当前位置:网站首页>强化学习基础记录
强化学习基础记录
2022-07-06 09:22:00 【喜欢库里的强化小白】
强化学习中Q-learning和Saras的对比
多智能体强化学习小白一枚,最近在学习强化学习基础,在此记录,以防忘记。
一、Q-learning
Q-learing最基础的强化学习算法,通过Q表存储状态-动作价值,即Q(s,a),可以用在状态空间较小的问题上,当状态空间维度很大时,需要配合神经网络,扩展成DQN算法,处理问题。
- Value-based
- Off-Policy
看了很多有关On-Policy和Off-Policy的博客,一直没太理解二者的区别,搞得一头雾水,前两天看了一个博主的回答,才有了更深入的理解,这里附上链接。
链接: on-policy和off-policy有什么区别?
当Q-learning更新时,虽然用到的数据是当前policy产生的,但是所更新的策略不是产生这些数据的策略(注意更新公式中的max),这里可以这样理解:这里的max操作是为了选取能够获得更大Q值的动作,更新Q表,但实际回合未必会采取改改动,所以是Off-Policy的。 - 伪代码

- 实现
这里用的环境是莫烦老师教程里的寻宝游戏,通过列表进行维护,—#-T,其中最后一个位置T是宝藏,#代表玩家现处的位置,走到最右格,发现宝藏,游戏结束。
代码实现参考了一个博主,找不到链接了。。。。。
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6个状态,一维数组长度
ACTIONS = [-1, 1] # 两个状态,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # 学习率
gamma = 0.9 # 奖励递减值
max_episodes = 10 # 最大回合数
fresh_time = 0.3 # 移动间隔时间
# q_table
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action: 1. 随机探索以及对于没有探索过的位置进行探索,否则选择reward最大的那个动作
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
#新状态 = 当前状态 + 移动状态
new_state = state + action
reward = 0
#右移加0.5
#往右移动,更靠近宝藏,获得+0.5奖励
if action > 0:
reward += 0.5
#往左移动,远离宝藏,获得-0.5奖励
if action < 0:
reward -= 0.5
#下一步到达宝藏,给予最高奖励+1
if new_state == N_STATES - 1:
reward += 1
#如果向左走到头,还要左移,获得最低负奖励-1
#同时注意,要定义一下新状态还在此,不然会报错
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# 达到目的地
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
def q_learning():
for epoch in range(max_episodes):
step = 0 # 移动步骤
state = 0 # 初始状态
update_env(state, epoch, step)
while state != N_STATES - 1:
cur_action = choose_action(state, q_table)
new_state, reward = get_env_feedback(state, cur_action)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, :].max()
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state = new_state
update_env(state, epoch, step)
step += 1
return q_table
q_learning()
二、Saras
Saras也是强化学习中最基础的算法,同时也是用Q表存储Q(s,a),这里之所以叫Saras,是因为一个transition包含(s,a,r,a,s)五元组,即Saras。
- Value-based
- On-Policy
这里对比Q-learning,我们便可知道,这里用到的数据是当前policy产生的,且更新Q值的时候,是基于新动作和新状态的Q值,新动作会被执行(注意更新公式中没有max),所以是On-Policy。 - 伪代码

- 实现
这里参考Q-learning做了简单修改,这里要基于新的状态,重新选择一次动作,而且要执行该动作,此外更新Q值的时候,直接基于该状态和动作对应的Q值更新。
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6个状态,一维数组长度
ACTIONS = [-1, 1] # 两个状态,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # 学习率
gamma = 0.9 # 奖励递减值
max_episodes = 10 # 最大回合数
fresh_time = 0.3 # 移动间隔时间
# q_table
#生成(N_STATES,len(ACTIONS)))的Q值空表
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action:
#0.9概率贪心,0.1概率随机选择动作,保持一定探索性
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
#新状态 = 当前状态 + 移动状态
new_state = state + action
reward = 0
#右移加0.5
#往右移动,更靠近宝藏,获得+0.5奖励
if action > 0:
reward += 0.5
#往左移动,远离宝藏,获得-0.5奖励
if action < 0:
reward -= 0.5
#下一步到达宝藏,给予最高奖励+1
if new_state == N_STATES - 1:
reward += 1
#如果向左走到头,还要左移,获得最低负奖励-1
#同时注意,要定义一下新状态还在此,不然会报错
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
#维护环境
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# 达到目的地
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
#更新Q表
def Saras():
for epoch in range(max_episodes):
step = 0 # 移动步骤
state = 0 # 初始状态
update_env(state, epoch, step)
cur_action = choose_action(state, q_table)
while state != N_STATES - 1:
new_state, reward = get_env_feedback(state, cur_action)
new_action = choose_action(new_state,q_table)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, new_action]
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state,cur_action = new_state,new_action
update_env(state, epoch, step)
step += 1
return q_table
Saras()
第一次写博客,可能理解存在问题,还望指正错误。
边栏推荐
- 为什么要使用Redis
- [graduation season · advanced technology Er] goodbye, my student days
- 【黑马早报】上海市监局回应钟薛高烧不化;麦趣尔承认两批次纯牛奶不合格;微信内测一个手机可注册俩号;度小满回应存款变理财产品...
- 1. First knowledge of C language (1)
- C language to achieve mine sweeping game (full version)
- 7-6 矩阵的局部极小值(PTA程序设计)
- Change vs theme and set background picture
- [面試時]——我如何講清楚TCP實現可靠傳輸的機制
- Canvas foundation 1 - draw a straight line (easy to understand)
- 扑克牌游戏程序——人机对抗
猜你喜欢
Programme de jeu de cartes - confrontation homme - machine
附加简化版示例数据库到SqlServer数据库实例中
记一次猫舍由外到内的渗透撞库操作提取-flag
![[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission](/img/d6/109042b77de2f3cfbf866b24e89a45.png)
[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
Record a penetration of the cat shed from outside to inside. Library operation extraction flag
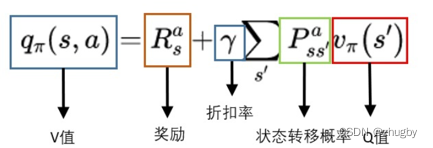
强化学习系列(一):基本原理和概念
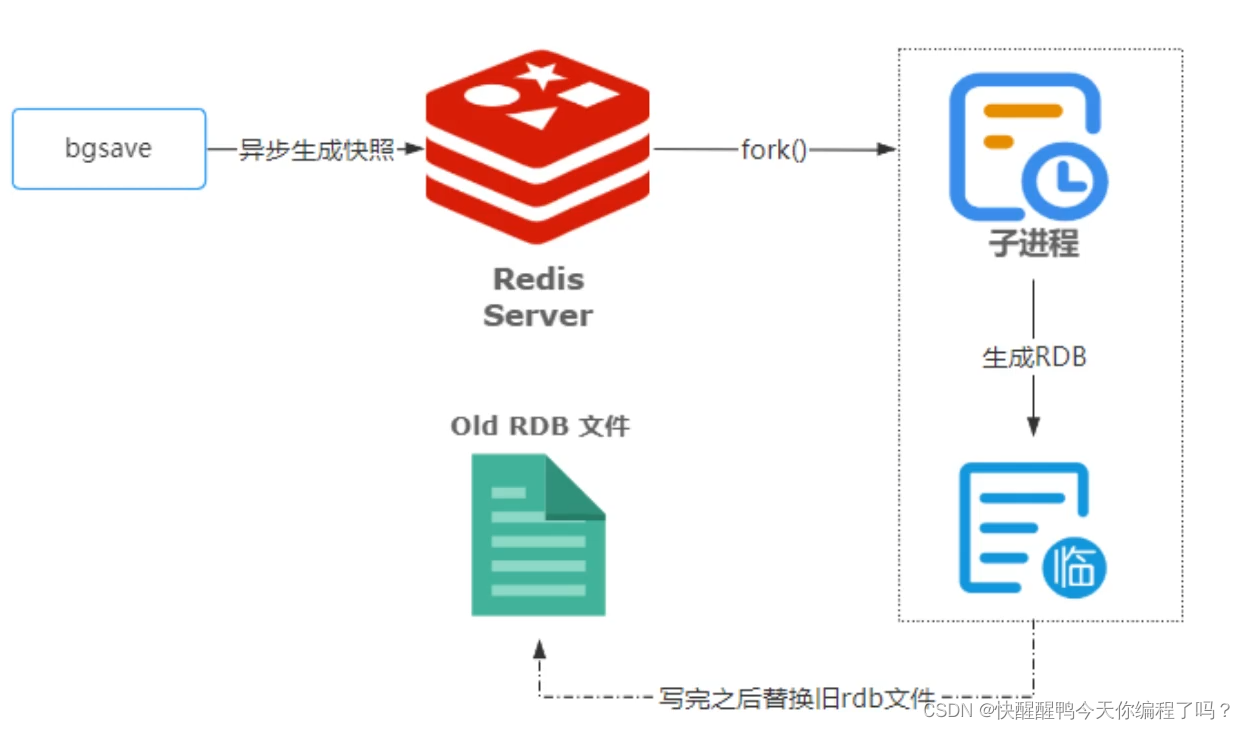
Principles, advantages and disadvantages of two persistence mechanisms RDB and AOF of redis

canvas基础2 - arc - 画弧线
Redis的两种持久化机制RDB和AOF的原理和优缺点
C语言入门指南
随机推荐
8. C language - bit operator and displacement operator
The latest tank battle 2022 full development notes-1
【头歌educoder数据表中数据的插入、修改和删除】
扑克牌游戏程序——人机对抗
【九阳神功】2019复旦大学应用统计真题+解析
Simply understand the promise of ES6
7-5 走楼梯升级版(PTA程序设计)
JS several ways to judge whether an object is an array
力扣152题乘数最大子数组
Implementation of count (*) in MySQL
7-7 7003 组合锁(PTA程序设计)
透彻理解LRU算法——详解力扣146题及Redis中LRU缓存淘汰
Canvas foundation 1 - draw a straight line (easy to understand)
5. Download and use of MSDN
Poker game program - man machine confrontation
【数据库 三大范式】一看就懂
自定义RPC项目——常见问题及详解(注册中心)
Programme de jeu de cartes - confrontation homme - machine
Record a penetration of the cat shed from outside to inside. Library operation extraction flag
Differences among fianl, finally, and finalize