当前位置:网站首页>AI遮天传 ML-回归分析入门
AI遮天传 ML-回归分析入门
2022-07-07 23:10:00 【老师我作业忘带了】

相信大家初高中都学习过求解回归线方程,大学概率论的第九章也有讲,忘记了也不要紧,这里简单回忆一下:
线性回归方程为:
我们可以先求出x、y的均值:

对于系数
:
对于系数
:



 :
: 
 :
: 
例:已知x、y之间的一组数据:
| x | 0 | 1 | 2 | 3 |
| y | 1 | 3 | 5 | 7 |
求y与x的回归方程:
答案 : 其实连起来就是一条线段
其实连起来就是一条线段
一、什么是回归分析
Regression
回归分析我们通常叫做 Regression ,它其实是一大类方法。我们之前了解到的Predicition它即包括了Regression也包括了Classification,即回归和分类。像是决策树适合的离散型输出,我们一般叫做分类;而对于连续型输出的问题,比如用户的满意度、一个家庭一年的开销或者是用户星级的评价、用户的点击又或是一些概率等等,就要用到这次介绍的Regression方法。
回归分析是描述变量间关系的一种统计分析方法
• 例:在线教育场景
• 因变量 Y:在线学习课程满意度
• 自变量 X:平台交互性、教学资源、课程设计
• 预测性的建模技术,通常用于预测分析
• 预测的结果多为连续值(但也可以是离散值,甚至是二值)
二、简单线性回归
线性回归 (Linear regression)
因变量和自变量之间是线性关系,就可以使用线性回归来建模

线性回归的目的即找到最能匹配(解释)数据的截距和斜率
- 有些变量间的线性关系是确定性的
| x | 1 | 2 | 3 | 4 | 5 | 6 |
| y | 3 | 5 | 7 | 9 | 11 | 13 |

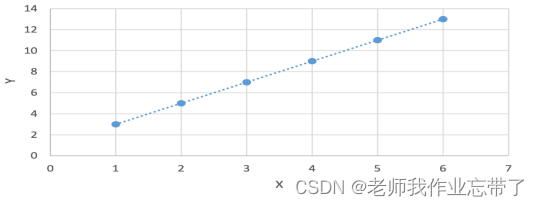
所以当 x=7时,我们预测为15.
- 然而通常情况下,变量间是近似的线性关系
| x | 1 | 2 | 3 | 4 | 5 | 6 |
| y | 3 | 2 | 8 | 8 | 11 | 13 |
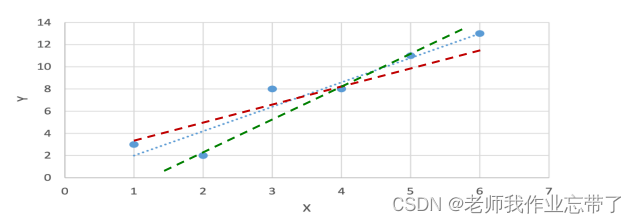
我们要解决的问题就是如何得到一条直线能够最好地解释数据?
拟合数据
- 假设只有一个因变量和自变量,每个训练样例表示 (𝑥𝑖 , 𝑦𝑖)
- 用
 表示根据拟合直线和 x𝑖 对 𝑦𝑖 的预测值:
表示根据拟合直线和 x𝑖 对 𝑦𝑖 的预测值: 
- 定义
 为误差项/残差
为误差项/残差
 表示根据拟合直线和 x𝑖 对 𝑦𝑖 的预测值:
表示根据拟合直线和 x𝑖 对 𝑦𝑖 的预测值: 
 为
为这里引入了一个新的定义:误差项,它是用样本的真实值减去样本的估计值。
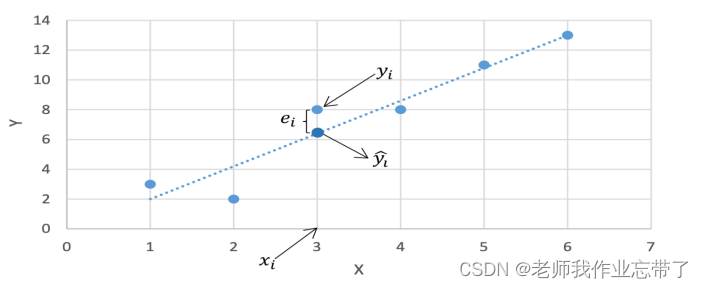
我们的目标就是得到一条直线使得对于所有训练样例的误差项尽可能小
线性回归的基本假设
我们假设:
- 假设自变量与因变量间存在线性关系
- 数据点之间独立
输出结果y1,y2,y3...没有关系
- 自变量之间无共线性,相互独立
对于走路累不累:如果特征是 伞 和 书包 伞和书包这两个变量没什么关系
如果是 天气 伞 书包 则 天气 和 伞 我们认为并不是相互独立的
- 残差独立、等方差、符合正态分布
error独立、等方差(面对同一个问题,也是同分布的)
根据中心极限定理:设从均值为μ、方差为σ^2;(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ^2/n 的正态分布。
三、损失函数(loss function)的定义
多种损失函数都是可行的,凭直觉就可以想到:
- 所有误差项的加和
- 所有误差项绝对值的加和
考虑到优化等问题,最常用的是基于误差平方和的损失函数

• 用误差平方和作为损失函数有很多优点
• 损失函数是严格的凸函数,有唯一解
• 求解过程简单且容易计算
• 同时也伴随着一些缺点
• 结果对数据中的“离群点”(outlier)非常敏感
• 解决方法:提前检测离群点并去除
• 损失函数对于超过和低于真实值的预测是等价的
• 但有些真实情况下二者带来的影响是不同的
我们需要求出合适的参数b1、b2使得误差平方和最小。
最小二乘法(Least Square, LS)
为了求解最优的截距和斜率,可以转化为一个针对损失函数的 凸优化问题,称为最小二乘法:
我们分别对b1、b2求偏导:

这就是我们文章最开始回忆的线性回归方程,我们使用时当然不用去求偏导了,直接用。
梯度下降法(Gradient Descent, GD)
除了最小二乘法,还可以用基于梯度的方法迭代更新截距和斜率:
- 可以随机先初始化 𝑏1, 𝑏2
- 重复:




有了初始化的一组b1、b2,我们就可以得到对应比如样本1的误差项error1,基于误差项去更新b,b=b-a,其中a是系数的更新(和误差有关的函数,比如0.1*error),这样就有了新的b1、b2,用样本2的误差项error2求出a不断更新迭代... 直到收敛。
四、多元线性回归(Multiple Linear Regression)
当因变量有多个时,我们可以用矩阵方式表达
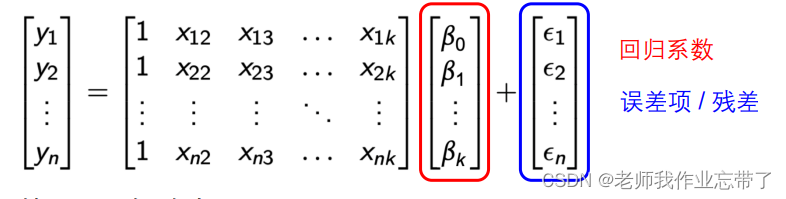
基于以上矩阵表示,可以写为

此时:
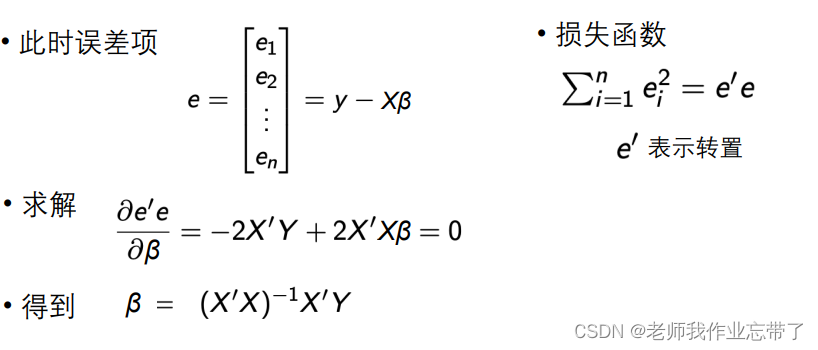
注:
- 矩阵X的第一列都是1,其与β相乘表示截距。
- 损失函数结果还是数字
- 通过最小二乘法得到求解β的公式:



例如:
记录了 25 个家庭每年在快销品和日常服务
- 总开销(𝑌)
- 每年固定收入( 𝑋2)、持有的流动资产( 𝑋3)
可以构建如下线性回归模型:

五、线性回归的相协方差、关系数、决定系数
协方差:协方差,描述两个变量 X 和 Y 的线性相关程度
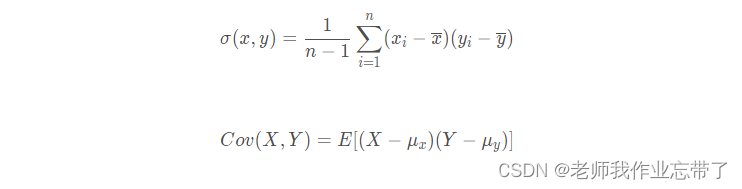
相关系数:取值区间[-1,1]
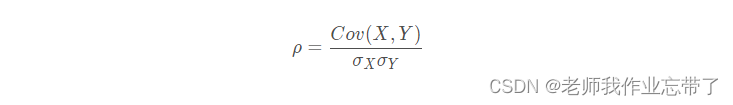
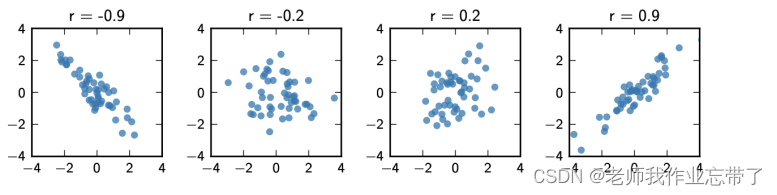
如:
决定系数:决定系数  ,也称作判定系数、拟合优度
,也称作判定系数、拟合优度


注意:有可能小于0,它不是一个数的平方。
衡量了模型对数据的解释程度
- y的波动有多少百分比能被x的波动所描述
- 𝑅 2越接近1,表示回归分析中自变量对因变量的解释越好
特别注意:变量相关 ≠ 存在因果关系
基于回归分析的世界大学综合得分预测
大学排名是一个非常重要同时也极富挑战性与争议性的问题,一所大学的综合实力涉及科研、师资、学生等方方面面。目前全球有上百家评估机构会评估大学的综合得分进行排序,而这些机构的打分也往往并不一致。在这些评分机构中,世界大学排名中心(Center for World University Rankings,缩写CWUR)以评估教育质量、校友就业、研究成果和引用,而非依赖于调查和大学所提交的数据著称,是非常有影响力的一个。
本任务中我们将根据 CWUR 所提供的世界各地知名大学各方面的排名(师资、科研等),一方面通过数据可视化的方式观察不同大学的特点,另一方面希望构建机器学习模型(线性回归)预测一所大学的综合得分。
数据来源:World University Rankings | Kaggle
数据观察与处理:
import pandas as pd
import numpy as np
data_df = pd.read_csv('./cwurData.csv')
data_df.head(3).T # 观察前几列并转置方便观察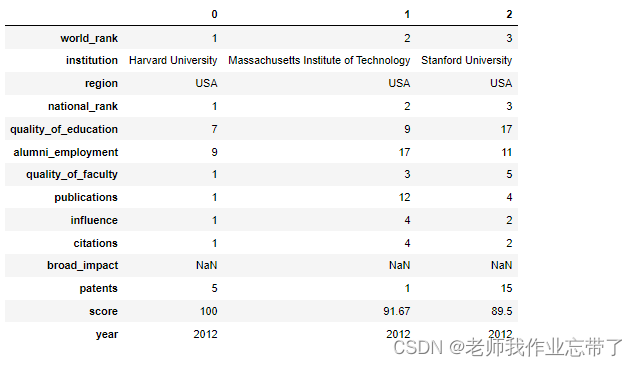
去除其中包含 NaN 的数据
data_df = data_df.dropna()
len(data_df) # 2000设置矩阵
feature_cols = ['quality_of_faculty', 'publications', 'citations', 'alumni_employment',
'influence', 'quality_of_education', 'broad_impact', 'patents'] # 提取特征值
X = data_df[feature_cols]
Y = data_df['score']
# X Y分别为自变量 因变量矩阵数据可视化
观察世界排名前十学校的平均得分情况,为此需要将同一学校不同年份的得分做一个平均。我们可以利用groupby()函数,将同一学校的记录整合起来并通过mean()函数取平均。之后我们按平均分降序排序,取前十个学校作为要观察的数据。
import matplotlib.pyplot as plt
import seaborn as sns
mean_df = data_df.groupby('institution').mean() # 按学校聚合并对聚合的列取平均
top_df = mean_df.sort_values(by='score', ascending=False).head(10) # 取前十学校
sns.set()
x = top_df['score'].values # 综合得分列表
y = top_df.index.values # 学校名称列表
sns.barplot(x, y, orient='h', palette="Blues_d") # 画条形图
plt.xlim(75, 101) # 限制 x 轴范围
plt.show()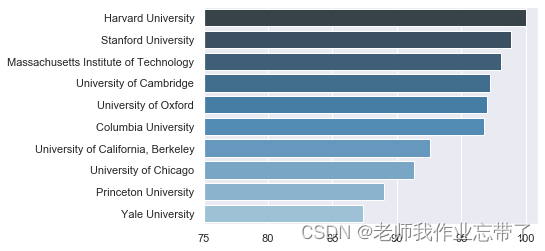
用pairplot的方法观察变量之间的关联关系,可以从图中看到,少部分变量之间有线性关系;各个变量和结果之间,近似对数关系。
sns.pairplot(data_df[feature_cols + ['score']], height=3, diag_kind="kde")
plt.show()
还可以用热力图的形式呈现相关度矩阵:
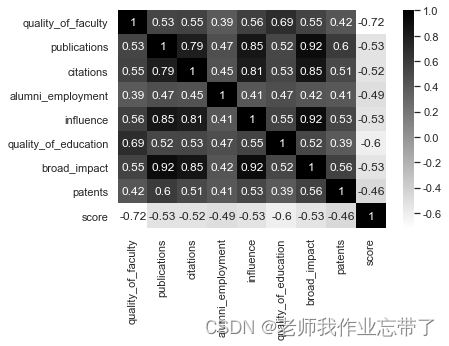
构建模型
取出对应自变量以及因变量的列,之后就可以基于此切分训练集和测试集,并进行模型构建与分析。
all_y = data_df['score'].values
all_x = data_df[feature_cols].values
# 取 values 是为了从 pandas 的 Series 转成 numpy 的 array
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.2, random_state=2020)
all_y.shape, all_x.shape, x_train.shape, x_test.shape, y_train.shape, y_test.shape # 输出数据行列信息
# ((2000,), (2000, 8), (1600, 8), (400, 8), (1600,), (400,))from sklearn.linear_model import LinearRegression
LR = LinearRegression() # 线性回归模型
LR.fit(x_train, y_train) # 在训练集上训练
p_test = LR.predict(x_test) # 在测试集上预测,获得预测值
test_error = p_test - y_test # 预测误差
test_rmse = (test_error**2).mean()**0.5 # 计算 RMSE
'rmse: {:.4}'.format(test_rmse)
# rmse: 3.999得到测试集的 RMSE 为 3.999,在百分制的预测目标下算一个尚可的结果。从评价指标上看貌似我们能根据各方面排名较好的预估综合得分,接下来我们观察一下学习到的参数,即各指标排名对综合得分的影响权重。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
sns.barplot(x=LR.coef_, y=feature_cols)
plt.show()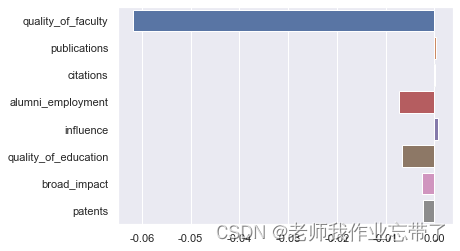
这里会发现综合得分的预测基本被「师资质量」这一自变量主导了,「就业」和「教育质量」这两个因素也有一定影响,其他指标起的作用就很小了。
为了观察「师资质量」这一主导因素与综合得分的关系,我们可以通过 seaborn 中的regplot()函数以散点图的方式画出其分布。
sns.regplot(data_df['quality_of_faculty'], data_df['score'], marker="+")
plt.show()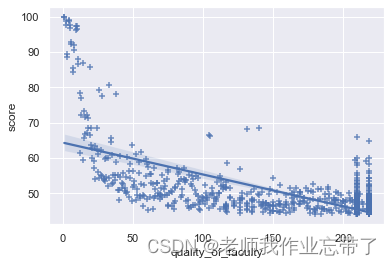
边栏推荐
- Interface test advanced interface script use - apipost (pre / post execution script)
- 3 years of experience, can't you get 20K for the interview and test post? Such a hole?
- The method of server defense against DDoS, Hangzhou advanced anti DDoS IP section 103.219.39 x
- RPA cloud computer, let RPA out of the box with unlimited computing power?
- ReentrantLock 公平锁源码 第0篇
- Letcode43: string multiplication
- Prompt configure: error: required tool not found: libtool solution when configuring and installing crosstool ng tool
- 【愚公系列】2022年7月 Go教学课程 006-自动推导类型和输入输出
- Is it safe to open an account on the official website of Huatai Securities?
- NTT template for Tourism
猜你喜欢

【测试面试题】页面很卡的原因分析及解决方案
Fofa attack and defense challenge record
基于微信小程序开发的我最在行的小游戏

RPA cloud computer, let RPA out of the box with unlimited computing power?
fabulous! How does idea open multiple projects in a single window?
Service mesh introduction, istio overview
![[note] common combined filter circuit](/img/2f/a8c2ef0d76dd7a45b50a64a928a9c8.png)
[note] common combined filter circuit

Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
【愚公系列】2022年7月 Go教学课程 006-自动推导类型和输入输出

Codeforces Round #804 (Div. 2)(A~D)
随机推荐
SDNU_ACM_ICPC_2022_Summer_Practice(1~2)
【obs】官方是配置USE_GPU_PRIORITY 效果为TRUE的
Introduction to paddle - using lenet to realize image classification method I in MNIST
Marubeni official website applet configuration tutorial is coming (with detailed steps)
从服务器到云托管,到底经历了什么?
Basic types of 100 questions for basic grammar of Niuke
Qt不同类之间建立信号槽,并传递参数
Analysis of 8 classic C language pointer written test questions
【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
CVE-2022-28346:Django SQL注入漏洞
[OBS] the official configuration is use_ GPU_ Priority effect is true
Is it safe to open an account on the official website of Huatai Securities?
浪潮云溪分布式数据库 Tracing(二)—— 源码解析
5G NR 系统消息
Stock account opening is free of charge. Is it safe to open an account on your mobile phone
Summary of weidongshan phase II course content
他们齐聚 2022 ECUG Con,只为「中国技术力量」
韦东山第二期课程内容概要
Su embedded training - day4
爬虫实战(八):爬表情包