当前位置:网站首页>Bert fine tuning skills experiment
Bert fine tuning skills experiment
2022-07-05 02:03:00 【Necther】
Background introduction
The text classification is NLP A classic task in , Generally, some pre trained models in large data sets can achieve good results in text classification . for example word2vec, CoVe(contextualized word embeddings) and ELMo All have achieved good results .Bert It's based on two-way transformer Use masked word prediction and NSP(next sentence prediction) The task of pre training , Then fine tune on downstream tasks .Bert The birth of , Swept the major lists . But has his potential been fully exploited ? This paper aims at text classification based on Bert Explore several methods that can optimize the effect .
These methods are :
- Fine-tune Strategy
- Deep pre training
- multitasking Fine-tune
Strategy introduction
1. Fine-tune Strategy
Different layers of neural network can capture different grammatical and semantic information . Use Bert To train downstream tasks, we need to consider several issues :
- Long article of pre training , because Bert The longest text sequence of is 512
- Layer selection , As mentioned above , Each layer captures different information , So we need to choose the most suitable layer
- Over fitting problem , Therefore, we need to consider the appropriate learning rate .Bert The bottom layer of will learn more general information , Right Bert Different layers of use different learning rates . The parameter iteration of each layer can be as follows :
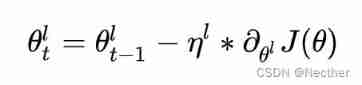
among
- It means the first one l Layer t Parameters of step iteration
- It means the first one l Layer learning rate , The calculation method is as follows . Represents the decay coefficient , When >1 Indicates that the learning rate decays layer by layer , Otherwise, it means expanding layer by layer . When =1 Time and tradition Bert identical .
2. Deep pre training
Bert It is pre trained on the General Corpus , If you want to apply text classification in a specific field , There must be some gaps in data distribution . At this time, you can consider deep pre training .
- Within-task pre-training:Bert Pre training on the training corpus
- In-domain pre-training: Pre training the corpus in the same field
- Cross-domain pre-training: Pre training the corpus in different fields
3. multitasking Fine-tune
Multitasking tuning is using Bert To train different downstream tasks, but except for the last layer , Share parameters in other layers .
experimental result
1. Data sets
This article uses IMDB, Yelp Comment data sets are used for emotional analysis ,TREC( Open domain question and answer data sets ),yahoo Q & A is used for problem classification ,AG Journalism ,DBPedia and Sougou News topic classification . Use in this paper WordPiece embeddings With ## Segment sentences . Yes Sougou News adoption ".", "?", "!" To separate sentences .

2. Fine-tune Strategy
- Long text processing
There are two ways to deal with long text , Truncation and segmentation .
- truncation : Generally speaking, the most important information in a text is the beginning and end , Therefore, the long text is truncated in this paper .
head-only: Leave the 510 Characters
tail-only: After reservation 510 Characters
head+tail: Leave the 128 And after 382 Characters
- segmentation : Divide the text into k paragraph , Input of each paragraph and Bert The general input is the same , The first character is [CLS] Represents the weighted information of this paragraph . In this paper, we use Max-pooling, Average pooling and self-attention Combine the representation of these fragments .
Here are the results of the experiment ,head+tail The representation of is better on both data sets . It should be that the long text combines the information at the beginning and end of the sentence , The information obtained is relatively balanced . However, it is strange that the splicing method as a whole is not as good as truncation , My guess is that cutting the sentence into several paragraphs may increase the instability of the model , And errors may be magnified when superimposed . and max-pooling and self-attention It also emphasizes more useful information in the text , So the overall effect is better than average.

2. Layer selection
In this paper, the effect of each layer and the results of the first four layers are spliced , The result stitching of the last four layers and 12 The results of layer splicing were tested , Found the last four layers of splicing and the 11 Layers have the same effect .

3. Catastrophic Forgetting
Catastrophic forgetting It means that the pre trained knowledge is forgotten when learning new knowledge . Right Bert Of Catastrophic Forgetting The problem is explored . The picture below is IMDB Different learning rates and error-rate The curve of , It can be seen that a relatively small learning rate has a better effect .

4. Interlayer learning rate
The influence of inter layer learning rate on the model , You can see when the initial learning rate is high , The recession rate should be relatively low . Because the deep model can learn less , A relatively low learning rate is required for fitting . Does this also mean that a relatively fixed learning at a certain level can make the model optimal ?

3. Deep pre training
1. Within-Task Further Pre-Training
Use training data for pre training , The following figure shows the pre training step And the error rate of the test , You can see the pre training 100K The effect of training after rounds has been improved .

2. In-Domain and Cross-Domain Further Pre-Training
The corpus is divided into emotional analysis , Problem classification and topic classification , On these corpora, according to the pre training of intra domain and cross domain . The following figure shows the results of pre training ,all Is to use the corpus in all fields for pre training ,w/o It's primitive bert. It can be seen that the effect of pre training is better than that of the original Bert Improved . But be careful , Small scale corpus TREC After training in the field, the effect becomes worse .

The text also uses Bert Feature input for Bilstm+self-attention To evaluate , The effect is as follows , among :
- BERT-Feat: BERT as features
- BERT-FiT: BERT + Fine-Tuning
- BERT-ITPT-FiT: BERT + withIn-Task Pre-Training + Fine-Tuning
- BERT-IDPT-FiT: BERT + In-Domain Pre-Training + Fine-Tuning
- BERT-CDPT-FiT: BERT + Cross-Domain Pre-Training + Fine-Tuning

4. multitasking Fine-tune
Used in the paper 4 A dataset of English Classification (IMDB, Yelp.P, AG, DBP) multitask , At the same time, it uses cross domain pre training Bert Compare the models , The effect is as follows . It can be seen that multi task learning can improve Bert The effect of , At the same time, pre training in cross fields Bert Multitask on the model Fine tune The effect is the best .

5. The size of the training set
Right Fine-tune Explore the influence of the size of the training set on the effect of the model . It can be seen that when the training data set is relatively small , The error rate of the model is relatively high , As the training set increases , The error rate of the model decreases . But why abscissa from 20 here we are 100 There is a little confusion here . among Bert-Fit Express Bert Fine-tune, BERT-ITPT-Fit Express BERT + withIn-Task Pre-Training + Fine-Tuning.

6. Bert Large Preliminary training
Right Bert Large It also went on With task Preliminary training , Do wonders vigorously , Sure enough Bert large Is much better .

summary
I feel this is a very solid article , Consider a more comprehensive experimental report , But there are few thoughts and explanations about the experimental results . In short, use Bert When fine-tuning, you can consider re pre training in the field , Let the model learn more , And deep learning is still working hard to achieve miracles as always .
Related information
How to Fine-Tune BERT for Text Classificationarxiv.org/pdf/1905.05583.pdf
边栏推荐
- Vulnstack3
- 线上故障突突突?如何紧急诊断、排查与恢复
- RichView TRVStyle MainRVStyle
- Kibana installation and configuration
- PHP 基础篇 - PHP 中 DES 加解密详解
- Express routing, express middleware, using express write interface
- Binary tree traversal - middle order traversal (golang)
- Codeforces Global Round 19 ABC
- Word processing software
- Limited query of common SQL operations
猜你喜欢

How to build a technical team that will bring down the company?
R语言用logistic逻辑回归和AFRIMA、ARIMA时间序列模型预测世界人口
One plus six brushes into Kali nethunter
Win: use shadow mode to view the Desktop Session of a remote user
Yolov5 model training and detection
![[swagger]-swagger learning](/img/60/1dbe074b3c66687867192b0817b553.jpg)
[swagger]-swagger learning
He was laid off.. 39 year old Ali P9, saved 150million
Exploration and Practice of Stream Batch Integration in JD
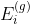
MATLB|多微电网及分布式能源交易

Mysql database | build master-slave instances of mysql-8.0 or above based on docker
随机推荐
Application and Optimization Practice of redis in vivo push platform
Kibana installation and configuration
Lsblk command - check the disk of the system. I don't often use this command, but it's still very easy to use. Onion duck, like, collect, pay attention, wait for your arrival!
Luo Gu Pardon prisoners of war
Yolov5 model training and detection
Restful fast request 2022.2.1 release, support curl import
Collection of gmat750 wrong questions
Win:将一般用户添加到 Local Admins 组中
Action News
Huawei machine test question: longest continuous subsequence
Blue Bridge Cup Square filling (DFS backtracking)
Common bit operation skills of C speech
Serious bugs with lifted/nullable conversions from int, allowing conversion from decimal
[source code attached] Intelligent Recommendation System Based on knowledge map -sylvie rabbit
Runc hang causes the kubernetes node notready
Application and Optimization Practice of redis in vivo push platform
"2022" is a must know web security interview question for job hopping
Yolov5 model training and detection
PHP wechat official account development
Win: enable and disable USB drives using group policy