 会遍历整个字符串,因此解析 expression 需要 O(n)。
空间复杂度: O(n)。保存 scope 以及递归调用栈需要 O(n) 的空间。
方法二:状态机



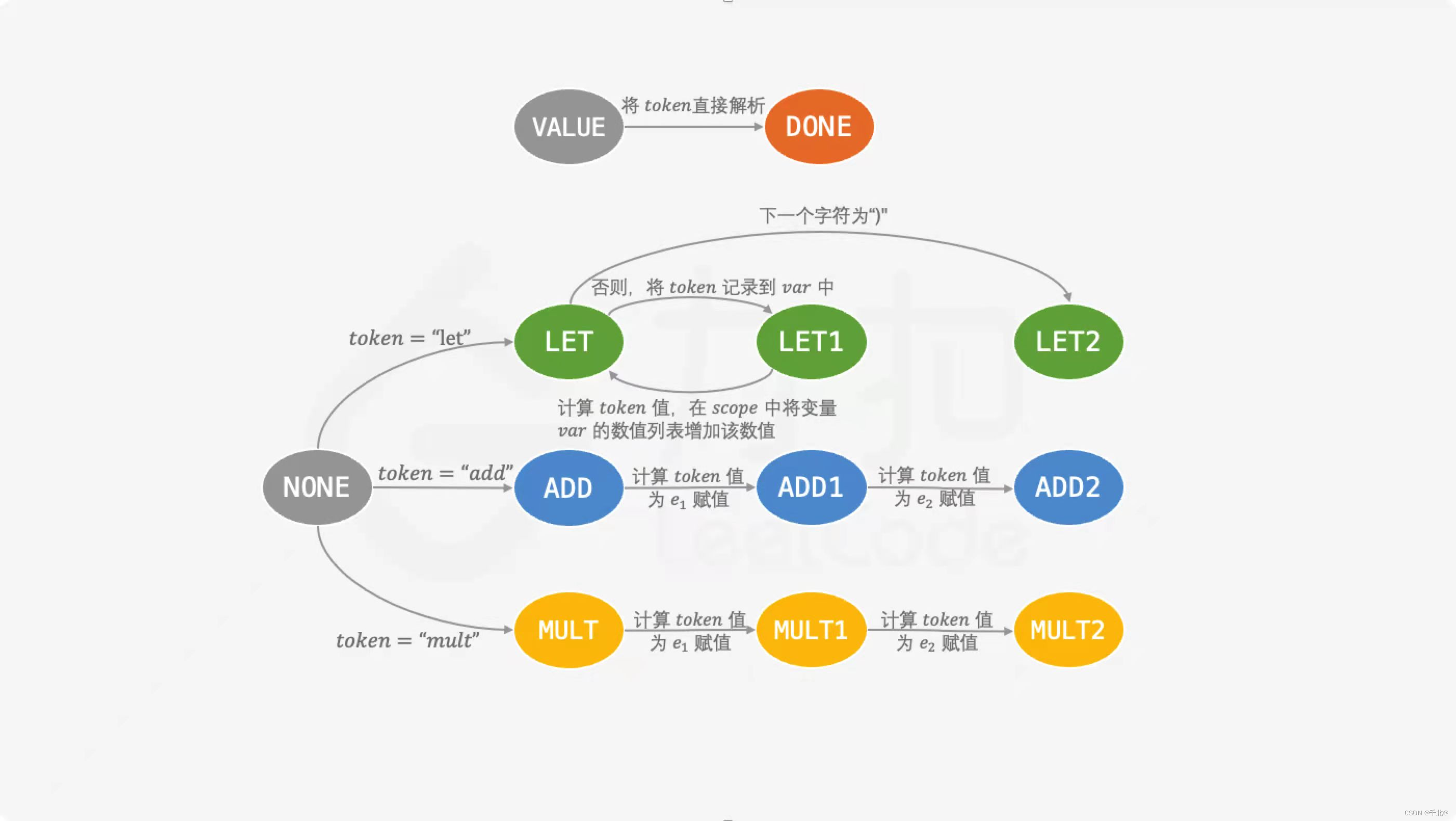
代码:
enum ExprStatus {
VALUE = 0, // 初始状态
NONE, // 表达式类型未知
LET, // let 表达式
LET1, // let 表达式已经解析了 vi 变量
LET2, // let 表达式已经解析了最后一个表达式 expr
ADD, // add 表达式
ADD1, // add 表达式已经解析了 e1 表达式
ADD2, // add 表达式已经解析了 e2 表达式
MULT, // mult 表达式
MULT1, // mult 表达式已经解析了 e1 表达式
MULT2, // mult 表达式已经解析了 e2 表达式
DONE // 解析完成
};
struct Expr {
ExprStatus status;
string var; // let 的变量 vi
int value; // VALUE 状态的数值,或者 LET2 状态最后一个表达式的数值
int e1, e2; // add 或 mult 表达式的两个表达式 e1 和 e2 的数值
Expr(ExprStatus s) {
status = s;
}
};
class Solution {
private:
unordered_map<string, vector<int>> scope;
public:
int evaluate(string expression) {
vector<vector<string>> vars;
int start = 0, n = expression.size();
stack<Expr> s;
Expr cur(VALUE);
while (start < n) {
if (expression[start] == ' ') {
start++; // 去掉空格
continue;
}
if (expression[start] == '(') {
start++; // 去掉左括号
s.push(cur);
cur = Expr(NONE);
continue;
}
string token;
if (expression[start] == ')') {
// 本质上是把表达式转成一个 token
start++; // 去掉右括号
if (cur.status == LET2) {
token = to_string(cur.value);
for (auto var : vars.back()) {
// 清除作用域
scope[var].pop_back();
}
vars.pop_back();
} else if (cur.status == ADD2) {
token = to_string(cur.e1 + cur.e2);
} else {
token = to_string(cur.e1 * cur.e2);
}
cur = s.top(); // 获取上层状态
s.pop();
} else {
while (start < n && expression[start] != ' ' && expression[start] != ')') {
token.push_back(expression[start]);
start++;
}
}
switch (cur.status) {
case VALUE:
cur.value = stoi(token);
cur.status = DONE;
break;
case NONE:
if (token == "let") {
cur.status = LET;
vars.emplace_back(); // 记录该层作用域的所有变量, 方便后续的清除
} else if (token == "add") {
cur.status = ADD;
} else if (token == "mult") {
cur.status = MULT;
}
break;
case LET:
if (expression[start] == ')') {
// let 表达式的最后一个 expr 表达式
cur.value = calculateToken(token);
cur.status = LET2;
} else {
cur.var = token;
vars.back().push_back(token); // 记录该层作用域的所有变量, 方便后续的清除
cur.status = LET1;
}
break;
case LET1:
scope[cur.var].push_back(calculateToken(token));
cur.status = LET;
break;
case ADD:
cur.e1 = calculateToken(token);
cur.status = ADD1;
break;
case ADD1:
cur.e2 = calculateToken(token);
cur.status = ADD2;
break;
case MULT:
cur.e1 = calculateToken(token);
cur.status = MULT1;
break;
case MULT1:
cur.e2 = calculateToken(token);
cur.status = MULT2;
break;
}
}
return cur.value;
}
int calculateToken(const string &token) {
if (islower(token[0])) {
return scope[token].back();
} else {
return stoi(token);
}
}
};
执行用时:0 ms, 在所有 C++ 提交中击败了100.00%的用户
内存消耗:7.3 MB, 在所有 C++ 提交中击败了93.20%的用户
复杂度分析
时间复杂度: O(n),其中 nn 是字符串 expression 的长度。状态机解析会遍历整个字符串,因此需要 O(n) 的时间。
空间复杂度: O(n)。保存状态的栈以及作用域变量都需要 O(n) 的空间。
author:LeetCode-Solution
边栏推荐
- Wechat can play the trumpet. Pinduoduo was found guilty of infringement. The shipment of byte VR equipment ranks second in the world. Today, more big news is here
- The root file system of buildreoot prompts "depmod:applt not found"
- EasyCVR视频广场点击播放时,主菜单高亮效果消失问题的修复
- Win11 control panel shortcut key win11 multiple methods to open the control panel
- 组织实战攻防演练的5个阶段
- Win11截图键无法使用怎么办?Win11截图键无法使用的解决方法
- sscanf,sscanf_s及其相关使用方法「建议收藏」
- ESG全球领导者峰会|英特尔王锐:以科技之力应对全球气候挑战
- [team learning] [34 issues] scratch (Level 2)
- 深入解析Kubebuilder
猜你喜欢
EasyCVR无法使用WebRTC进行播放,该如何解决?

MySQL数据库(基础篇)
R language principal component PCA, factor analysis, clustering analysis of regional economy analysis of Chongqing Economic Indicators
图灵诞辰110周年,智能机器预言成真了吗?
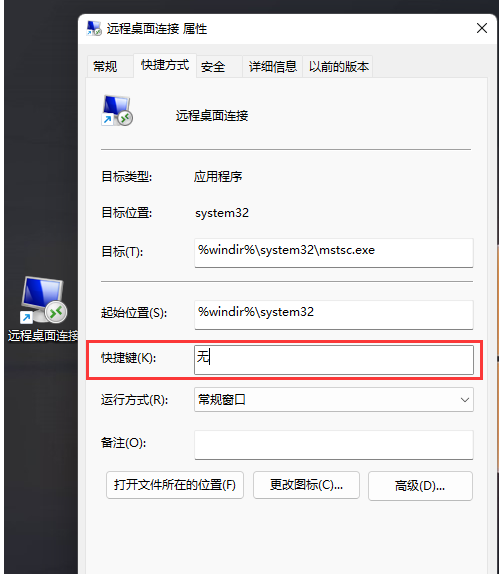
How to open win11 remote desktop connection? Five methods of win11 Remote Desktop Connection
这项15年前的「超前」技术设计,让CPU在AI推理中大放光彩

Camera calibration (I): robot hand eye calibration
acwing 843. N-queen problem

Section 1: (3) logic chip process substrate selection
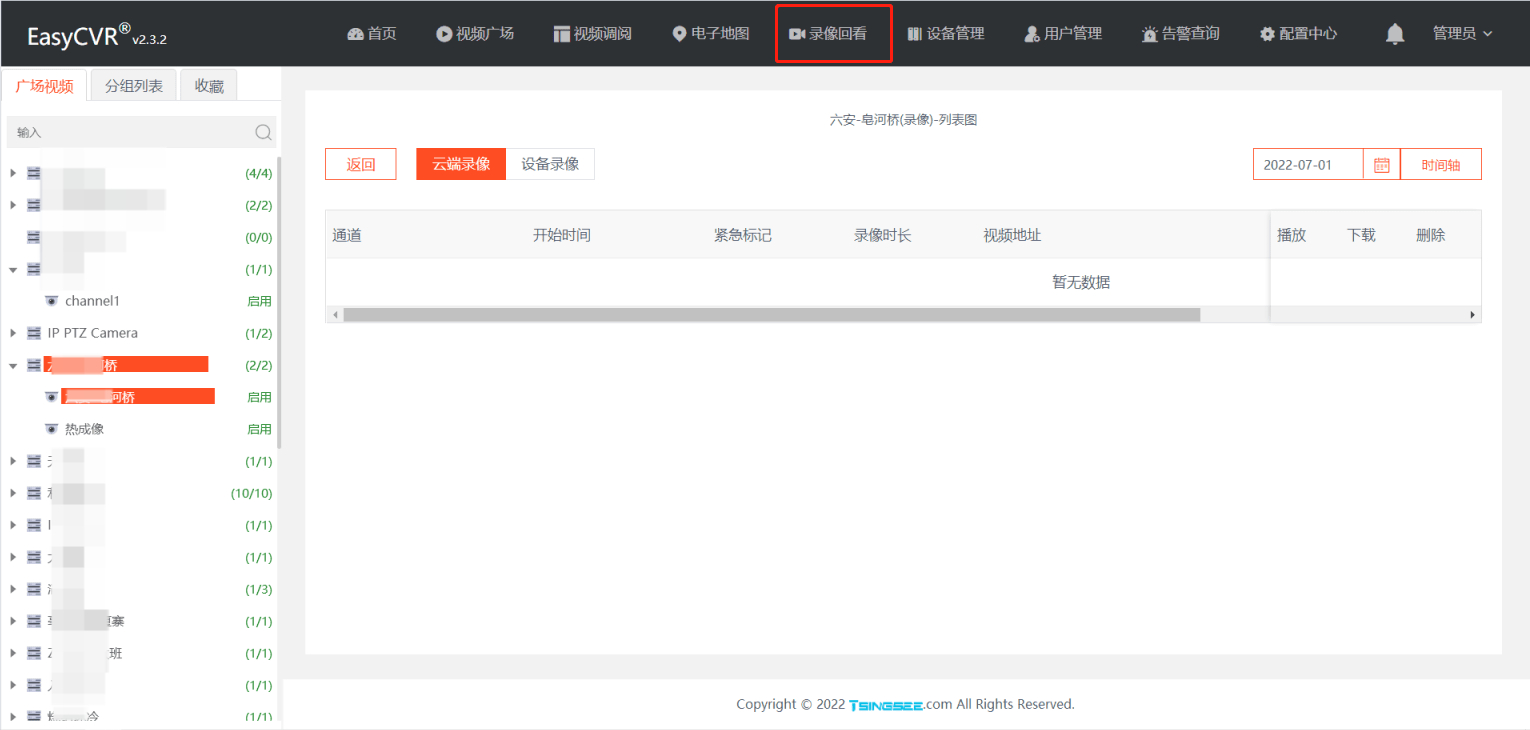
Fix the problem that the highlight effect of the main menu disappears when the easycvr Video Square is clicked and played
随机推荐
[team learning] [phase 34] Baidu PaddlePaddle AI talent Creation Camp
mpf2_线性规划_CAPM_sharpe_Arbitrage Pricin_Inversion Gauss Jordan_Statsmodel_Pulp_pLU_Cholesky_QR_Jacobi
Jetson nano配置pytorch深度学习环境//待完善
组织实战攻防演练的5个阶段
Programmers go to work fishing, so play high-end!
leetcode 53. Maximum subarray maximum subarray sum (medium)
每人每年最高500万经费!选人不选项目,专注基础科研,科学家主导腾讯出资的「新基石」启动申报
軟件測試之網站測試如何進行?測試小攻略走起!
【实践出真理】import和require的引入方式真的和网上说的一样吗
Web3 社区中使用的术语
程序员上班摸鱼,这么玩才高端!
Nanopineo use development process record
EasyCVR集群重启导致其他服务器设备通道状态离线情况的优化
Analyse approfondie de kubebuilder
Windows are not cheap things
Flex layout and usage
一图看懂!为什么学校教了你Coding但还是不会的原因...
A detailed explanation of head pose estimation [collect good articles]
视频融合云平台EasyCVR视频广场左侧栏列表样式优化
Optimization of channel status offline of other server devices caused by easycvr cluster restart