当前位置:网站首页>Mysql27 - Optimisation des index et des requêtes
Mysql27 - Optimisation des index et des requêtes
2022-07-06 10:29:00 【Protégez - nous, Yao.】
Un.. Préparation des données
Tableau des participants Insérer 50(En milliers de dollars des États - Unis) Article (s), Liste des classes Insérer 1(En milliers de dollars des États - Unis) Article (s).
1.1. Construction de montres
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1.2. Définir les paramètres
Commande activée:Autoriser la création de paramètres de fonction:
set global log_bin_trust_function_creators=1; # Non.globalSeulement la fenêtre actuelle est valide.
1.3. Créer une fonction
Assurez - vous que chaque donnée est différente.
#Chaîne générée au hasard
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#Si vous voulez supprimer
#drop function rand_string;
Générer des numéros de classe au hasard
#Nombre de nombres générés au hasard
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#Si vous voulez supprimer
#drop function rand_num;
1.4. Créer une procédure stockée
Créer versclassProcédure stockée pour insérer des données dans un tableau
#Exécuter la procédure stockée,Allez.classTableau ajouter des données aléatoires
DELIMITER //
CREATE PROCEDURE `insert_class`( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#Si vous voulez supprimer
#drop PROCEDURE insert_class;
1.5. Procédure stockée d'appel
class
#Exécuter la procédure stockée,Allez.classAjout de tableaux110 000 données
CALL insert_class(10000);
stu
#Exécuter la procédure stockée,Allez.stuAjout de tableaux5010 000 données
CALL insert_stu(100000,500000);
1.6. Supprimer un index sur une table
Créer une procédure stockée
DELIMITER //
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>'PRIMARY' ;
# Chaque curseur doit utiliser un declare continue handler for not found set done=1 Pour contrôler la fin du curseur
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#Si aucune donnée n'est retournée,La procédure se poursuit,Et mettre la variabledoneSet to2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
Exécuter la procédure stockée
CALL proc_drop_index("dbname","tablename");
2.. Cas de défaillance de l'index
2.1. Correspondance complète
2.2. Meilleure règle du préfixe gauche
Développement:Alibaba《JavaManuel de développement》
Le fichier index a B-Tree Propriétés de correspondance du préfixe le plus à gauche pour,Si la valeur à gauche n'est pas déterminée,Cet index ne peut pas être utilisé.
2.3. Séquence d'insertion de la clé primaire

Si une autre clé primaire est insérée à ce stade 9 Les dossiers de,Il est inséré dans la figure suivante: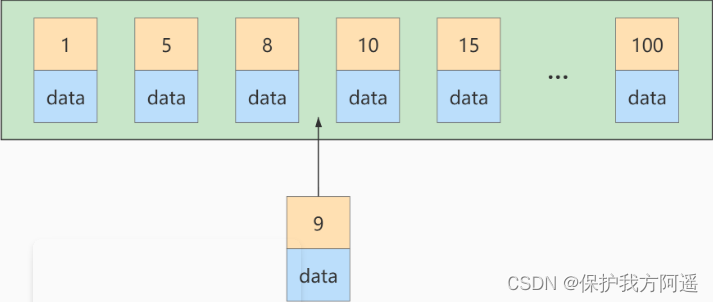
Mais cette page de données est pleine , Et s'il y en avait d'autres? ? Nous devons mettre Page divisée En deux pages , Déplacer certains enregistrements de cette page vers cette page nouvellement créée . Qu'est - ce que la séparation des pages et le déplacement des enregistrements signifient ?Ce qui signifie: Perte de performance ! Donc si nous essayons d'éviter une telle perte de performance inutile , Il est préférable que l'enregistrement inséré La valeur de la clé primaire augmente successivement ,Pour éviter une telle perte de performance. Nous suggérons donc :Laisser la clé primaire avoir AUTO_INCREMENT ,Laissez le moteur de stockage générer sa propre clé primaire pour la table,Au lieu d'insérer manuellement ,Par exemple,: person_info Tableau:
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
Nos colonnes de clés primaires personnalisées id Propriété AUTO_INCREMENT Propriétés, Le moteur de stockage remplit automatiquement la valeur de la clé primaire auto - incrémentale pour nous lors de l'insertion de l'enregistrement . Une telle clé primaire prend peu d'espace ,Écrire séquentiellement,Réduire la fragmentation des pages.
2.4. Calcul、Fonctions、Conversion de type(Automatique ou manuel)Invalider l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
Créer un index
CREATE INDEX idx_name ON student(NAME);
Première catégorie: Efficacité de l'optimisation de l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';

Deuxième type: Échec de l'optimisation de l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';

typePour“ALL”,Indique que l'index n'est pas utilisé.
Encore un exemple:
- studentChamps du tableaustuno Index défini sur .
CREATE INDEX idx_sno ON student(stuno);
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;

- Efficacité de l'optimisation de l'index
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;

Encore un exemple:
3. studentChamps du tableauname Index défini sur
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT id, stuno, name FROM student WHERE SUBSTRING(name, 1,3)='abc';

EXPLAIN SELECT id, stuno, NAME FROM student WHERE NAME LIKE 'abc%';

2.5. La conversion de type entraîne l'invalidation de l'index
Lequel des éléments suivantssql L'instruction peut utiliser l'index .(Hypothèsesname Index défini sur le champ )
name=123Une conversion de type s'est produite,Échec de l'index.
Non utilisé dans l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
# Utiliser pour indexer
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name='123';
2.6. Défaillance de l'index de colonne à droite de l'état de la plage
ALTER TABLE student DROP INDEX idx_name;
ALTER TABLE student DROP INDEX idx_age;
ALTER TABLE student DROP INDEX idx_age_classid;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ;
create index idx_age_name_classid on student(age,name,classid);
- Placer les critères de requête scope à la fin de l'instruction :
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name =
'abc' AND student.classId>20 ;

2.7. Pas égal à(!= Ou<>)Échec de l'index
2.8. is nullVous pouvez utiliser l'index,is not nullImpossible d'utiliser l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
2.9. likeComme Joker%Échec de l'index de départ
Développement:Alibaba《JavaManuel de développement》
【Obligatoire】La recherche de page ne doit pas être floue à gauche ou complètement floue,Si vous avez besoin d'un moteur de recherche pour résoudre.
2.10. OR Colonnes non indexées avant et après,Échec de l'index
# Non utilisé dans l'index
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
#Utiliser pour indexer
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR name = 'Abel';
2.11. Les Jeux de caractères de la base de données et de la table sont utilisés uniformémentutf8mb4
Utilisation uniformeutf8mb4( 5.5.3Prise en charge de plus de)Meilleure compatibilité,Un jeu de caractères uniforme évite le brouillage causé par la conversion d'un jeu de caractères.Différent Jeu de caractères Doit être effectué avant la comparaison Conversion Invalidera l'index .
Trois. Optimisation des requêtes associées
3.1. Préparation des données
#Classification
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
#Les livres
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
#Ajouter20Enregistrement (s)
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO `type`(card) VALUES(FLOOR(1 + (RAND() * 20)));
#Ajouter à la liste des livres20Enregistrement (s)
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
3.2. Connexion extérieure gauche
Ça commence EXPLAIN Analyse
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 Conclusions:type Oui.All
Conclusions:type Oui.All
Ajouter une optimisation d'index
ALTER TABLE book ADD INDEX Y ( card); #【Table entraînée】,Le balayage complet de la table peut être évité
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
 Vous pouvez voir la deuxième ligne type Ça devient ref,rows C'est devenu une optimisation plus évidente.Ceci est déterminé par la propriété de connexion gauche.LEFT JOINLes critères sont utilisés pour déterminer comment rechercher les lignes du tableau de droite,Il doit y en avoir à gauche.,Alors... À droite, c'est notre clé.,Un index doit être établi.
Vous pouvez voir la deuxième ligne type Ça devient ref,rows C'est devenu une optimisation plus évidente.Ceci est déterminé par la propriété de connexion gauche.LEFT JOINLes critères sont utilisés pour déterminer comment rechercher les lignes du tableau de droite,Il doit y en avoir à gauche.,Alors... À droite, c'est notre clé.,Un index doit être établi.
ALTER TABLE `type` ADD INDEX X (card); #【Tableau d'entraînement】, Impossible d'éviter un balayage complet de la table
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

Et voilà.:
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;

3.3. Avec connexion interne
drop index X on type;
drop index Y on book;( Si elle a été supprimée, vous n'avez plus besoin d'effectuer l'opération )
Remplacer par inner join(MySQLSélection automatique de la table d'entraînement)
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 Ajouter une optimisation d'index
Ajouter une optimisation d'index
ALTER TABLE book ADD INDEX Y ( card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;

ALTER TABLE type ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
 Et voilà.:
Et voilà.:
DROP INDEX X ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
 Et voilà.:
Et voilà.:
ALTER TABLE `type` ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` INNER JOIN book ON type.card=book.card;

3.4. joinPrincipe de la Déclaration
Index Nested-Loop Join
CREATE TABLE `t2` (
`id` INT(11) NOT NULL,
`a` INT(11) DEFAULT NULL,
`b` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
INDEX `a` (`a`)
) ENGINE=INNODB;
DELIMITER //
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE(i<=1000)DO
INSERT INTO t2 VALUES(i, i, i);
SET i=i+1;
END WHILE;
END //
DELIMITER ;
CALL idata();
#Créationt1 Tableau et copie t1Avant dans le tableau100Données
CREATE TABLE t1
AS
SELECT * FROM t2
WHERE id <= 100;
#Données de la feuille d'essai
SELECT COUNT(*) FROM t1;
SELECT COUNT(*) FROM t2;
#Voir l'index
SHOW INDEX FROM t2;
SHOW INDEX FROM t1;
Regardons cette déclaration:
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);
Si utilisé directementjoinDéclarations,MySQLL'optimiseur peut sélectionner une tablet1Out2Comme tableau d'entraînement,Cela nous affecte dans notre analyseSQLProcédure d'exécution de l'instruction.Alors...,Pour faciliter l'analyse des problèmes de rendement pendant l'exécution,Je suis passé à straight_join JeanMySQLExécuter la requête en utilisant une connexion fixe,De cette façon, l'optimiseur n'ira que comme nous l'avons spécifiéjoin.Dans cette déclaration,t1 C'est la table d'entraînement.,t2Est la table entraînée.
Je vois.,Dans cette déclaration,Table entraînéet2Champs pouraIndex sur,joinLe processus utilise cet index,Le processus d'exécution de cette instruction est donc le suivant:
- De la tablet1Lire une ligne de données R;
- De la ligne de donnéesRMoyenne,Enlevez - le.aChamp à tableaut2Pour trouver;
- Tableau de retraitt2Lignes répondant aux critères,Suivez - moi.RFormer une ligne,Dans le cadre de l'ensemble de résultats;
- Répéter les étapes1À3,Jusqu'au tableaut1Fin du cycle.
Ce processus consiste à traverser la table en premiert1,Puis selon le tableau suivantt1Dans chaque ligne de données extraite deaValeur,Va voir.t2Trouver des enregistrements qualifiés dans.Officiellement,Ce processus est similaire aux requêtes imbriquées que nous avons écrites,Et peut utiliser l'index de la table entraînée,C'est pourquoi nous l'appelons“Index Nested-Loop Join”,AbréviationsNLJ.
L'organigramme correspondant est le suivant::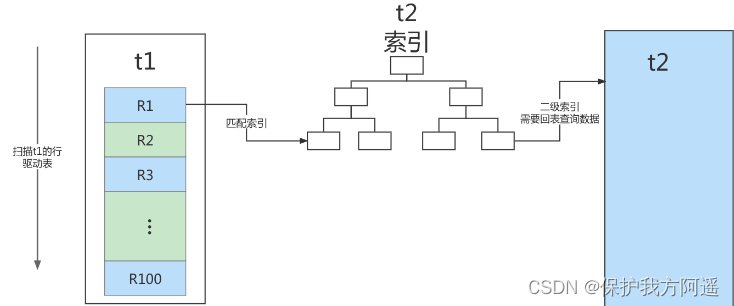
Dans ce processus: - Compteur d'entraînementt1J'ai fait un scan complet.,Ce processus nécessite un balayage100D'accord;
- Et pour chaque ligneR,SelonaChamp à tablet2Trouver,C'est le processus de recherche de l'arbre..Parce que les données que nous construisons correspondent une par une,Donc chaque recherche ne scanne qu'une seule ligne,C'est un total de scans.100D'accord;
- Alors...,Tout le processus d'exécution,Le nombre total de lignes numérisées est200.
3.5. Résumé
- Garantie de la table entraînéeJOINLe champ a été indexé.
- BesoinJOIN Champs pour,Les types de données sont absolument cohérents.
- LEFT JOIN Heure,Sélectionnez la petite table comme table d'entraînement, Grande montre comme une montre entraînée .Réduire le nombre de cycles externes.
- INNER JOIN Heure,MySQLVa automatiquement La table du petit ensemble de résultats est sélectionnée comme table d'entraînement .Choisir de croireMySQLOptimiser la stratégie.
- Peut être directement associé à plusieurs tables aussi directement que possible,Pas de sous - Requête.(Réduire le nombre de requêtes).
- Les sous - requêtes ne sont pas recommandées,Sous - Requête recommandéeSQLRequête multiple de Split Union,Ou utiliser JOIN Pour remplacer les sous - Requêtes.
- Les tables dérivées ne peuvent pas être indexées
Quatre. Optimisation des sous - requêtes
MySQLDe4.1La version commence à prendre en charge les sous - requêtes,Utilisez la Sous - requête pour faireSELECTRequêtes imbriquées pour les déclarations,UnSELECTLe résultat de la requête est un autreSELECTConditions de déclaration. Les sous - requêtes peuvent être complétées en plusieurs étapes logiques à la foisSQLFonctionnement .
La Sous - requête est MySQL Une fonction importante de,Peut nous aider à passer par un SQL Les déclarations implémentent des requêtes plus complexes.Mais, Exécution inefficace des sous - requêtes .Raisons:
① Lors de l'exécution d'une sous - Requête,MySQLRésultats de la requête pour l'instruction de requête interne requise Créer une table temporaire ,Ensuite, l'instruction de requête externe interroge l'enregistrement à partir de la table temporaire.Une fois la requête terminée,Encore. Annulation de ces tableaux provisoires .Ça consomme tropCPUEtIORessources,Générer beaucoup de requêtes lentes.
② Table temporaire stockée dans l'ensemble de résultats de la Sous - Requête,Qu'il s'agisse d'une table temporaire de mémoire ou d'une table temporaire de disque Aucun index n'existe ,Donc la performance de la requête sera affectée dans une certaine mesure.
③ Pour les sous - requêtes qui renvoient de grands ensembles de résultats,Plus l'impact sur la performance de la requête est grand.
InMySQLMoyenne,Connexion disponible(JOIN)Requête pour remplacer la Sous - Requête.Requête de connexion Il n'est pas nécessaire d'établir un tableau provisoire ,Le Plus rapide que les sous - requêtes ,Si l'index est utilisé dans la requête,La performance sera meilleure.
Conclusions:Essayez de ne pas utiliserNOT IN Ou NOT EXISTS,AvecLEFT JOIN xxx ON xx WHERE xx IS NULLSubstitution
Cinq. Optimisation du tri
5.1. Optimisation du tri
Questions:In WHERE Champ de condition indexé,Mais pourquoi? ORDER BY Il y a encore des citations de Picasso sur le champ?
Conseils d'optimisation:
- SQL Moyenne,Ça pourrait être dans WHERE Clauses et ORDER BY Utilisation de l'index dans les clauses,Le but est de WHERE Dans la clause Évitez le balayage complet de la table ,In ORDER BY Clause Ne pas utiliser FileSort Trier .Bien sûr.,Dans certains cas, un balayage complet de la table,Ou FileSort Le tri n'est pas nécessairement plus lent que l'index.Mais dans l'ensemble,Nous devons quand même éviter,Pour améliorer l'efficacité des requêtes.
- Utiliser autant que possible Index Terminé. ORDER BY Trier.Si WHERE Et ORDER BY Les mêmes colonnes sont suivies d'une seule colonne index;Utilisez l'index fédéré si différent.
- Impossible d'utiliser Index Heure,Oui. FileSort Méthode de réglage.
INDEX a_b_c(a,b,c)
order by Peut utiliser le préfixe le plus à gauche de l'index
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
SiWHERELe préfixe le plus à gauche de l'index est défini comme une constante,Etorder by Accès à l'index
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b = const ORDER BY c
- WHERE a = const ORDER BY b,c
- WHERE a = const AND b > const ORDER BY b,c
Impossible de trier avec index
- ORDER BY a ASC,b DESC,c DESC /* Tri incohérent */
- WHERE g = const ORDER BY b,c /*PerduaIndex*/
- WHERE a = const ORDER BY c /*PerdubIndex*/
- WHERE a = const ORDER BY a,d /*dNe fait pas partie de l'index*/
- WHERE a in (...) ORDER BY b,c /*Pour le tri,Plusieurs critères d'égalité sont également des requêtes de plage*/
5.2. Cas en action
ORDER BYClause,Utiliser autant que possibleIndexTrier par,Ne pas utiliserFileSortTrier par.
Effacer avant d'exécuter le cas studentIndex on, Laissez seulement la clé primaire :
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;
DROP INDEX idx_age_classid_name ON student;
#Ou
call proc_drop_index('INDEXTEST','student');
Scénario:L'âge de la requête est30Un an, Et le numéro d'étudiant est inférieur à 101000Étudiants, Trier par nom d'utilisateur
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;

Conclusions:type - Oui. ALL,Dans le pire des cas..Extra Il est encore là. Using filesort,Et le pire..L'optimisation est nécessaire.
Idées d'optimisation:
Programme I: Pour enleverfilesortNous pouvons construire l'index
#Créer un nouvel index
CREATE INDEX idx_age_name ON student(age,NAME);
Programme II: Fais de ton mieux.where Les critères de filtrage et de tri pour utiliser l'index ci - dessus
Créer un index combiné de trois champs :
DROP INDEX idx_age_name ON student;
CREATE INDEX idx_age_stuno_name ON student (age,stuno,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY
NAME ;
Il s'est avéré qu'il y avait filesortDe sql Vitesse de fonctionnement, Il a été optimisé. filesortDe sql , Et c'est beaucoup plus rapide. , Les résultats sont apparus presque instantanément .
Conclusions:
1. Les deux index existent en même temps,mysqlSélection automatique de la solution optimale.(Pour cet exemple,mysqlSélectionner
idx_age_stuno_name).Mais, Variation de la quantité de données,L'index choisi changera également en conséquence .
2. Quand【Champ d'application】Et【group by Ou order by】Le champ apparaît deux fois,Le champ condition de priorité est dépassé
Nombre de filtres,Si les données filtrées sont suffisantes,Et il n'y a pas beaucoup de données à trier,Priorité de l'index dans le champ de plage
Allez..Au contraire,C'est pareil..
5.3. filesortAlgorithmes:Tri bidirectionnel et tri unidirectionnel
5.3.1. Tri bidirectionnel (Doucement)
- MySQL 4.1Avant cela, on utilisait un double tri ,Littéralement, deux scans du disque,Obtenir des données, Lire les pointeurs de ligne etorder byColonnes ,Triez - les.,Puis numérisez la liste déjà triée,Relisez la sortie de données correspondante de la liste selon les valeurs de la liste.
- Extraire les champs de tri du disque,InbufferTrier,Encore. Le disque récupère d'autres champs .
Prenez un lot de données,Pour numériser le disque deux fois,Tout le monde sait,IOC'est long,Donc, dansmysql4.1Après,Un deuxième algorithme amélioré est apparu,C'est le tri à sens unique.
5.3.2. Tri à sens unique (Allez)
Lire la requête à partir du disque Toutes les colonnes ,Selonorder byListé dansbufferLes trier,Puis numérisez la liste triée pour la sortie, C'est plus rapide.,La deuxième lecture des données est évitée.Et de mettre au hasardIOC'est devenu l'ordre.IO,Mais ça va utiliser plus d'espace, Parce qu'il garde chaque ligne en mémoire.
5.3.3. Optimiser la stratégie
- Essayer d'améliorer sort_buffer_size.
- Essayer d'améliorer max_length_for_sort_data.
- Order by Heureselect * C'est un tabou.C'est mieux.QueryChamps requis.
Six. GROUP BYOptimisation
- group by Le principe de l'utilisation de l'index suit presqueorder byD'accord. ,group by Même s'il n'y a pas de critères de filtrage pour utiliser l'index, L'index peut également être utilisé directement .
- group by Trier puis grouper,Suivez la règle du préfixe gauche optimal pour la construction d'index.
- Lorsque la colonne index ne peut pas être utilisée,Augmentation max_length_for_sort_data Et sort_buffer_size Paramètres.
- whereEfficacité supérieure àhaving,Peut être écrit danswhereLes conditions de qualification ne sont pas écrites danshavingOn y est..
- Réduction de l'utilisationorder by,Communiquer avec les entreprises sans trier,Ou mettre le tri sur le côté du programme.Order by、groupby、distinctCes déclarations sont coûteusesCPU,De la base de donnéesCPULes ressources sont extrêmement précieuses.
- Inclusorder by、group by、distinctDéclarations pour ces requêtes,whereL'ensemble de résultats filtrés par condition doit être maintenu à1000En ligne,SinonSQLÇa va être lent..
Sept. Optimiser la requête de pagination
Optimiser la pensée 1:
Trier la pagination sur l'index,Enfin, selon l'Association de la clé primaire, retournez à la table originale pour interroger les autres colonnes nécessaires.
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10)
a
WHERE t.id = a.id;

Idées d'optimisation II:
Ce schéma s'applique au tableau d'auto - augmentation de la clé primaire,Tu peux mettreLimit Requête convertie en requête à un endroit .
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;

Huit. Priorité à l'index de superposition
8.1. Qu'est - ce qu'un index de superposition?
Mode de compréhension I:L'indexation est un moyen efficace de trouver des lignes,Mais en général, les bases de données peuvent aussi utiliser des index pour trouver les données d'une colonne,Donc il n'a pas à lire toute la ligne.Après tout, les noeuds de feuilles indexées stockent les données qu'ils indexent;Lorsque vous pouvez lire l'index, vous pouvez obtenir les données que vous voulez,Alors vous n'avez pas besoin de lire la ligne.Un index qui contient des données qui répondent aux résultats de la requête est appelé un index de superposition.
Mode de compréhension II:Une forme d'index composite non groupé,Il est inclus dans la requêteSELECT、JOINEtWHEREToutes les colonnes utilisées dans la clause(Les champs indexés sont exactement les champs impliqués dans les critères de requête de superposition).
En termes simples,, Colonnes d'index+Clé primaire Contient SELECT À FROMColonnes demandées entre .
8.2. Avantages et inconvénients de la couverture des index
Les avantages:
- ÉviterInnodbTable pour la requête secondaire indexée(Retour au tableau).
- On peut mettre au hasardIODans l'ordreIOAccélérer l'efficacité des requêtes.
Inconvénients:
Maintenance des champs d'index Il y a toujours un prix..Donc,,Des considérations commerciales doivent être prises en considération lors de l'établissement d'index redondants pour soutenir les index superposés.C'est une affaire.DBA,Ou le travail d'un architecte de données d'affaires.
Neuf. Comment indexer une chaîne
Il y a une liste des professeurs. ,Le tableau est défini comme suit::
create table teacher(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
L'instructeur se connecte à l'aide de la boîte aux lettres ,Il doit donc y avoir une déclaration comme celle - ci dans le Code d'entreprise:
select col1, col2 from teacher where email='xxx';
SiemailIl n'y a pas d'index sur ce champ, Alors cette déclaration ne peut être faite que Balayage complet de la table .
9.1. Index des préfixes
MySQLEst supporté par l'index préfixe.Par défaut,Si vous créez une instruction indexée sans spécifier la longueur du préfixe,L'index contiendra alors toute la chaîne.
alter table teacher add index index1(email)
#Ou
alter table teacher add index index2(email(6));
Quelle est la différence entre les deux définitions en termes de structure et de stockage des données?? La figure ci - dessous illustre ces deux indices .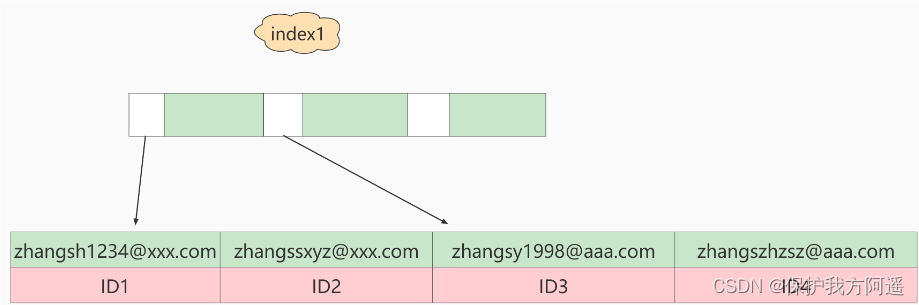 Et:
Et: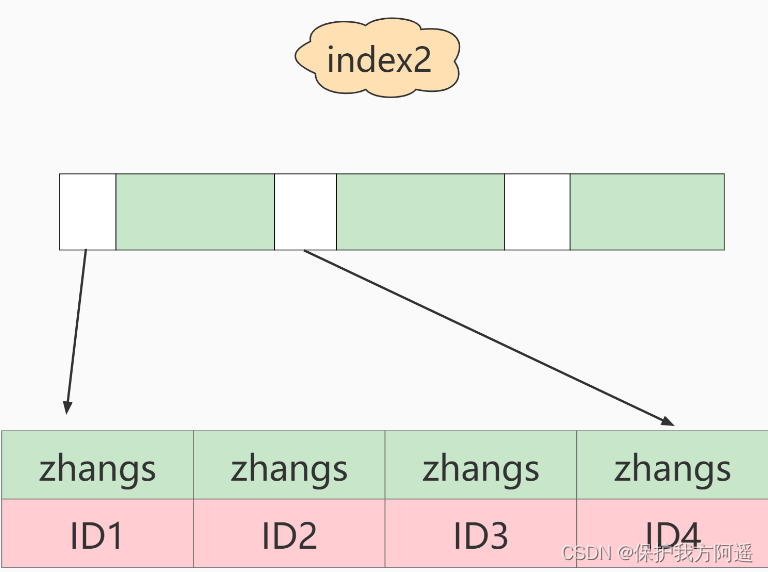
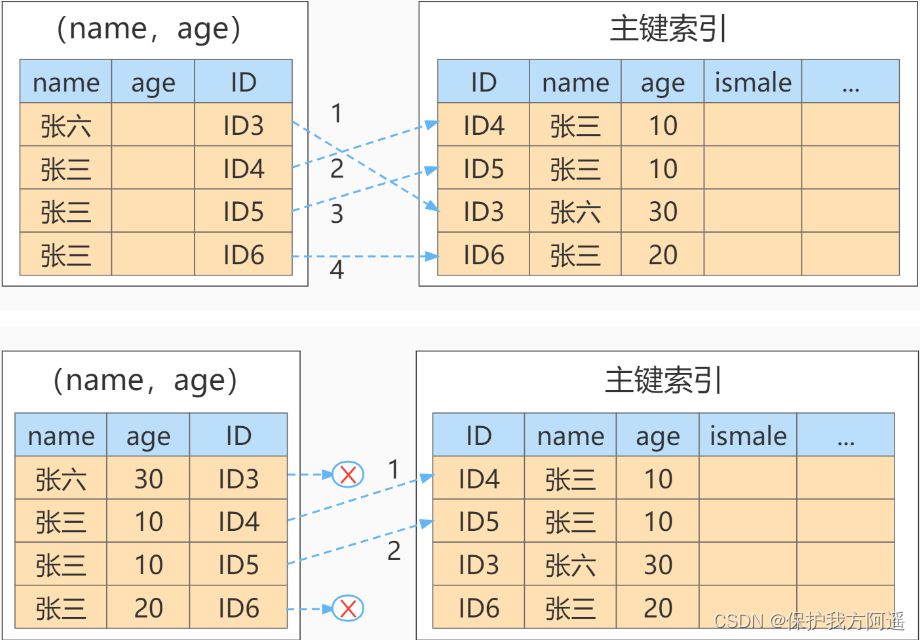
Si vous utilisezindex1(C'est - à - dire:emailStructure de l'index pour toute la chaîne),L'ordre d'exécution est le suivant::
- Deindex1L'arbre d'index a trouvé une valeur d'index satisfaisante oui’ [email protected] ’Ce disque,AccèsID2Valeur de;
- La valeur de la clé primaire trouvée sur la clé primaire estID2Oui.,JugementemailLa valeur de est correcte,Ajouter cette ligne d'enregistrement à l'ensemble de résultats;
- Prends - le.index1L'enregistrement suivant de l'emplacement qui vient d'être trouvé dans l'arbre d'index,Trouvé insatisfaitemail=’ [email protected] ’C'est bon.,Fin du cycle.
Dans ce processus,,Les données ne doivent être récupérées qu'une seule fois dans l'index de la clé primaire,Donc le système pense qu'une seule ligne a été scannée.
Si vous utilisezindex2(C'est - à - dire:email(6)Structure de l'index),L'ordre d'exécution est le suivant:: - Deindex2L'arbre d'index a trouvé une valeur d'index satisfaisante oui’zhangs’Les dossiers de,Le premier que j'ai trouvéID1;
- La valeur de la clé primaire trouvée sur la clé primaire estID1Oui.,Juge.emailNon.’ [email protected] ’,Cette ligne d'enregistrement est abandonnée;
- Prends - le.index2Enregistrement suivant de l'emplacement que vous venez de trouver,La découverte est toujours’zhangs’,Enlevez - le.ID2,Encore.IDArrondir les lignes sur l'index et juger,Ça vaut le coup.,Ajouter cette ligne d'enregistrement à l'ensemble de résultats;
- Répétez l'étape précédente,Jusqu'àidxe2La valeur obtenue sur n'est pas’zhangs’Heure,Fin du cycle.
C'est - à - dire en utilisant l'index préfixe ,Définir la longueur,Pour économiser de l'espace,Pas besoin d'ajouter trop de frais de recherche. J'ai déjà parlé de la Division ,Plus la distinction est élevée, mieux c'est..Parce que plus la Division est élevée,,Cela signifie moins de valeurs clés dupliquées.
9.2. Effet de l'index préfixe sur l'index de superposition
Conclusions:
L'utilisation de l'index préfixe permet d'optimiser les performances de la requête sans écraser l'index,C'est aussi un facteur dont vous devez tenir compte lorsque vous choisissez d'utiliser ou non l'index préfixe.
Dix. Index Push down
Index Condition Pushdown(ICP)- Oui.MySQL 5.6Nouvelles caractéristiques,Est un moyen optimisé de filtrer les données au niveau du moteur de stockage en utilisant des index.ICPVous pouvez réduire le nombre de fois que le moteur de stockage accède à la table de base etMySQLNombre de fois que le serveur a accédé au moteur de stockage.
10.1. Le processus de numérisation avant et après l'utilisation
Non utiliséICP Processus de numérisation des index :
storageCouche: Ne satisfera que index key Extraction de l'ensemble de la ligne d'enregistrement correspondant à l'enregistrement index de la condition ,Retour àserverCouche.
server Couche:Pour les données retournées, Utilisez le whereFiltration conditionnelle, Jusqu'à la dernière ligne .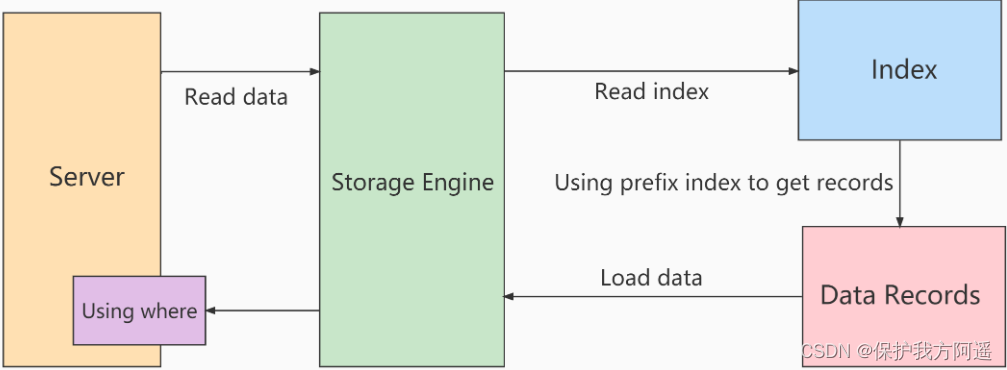
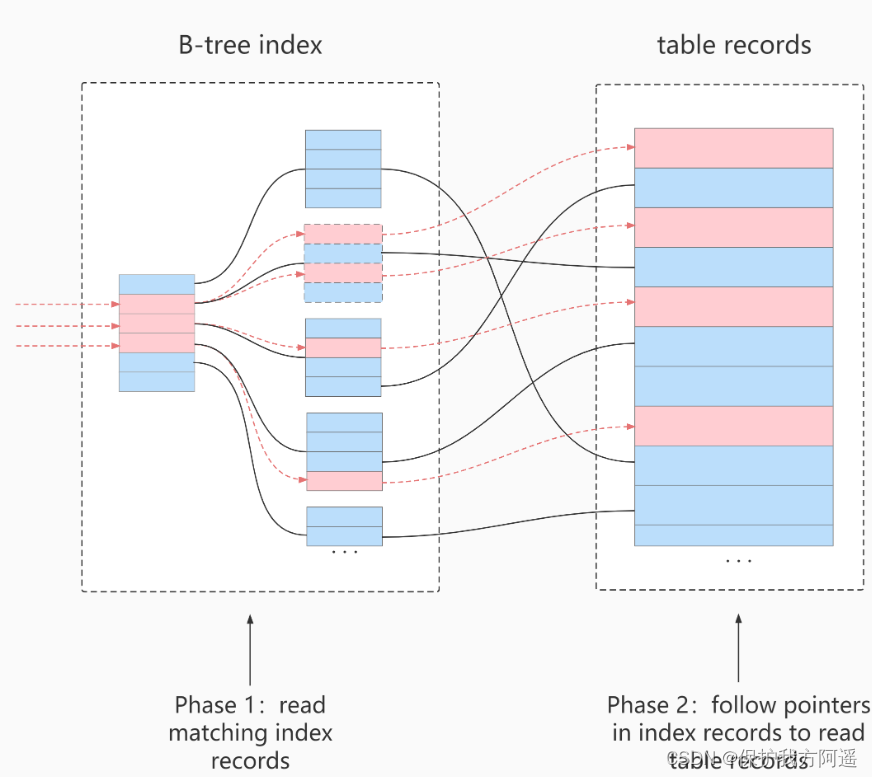
UtiliserICPProcessus de numérisation:
- storageCouche:
D'abordindex key Détermination de l'intervalle d'enregistrement de l'index lorsque les conditions sont remplies , Ensuite, utilisez l'index index filterFiltrer. Sera satisfait indexfilter Ce n'est que lorsque l'enregistrement index de l'état est retourné à la table de retour que l'ensemble de la ligne d'enregistrement est retourné à serverCouche.Insatisfaitindex filter Les enregistrements d'index conditionnels sont supprimés ,Ne pas retourner au tableau、Et ne reviendra passerverCouche. - server Couche:
Pour les données retournées,Utilisertable filter Les conditions font le filtrage final .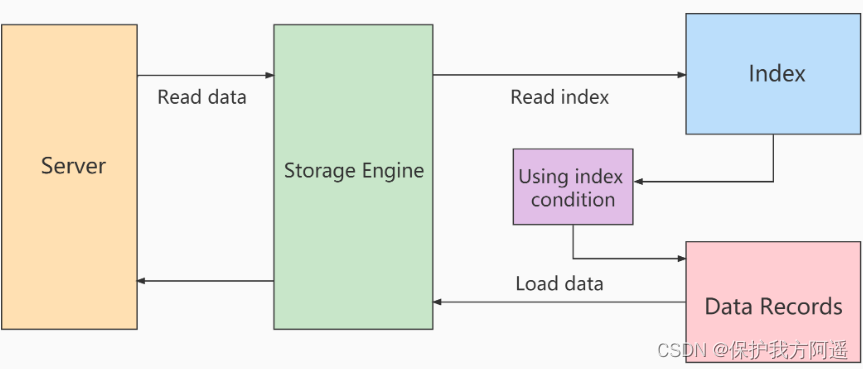
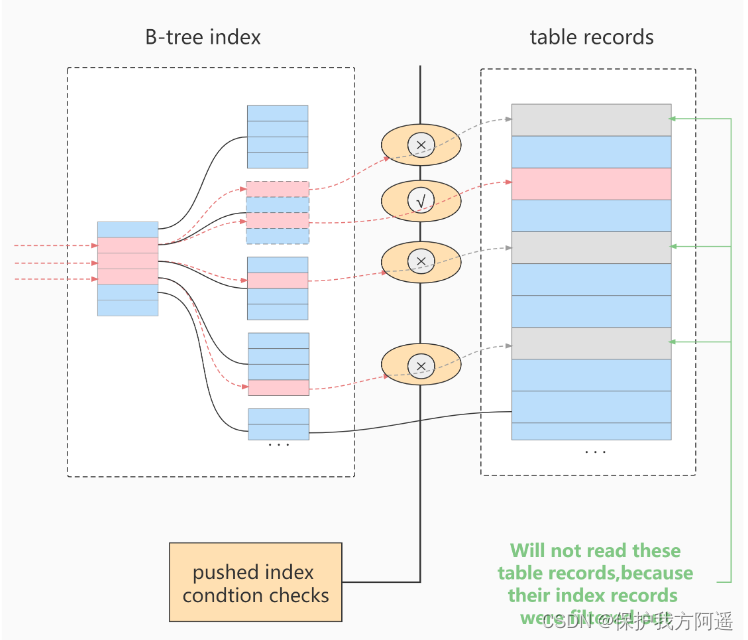 Différence de coût avant et après utilisation
Différence de coût avant et après utilisation
- Avant utilisation, Le niveau de stockage est retourné plus que nécessaire par index filter Ligne entière filtrée
- UtiliserICPAprès, Ça élimine l'insatisfaction. index filterEnregistrement des conditions, Ils n'ont pas à retourner les formulaires et les transmettre à serverCoût de la couche.
- ICPDe Effet d'accélération Dépend du passage dans le moteur de stockage ICPFiltrage Proportion de données perdues .
10.2. ICPConditions d'utilisation
ICPConditions d'utilisation:
① Uniquement pour les index secondaires (secondary index)
②explain Dans le plan d'exécution affiché typeValeur(join Type)Pour range 、 ref 、 eq_ref Ou ref_or_null .
③ Pas touswhere Toutes les conditions peuvent être utilisées ICPFiltrage,Siwhere Le champ de la condition n'est pas dans la colonne index , Ou lire l'enregistrement de la table entière
ÀserverFais - le.whereFiltration.
④ ICPPeut être utiliséMyISAMEtInnnoDBMoteur de stockage
⑤ MySQL 5.6 La version ne supporte pas les tables partitionnées ICPFonction,5.7 Prise en charge du démarrage de la version .
⑥ QuandSQL Lors de l'utilisation de l'index override ,Non pris en chargeICPMéthodes d'optimisation.
10.3. ICPCas d'utilisation
CAS1:
SELECT * FROM tuser
WHERE NAME LIKE 'Zhang.%'
AND age = 10
AND ismale = 1;
 CAS2:
CAS2:
Onze. Index général vs Index unique
Du point de vue de la performance, Choisissez un index unique ou un index normal ?Quelle est la base du choix?
Hypothèses,Nous avons une clé primaire listée commeIDTableau,Champs dans le tableauk,Et danskIndex sur,Champ hypothétique k Aucune des valeurs ci - dessus ne se répète.
L'instruction de construction de cette table est:
reate table test(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;
11.1. Processus de requête
Hypothèses,L'instruction qui exécute la requête est select id from test where k=5.
- Pour un index normal,Premier enregistrement trouvé satisfaisant(5,500)Après,Besoin de trouver le prochain enregistrement,Jusqu'à ce que vous rencontriez le premier insatisfaitk=5Enregistrement des conditions.
- Pour un index unique,Parce que l'index définit le caractère unique,Après avoir trouvé le premier enregistrement qualifié,Arrête de récupérer..
Alors,Combien d'écarts de rendement cette différence peut - elle entraîner??La réponse est:, Très peu. .
11.2. Processus de mise à jour
Afin d'illustrer l'effet de l'index général et de l'index unique sur la performance de l'instruction de mise à jour,Introductionchange buffer.
Lorsqu'une page de données doit être mise à jour,Mise à jour directe si la page de données est en mémoire,Et si cette page de données n'est pas encore en mémoire,Sans préjudice de la cohérence des données, InooDBCes mises à jour sont mises en cache danschange bufferMoyenne ,Cela élimine la nécessité de lire cette page de données à partir du disque.La prochaine fois qu'une requête nécessite l'accès à cette page de données,Lire la page de données en mémoire,Et ensuite exécuterchange bufferActions relatives à cette page.De cette façon, l'exactitude de cette logique de données peut être garantie.
Oui.change bufferL'opération dans s'applique à la page de données originale,Le processus d'obtention des résultats les plus récents est appelé merge .Sauf que Accédez à cette page de données Ça va déclenchermergeExtérieur,Le système a Les fils de fond sont périodiques merge.In Fermeture normale de la base de données(shutdown) En cours,Sera également exécutémergeFonctionnement.
Si vous pouvez enregistrer l'opération de mise à jour en premierchange buffer, Réduire la lecture des disques ,La vitesse d'exécution des déclarations sera considérablement améliorée.Et,La mémoire de lecture des données est nécessaire buffer pool De,De cette façon, il est possible Évitez d'utiliser la mémoire ,Améliorer l'utilisation de la mémoire.
La mise à jour d'un index unique ne peut pas être utiliséechange buffer ,En fait, seuls les index normaux sont disponibles.
Si vous voulez insérer un nouvel enregistrement dans ce tableau (4,400)Et si,InnoDBComment fonctionne le processus?
11.3. change bufferScénarios d'utilisation pour
- Comment choisir les index normaux et uniques?En fait...,Il n'y a pas de différence dans la capacité de requête entre les deux types d'index, La principale considération est de mettre à jour le rendement Impact de.Alors...,Il est recommandé de sélectionner un index normal autant que possible. .
- Dans la pratique , Index général Et change buffer Utilisation avec,Pour Grande quantité de données ..L'optimisation de la mise à jour du tableau est encore évidente .
- Si toutes les mises à jour suivent, Tout de suite. Avec la recherche de cet enregistrement ,Alors tu devrais Fermerchange buffer .Et dans d'autres cas,,change bufferAméliore les performances de mise à jour.
- Parce qu'il n'y a pas de référence uniquechange bufferMécanisme d'optimisation,Donc si Les affaires sont acceptables , Du point de vue du rendement, il est recommandé de donner la priorité aux index non uniques .Mais si"Les entreprises peuvent ne pas être en mesure de s'assurer"Dans le cas de,Qu'est - ce qu'on fait??
- Tout d'abord,, Priorité à l'exactitude opérationnelle .Notre prémisse est que“Le Code d'entreprise a garanti que les données en double ne seront pas écrites”Dans le cas de,Discuter des questions de rendement.Si l'entreprise ne peut garantir,Ou l'entreprise demande à la base de données de faire des contraintes,Il n'y a pas de choix.,Un index unique doit être créé.Dans ce cas, Le sens de cette section est , Si vous rencontrez beaucoup de données d'insertion lentes 、 Quand le taux de succès de la mémoire est faible , Pour vous donner une idée de dépannage supplémentaire .
- Et puis,Dans certains“ Archive Library ”Scènes, Vous pouvez envisager d'utiliser un index unique .Par exemple,, Les données en ligne ne doivent être conservées que six mois ,Les données historiques sont ensuite sauvegardées dans la Bibliothèque d'archives.À ce moment - là., L'archivage des données est déjà assuré qu'il n'y a pas de conflit de clé unique .Pour améliorer l'efficacité de l'archivage, Vous pouvez envisager de changer l'index unique dans le tableau en index normal .
Douze. Autres stratégies d'optimisation des requêtes
12.1. À propos deSELECT(*)
Dans une requête de table, Il est recommandé de clarifier les champs ,Ne pas utiliser * Liste des champs à interroger,RecommandéSELECT <Liste des champs> Requête.Raisons:
① MySQL Au cours de l'analyse,Va passer Dictionnaire de données de requête Oui."*" Convertir tous les noms de colonnes dans l'ordre , Cela peut coûter beaucoup de ressources et de temps .
② Impossible d'utiliser écraser l'index.
12.2. LIMIT 1 Impact sur l'optimisation
Le but est de numériser la table entière SQL Déclarations, Si vous pouvez vous assurer qu'il n'y a qu'un seul résultat ,Alors, plus LIMIT 1 Quand, Le scan ne se poursuivra pas quand un résultat sera trouvé , Cela accélère les requêtes .
Si la table de données a établi un index unique pour le champ , Ensuite, vous pouvez interroger l'index , Si vous ne numérisez pas la table entière, , Pas besoin d'ajouter LIMIT 1 C'est.
12.3. Utilisation multipleCOMMIT
Dans la mesure du possible, Utiliser le plus possible dans le programme COMMIT, De cette façon, la performance du programme est améliorée , La demande sera aussi due à COMMIT Diminution des ressources libérées .
COMMIT Ressources libérées:
- Informations sur le segment ROLLBACK pour récupérer les données.
- Verrouillage obtenu par une instruction de programme.
- redo / undo log buffer Espace dans.
- Gérer ce qui précède 3 Dépenses internes dans les ressources.
边栏推荐
- Software test engineer development planning route
- Installation of pagoda and deployment of flask project
- ① BOKE
- PyTorch RNN 实战案例_MNIST手写字体识别
- 简单解决phpjm加密问题 免费phpjm解密工具
- MySQL實戰優化高手04 借著更新語句在InnoDB存儲引擎中的執行流程,聊聊binlog是什麼?
- 软件测试工程师必备之软技能:结构化思维
- Advantages and disadvantages of evaluation methods
- oracle sys_ Context() function
- 软件测试工程师必备之软技能:结构化思维
猜你喜欢
MySQL实战优化高手11 从数据的增删改开始讲起,回顾一下Buffer Pool在数据库里的地位
History of object recognition

Sichuan cloud education and double teacher model
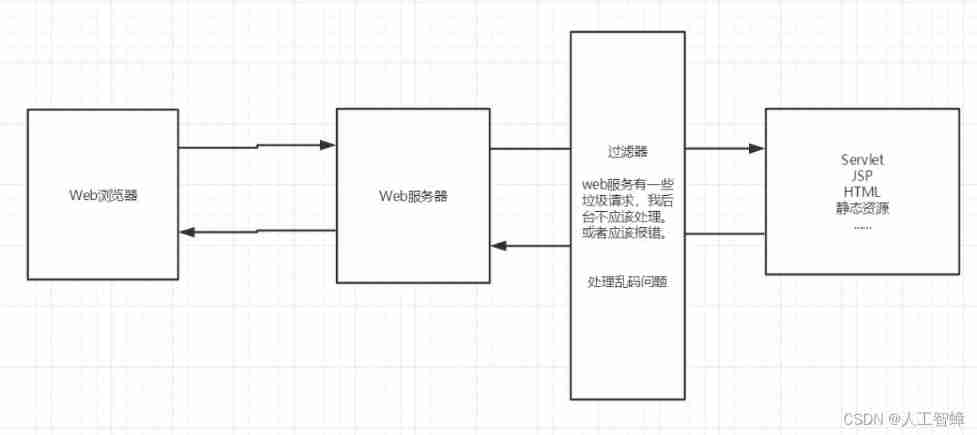
Complete web login process through filter
![17 medical registration system_ [wechat Payment]](/img/b4/f9abfa0fb0447d727078069d888b57.png)
17 medical registration system_ [wechat Payment]
Nanny hand-in-hand teaches you to write Gobang in C language
![15 medical registration system_ [appointment registration]](/img/c1/27c7a5aae82783535e5467583bb176.png)
15 medical registration system_ [appointment registration]
The appearance is popular. Two JSON visualization tools are recommended for use with swagger. It's really fragrant
该不会还有人不懂用C语言写扫雷游戏吧

The 32-year-old fitness coach turned to a programmer and got an offer of 760000 a year. The experience of this older coder caused heated discussion
随机推荐
What is the difference between TCP and UDP?
Several errors encountered when installing opencv
MySQL combat optimization expert 04 uses the execution process of update statements in the InnoDB storage engine to talk about what binlog is?
NLP路线和资源
MySQL30-事务基础知识
C miscellaneous shallow copy and deep copy
17 医疗挂号系统_【微信支付】
13 medical registration system_ [wechat login]
简单解决phpjm加密问题 免费phpjm解密工具
Cmooc Internet + education
Record the first JDBC
再有人问你数据库缓存一致性的问题,直接把这篇文章发给他
15 医疗挂号系统_【预约挂号】
Carolyn Rosé博士的社交互通演讲记录
MySQL35-主从复制
寶塔的安裝和flask項目部署
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
MySQL实战优化高手05 生产经验:真实生产环境下的数据库机器配置如何规划?
宝塔的安装和flask项目部署
Download and installation of QT Creator