当前位置:网站首页>2021 Li Hongyi machine learning (1): basic concepts
2021 Li Hongyi machine learning (1): basic concepts
2022-07-05 02:38:00 【Three ears 01】
2021 Li hongyi machine learning (1): Basic concepts
B On the site 2021 Li Hongyi's learning notes of machine learning course , For reuse .
1 Basic concepts
Machine learning is ultimately about finding a function .
1.1 Different function categories
- Return to Regression—— Output is numeric
- classification Classification—— The output is in different categories classes, Do multiple choice questions
- Structural learning Structured Learning—— Generate a structured file ( Draw a picture 、 Write an article ), Let the machine learn to create
1.2 How to find functions (Training):
- First , Write a function with unknown parameters ;
- secondly , Definition loss( A function related to parameters ,MAE—— Absolute error ,MSE—— Mean square error );
- Last , Optimize , Find the loss Minimum parameters —— gradient descent
1) Randomly select the initial value of the parameter ;
2) Calculation ∂ L ∂ w ∣ w = w 0 \left.\frac{\partial L}{\partial w}\right|_{w=w^{0}} ∂w∂L∣∣w=w0, Then step down the gradient , The step size is l r × ∂ L ∂ w ∣ w = w 0 \left.lr\times\frac{\partial L}{\partial w}\right|_{w=w^{0}} lr×∂w∂L∣∣w=w0
3) Update parameters
This method has a huge drawback : Usually we will find Local minima, But what we want is global minima
1.3 Model
Linear model linear model There's a big limit , Cannot simulate polyline 、 Curve , This restriction is called model bias, So we need to improve .
How to improve :Piecewise Linear Curves
Many such sets can be fitted into curves .
1.3.1 sigmoid
It can be used sigmoid function y = c 1 1 + e − ( b + w x 1 ) = c s i g m o i d ( b + w x 1 ) y=c \frac{1}{1+e^{-\left(b+w x_{1}\right)}}=c sigmoid(b+wx_1) y=c1+e−(b+wx1)1=csigmoid(b+wx1) Fit the blue broken line :
y = b + ∑ i c i sigmoid ( b i + ∑ j w i j x j ) y=b+\sum_{i} c_{i} \operatorname{sigmoid}\left(b_{i}+\sum_{j} w_{i j} x_{j}\right) y=b+i∑cisigmoid(bi+j∑wijxj)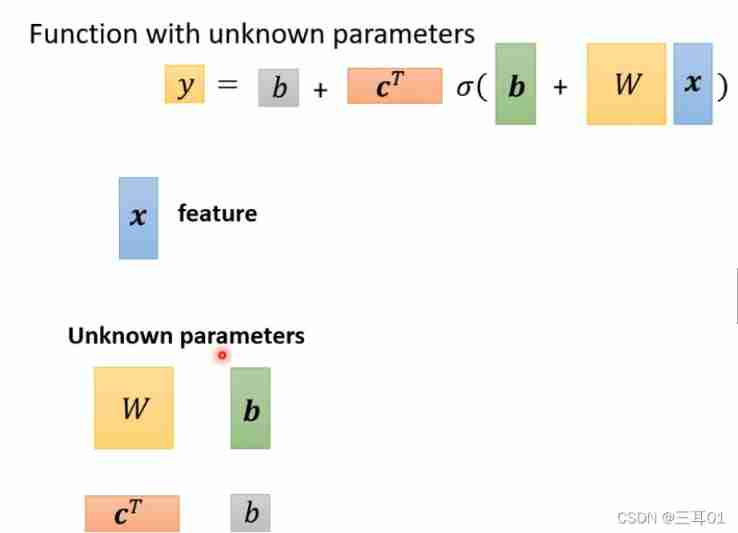
All unknown parameters in this , Use both θ \theta θ Express :
Use all at once θ \theta θ To calculate , Make a gradient descent , Such a large amount of data , Therefore, small batches are used batch: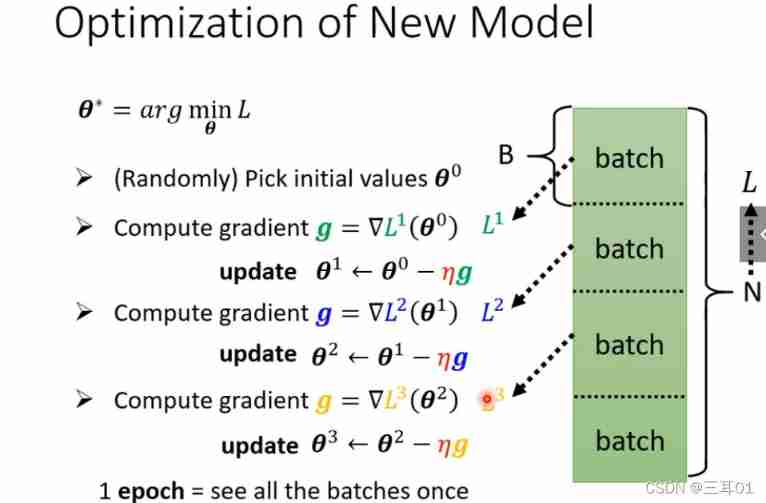
every last data The number of updates depends on the total amount of data and batch Number :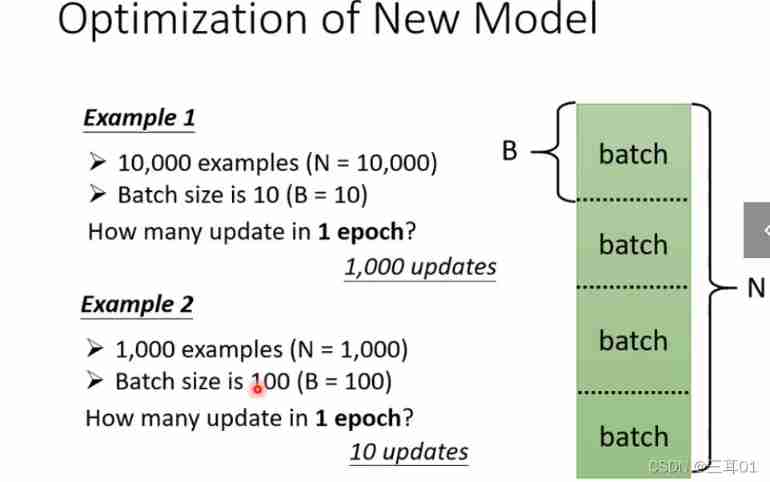
1.3.2 ReLU
In front of it is soft sigmoid, That's the curve , In fact, you can use two ReLU Quasi synthesis hard sigmoid, That's the broken line :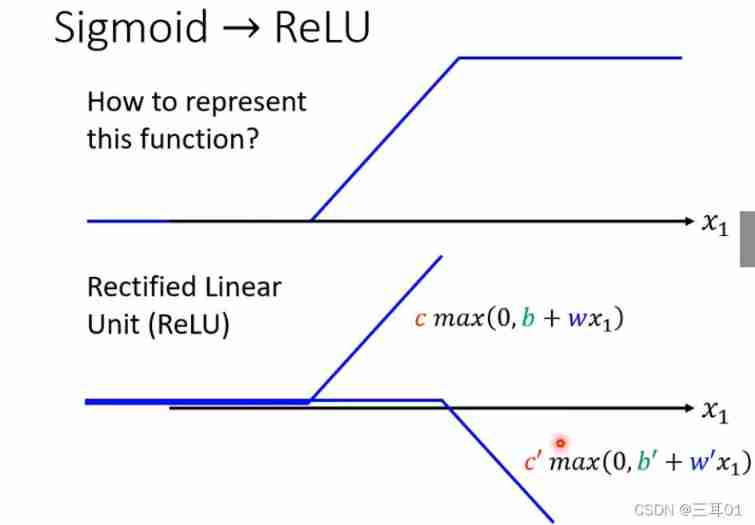
above sigmoid The formula becomes :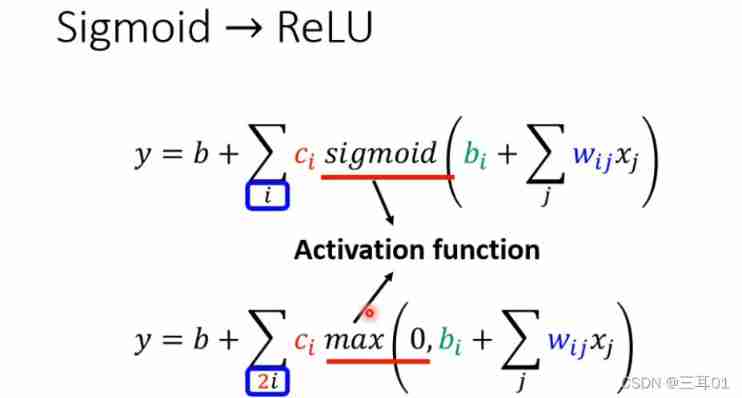
1.3.3 Yes sigmoid The calculation of can be done several more times
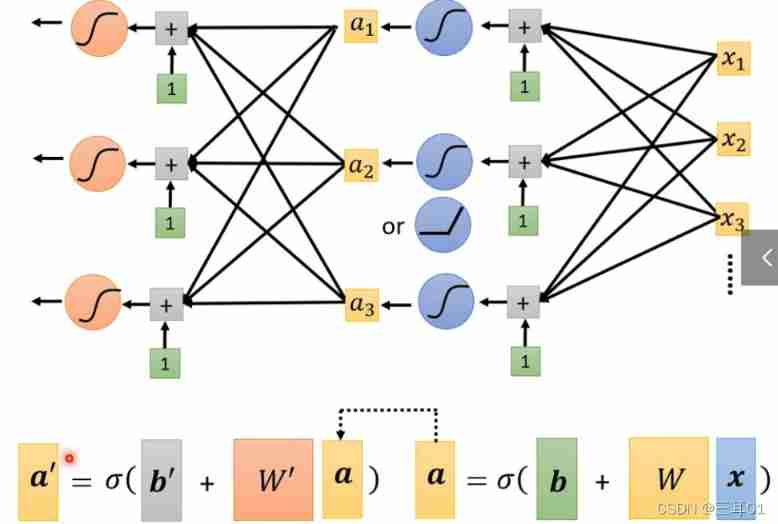
There are many such layers , It is called neural network Neural Network, Later called Deep learning=Many hidden layers
边栏推荐
- RichView TRVStyle MainRVStyle
- Grpc message sending of vertx
- CAM Pytorch
- Official announcement! The third cloud native programming challenge is officially launched!
- A label making navigation bar
- Three properties that a good homomorphic encryption should satisfy
- 如何做一个炫酷的墨水屏电子钟?
- Elk log analysis system
- 返回二叉树中两个节点的最低公共祖先
- Problem solving: attributeerror: 'nonetype' object has no attribute 'append‘
猜你喜欢
He was laid off.. 39 year old Ali P9, saved 150million
Exploration of short text analysis in the field of medical and health (I)
Exploration of short text analysis in the field of medical and health (II)

Practice of tdengine in TCL air conditioning energy management platform

Learn game model 3D characters, come out to find a job?
Introduce reflow & repaint, and how to optimize it?
【LeetCode】98. Verify the binary search tree (2 brushes of wrong questions)
【LeetCode】110. Balanced binary tree (2 brushes of wrong questions)
![Moco V2 literature research [self supervised learning]](/img/bd/79b7b203ea064c65d143116c9f4dd0.jpg)
Moco V2 literature research [self supervised learning]
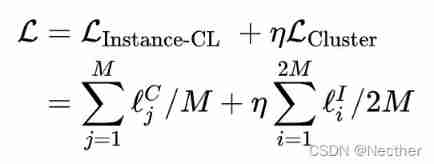
Naacl 2021 | contrastive learning sweeping text clustering task
随机推荐
8. Commodity management - commodity classification
官宣!第三届云原生编程挑战赛正式启动!
Elfk deployment
openresty ngx_ Lua execution phase
openresty ngx_lua执行阶段
LeetCode --- 1071. Great common divisor of strings problem solving Report
Leetcode takes out the least number of magic beans
The steering wheel can be turned for one and a half turns. Is there any difference between it and two turns
Visual explanation of Newton iteration method
Zabbix
Why do you understand a16z? Those who prefer Web3.0 Privacy Infrastructure: nym
Redis distributed lock, lock code logic
Can you really learn 3DMAX modeling by self-study?
【附源码】基于知识图谱的智能推荐系统-Sylvie小兔
Spark SQL learning bullet 2
Video display and hiding of imitation tudou.com
Missile interception -- UPC winter vacation training match
Spoon inserts and updates the Oracle database, and some prompts are inserted with errors. Assertion botch: negative time
Asynchronous and promise
Collection of gmat750 wrong questions