当前位置:网站首页>Deep understanding of distributed cache design
Deep understanding of distributed cache design
2022-07-07 00:46:00 【Java notes shrimp】
Click on the official account , utilize Fragment time to learn
Preface
In highly concurrent distributed systems , Caching is an essential part . There is no cache to speed up the system and block a large number of requests directly to the bottom of the system , It's hard for the system to sustain the impact of high concurrency , So the design of cache in distributed system is very important . Let's talk about the design of cache in distributed system and some problems encountered in the process .
The benefits and costs of caching
Using cache, we get the following benefits :
Speed up reading and writing . Because the cache is usually full memory , such as Redis、Memcache. Direct reading and writing to memory is better than traditional storage layers MySQL, Much better performance . for instance : Single machine with the same configuration Redis QPS Can easily tens of thousands of ,MySQL Only a few thousand . After accelerated reading and writing , Faster response time , In contrast, the user experience of the system can be better improved .
Reduce the load on the back end . Caching some complex calculations or time-consuming results can reduce the back-end system's response to CPU、IO、 Thread the requirements of these resources , Let the system run in a relatively resource healthy environment .
But then there are some costs :
Data inconsistency : There is a certain time window consistency between the data of cache layer and storage layer , The time window is related to the cache expiration time update policy .
Code maintenance costs : After adding the cache , You need to deal with both the cache layer and the storage layer logic , It increases the cost for developers to maintain the code .
O & M costs : Introduce cache layer , such as Redis. To ensure high availability , Need to be the master and slave , High concurrency requires clustering .
combined , As long as the benefits outweigh the costs , We can use caching .
Cache update
Cached data generally has a lifetime , After a period of time it will fail , It needs to be reloaded when accessing again . Cache invalidation is to ensure the consistency of the real data with the data source and the effective utilization of the cache space . The following will start with the usage scenario 、 Data consistency 、 Introduce several cache update strategies from three aspects of development, operation and maintenance cost .
1、LRU/LFU/FIFO
These three algorithms all belong to when Not enough cache Update algorithm used in . It's just that the rules for the elimination of selected elements are different :LRU Eliminate the ones that have not been visited for the longest time ,LFU Eliminate the least number of visits ,FIFO fifo .
Uniformity : Which data to clean up is determined by specific algorithm , Developers can only choose one of them , Poor consistency .
Development and maintenance costs : The algorithm does not need to be maintained by developers , Just configure the maximum available memory , Then select the elimination algorithm , Therefore, the cost is low .
Use scenarios : Suitable for limited memory space , The data remain unchanged for a long time , Basically, there is no data related business . For example, some information that cannot be changed once it is confirmed .
2、 Time out culling
to Manually set an expiration time for cached data , such as Redis expire command . When time is over , Reload from the data source and set the cache back on access again .
Uniformity : It mainly focuses on the cache life time window , This is controlled by developers . But there is still no guarantee of real-time consistency , The estimation consistency is general .
Development and maintenance costs : The cost is not very high , Many caching systems have their own expiration time API. such as Redis expire
Use scenarios : Suitable for businesses that can tolerate data inconsistency within a certain period of time , For example, the description of promotional activities .
3、 Active update
If the data of the data source is updated , Update the cache actively .
Uniformity : The consistency among the three is the highest , As long as you can be sure to update correctly , Consistency can guarantee .
Development and maintenance costs : This is relatively high ,** Business data update is coupled with cache update . Business data needs to be processed and updated successfully , The scenario of cache update failure ,** In order to decouple the update that is usually used for message queuing . But to improve fault tolerance , Generally, it will be combined with overtime elimination scheme , Avoid cache update failure , Cache not updated scenarios .
Use scenarios : High requirements for data consistency , Like the trading system , The total number of coupons .
So in general, the best practice for cache updates is :
Low consistency business : You can choose the first strategy and combine the second strategy .
High consistency business : Two 、 Combination of three strategies .
Penetration optimization
Cache penetration refers to querying data that does not exist at all , Cache tier and storage tier miss . The general processing logic is if the storage layers do not hit , The cache layer has no corresponding data . But in high concurrency scenarios, a lot of cache penetration , The request goes directly to the storage tier , The back-end system will be crushed by a little carelessness . Therefore, for cache penetration, we have the following schemes to optimize .
1、 Caching empty objects
The first solution is to cache an empty object . Missed requests for storage tiers , We return a business object by default . So you can resist A lot of repetition is meaningless Request , It plays a role in protecting the back end . However, this solution still can not deal with a large number of high concurrency and different cache penetration , If someone has figured out the scope of your business before , Make a lot of different requests in a flash , Your first query will still penetrate DB. Another disadvantage of this scheme is : Every different cache penetration , Cache an empty object . A lot of different penetrations , Cache a large number of empty objects . Memory is occupied by a lot of white space , So that really valid data can't be cached .
So for this kind of scheme, we need to do : First of all , Do a good job in business filtering . For example, we determine the business ID The range is [a, b], As long as it doesn't belong to [a,b] Of , The system returns directly to , Do not query directly . second , Set a shorter expiration time for cached empty objects , It can be effectively and quickly cleared when the memory space is insufficient .
2、 The bloon filter
The bloom filter is a combination of hash Function and bitmap A data structure of . Related definitions are as follows :
The bloon filter ( English :Bloom Filter) yes 1970 Proposed by bron in . It's actually a very long binary vector and a series of random mapping functions . The bloom filter can be used to retrieve whether an element is in a collection . Its advantage is that the space efficiency and query time are far more than the general algorithm , The disadvantage is that it has certain error recognition rate and deletion difficulty .
There are many introductions about the principle and implementation of Bloom filter on the Internet , Everyone, baidu /GOOGLE Just a minute .
Bloom filter can effectively judge whether elements are in the set , For example, the business above ID, And even hundreds of millions of data, bloom filter can work well . Therefore, for the query of some historical data, bloom filter is an excellent anti penetration choice . For real-time data , You need to actively update the bloom filter when the business data , This will increase the cost of developing, maintaining and updating , Like the proactive update cache logic, you need to deal with various abnormal results .
in summary , In fact, I think bloom filter and caching empty objects can be combined completely . The specific approach is to use the local cache to implement the bloom filter , Because the memory usage is very low , When you don't hit redis/memcache This remote cache query .
Bottomless optimization
1. What is the cache bottomless hole problem :
Facebook The staff reaction 2010 Years have reached 3000 individual memcached node , Store thousands of G The cache of . They found a problem –memcached The connection efficiency has decreased , Then add memcached node , And then when we're done , It's not getting better . be called “ Bottomless pit ” The phenomenon
2. The cause of cache bottomless hole :
Key value database or cache system , Because... Is usually used hash Function will key Map to the corresponding instance , cause key The distribution of has nothing to do with the business , But due to the amount of data 、 Demand for traffic , Need to use distributed post ( Whether client consistency 、redis-cluster、codis), Batch operations, such as batch acquisition of multiple key( for example redis Of mget operation ), You usually need to get from different instances key value , Compared with single machine batch operation, it only involves one network operation , Distributed batch operations involve multiple networks io.
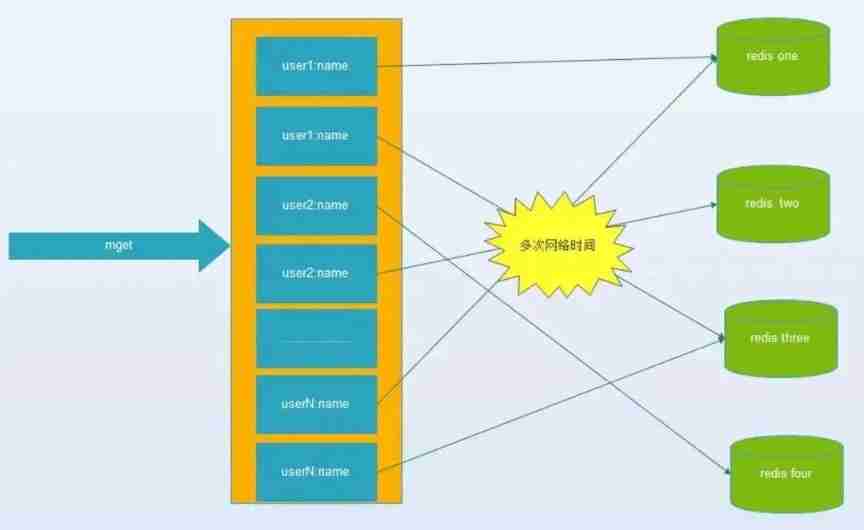
3. The harm caused by the bottomless hole problem :
(1) A batch operation of the client will involve multiple network operations , This means that the number of batch operations will increase , It's going to take longer .
(2) The number of network connections at the server becomes more , It also has a certain impact on the performance of the instance .
So the bottomless pit seems to be an unsolved problem . In fact, as long as we understand the causes of the bottomless hole and plan well in the early stage of business, we can reduce or even avoid the occurrence of the bottomless hole .
1、 First of all, if your business query does not , image mget This batch operation , congratulations , The bottomless pit will be far away from you .
2、 Isolate the cluster as a project group , In this way, each group of businesses redis/memcache The cluster will not be too large .
3、 If your company's maximum peak traffic is far less than FB, Maybe you don't need to worry about this problem .
Are there any technical priorities ? The solution is as follows :
1. IO The optimization idea of :
(1) The efficiency of the command itself : for example sql Optimize , Command optimization .
(2) Network times : Reduce the number of Communications .
(3) Reduce access costs : Coptis / Connection pool ,NIO etc. .
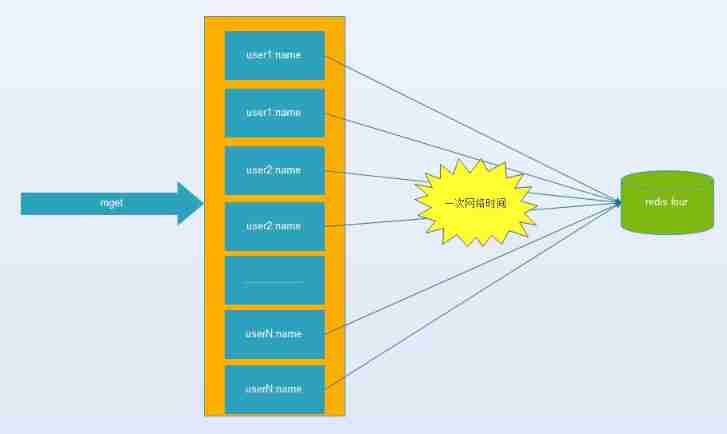
(4) IO Access merge :O(n) To O(1) The process : Batch interface (mget).
(1)、(3)、(4) It is usually decided by the design developer of the cache system , As users, we can learn from (2) Optimize the number of communications
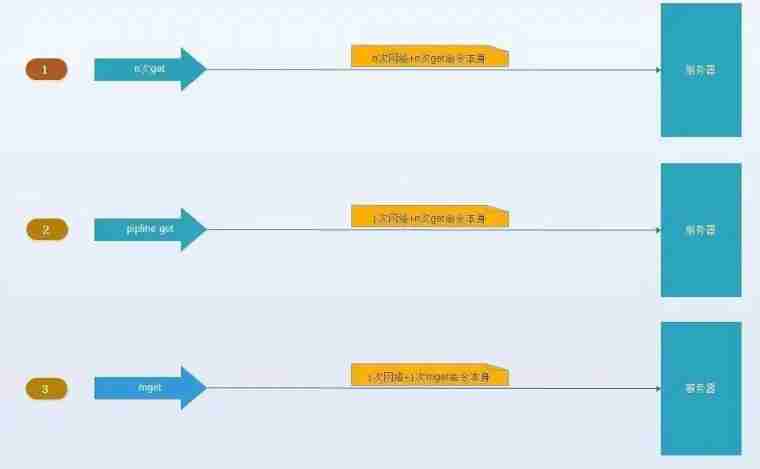
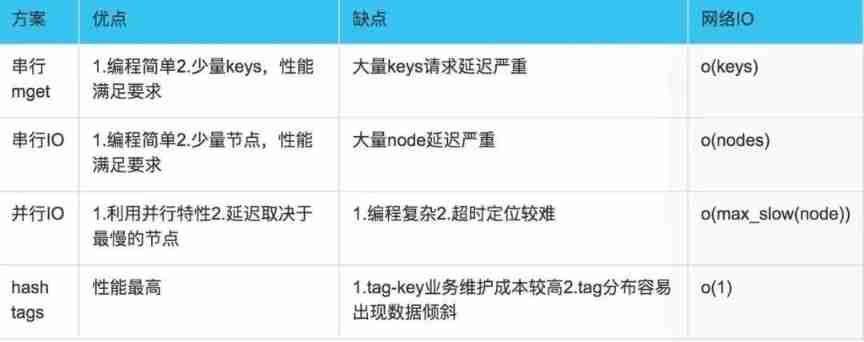
With mget There are four options :
(1). Serial mget
take mget operation (n individual key) Split into successive execution N Time get operation , Obviously, this operation has high time complexity , Its operating time =n Sub network time +n Time of the second order , The number of networks is n, Obviously this is not the best solution , But simple enough .
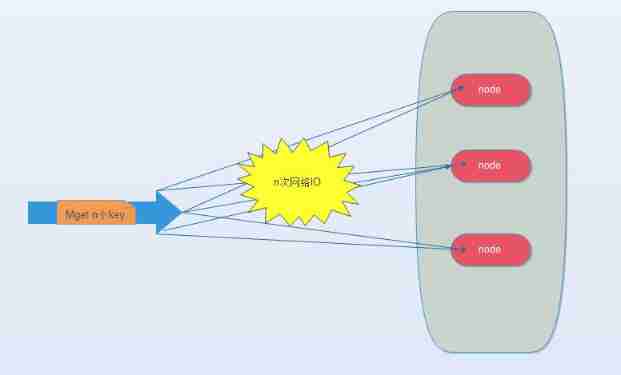
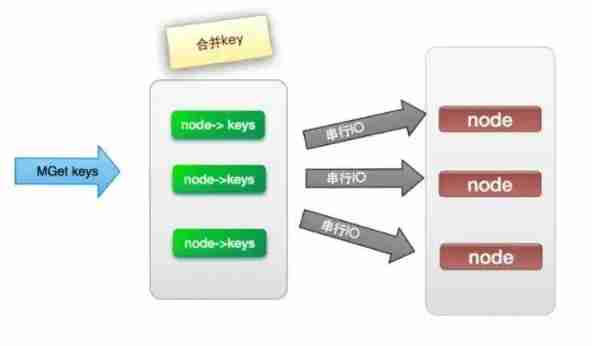
(2). Serial IO
take mget operation (n individual key), Using known hash Function calculation key Corresponding node , In this way, we can get such a relationship :Map, That is, some corresponding to each node keys
Its operating time =node Sub network time +n Time of the second order , The number of networks is node The number of , Obviously, this is a much better solution than the first one , But if there are enough nodes , There are still some performance problems .
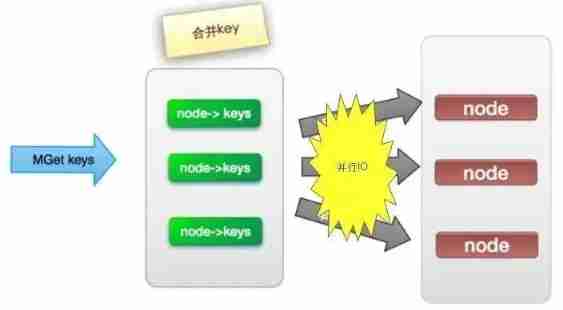
(3). parallel IO
This plan is to put the plan (2) The last step in , Change to multithreading , Although the number of networks is still nodes.size(), But network time becomes o(1), But this scheme will increase the complexity of programming .
Its operating time =1 Sub network time +n Time of the second order
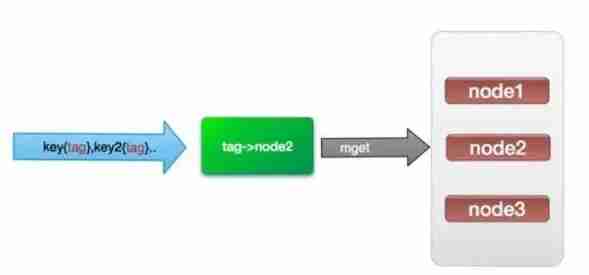
(4). hash-tag Realization .
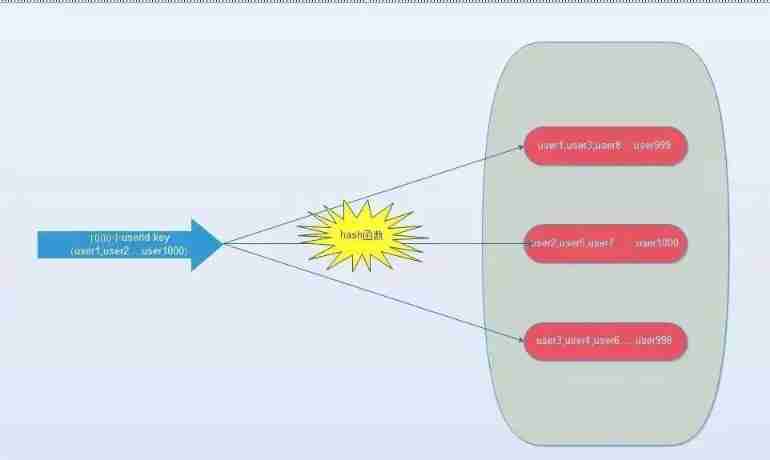
because hash Function will cause key Randomly assigned to each node , So is there a way to force some key To the specified node to the specified node ?
redis It provides such a function , be called hash-tag. What does that mean ? If we are using redis-cluster(10 individual redis Node composition ), We have 1000 individual k-v, Then according to the hash function (crc16) The rules , this 1000 individual key Will be scattered to 10 A node , So the time complexity is still the above (1)~(3)
So can we use a single machine redis equally , once IO Will all key Take it out ?hash-tag It provides such a function , If the above key To the following , That is, enclose the same content in curly braces , So these key It will go to a specified node .
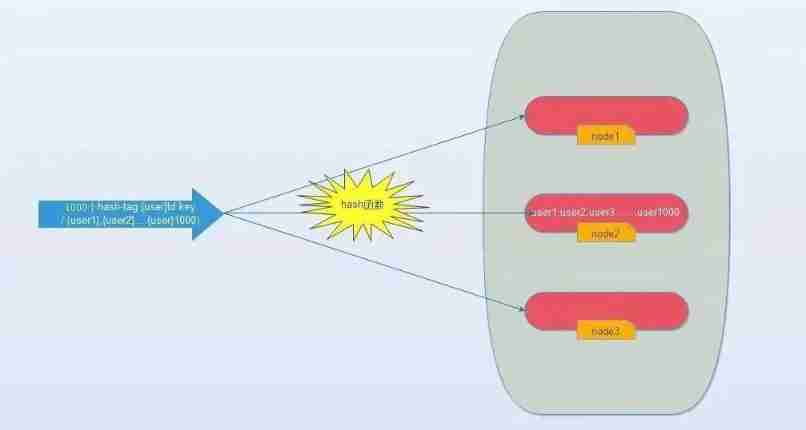
Its operating time =1 Sub network time +n Time of the second order
3. Comparison of four batch operation solutions :
About the bottomless hole optimization , For details, please refer to an article on concurrent programming network .
Mention it , Serial in production IO And parallel IO The plan , I have used , In fact, the effect is good . After all, nodes are limited , No FB、BAT There's so much traffic . parallel IO If you use java, also JDK8 Or more , Just turn on labmda Parallel flow can realize parallel IO 了 , It's convenient , Programming is not complicated , Timeout positioning , You can add more logs .
Avalanche optimization
Cache avalanche : Because the cache layer carries a lot of requests , Effectively protect the storage layer , But if the cache layer cannot provide services for some reason , So all the requests arrive at the storage layer , The number of calls to the storage layer will skyrocket , Conditions that cause cascading downtime of the storage tier . To prevent and solve the cache avalanche problem, we can start from the following aspects .
(1) Ensure high availability of cache layer services , For example, one master and many slaves ,Redis Sentine Mechanism .
(2) Rely on the isolation component to limit the flow to the back end and degrade , such as netflix Of hystrix. About current limiting 、 Downgrade and hystrix The technical design of can refer to the following links .
(3) Project resource isolation . Avoid the of a project bug, It affects the whole system architecture , Problems are also limited within the project .
hotspot key Reconstruction optimization
Used by developers " cache + Expiration time " To speed up reading and writing , And ensure the regular update of data , This model can basically meet most of the needs . But if there are two problems at the same time , May cause fatal injury to the application .
At present key It's a hot key, For example, hot entertainment news , The amount of concurrency is very large .
Rebuilding the cache cannot be done in a short time , It could be a complex calculation , For example, complicated SQL, many times IO, Multiple dependencies, etc .
When the cache fails , There will be a large number of threads to rebuild the cache , Cause the back-end load to increase , It should even break down . To solve this problem, there are the following solutions :
1、 The mutex
The specific approach is to allow only one thread to rebuild the cache , Other threads wait for the thread rebuilding the cache to finish executing , Get the data from the cache again . In this case , There is a risk that the reconstruction time is too long or the concurrency is too large , There will be a lot of thread blocking , It will also increase the system load . An optimization method : In addition to rebuilding threads , Other threads take the old value and return it directly . such as Google Of Guava Cache Of refreshAfterWrite This is the scheme adopted to avoid avalanche effect .
2、 Never expire
This is that the cache update operation is independent , It can be updated regularly by running regular tasks , Or take the initiative to update when changing data .
3、 Back end current limiting
The above two schemes are based on our prior knowledge hot key Under the circumstances , If we know in advance which are hot key Words , In fact, the problem is not very big . The problem is what we don't know ! since hot key The harm is that a large number of reconstruction requests fall to the back end , What if the backend does its own current limiting , Only part of the requests fell to the back end , All the others have been called back . One hot key As long as one reconstruction request is processed successfully , Subsequent requests go directly to the cache , The problem is solved .
So in the case of high concurrency , Back end current limiting is essential .
The above is my work on cache design 、 Some experience of using . If you like the article , You are welcome to like or pay attention .
source :zhuanlan.zhihu.com/p/55303228
recommend :
Main stream Java Advanced technology ( Learning material sharing )
PS: Because the official account platform changed the push rules. , If you don't want to miss the content , Remember to click after reading “ Looking at ”, Add one “ Star standard ”, In this way, each new article push will appear in your subscription list for the first time . spot “ Looking at ” Support us !
边栏推荐
- 2021 SASE integration strategic roadmap (I)
- MySQL learning notes (mind map)
- Leetcode(547)——省份数量
- Markov decision process
- If the college entrance examination goes well, I'm already graying out at the construction site at the moment
- How engineers treat open source -- the heartfelt words of an old engineer
- What is time
- Leecode brush question record sword finger offer 58 - ii Rotate string left
- stm32F407-------DAC数模转换
- Advanced learning of MySQL -- Fundamentals -- four characteristics of transactions
猜你喜欢

Core knowledge of distributed cache

Testers, how to prepare test data

沉浸式投影在线下展示中的三大应用特点
Win10 startup error, press F9 to enter how to repair?

The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge

48 page digital government smart government all in one solution
How to set encoding in idea
Basic information of mujoco
深度学习之环境配置 jupyter notebook
建立自己的网站(17)
随机推荐
Imeta | Chen Chengjie / Xia Rui of South China Agricultural University released a simple method of constructing Circos map by tbtools
Stm32f407 ------- DAC digital to analog conversion
深度学习之线性代数
The difference between redirectto and navigateto in uniapp
Attention SLAM:一種從人類注意中學習的視覺單目SLAM
【YoloV5 6.0|6.1 部署 TensorRT到torchserve】环境搭建|模型转换|engine模型部署(详细的packet文件编写方法)
【vulnhub】presidential1
[yolov5 6.0 | 6.1 deploy tensorrt to torch serve] environment construction | model transformation | engine model deployment (detailed packet file writing method)
[vector retrieval research series] product introduction
Stm32f407 ------- SPI communication
工程师如何对待开源 --- 一个老工程师的肺腑之言
Operation test of function test basis
Model-Free Control
Advanced learning of MySQL -- basics -- multi table query -- external connection
37 page overall planning and construction plan for digital Village revitalization of smart agriculture
Uniapp uploads and displays avatars locally, and converts avatars into Base64 format and stores them in MySQL database
Advanced learning of MySQL -- basics -- multi table query -- subquery
System activity monitor ISTAT menus 6.61 (1185) Chinese repair
Leecode brush questions record sword finger offer 44 A digit in a sequence of numbers
Notes of training courses selected by Massey school