当前位置:网站首页>Easy processing of ten-year futures and stock market data -- Application of tdengine in Tongxinyuan fund
Easy processing of ten-year futures and stock market data -- Application of tdengine in Tongxinyuan fund
2022-07-05 03:16:00 【songroom】
Easy processing of ten-year futures and stock market data ——TDengine Application in concentric source Fund
Concentric source ( sanya ) fund Liu Jian Dec 08, 2021 / classification Chinese、 User stories 、 Top recommendation
Small T Reading guide : Concentric source ( sanya ) Fund Management Co., Ltd. is a company committed to adopting scientific methods , Private equity companies investing in the secondary market . The team members of the company are from excellent universities at home and abroad , The founder has a PhD in computer , Many years of algorithm research 、 Experience in software system development .
Starting from our business model , Business personnel mainly discover the trading rules of the market through data mining and automatic pattern recognition . therefore , Our work scenario is based on a large amount of financial data , It mainly includes the following categories :
Real time high-frequency data of domestic futures market , Item by item data, etc
Historical high-frequency data of domestic futures market , Data by data
High frequency data of domestic stock market , Item by item data, etc
Historical high-frequency data of domestic stock market , Data by data
A larger amount of level derivative data generated from the above data
After years of development , The stock market has a huge amount of data , With the cleaning and writing of new data every day , The total amount has become even higher . For more than a dozen TB The amount of data , Storage alone is not easy , If you need to query and download the data , Even more difficult . These problems lie before us , It also makes us lose confidence in the mainstream databases on the market .
later , After the introduction of professionals , We tried TDengine, I didn't expect it to easily adapt to our current business .
Specific practice and landing effect
After selecting the database, we immediately started to build , And chose the latest 2.1.3.2 The version of is deployed , The databases corresponding to different data types are as follows :
1) Stock high frequency database , Including the historical data of the stock market + Daily new data :
Such data are passed daily through Python The way of the connector , After closing, batch import and then analyze . Each table represents a stock , common 85 Column , With Float Data based , common 32311 Zhang .
According to the above table, the structure is calculated , The current situation is about... Per line 408 The length of bytes , Then we use the script to query the row number of all tables , Probably 320 Billion rows .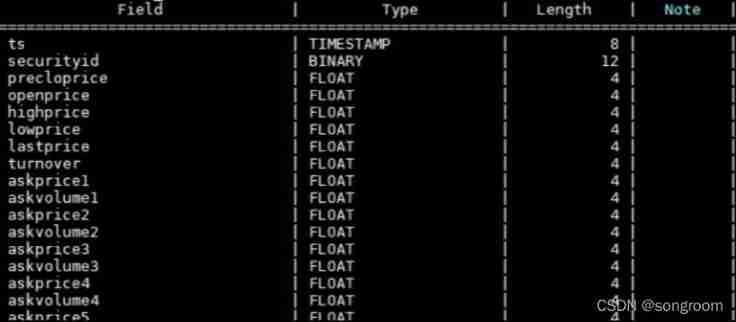
Based on the above data, the total amount of data received is estimated , The rough calculation is 408*320 Billion rows , Probably 12TB about , After statistics, the actual disk space occupied is only 2T about , This shocked us —— Compression up to 16.7%.

as everyone knows ,Float Type data compression has always been a difficult problem in the field of database , Especially for the database with line storage , Thank you very much for your pleasure TDengine Column storage of , Helped us solve this thorny problem perfectly .
Then we learned from officials , In later versions ,TDengine Further algorithm optimization is also done for floating-point data , The compression ratio can also be greatly improved . But now you need to compile it manually , You can contact the official for specific operation .
2) Futures warehouse :
The futures library is deployed on another server , There are three : Futures high frequency database 、 futures X Frequency database 、 futures Y Frequency database . They represent the high-frequency data of all domestic futures and the aggregated data of different time and frequency :
Futures high frequency database : Real time recording of information sent by the exchange tick data
futures X Frequency database : According to the time period X Set up , Record the aggregated data
futures Y Frequency database : According to the time period Y Set up , Record the aggregated data
The above three libraries contain 3351、5315、5208 Zhang Zibiao , Like a stock pool , They also include long-term historical data and real-time data .
The specific table structure is as follows :
In terms of inquiry , At present, our query is only for a single table , So the logic is simple , The code is as follows :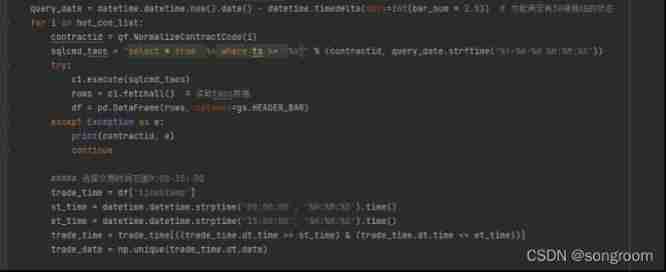
Besides , As there is no market for futures for many consecutive years , So for long-term data display , We choose to use multiple segments of each X Months of data were spliced , Query efficiency is very fast . for example : stay TDengine The client server uses Python Pull the futures market data for two consecutive months from the server , Time consuming 0.16 second .
The following figure shows the factor 1 Yield curve on futures rapeseed meal , We can also see from this picture , Some other commonly used functions, such as max、last, be based on TDengine Cache and other technologies also realize the millisecond return data .
from “ Two points ” To in-depth cooperation
Careful readers may also notice two small problems in the article :
Why do we estimate the amount of raw data , Is to count the number of rows in all sub tables through scripts , Multiply it by a single byte , Not directly through TDengine Of “ Supertable ”?
Why in the data classification description at the beginning of the article ,1-4 You can see the actual corresponding database in the following text , But there is no second 5 strip —— A large number of derivative data generated based on the above data ?
In fact, it is , At the beginning of the project, there is no need for multi table aggregation query , In addition, in order to reduce the complexity of data migration , Therefore, we didn't choose the super table in the early stage of environment construction .
But with the continuous improvement of business , We will need more data to do more complex analysis , This leads to the second 5 Data type of bar —— A larger amount of level derivative data generated from the above data . So , This part of the data will come from our business to be launched later .
When the , We will use... In more depth TDengine Other core features of , Such as super watch 、 Many calculation functions and so on . But just for now ,TDengine We have been pleasantly surprised by the powerful storage capacity and fast query , Let's also look forward to further cooperation in the future .
About author :
Liu Jian , Master degree in pattern recognition from Beijing University of Aeronautics and Astronautics , Once worked for China Aerospace Science and technology group, engaged in software research and development .2014 In, I started a business with my friends and engaged in foreign exchange 、 futures 、 Stocks ETF Automatic trading has been . Focus on Data Mining 、 Automatic quantitative trading is carried out in the domestic secondary market by means of automatic pattern recognition .
边栏推荐
- When sqlacodegen generates a model, how to solve the problem that the password contains special characters?
- College Students' innovation project management system
- Yyds dry goods inventory embedded matrix
- el-select,el-option下拉选择框
- Breaking the information cocoon - my method of actively obtaining information - 3
- Pat class a 1160 forever (class B 1104 forever)
- Spark SQL learning bullet 2
- Acwing game 58 [End]
- Clean up PHP session files
- Avoid material "minefields"! Play with super high conversion rate
猜你喜欢
Anchor free series network yolox source code line by line explanation Part 2 (a total of 10, ensure to explain line by line, after reading, you can change the network at will, not just as a participan
Azkaban安装部署

Acwing第 58 场周赛【完结】
Design and implementation of kindergarten management system
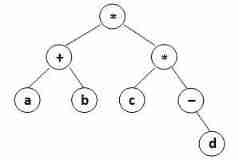
Pat class a 1162 postfix expression

Single box check box

Linux Installation redis

el-select,el-option下拉选择框
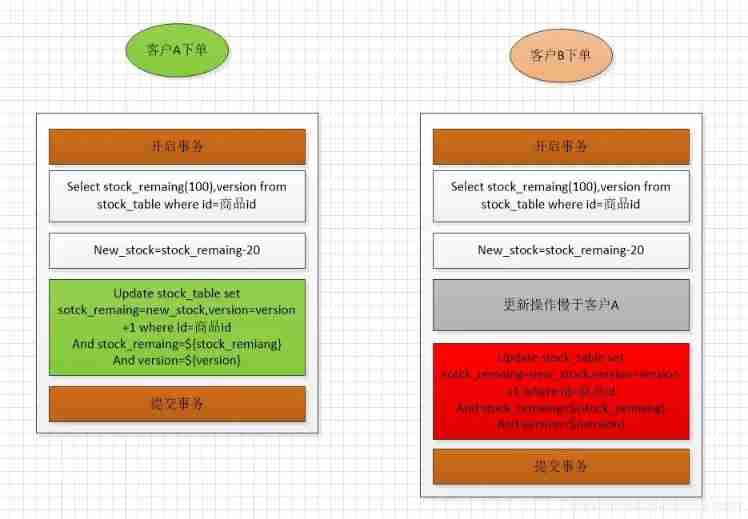
Jd.com 2: how to prevent oversold in the deduction process of commodity inventory?
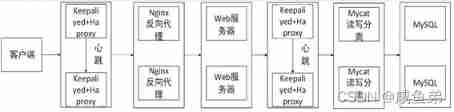
Design and implementation of high availability website architecture
随机推荐
The perfect car for successful people: BMW X7! Superior performance, excellent comfort and safety
Delphi read / write JSON format
Kuboard
GFS分布式文件系统
El select, El option drop-down selection box
Anchor free series network yolox source code line by line explanation Part 2 (a total of 10, ensure to explain line by line, after reading, you can change the network at will, not just as a participan
Pytest (4) - test case execution sequence
为什么腾讯阿里等互联网大厂诞生的好产品越来越少?
Cette ADB MySQL prend - elle en charge SQL Server?
看 TDengine 社区英雄线上发布会,听 TD Hero 聊开发者传奇故事
TCP security of network security foundation
返回二叉树中两个节点的最低公共祖先
Master Fur
[micro service SCG] 33 usages of filters
SPI and IIC communication protocol
Leetcode42. connect rainwater
LeetCode 237. Delete nodes in the linked list
Mongodb common commands
IPv6 experiment
Why are there fewer and fewer good products produced by big Internet companies such as Tencent and Alibaba?