当前位置:网站首页>Shardingsphere sub database and table examples (logical table, real table, binding table, broadcast table, single table)
Shardingsphere sub database and table examples (logical table, real table, binding table, broadcast table, single table)
2022-07-07 10:54:00 【Clang clang】
Preface
1、 Use version 5.0.0
2、 Usage mode - Memory mode
One 、 Table name Description
1、 This official document also states , Official statement - surface - chinese
1.1、 Logic table
1、 Horizontal split database with the same structure ( surface ) The logical name of , yes SQL Logical identification of the table in . example : Order data is split into 10 A watch , Namely t_order_0 To t_order_9, Their logical table is called t_order
2、 Examples will be given later in the case
1.2、 True table
1、 Real physical tables in a horizontally split database . In the previous example t_order_0 To t_order_9
2、 Examples will be given later in the case
1.3、 Binding table
1、 It refers to the main table and sub table with the same fragmentation rules . for example :t_order Table and t_order_item surface , All in accordance with order_id Fragmentation , The two tables are bound to each other . There will be no Cartesian product association in multi table Association queries between bound tables , The efficiency of association query will be greatly improved . Illustrate with examples , If SQL by
Pay attention to the yellow mark on the top , Yejun , It means back
t_orderandt_order_itemThe rules of table segmentation should be exactly the same , Fragment according to the same field .
SELECT
i.*
FROM
t_order o
JOIN t_order_item i ON o.order_id = i.order_id
WHERE
o.order_id IN ( 10, 11 );
2、 When the binding table relationship is not configured , Let's say the partition bond order_id Numerical value 10 Route to 0 slice , Numerical value 11 Route to 1 slice , So after routing SQL Should be 4 strip , They appear as Cartesian products :
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
3、 After configuring the binding table relationship , The routing SQL Should be 2 strip :
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
4、 among t_order stay FROM The far left side of ,ShardingSphere It will be used as the main table of the whole binding table . All routing calculations will use only the primary table policy , that t_order_item The slice calculation of the table will use t_order Conditions . therefore , The partition keys between bound tables need to be exactly the same
1.4、 Broadcast table
1、 It refers to the table that exists in all fragmentation data sources , The table structure and its data are completely consistent in each database . It is suitable for scenarios where the amount of data is not large and needs to be associated with massive data tables , for example : Dictionary table .
2、 Examples will be given later in the case
1.5、 Single table
1、 It refers to the only table that exists in all fragmented data sources . It is suitable for tables with small amount of data and no need of segmentation .
2、 stay shardingSphere5.0.0 Version start , Single table does not need configuration , It will be internally routed to the data source of a single table .
3、 Examples will be given later in the case
Two 、 Infrastructure project architecture
1、 Use springBoot and mybatisPlus The project to build a foundation is as follows
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.gxm</groupId>
<artifactId>shardingSphere-test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingSphere-test</name>
<description>shardingSphere-test</description>
<properties>
<java.version>1.8</java.version>
<mybatis-plus.version>3.4.1</mybatis-plus.version>
<shardingsphere.version>5.0.0</shardingsphere.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>${shardingsphere.version}</version>
</dependency>
<!-- hutool Tools -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
3、 ... and 、 Use cases – Simple sub database and sub table
3.1、 Database format
1、 Create two databases , Each database contains t_problem surface , The data format is the same .
Note that the primary key is bigint, also No Self increasing couple
2、 The database script is as follows , Then execute it in both databases
-- ----------------------------
-- Table structure for t_problem0
-- ----------------------------
DROP TABLE IF EXISTS `t_problem0`;
CREATE TABLE `t_problem0` (
`id` bigint(0) NOT NULL,
`content` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_problem1
-- ----------------------------
DROP TABLE IF EXISTS `t_problem1`;
CREATE TABLE `t_problem1` (
`id` bigint(0) NOT NULL,
`content` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_problem2
-- ----------------------------
DROP TABLE IF EXISTS `t_problem2`;
CREATE TABLE `t_problem2` (
`id` bigint(0) NOT NULL,
`content` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
3.2、 Project code
1、application.yml The configuration is as follows :
I won't explain the specific content one by one , The relevant configurations inside have been explained very clearly
The main point is , The strategy of sub database and sub table
sub-treasuryds$->{id % 2}Explain the basis t_problem Table inserted id %2 , That's it 【ds0,ds1】, and ds0 and ds1 The data source is defined above
tablet_problem$->{id % 3}Explain the basis t_problem Table inserted id %3, Namely 【t_problem0,t_problem1,t_problem2】
spring:
sharding-sphere: # mode.type The default is memory mode startup
props:
# Exhibition sql
sql-show: true # Print sql, The console can see the logic table of execution sql, And the real table sql(5.0.0 Another parameter before version )
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
rules:
sharding:
sharding-algorithms:
t-problem-db-inline: # be known as t-problem-db-inline The algorithm of the sub database strategy
props:
algorithm-expression: ds$->{
id % 2}
type: INLINE
t-problem-table-inline: # be known as t-problem-table-inline Algorithm of table splitting strategy
props:
algorithm-expression: t_problem$->{
id % 3}
type: INLINE
tables:
t_problem:
actual-data-nodes: ds$->{
0..1}.t_problem$->{
0..2}
database-strategy: # Sub library strategy
standard: # Standard slicing scenarios for single slicing keys ,( Distinguishing multiple column IDS is a complex situation , take standard Switch to complex( That is, the name of the partition column , Multiple columns are separated by commas ))
sharding-algorithm-name: t-problem-db-inline # name , Use on top
sharding-column: id # That field is passed to the following algorithm
table-strategy: # Tabulation strategy
standard:
sharding-algorithm-name: t-problem-table-inline
sharding-column: id # That field is passed to the following algorithm
key-generate-strategy: # t_problem Table primary key id Generated strategies https://blog.csdn.net/chinawangfei/article/details/114675854
column: id # t_order Primary Key id Need to use snowflake Algorithm
keyGeneratorName: t-problem-snowflake # The key here is modified It doesn't seem to work , This is the most outrageous , The snowflake algorithm is used by default
key-generators:
t-problem-snowflake:
type: snowflake
props:
worker-id: 1
server:
port: 8123
mybatis-plus:
configuration:
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.gxm.shardingspheretest.model
2、model Definition , Pay attention to the notes
package cn.gxm.shardingspheretest.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 24 Japan */
@TableName("t_problem")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Problem extends Model<Problem> {
/** * 1、 It must be used here Long, Out of commission int perhaps integer because * Use shardSphere The value generated by the snowflake algorithm is very large , Already exceeded * Integer.MAX_VALUE(), Only use Long To store , And the database must also be bigint * Of course, if you choose to use the type of string , Then there are not so many things here * <p> * Notice the type Is the default value IdType.NONE, Don't set ,NONE Namely 【 User input ID This type can be filled by registering the auto fill plug-in 】 */
@TableId(value = "id")
private Long id;
@TableField("content")
private String content;
}
3、mapper and service Just omit , And the usual configuration mybatis plus almost
4、 Create a new one controller Use it for testing , The contents are as follows
package cn.gxm.shardingspheretest.controller;
import cn.gxm.shardingspheretest.model.Problem;
import cn.gxm.shardingspheretest.service.ProblemService;
import cn.hutool.core.util.RandomUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 24 Japan */
@RestController
@RequestMapping("/problem")
public class ProblemController {
private final ProblemService problemService;
@Autowired
public ProblemController(ProblemService problemService) {
this.problemService = problemService;
}
@GetMapping("/{id}")
public Problem getById(@PathVariable Long id) {
return this.problemService.getById(id);
}
@GetMapping("list")
public List<Problem> list() {
return this.problemService.list();
}
/** * The more you get the data behind the offset position , Use LIMIT The less efficient paging is , * Here's the solution ( There are many ways to avoid using LIMIT paging ) * 1、 For example, construct a secondary index of the number of row records and the row offset * 2、 Or end with the last paging data ID Pagination as the next query condition, etc ( Must not skip page query ) * <p> * Paging is very uncomfortable , For example, you now have two databases , Each database is divided into 3 A watch , amount to One t_order surface , Is divided into 6 A watch , and * If you query by page The first 3 page 100 Data (page=3,limit=100), In fact, it is equivalent to checking 6 Tabular 3*100 The data of , Then put it all together , Get in paging 100 strip . * So the slower you ask later * <p> * Be careful ,shardingSphere stay 5.0.0 After the version , Turn on memory limit mode And connection limited mode , We just need to configure maxConnectionSizePerQuery , Will be based on * Formula to calculate , Use memory limit mode or link limit mode * but shardingSphere Part of the processing will be carried out 【 Merge results by moving the result set cursor down , It's called flow merging , It does not need to load all the result data into memory 】 * * @param page page * @param limit limit * @return pojo */
@GetMapping("page")
public List<Problem> page(@RequestParam("page") Integer page, @RequestParam("limit") Integer limit) {
Page<Problem> orderPage = this.problemService.page(new Page<>(page, limit));
return orderPage.getRecords();
}
@GetMapping("/count")
public Integer count() {
return this.problemService.count();
}
@GetMapping("/mock")
public String mock() {
for (int i = 0; i < 12; i++) {
final Problem problem = new Problem();
problem.setContent(RandomUtil.randomString(20));
this.problemService.save(problem);
}
return "SUCCESS";
}
}
3.3、 Test and analysis
3.3.1、mock Interface
1、 call mock After the interface , The log is as follows

2、 The database data is as follows 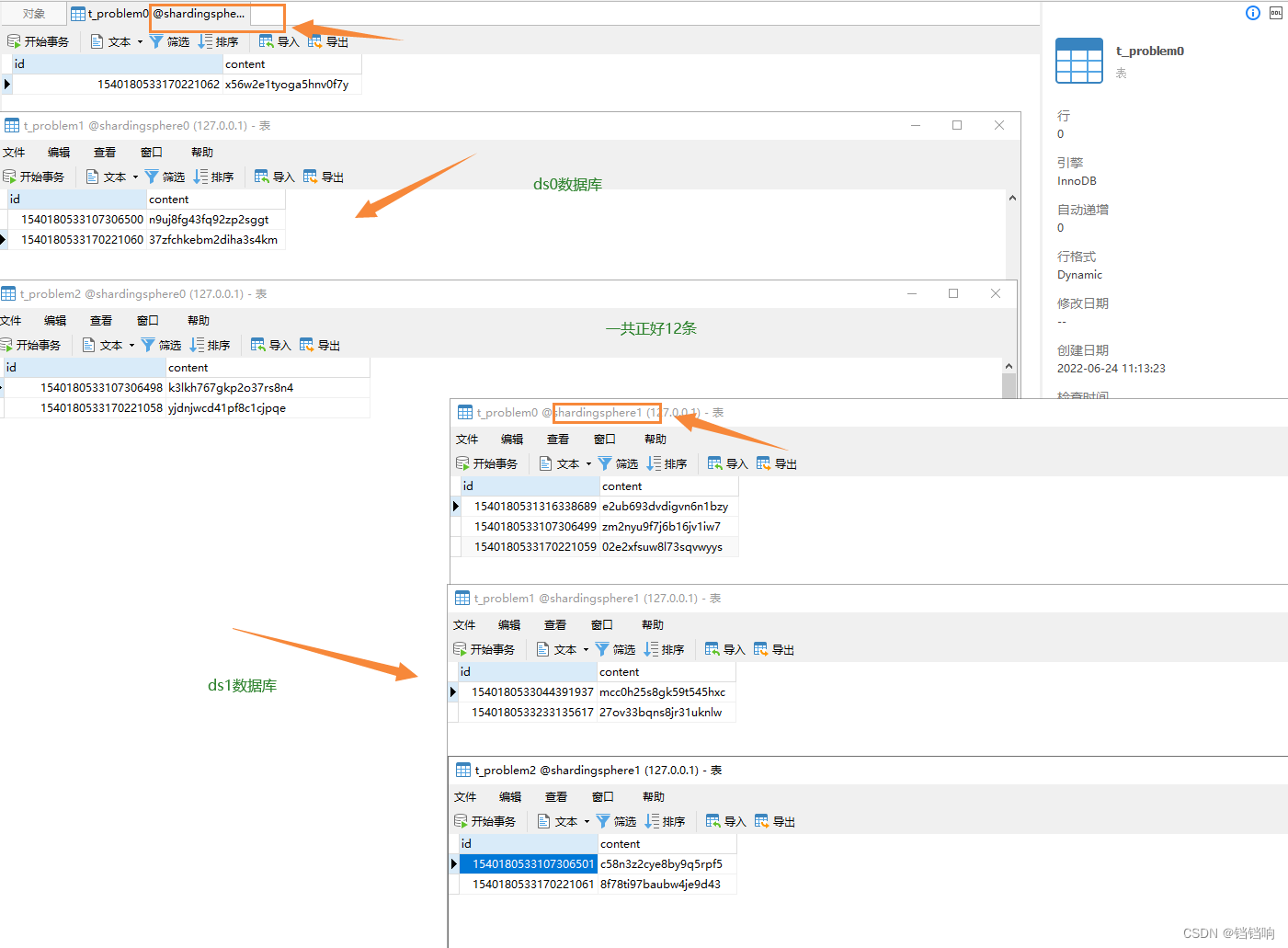
3.3.2、count Interface
1、 Request the results , Namely 12 strip 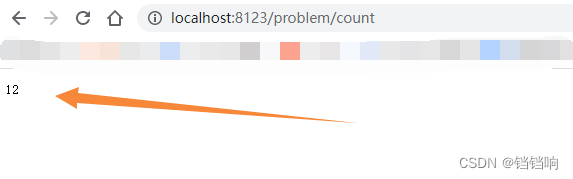
2、 The execution log is as follows 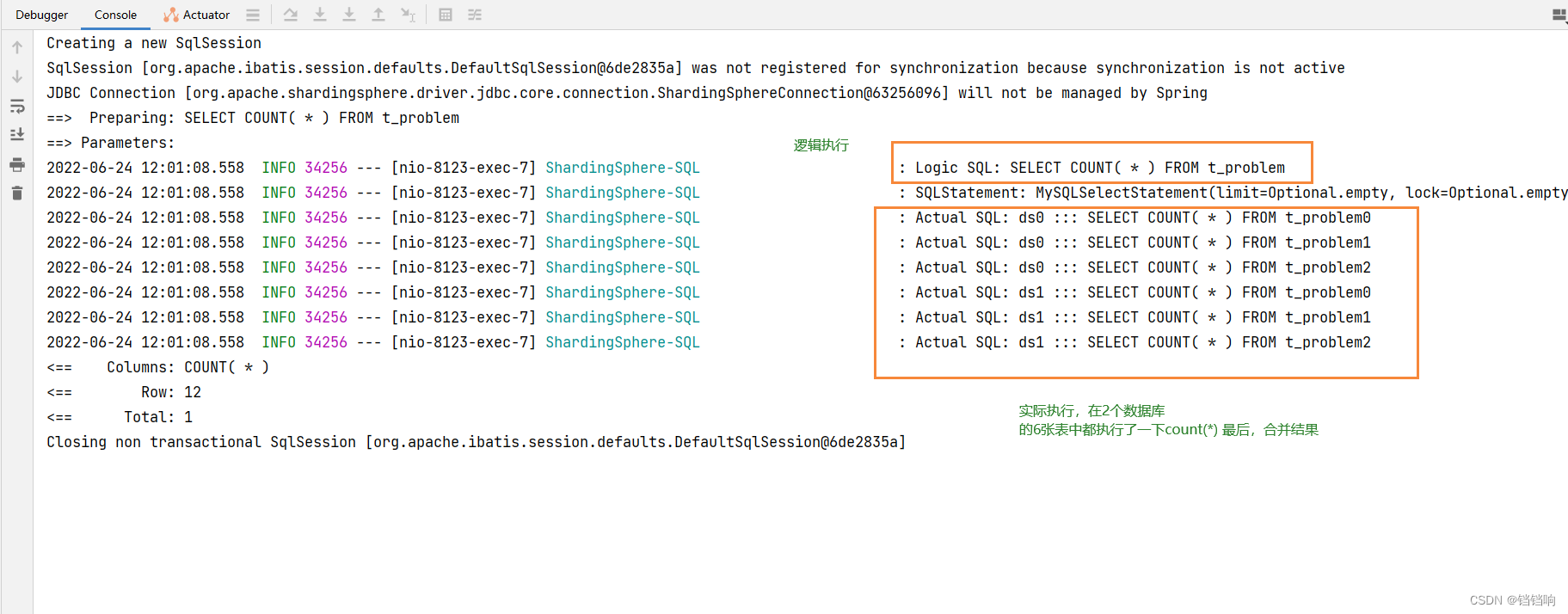
3.3.3、page Interface
1、 Request interface ,, Be careful , Once our page numbers get bigger , Maybe the performance will drop a part , although shardingsphere Helped us do some optimization , But if the amount of data is still large , That performance is still not objective , as follows
Be careful , There is no home sorting rule here , If you add sorting rules , Executive sql There will be some other logic , such as
shardingsphereSupplementary column , In this part, you can go to the official documents .
If I check the beginning of page 3 10 strip , Then it will find the third page of the sub table in all databases 10 strip , Consolidated results , Then intercept the data .
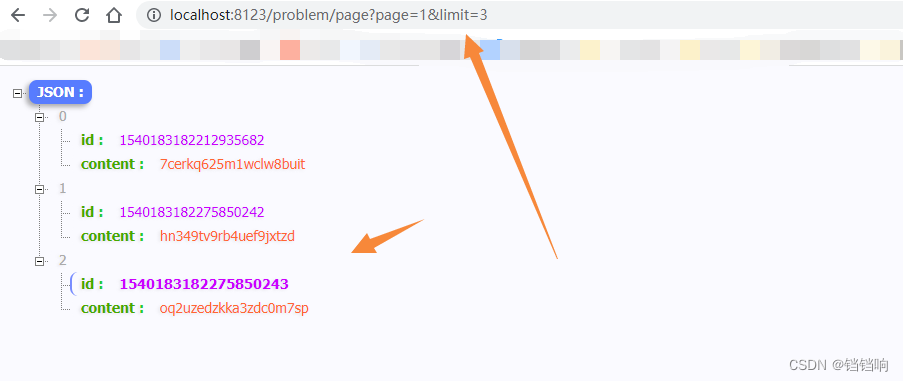
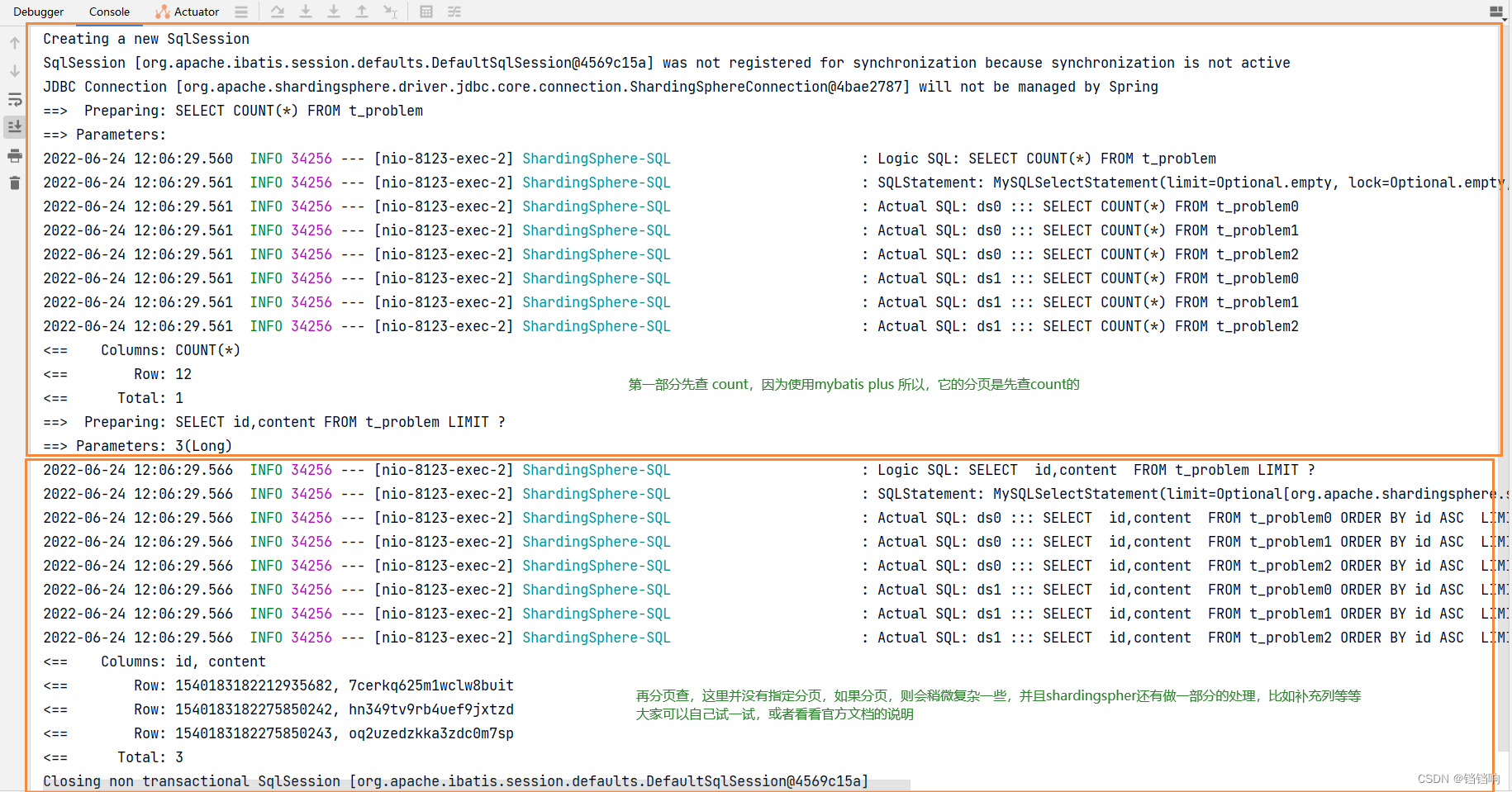
2、 The console log is as follows :
3.3.4、id Interface
1、 Request interface 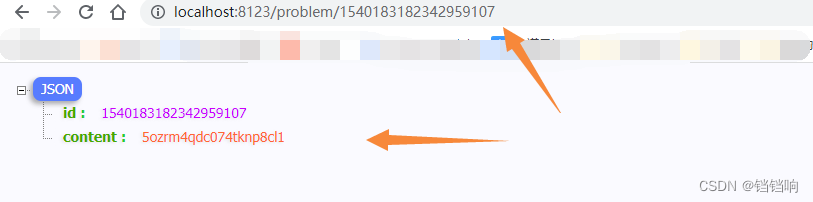
2、 Console log 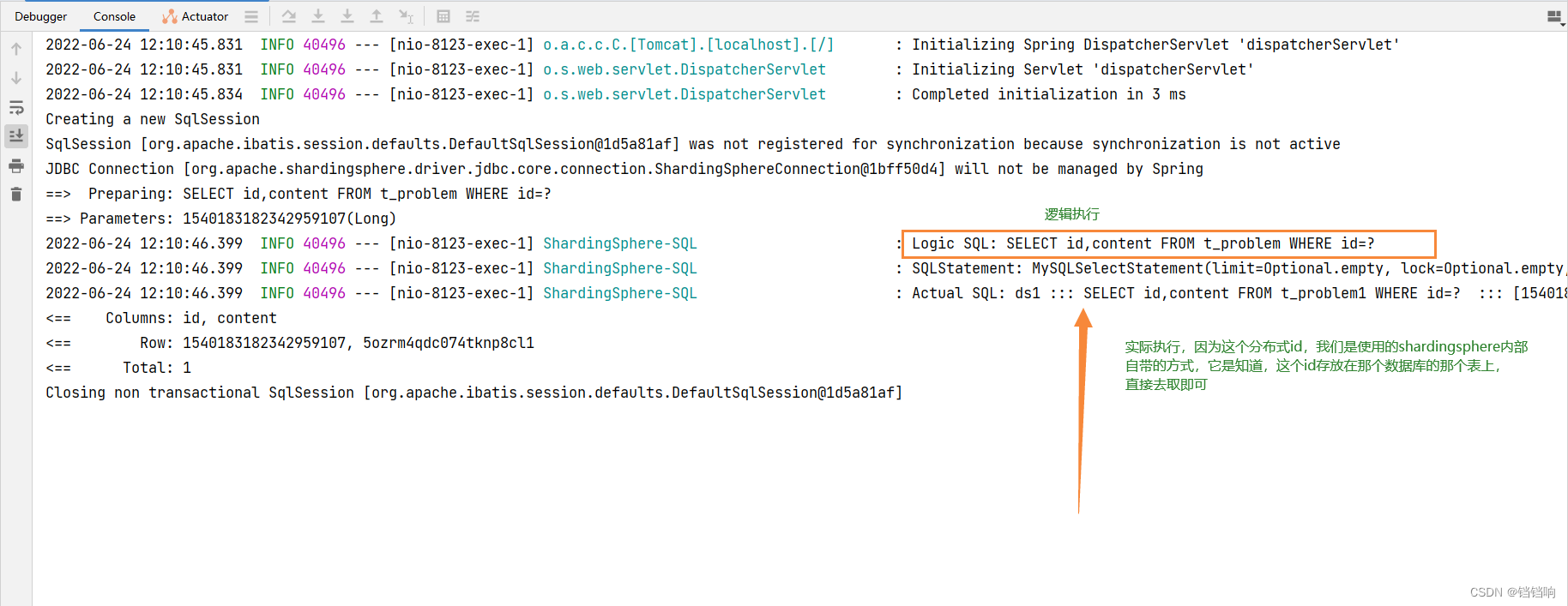
Four 、 Use cases – Binding table (bindTable)
4.1、 Database format
1、 Database creation , Business table t_order And its associated sub table t_order_item, Distributed in 2 In Databases , And the sub tables are all for 3
2、 Data script
Note the related primary key id Are not set to self increase , And the type is bigInt, Because of the use of
shardingsphereBuilt in distributed id The generated value will be very large .
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_order0
-- ----------------------------
DROP TABLE IF EXISTS `t_order0`;
CREATE TABLE `t_order0` (
`id` bigint(0) NOT NULL,
`user_id` bigint(0) NULL DEFAULT NULL,
`order_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order1
-- ----------------------------
DROP TABLE IF EXISTS `t_order1`;
CREATE TABLE `t_order1` (
`id` bigint(0) NOT NULL,
`user_id` bigint(0) NULL DEFAULT NULL,
`order_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order2
-- ----------------------------
DROP TABLE IF EXISTS `t_order2`;
CREATE TABLE `t_order2` (
`id` bigint(0) NOT NULL,
`user_id` bigint(0) NULL DEFAULT NULL,
`order_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order_item0
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item0`;
CREATE TABLE `t_order_item0` (
`id` bigint(0) NOT NULL,
`order_id` bigint(0) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order_item1
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item1`;
CREATE TABLE `t_order_item1` (
`id` bigint(0) NOT NULL,
`order_id` bigint(0) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for t_order_item2
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item2`;
CREATE TABLE `t_order_item2` (
`id` bigint(0) NOT NULL,
`order_id` bigint(0) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
4.2、 Project code
1、application.yml The configuration is as follows :
I won't explain the specific content one by one , The relevant configurations inside have been explained very clearly
The main point is , The strategy of sub database and sub table
sub-treasuryds$->{id % 2}Description of id %2 , That's it 【ds0,ds1】, and ds0 and ds1 The data source is defined above
tablet_order$->{id % 3}Explain the basis t_order Table inserted id %3, Namely 【t_order0,t_order1,t_order2】
And fort_order_itemCome on , And t_order The strategy of dividing the database and table of the table should be consistent , therefore , It usest_order_itemOforder_idFields to separate databases and tables , And rules andt_orderbring into correspondence with , This is stated in the official document .
spring:
sharding-sphere: # mode.type The default is memory mode startup
props:
# Exhibition sql
sql-show: true
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
rules:
sharding:
sharding-algorithms:
t-order-db-inline:
props:
algorithm-expression: ds$->{
id % 2}
type: INLINE
t-order-table-inline:
props:
algorithm-expression: t_order$->{
id % 3}
type: INLINE
t-order-item-db-inline:
props:
algorithm-expression: ds$->{
order_id % 2}
type: INLINE
t-order-item-table-inline:
props:
algorithm-expression: t_order_item$->{
order_id % 3}
type: INLINE
tables:
t_order:
actual-data-nodes: ds$->{
0..1}.t_order$->{
0..2}
database-strategy: # Sub library strategy
standard: # Standard slicing scenarios for single slicing keys ,( Distinguishing multiple column IDS is a complex situation , take standard Switch to complex( That is, the name of the partition column , Multiple columns are separated by commas ))
sharding-algorithm-name: t-order-db-inline # name , Use on top
sharding-column: id # That field is passed to the following algorithm
table-strategy: # Tabulation strategy
standard:
sharding-algorithm-name: t-order-table-inline
sharding-column: id # That field is passed to the following algorithm
key-generate-strategy: # t_order Table primary key order_id Generated strategies https://blog.csdn.net/chinawangfei/article/details/114675854
column: id # t_order Primary Key id Need to use snowflake Algorithm
keyGeneratorName: t-order-snowflake # The key here is modified It doesn't seem to work , This is the most outrageous , The snowflake algorithm is used by default
t_order_item:
actual-data-nodes: ds$->{
0..1}.t_order_item$->{
0..2}
database-strategy:
standard:
sharding-algorithm-name: t-order-item-db-inline
sharding-column: order_id
table-strategy:
standard:
sharding-algorithm-name: t-order-item-table-inline
sharding-column: order_id
key-generate-strategy:
column: id
keyGeneratorName: t-order-item-snowflake
key-generators:
t-order-snowflake:
type: snowflake
props:
worker-id: 1
t-order-item-snowflake:
type: snowflake
props:
worker-id: 1
binding-tables:
- t_order,t_order_item # Binding table , It can avoid the formation of Cartesian product in the associated query , Note that the database and table splitting algorithms between bound tables must be consistent , For example, above t_order and t_order_item Is to use order_id As the basis of sub database and sub table 【 among t_order stay FROM The far left side of ,ShardingSphere It will be used as the main table of the whole binding table . All routing calculations will use only the primary table policy , that t_order_item The slice calculation of the table will use t_order Conditions . So the partition keys between binding tables should be exactly the same 】
server:
port: 8123
mybatis-plus:
configuration:
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.gxm.shardingspheretest.model
2、model Definition , Pay attention to the notes
- Order object
package cn.gxm.shardingspheretest.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/** * (Order) Table entity class * * @author GXM * @date 2022-06-21 15:07:00 */
@TableName("t_order")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order extends Model<Order> {
/** * 1、 It must be used here Long, Out of commission int perhaps integer because * Use shardSphere The value generated by the snowflake algorithm is very large , Already exceeded * Integer.MAX_VALUE(), Only use Long To store , And the database must also be bigint * Of course, if you choose to use the type of string , Then there are not so many things here * <p> * Notice the type Is the default value IdType.NONE, Don't set ,NONE Namely 【 User input ID This type can be filled by registering the auto fill plug-in 】 */
@TableId(value = "id")
private Long id;
@TableField("user_id")
private Long userId;
@TableField("order_name")
private String orderName;
}
- OrderItem object
package cn.gxm.shardingspheretest.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/** * @author GXM * @version 1.0.0 * @Description Order association table ( Current table and order Table is an associated table , It is also necessary to configure sub database and sub table , And the order Tables are set together as bound tables ) * @createTime 2022 year 06 month 23 Japan */
@TableName("t_order_item")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderItem {
/** * 1、 It must be used here Long, Out of commission int perhaps integer because * Use shardSphere The value generated by the snowflake algorithm is very large , Already exceeded * Integer.MAX_VALUE(), Only use Long To store , And the database must also be bigint * Of course, if you choose to use the type of string , Then there are not so many things here * <p> * Notice the type Is the default value IdType.NONE, Don't set ,NONE Namely 【 User input ID This type can be filled by registering the auto fill plug-in 】 */
@TableId(value = "id")
private Long id;
@TableField("order_id")
private Long orderId;
@TableField("name")
private String name;
}
3、mapper and service Just omit , And the usual configuration mybatis plus almost , But add the corresponding xml The contents of the document
<?xml version="1.0" encoding="UTF-8" ?>
<!-- ~ Licensed to the Apache Software Foundation (ASF) under one or more ~ contributor license agreements. See the NOTICE file distributed with ~ this work for additional information regarding copyright ownership. ~ The ASF licenses this file to You under the Apache License, Version 2.0 ~ (the "License"); you may not use this file except in compliance with ~ the License. You may obtain a copy of the License at ~ ~ http://www.apache.org/licenses/LICENSE-2.0 ~ ~ Unless required by applicable law or agreed to in writing, software ~ distributed under the License is distributed on an "AS IS" BASIS, ~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. ~ See the License for the specific language governing permissions and ~ limitations under the License. -->
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.gxm.shardingspheretest.mapper.OrderMapper">
<resultMap id="baseResultMap" type="cn.gxm.shardingspheretest.model.Order">
<result column="order_id" property="orderId" jdbcType="BIGINT"/>
<result column="user_id" property="userId" jdbcType="BIGINT"/>
<result column="order_name" property="orderName" jdbcType="VARCHAR"/>
</resultMap>
<!-- Custom insertion , The return of the primary key can be written like this -->
<insert id="selfInsert" useGeneratedKeys="true" keyProperty="orderId" parameterType="cn.gxm.shardingspheretest.model.Order">
INSERT INTO t_order (user_id, order_name)
VALUES (#{userId,jdbcType=INTEGER}, #{orderName,jdbcType=VARCHAR});
</insert>
<!-- Check whether the binding table is effective Corresponding sql -->
<select id="bindTableByOrderId" parameterType="java.lang.Long" resultType="cn.gxm.shardingspheretest.dto.OrderDTO">
SELECT a.id as order_id, a.user_id, a.order_name, b.id as item_id, b.`name` as item_name
from t_order a
LEFT JOIN t_order_item b on a.id = b.order_id
where a.id = #{orderId,jdbcType=BIGINT};
</select>
<select id="bindTableByOrderIdWithIn" parameterType="java.lang.Long" resultType="cn.gxm.shardingspheretest.dto.OrderDTO">
SELECT a.id as order_id, a.user_id, a.order_name, b.id as item_id, b.`name` as item_name
from t_order a
LEFT JOIN t_order_item b on a.id = b.order_id
where a.id in (#{orderId,jdbcType=BIGINT})
</select>
</mapper>
4、 Create a new one controller Use it for testing , The contents are as follows
package cn.gxm.shardingspheretest.controller;
import cn.gxm.shardingspheretest.dto.OrderDTO;
import cn.gxm.shardingspheretest.model.Order;
import cn.gxm.shardingspheretest.model.OrderItem;
import cn.gxm.shardingspheretest.service.OrderItemService;
import cn.gxm.shardingspheretest.service.OrderService;
import cn.hutool.core.util.RandomUtil;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 21 Japan */
@RestController
@RequestMapping("/order")
public class OrderController {
private final OrderService orderService;
private final OrderItemService orderItemService;
@Autowired
public OrderController(OrderService orderService, OrderItemService orderItemService) {
this.orderService = orderService;
this.orderItemService = orderItemService;
}
@GetMapping("/{id}")
public Order getById(@PathVariable String id) {
return this.orderService.getById(id);
}
@GetMapping("list")
public List<Order> list() {
return this.orderService.list();
}
/** * The more you get the data behind the offset position , Use LIMIT The less efficient paging is , * Here's the solution ( There are many ways to avoid using LIMIT paging ) * 1、 For example, construct a secondary index of the number of row records and the row offset * 2、 Or end with the last paging data ID Pagination as the next query condition, etc ( Must not skip page query ) * <p> * Paging is very uncomfortable , For example, you now have two databases , Each database is divided into 3 A watch , amount to One t_order surface , Is divided into 6 A watch , and * If you query by page The first 3 page 100 Data (page=3,limit=100), In fact, it is equivalent to checking 6 Tabular 3*100 The data of , Then put it all together , Get in paging 100 strip . * So the slower you ask later * <p> * Be careful ,shardingSphere stay 5.0.0 After the version , Turn on memory limit mode And connection limited mode , We just need to configure maxConnectionSizePerQuery , Will be based on * Formula to calculate , Use memory limit mode or link limit mode * but shardingSphere Part of the processing will be carried out 【 Merge results by moving the result set cursor down , It's called flow merging , It does not need to load all the result data into memory 】 * * @param page page * @param limit limit * @return pojo */
@GetMapping("page")
public List<Order> page(@RequestParam("page") Integer page, @RequestParam("limit") Integer limit) {
Page<Order> orderPage = this.orderService.page(new Page<>(page, limit));
return orderPage.getRecords();
}
@GetMapping("/count")
public Integer count() {
return this.orderService.count();
}
@GetMapping("/mock")
public String mock() {
for (int i = 0; i < 12; i++) {
final Order order = new Order();
order.setUserId((long) i);
order.setOrderName(RandomUtil.randomString(20));
this.orderService.save(order);
}
return "SUCCESS";
}
/** * order by There will be a case of supplementary columns * Please refer to the official documents https://shardingsphere.apache.org/document/5.0.0/cn/reference/sharding/rewrite/ * * @param page page * @param limit limit * @return json string */
@GetMapping("/orderBy")
public String orderBy(@RequestParam(value = "page", required = false) Integer page,
@RequestParam(value = "limit", required = false) Integer limit) {
LambdaQueryWrapper<Order> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// For example, I only inquire here order_name Column , But because you sort using OrderId, And finally merge 6 Table data , According to order_id Sort , therefore ,
// Even if you didn't say to query this column ,sharding-sphere This field will also be added . as follows
// SELECT
// order_name
// , order_id AS ORDER_BY_DERIVED_0 FROM t_order0
//
// ORDER BY order_id ASC LIMIT ?,? ::: [0, 12]
lambdaQueryWrapper.select(Order::getOrderName);
lambdaQueryWrapper.orderByAsc(Order::getId);
if (page == null || limit == null) {
return JSONUtil.toJsonStr(this.orderService.list(lambdaQueryWrapper));
}
return JSONUtil.toJsonStr(this.orderService.page(new Page<>(page, limit), lambdaQueryWrapper));
}
public String testXA() {
// xas
// XAShardingSphereTransactionManager
return "ok";
}
/** * Test the encryption and decryption fields * * @return */
public String testCipher() {
return "ok";
}
/** * Test the binding table Use t_order and t_order_item * There will be no Cartesian product association in multi table Association queries between bound tables , The efficiency of association query will be greatly improved * * @return */
@GetMapping("/bindTable/mock")
public String mockWithBindTable() {
for (int i = 0; i < 1; i++) {
// 1、 Insert order surface
Order orderMock = new Order();
// This order id We don't need to set , We are shardingSphere Set the primary key of the table to use shardingSphere Built in snowflake Algorithm
// orderMock.setOrderId();
orderMock.setUserId((long) i);
orderMock.setOrderName(RandomUtil.randomString(20));
orderService.save(orderMock);
// orderService.selfInsert(orderMock);
// 2、 Insert t_order_item surface
OrderItem orderItemMock = new OrderItem();
// id We don't need to set , We are shardingSphere Set the primary key of the table to use shardingSphere Built in snowflake Algorithm
// orderItemMock.setItemId();
orderItemMock.setOrderId(orderMock.getId());
orderItemMock.setName(RandomUtil.randomString(20));
orderItemService.save(orderItemMock);
}
return "ok";
}
/** * Relational query order and order_item * * @param orderId * @return */
@GetMapping("bindTable/{orderId}")
public OrderDTO bindTableByOrderId(@PathVariable("orderId") Long orderId) {
OrderDTO orderDTO = orderService.bindTableByOrderId(orderId);
return orderDTO;
}
/** * 【 At this time, because we have configured the binding table , There will be no Cartesian product 】 * * @param orderId * @return */
@GetMapping("bindTableWithIn/{orderId}")
public OrderDTO bindTableByOrderIdWithIn(@PathVariable("orderId") Long orderId) {
List<OrderDTO> orderDTOS = orderService.bindTableByOrderIdWithIn(orderId);
return orderDTOS.get(0);
}
}
4.3、 Test and analysis
4.3.1、/bindTable/mock Interface
1、 call /bindTable/mock Interface 
2、 The console log is as follows 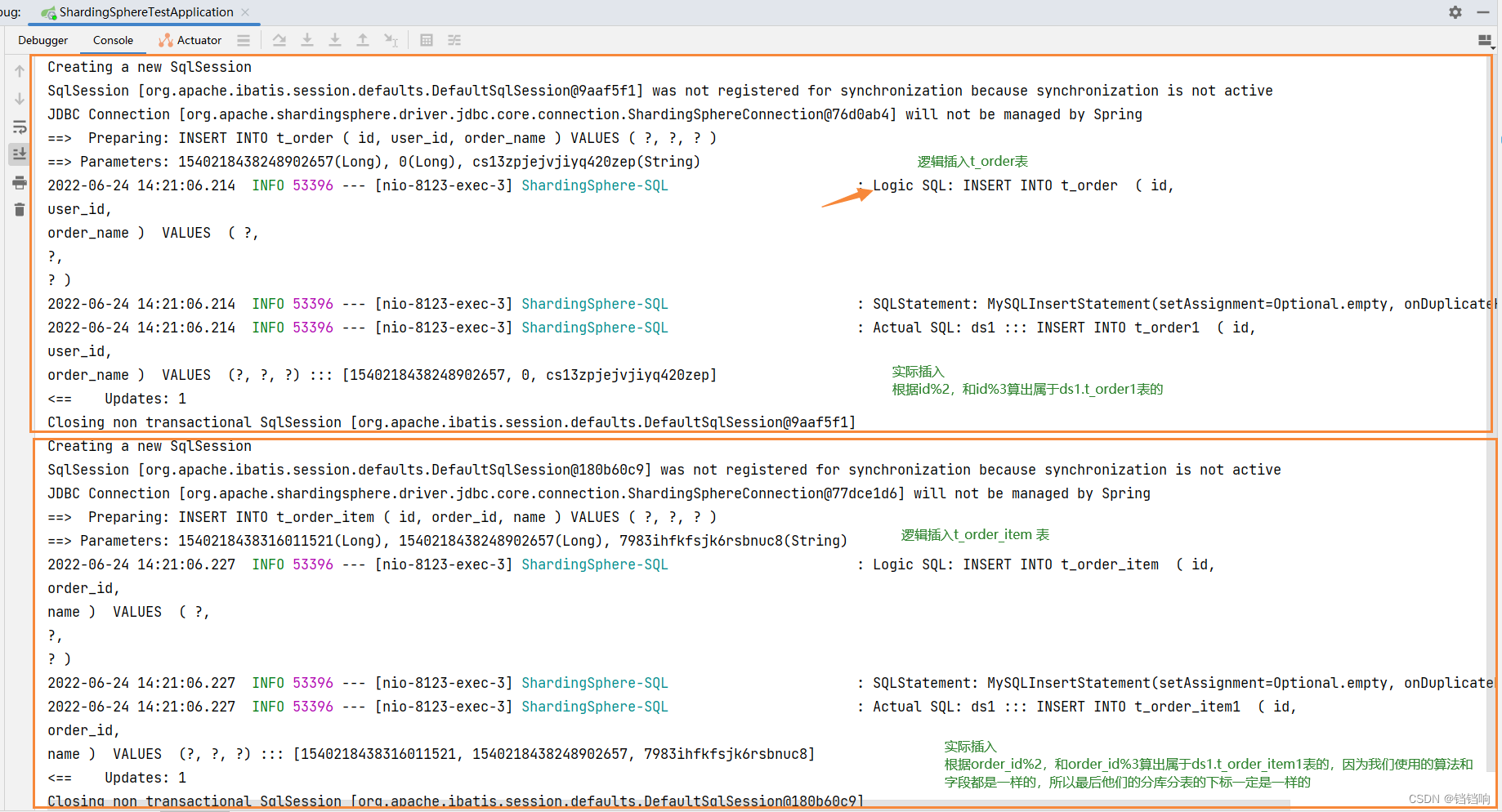
3、 Database data 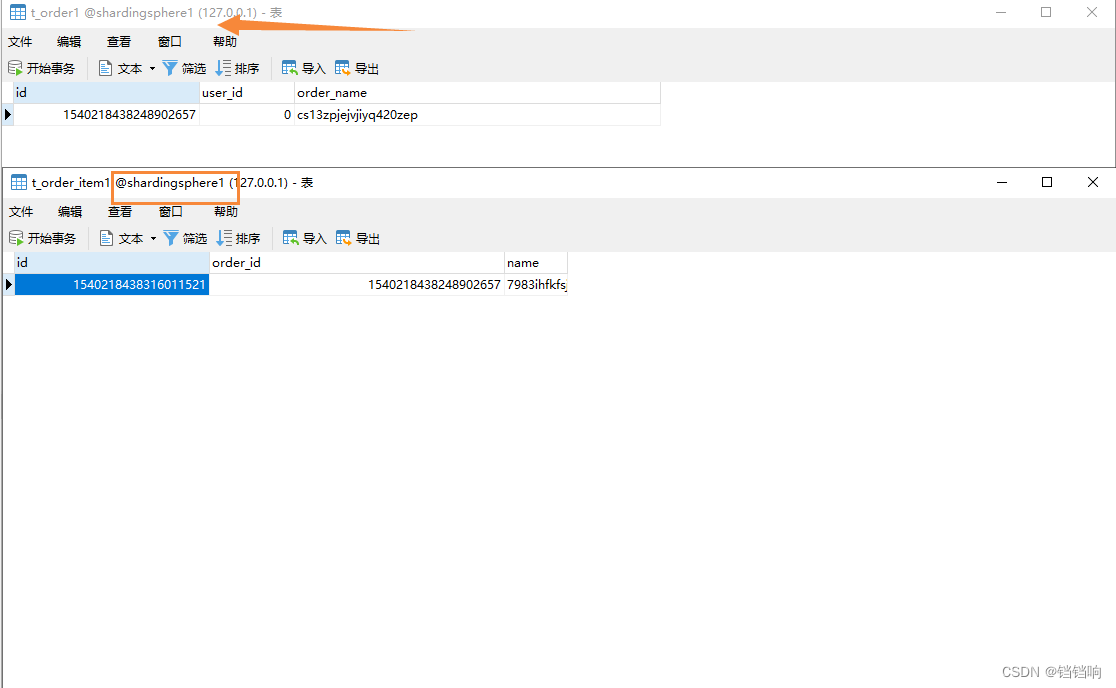
4.3.2、bindTable/{orderId} Interface ( Use ==)
1、 According to the front mock Generated order_id request , For more details 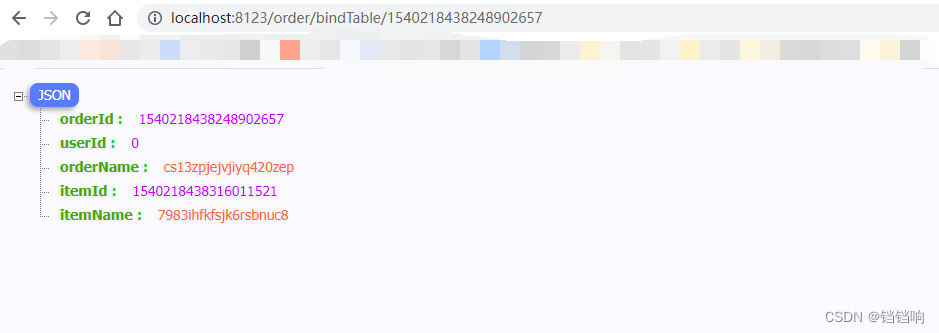
2、 Console log 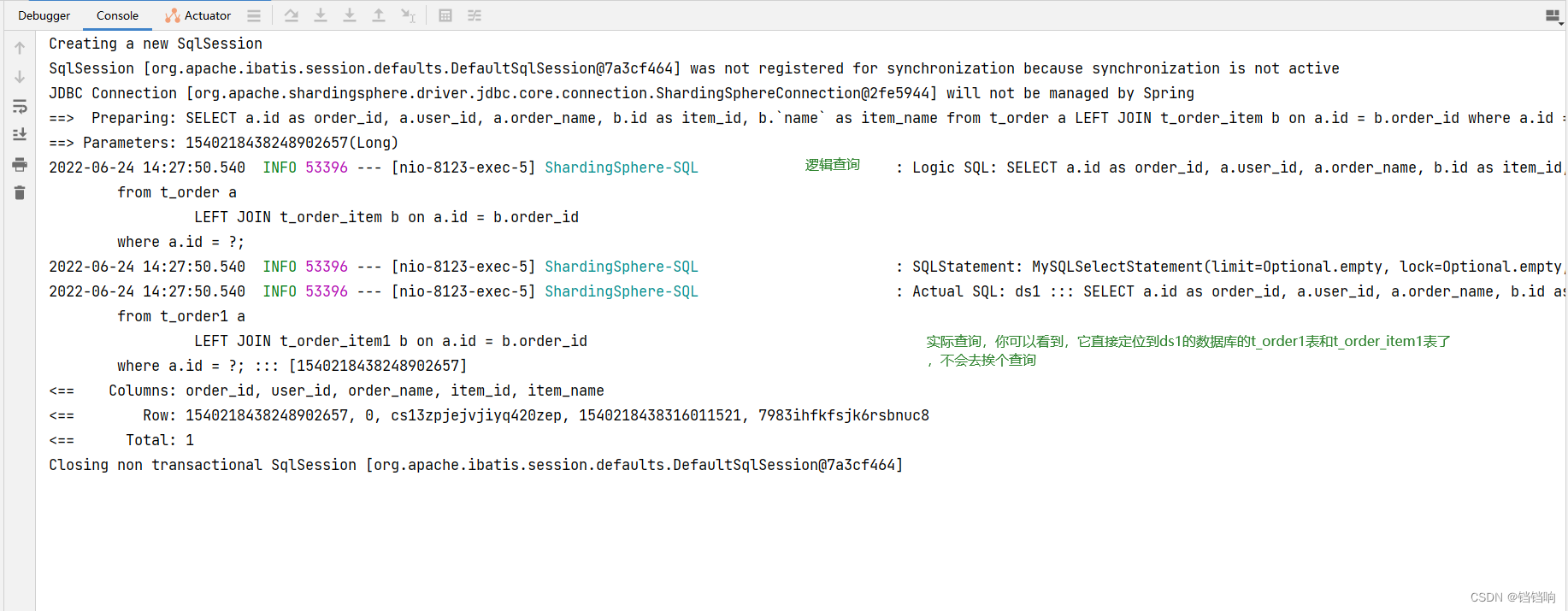
4.3.3、bindTableWithIn/{orderId} Interface ( Use in)
1、 According to the front mock Generated order_id request , For more details 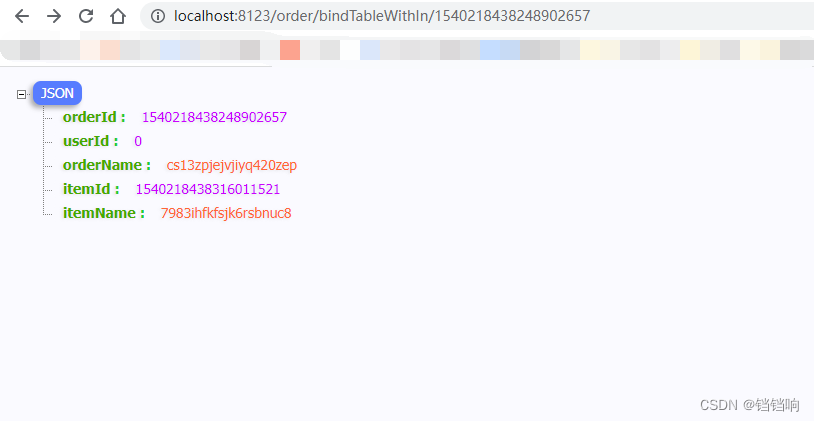
2、 Console log 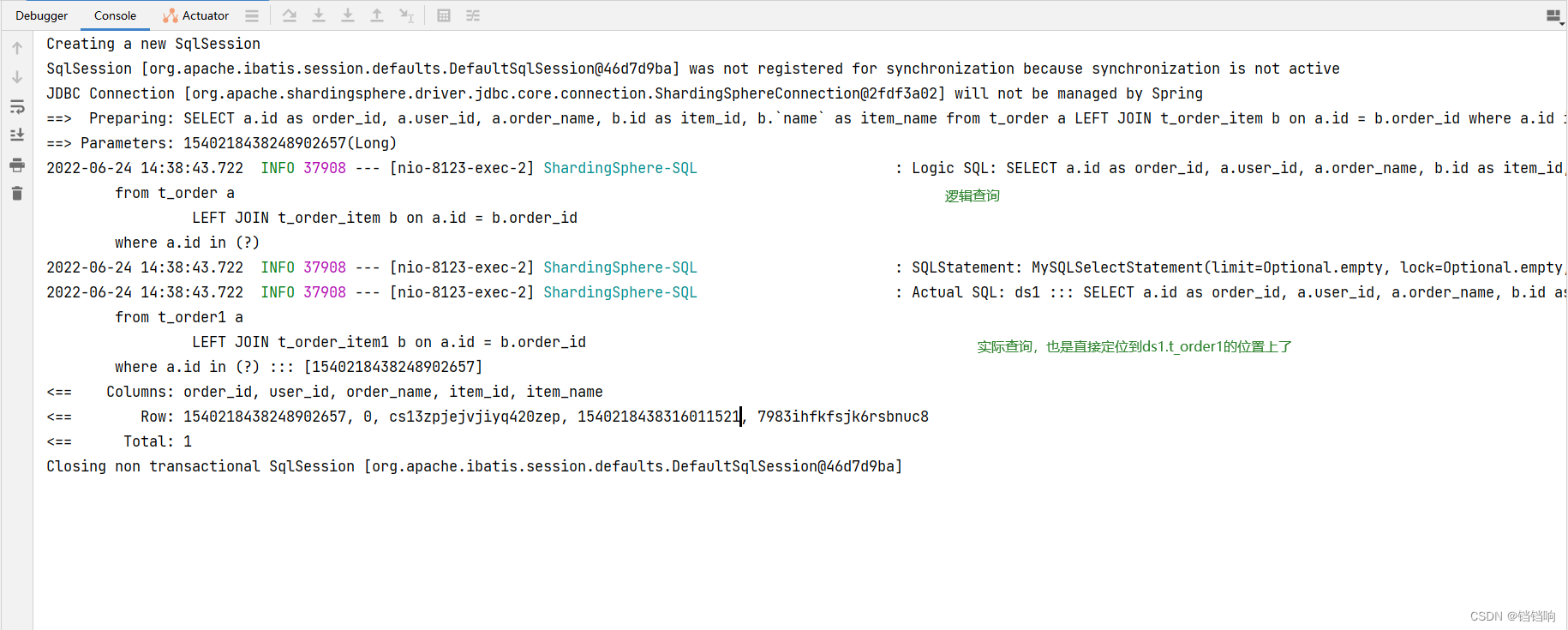
4.3.3、orderBy Interface
1、 Let's call mock Interface , Generate corresponding 12 Data , According to id Sort query 
2、 The console log is as follows

5、 ... and 、 Use cases – Broadcast table (bindTable)
5.1、 Database format
1、 Database creation , Business table t_user, Distributed in 2 In Databases , And the data structure is the same , And no table
The definition of broadcast table has been mentioned before , Every sub Treasury has , But no table .
2、 Data script
Note the related primary key id Are not set to self increase , And the type is bigInt, Because of the use of
shardingsphereBuilt in distributed id The generated value will be very large .
CREATE TABLE `t_user` (
`id` bigint NOT NULL,
`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`sex` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
5.2、 Project code
1、application.yml The configuration is as follows , You can see , We don't need to configure the two-point rule of sub database and sub table for this broadcast table , because , The default is that the table data of the two databases are the same , The only thing to note is this primary key id Still need to let shardingSphere To produce
spring:
sharding-sphere: # mode.type The default is memory mode startup
props:
# Exhibition sql
sql-show: true
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
rules:
sharding:
tables:
t_user: # The broadcast table does not fragment the data , So configure sub database , The split table rule will not take effect
key-generate-strategy:
column: id
keyGeneratorName: t-user-snowflake
key-generators:
t-user-snowflake:
type: snowflake
props:
worker-id: 1
broadcast-tables:
- t_user # 【 It refers to the table that exists in all fragmentation data sources 】, The table structure and its data are completely consistent in each database . It is suitable for scenarios where the amount of data is not large and needs to be associated with massive data tables , for example : Dictionary table .
server:
port: 8123
mybatis-plus:
configuration:
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.gxm.shardingspheretest.model
2、model Code
package cn.gxm.shardingspheretest.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/** * @author GXM * @version 1.0.0 * @Description User table ( Use it as a broadcast table ) * @createTime 2022 year 06 month 24 Japan */
@TableName("t_user")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User extends Model<User> {
/** * 1、 It must be used here Long, Out of commission int perhaps integer because * Use shardSphere The value generated by the snowflake algorithm is very large , Already exceeded * Integer.MAX_VALUE(), Only use Long To store , And the database must also be bigint * Of course, if you choose to use the type of string , Then there are not so many things here * <p> * Notice the type Is the default value IdType.NONE, Don't set ,NONE Namely 【 User input ID This type can be filled by registering the auto fill plug-in 】 */
@TableId(value = "id")
private Long id;
@TableField("name")
private String name;
@TableField("sex")
private String sex;
}
3、mapper and service Just omit , And the usual configuration mybatis plus almost ,
4、 Add one more controller, Let's test it
package cn.gxm.shardingspheretest.controller;
import cn.gxm.shardingspheretest.model.User;
import cn.gxm.shardingspheretest.service.UserService;
import cn.hutool.core.util.RandomUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 24 Japan */
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
private final UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
@GetMapping("/mock")
public String mock() {
for (int i = 0; i < 100; i++) {
User user = new User();
user.setName(RandomUtil.randomString(10));
user.setSex(RandomUtil.randomString(1));
userService.save(user);
log.info("insert success");
}
return "ok";
}
@GetMapping("{userId}")
public User getById(@PathVariable("userId") Long userId) {
return userService.getById(userId);
}
@GetMapping("update/{userId}/{sex}")
public String update(@PathVariable("userId") Long userId,
@PathVariable("sex") String sex) {
User user = new User();
user.setId(userId);
user.setSex(sex);
userService.updateById(user);
return "ok";
}
}
5.3、 Test and analysis
5.3.1、mock Interface
1、 call mock Interface 
2、 The console log is as follows :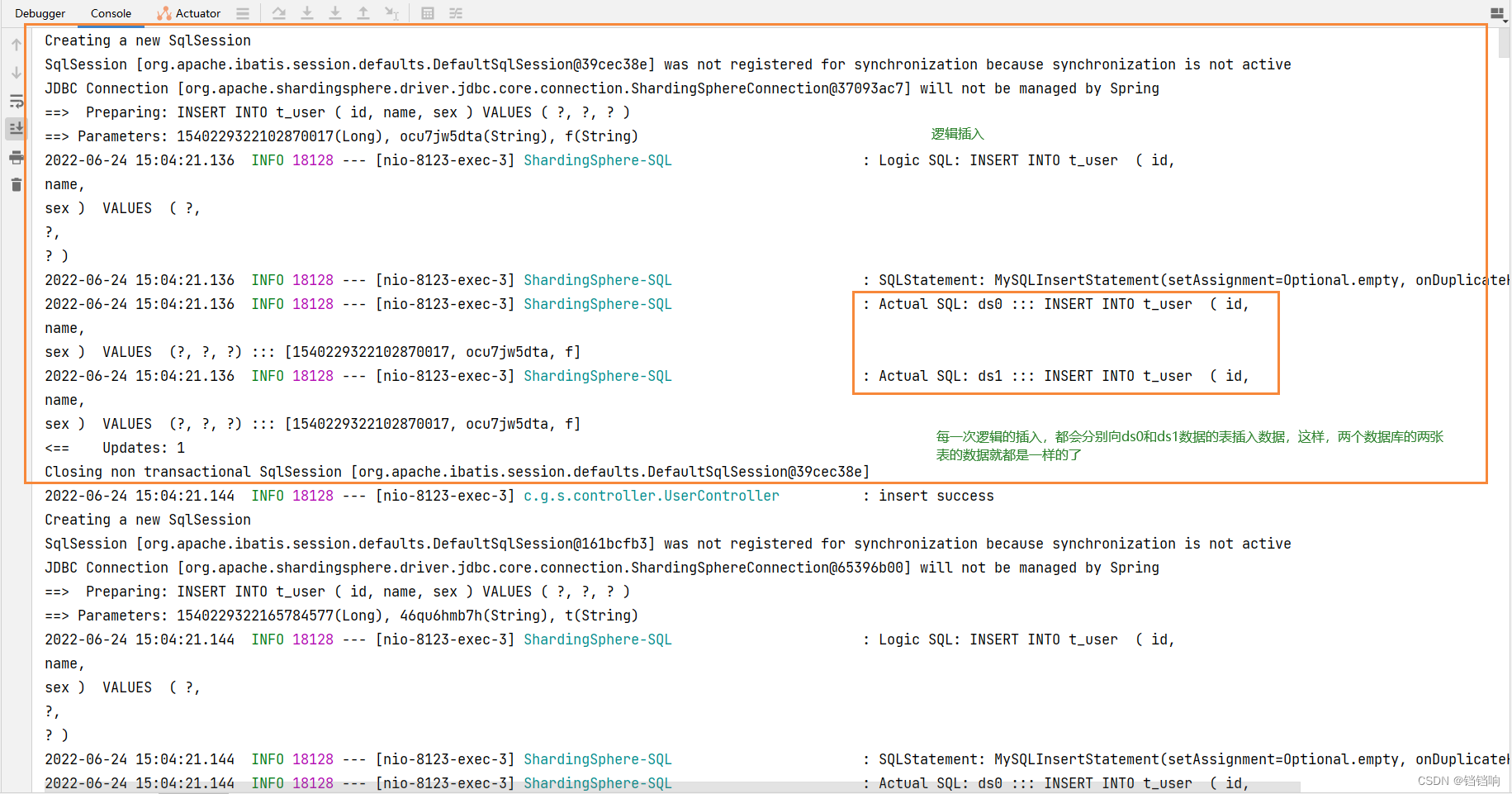
3、 Database data 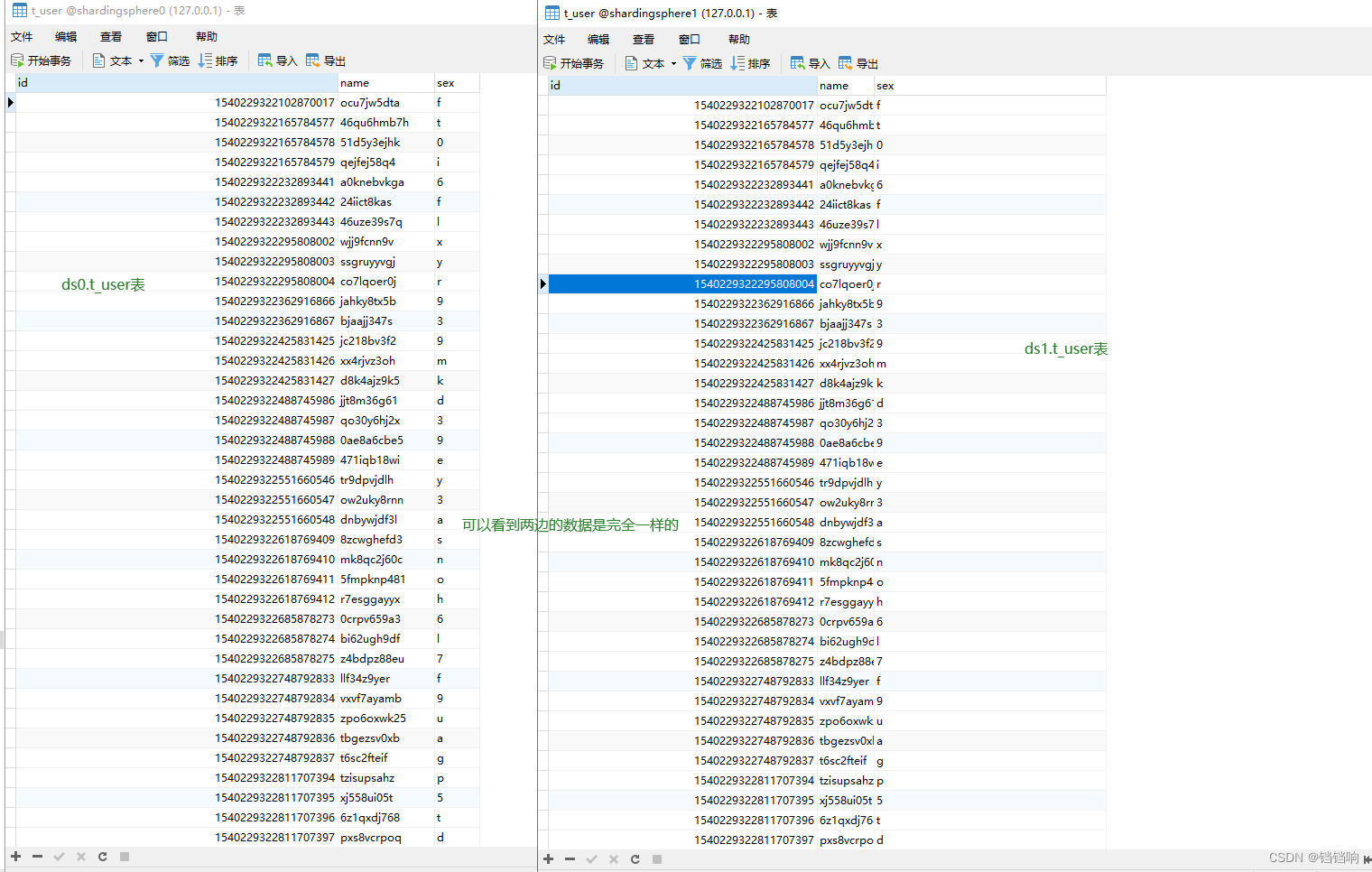
5.3.1、{userId} Interface
1、 call {userId} Interface
2、 Console log 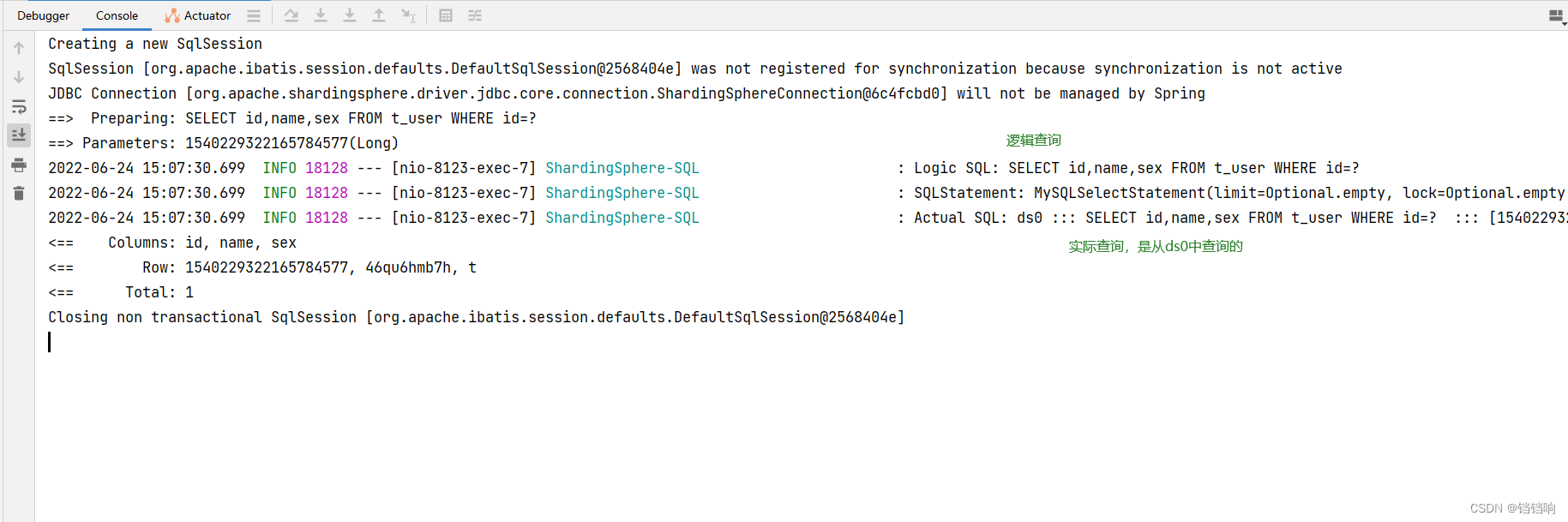
5.3.1、update/{userId}/{sex} Interface
1、 call update/{userId}/{sex} Interface
2、 Console log 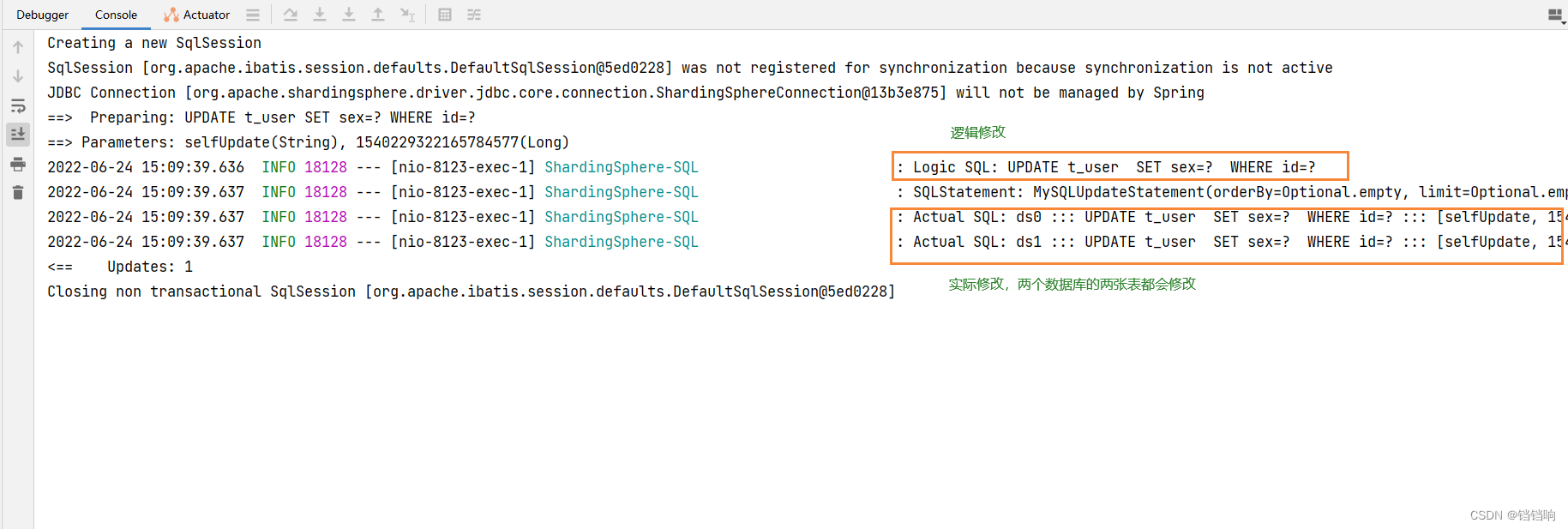
3、 Database data 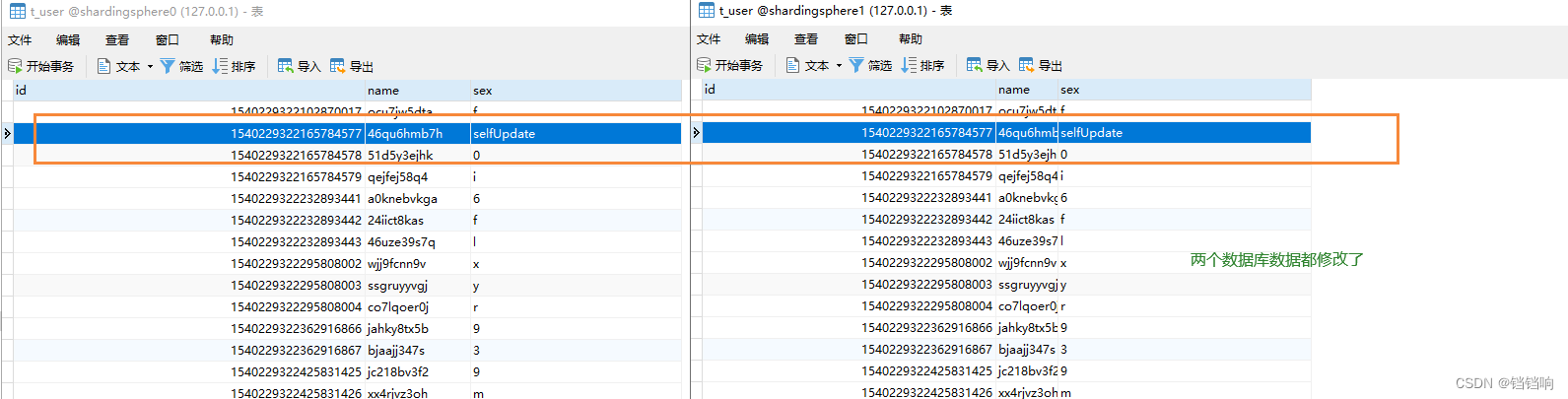
6、 ... and 、 Use cases – Single table (singleTable)
6.1、 Database format
1、 Database creation , Business table t_dict, Distributed in ds0 In these databases ,
It refers to the only table that exists in all fragmented data sources . It is suitable for tables with small amount of data and no need of segmentation .
2、 You can see , Only in ds0 There is this table in the database ,ds1 There is no database 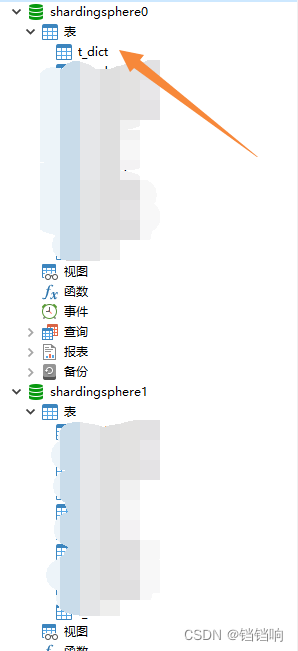
3、 Notice the primary key here id, I set the database self increment , Because it is our ordinary watch , No participation shardingsphere The business of , therefore , How do you usually make such a watch , Just do it , that will do
CREATE TABLE `t_dict` (
`id` bigint NOT NULL AUTO_INCREMENT,
`type` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
6.2、 Project code
1、application.yml The configuration is as follows , In fact, the single watch is shrdingsphere Of 5.0.0 After the version , There is no need to do any configuration , It will automatically find , In theory , I directly configure ds0 and ds1 The data source is just , There is no need to configure anything else , But if you configure it like this , It means that your project does not use shardingsphere Any function of , It will report an error , So it means that you used shardingsphere You have to have a table with separate databases and tables , therefore , Even if I don't use the configuration of broadcast table here ( Of course, you can change this configuration to anything else , You have to let shardingsphere I know you use some functions ), I'd better configure it , In this way, it will not report an error when it starts .
spring:
sharding-sphere: # mode.type The default is memory mode startup
props:
# Exhibition sql
sql-show: true
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
rules:
sharding:
tables:
t_user: # The broadcast table does not fragment the data , So configure sub database , The split table rule will not take effect
key-generate-strategy:
column: id
keyGeneratorName: t-user-snowflake
key-generators:
t-user-snowflake:
type: snowflake
props:
worker-id: 1
broadcast-tables:
- t_user # 【 It refers to the table that exists in all fragmentation data sources 】, The table structure and its data are completely consistent in each database . It is suitable for scenarios where the amount of data is not large and needs to be associated with massive data tables , for example : Dictionary table .
server:
port: 8123
mybatis-plus:
configuration:
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.gxm.shardingspheretest.model
2、model, Pay attention to the... Used here @TableId(value = "id", type = IdType.AUTO), Because this is an ordinary business table , Primary key I choose to let the database generate ,shardingsphere Not involved in processing
package cn.gxm.shardingspheretest.model;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 22 Japan */
@TableName("t_dict")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Dict extends Model<Dict> {
@TableId(value = "id", type = IdType.AUTO)
private Long id;
@TableField("type")
private String type;
}
3、mapper and service Just omit , And the usual configuration mybatis plus almost ,
4、 Add one more controller, Let's test it
package cn.gxm.shardingspheretest.controller;
import cn.gxm.shardingspheretest.model.Dict;
import cn.gxm.shardingspheretest.service.DictService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/** * @author GXM * @version 1.0.0 * @Description TODO * @createTime 2022 year 06 month 22 Japan */
@RequestMapping("/dict")
@RestController
public class DictController {
private final DictService dictService;
@Autowired
public DictController(DictService dictService) {
this.dictService = dictService;
}
/** * This table only exists in shardingsphere0 database * shardSphere 5.0.0 No configuration for version default-datasource, It will automatically determine which database this table is in * The previous version ( < 5.0.0) You need to configure this parameter , Identify the default database location for a single table * * @return */
@GetMapping("/mock")
public String mock() {
for (int i = 0; i < 100; i++) {
Dict dict = new Dict();
dict.setType(String.valueOf(i));
this.dictService.save(dict);
System.out.println();
}
return "ok";
}
}
6.3、 test
6.3.1、mock The interface test
1、 Request interface 
2、 Console log 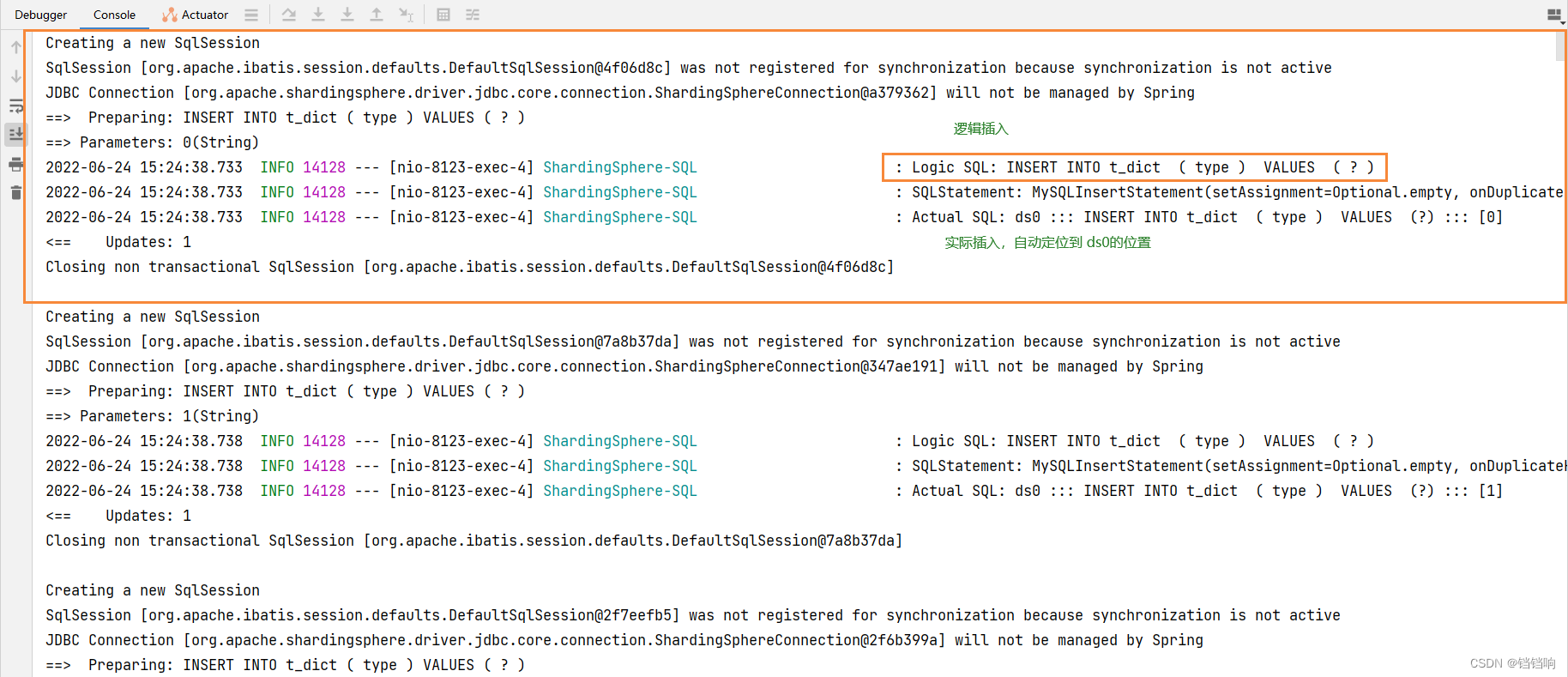
3、 Database content
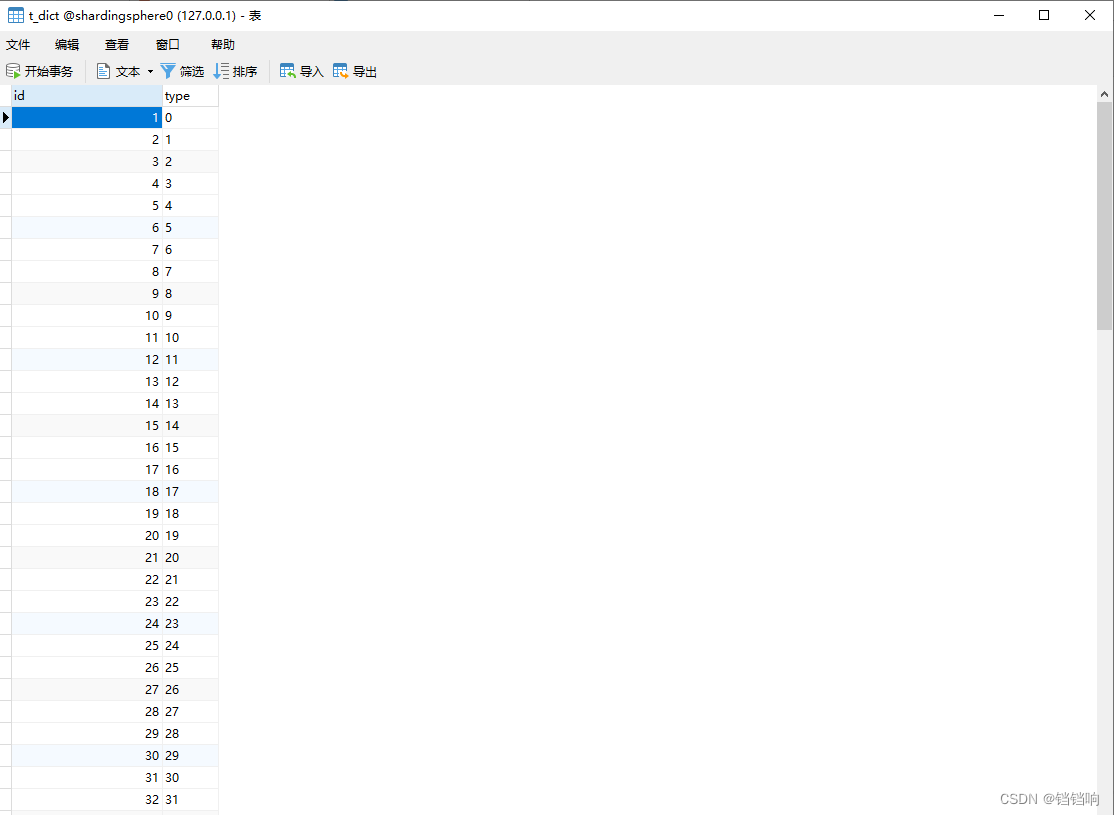
7、 ... and 、 Use cases – Mix the above situations
1、yml The documents are as follows
spring:
sharding-sphere: # mode.type The default is memory mode startup
props:
# Exhibition sql
sql-show: true
datasource:
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/shardingsphere1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT&allowPublicKeyRetrieval=true
password: 123456
type: com.zaxxer.hikari.HikariDataSource
username: root
names: ds0,ds1
rules:
sharding:
sharding-algorithms:
t-problem-db-inline: # be known as t-problem-db-inline The algorithm of the sub database strategy
props:
algorithm-expression: ds$->{
id % 2}
type: INLINE
t-problem-table-inline: # be known as t-problem-table-inline Algorithm of table splitting strategy
props:
algorithm-expression: t_problem$->{
id % 3}
type: INLINE
t-order-db-inline:
props:
algorithm-expression: ds$->{
id % 2}
type: INLINE
t-order-table-inline:
props:
algorithm-expression: t_order$->{
id % 3}
type: INLINE
t-order-item-db-inline:
props:
algorithm-expression: ds$->{
order_id % 2}
type: INLINE
t-order-item-table-inline:
props:
algorithm-expression: t_order_item$->{
order_id % 3}
type: INLINE
tables:
t_problem:
actual-data-nodes: ds$->{
0..1}.t_problem$->{
0..2}
database-strategy: # Sub library strategy
standard: # Standard slicing scenarios for single slicing keys ,( Distinguishing multiple column IDS is a complex situation , take standard Switch to complex( That is, the name of the partition column , Multiple columns are separated by commas ))
sharding-algorithm-name: t-problem-db-inline # name , Use on top
sharding-column: id # That field is passed to the following algorithm
table-strategy: # Tabulation strategy
standard:
sharding-algorithm-name: t-problem-table-inline
sharding-column: id # That field is passed to the following algorithm
key-generate-strategy: # t_problem Table primary key id Generated strategies https://blog.csdn.net/chinawangfei/article/details/114675854
column: id # t_order Primary Key id Need to use snowflake Algorithm
keyGeneratorName: t-problem-snowflake # The key here is modified It doesn't seem to work , This is the most outrageous , The snowflake algorithm is used by default
t_order:
actual-data-nodes: ds$->{
0..1}.t_order$->{
0..2}
database-strategy: # Sub library strategy
standard: # Standard slicing scenarios for single slicing keys ,( Distinguishing multiple column IDS is a complex situation , take standard Switch to complex( That is, the name of the partition column , Multiple columns are separated by commas ))
sharding-algorithm-name: t-order-db-inline # name , Use on top
sharding-column: id # That field is passed to the following algorithm
table-strategy: # Tabulation strategy
standard:
sharding-algorithm-name: t-order-table-inline
sharding-column: id # That field is passed to the following algorithm
key-generate-strategy: # t_order Table primary key order_id Generated strategies https://blog.csdn.net/chinawangfei/article/details/114675854
column: id # t_order Primary Key id Need to use snowflake Algorithm
keyGeneratorName: t-order-snowflake # The key here is modified It doesn't seem to work , This is the most outrageous , The snowflake algorithm is used by default
t_order_item:
actual-data-nodes: ds$->{
0..1}.t_order_item$->{
0..2}
database-strategy:
standard:
sharding-algorithm-name: t-order-item-db-inline
sharding-column: order_id
table-strategy:
standard:
sharding-algorithm-name: t-order-item-table-inline
sharding-column: order_id
key-generate-strategy:
column: id
keyGeneratorName: t-order-item-snowflake
t_user: # The broadcast table does not fragment the data , So configure sub database , The split table rule will not take effect
key-generate-strategy:
column: id
keyGeneratorName: t-user-snowflake
key-generators:
t-order-snowflake:
type: snowflake
props:
worker-id: 1
t-order-item-snowflake:
type: snowflake
props:
worker-id: 1
t-user-snowflake:
type: snowflake
props:
worker-id: 1
t-problem-snowflake:
type: snowflake
props:
worker-id: 1
binding-tables:
- t_order,t_order_item # Binding table , It can avoid the formation of Cartesian product in the associated query , Note that the database and table splitting algorithms between bound tables must be consistent , For example, above t_order and t_order_item Is to use order_id As the basis of sub database and sub table 【 among t_order stay FROM The far left side of ,ShardingSphere It will be used as the main table of the whole binding table . All routing calculations will use only the primary table policy , that t_order_item The slice calculation of the table will use t_order Conditions . So the partition keys between binding tables should be exactly the same 】
broadcast-tables:
- t_user # 【 It refers to the table that exists in all fragmentation data sources 】, The table structure and its data are completely consistent in each database . It is suitable for scenarios where the amount of data is not large and needs to be associated with massive data tables , for example : Dictionary table .
server:
port: 8123
mybatis-plus:
configuration:
cache-enabled: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.gxm.shardingspheretest.model
边栏推荐
- 软考中级电子商务师含金量高嘛?
- What are the contents of the intermediate soft test, the software designer test, and the test outline?
- ADB utility commands (network package, log, tuning related)
- Leetcode-304: two dimensional area and retrieval - matrix immutable
- How to prepare for the advanced soft test (network planning designer)?
- 深入理解Apache Hudi异步索引机制
- Unable to open kernel device '\.\vmcidev\vmx': operation completed successfully. Reboot after installing vmware workstation? Module "devicepoweron" failed to start. Failed to start the virtual machine
- Différences entre les contraintes monotones et anti - monotones
- 南航 PA3.1
- Simple and easy to modify spring frame components
猜你喜欢
【STM32】实战3.1—用STM32与TB6600驱动器驱动42步进电机(一)
![[OneNote] can't connect to the network and can't sync the problem](/img/28/9a02b1da0f43889989a9539c9fb6b6.png)
[OneNote] can't connect to the network and can't sync the problem
![1323: [example 6.5] activity selection](/img/2e/ba74f1c56b8a180399e5d3172c7b6d.png)
1323: [example 6.5] activity selection

July 10, 2022 "five heart public welfare" activity notice + registration entry (two-dimensional code)
SQL Server knowledge gathering 9: modifying data
MySQL insert data create trigger fill UUID field value
![P1031 [noip2002 improvement group] average Solitaire](/img/ba/6303f54d652fa7aa89440e314f8718.png)
P1031 [noip2002 improvement group] average Solitaire
软考中级有用吗??

Unity script generates configurable files and loads
使用Tansformer分割三维腹部多器官--UNETR实战
随机推荐
Schnuka: machine vision positioning technology machine vision positioning principle
JS implementation chain call
[recommendation system 01] rechub
Long list performance optimization scheme memo
Unity determines whether the mouse clicks on the UI
使用Tansformer分割三维腹部多器官--UNETR实战
SQL Server knowledge collection 11: Constraints
Is the soft test intermediate useful??
【机器学习 03】拉格朗日乘子法
Trajectory planning for multi robot systems: methods and Applications Overview reading notes
Deep understanding of Apache Hudi asynchronous indexing mechanism
Unity script visualization about layout code
Deep understanding of Apache Hudi asynchronous indexing mechanism
Unity script generates configurable files and loads
如何顺利通过下半年的高级系统架构设计师?
Arduino board description
枪出惊龙,众“锁”周之
Deeply understand the characteristics of database transaction isolation
软考中级,软件设计师考试那些内容,考试大纲什么的?
简单易修改的弹框组件