当前位置:网站首页>Transformation transformation operator
Transformation transformation operator
2022-07-07 01:14:00 【MelodyYN】
List of articles
Transformation Conversion operator
1、 single Value type
map operator
RDD Each element in passes through map Anonymous functions in operators , Form a new RDD
The partition does not change
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/8 18:30 * @version 1.0 */
object Test01_Map {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRdd = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
listRdd.map(i => {
println(" Calling operator ")
i*2
}).collect().foreach(println)
//4. close sc
sc.stop()
}
}
mapPartitions operator
mapPartitions() Execute on a partition by partition basis Map, Process the data of one partition at a time .
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/8 18:35 * @version 1.0 */
object Test02_MapPartitons {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRdd = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
val value = listRdd.mapPartitions( list => {
println(" Calling operator ")
list.map( i => {
println(" Calculated figures ")
i * 2
} )
} )
value.collect().foreach(println)
//4. close sc
sc.stop()
}
}
map(): Process one piece of data at a time
mapPartitions(): Processing data one partition at a time . After the data processing of this partition , original RDD The data in the partition will be released , May cause OOM
When the memory space is large , It is recommended to use mapPartitions, More efficient
mapPartitionsWithIndex operator
Be similar to mapPartitions(), With area code .
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/8 18:39 * @version 1.0 */
object Test03_MapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRdd = sc.makeRDD( 1 to 4, 2 )
val value = listRdd.mapPartitionsWithIndex( (index, list) => {
list.map( (index, _) )
} )
value.collect().foreach(println)
//4. close sc
sc.stop()
}
}
flatMap operator
flat , And map The operator is similar to . But enter an element , Then output an iterator
package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 11:38 * @version 1.0 */
object Test04_FlatMap {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD = sc.makeRDD( List( List( 1, 2, 3 ), List( 4, 5, 6 ) ), 2 )
val intRDD = listRDD.flatMap( list => list )
intRDD.collect().foreach(println)
// Determine the partition
//flatMap Do not change the partition Keep the original partition
intRDD.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
// Corresponding ( Long string , frequency ) => ( word , frequency ),( word , frequency )
val tupleRDD: RDD[(String, Int)] = sc.makeRDD(List(("hello world", 100), ("hello scala", 200)))
tupleRDD.flatMap(tuple=>{
tuple._1.split( " " )
.map((_,tuple._2))
})
// Partial function
tupleRDD.flatMap(tuple => tuple match {
case (line,count) => line.split(" ").map(word => (word,count))
})
tupleRDD.flatMap{
case (line,count) => line.split(" ").map(word => (word,count))
}
//4. close sc
sc.stop()
}
}
glom operator
Partition conversion array : The operation will RDD Each partition in becomes an array , And put it in a new RDD in , The element type in the array is consistent with that in the original partition
package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 11:55 * @version 1.0 */
object Test05_Glom {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
val arrayRDD: RDD[Array[Int]] = listRDD.glom()
val result = arrayRDD.map( _.max )
result.collect().foreach(println)
val lineRDD = sc.textFile( "input/1.sql" ,1)
val value = lineRDD.glom()
value.map(array => array.mkString).collect().foreach(println)
//4. close sc
sc.stop()
}
}
Can be obtained from sql In the document sql sentence
groupBy operator
grouping , Install the return values of the incoming array to group . Will be the same key The corresponding value is put into the same iterator
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 14:56 * @version 1.0 */
object Test06_GroupBy {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
val groupRDD = listRDD.groupBy( num => num % 2 )
groupRDD.collect().foreach(println)
//4. close sc
sc.stop()
}
}
Use GroupBy Conduct wordcount
package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 16:43 * @version 1.0 */
object Test07_GroupByWC {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val lineRDD = sc.textFile( "input/2.txt" )
val wordRDD = lineRDD.flatMap( _.split( " " ) )
val tupleRDD: RDD[(String, Iterable[String])] = wordRDD.groupBy( word => word )
tupleRDD.collect().foreach(println)
val result1 = tupleRDD.mapValues( _.size )
tupleRDD.map(tuple => (tuple._1,tuple._2.size)).collect().foreach(println)
println("===========")
result1.collect().foreach(println)
println("============")
// Partial function
tupleRDD.map(tuple => tuple match {
case (word,list) => (word,list.size)
}).collect().foreach(println)
tupleRDD.map{
case (word,list) => (word,list.size)
}.collect().foreach(println)
//4. close sc
sc.stop()
}
}
filter operator
Receive a function with a Boolean return value as an argument . When a RDD call filter When the method is used , Will the RDD Apply... To each element in the f function , If the return value type is true, Then the element will be added to the new RDD in .
Don't go shuffle
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 16:54 * @version 1.0 */
object Test08_Filter {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext( conf )
//3. Write code
val listRDD = sc.makeRDD( List( 1, 3, 2, 4 ), 2 )
val value = listRDD.filter( _ % 2 == 0 )
value.collect().foreach( println )
listRDD.filter( _ % 2 == 0 ).mapPartitionsWithIndex( (num, list) => list.map( (num, _) ) )
.collect()
.foreach( println )
//4. close sc
sc.stop()
}
}
sample operator
Sampling operator :
- No put back
- Put it back
object value09_sample {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc: SparkContext = new SparkContext(conf)
//3.1 Create a RDD
val dataRDD: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6))
// Extract data without putting it back ( Bernoulli algorithm )
// Bernoulli algorithm : Also called 0、1 Distribution . For example, toss a coin , Or the front , Or the opposite .
// Concrete realization : According to the seed and random algorithm to calculate a number and the second parameter setting probability comparison , Less than the second parameter to , Don't
// The first parameter : Whether the extracted data is put back ,false: Don't put back
// The second parameter : The probability of extraction , The scope is [0,1] Between ,0: Not at all ;1: Take all ;
// The third parameter : Random number seed
val sampleRDD: RDD[Int] = dataRDD.sample(false, 0.5)
sampleRDD.collect().foreach(println)
println("----------------------")
// Extract data and put it back ( Poisson algorithm )
// The first parameter : Whether the extracted data is put back ,true: Put back ;false: Don't put back
// The second parameter : The probability of duplicate data , The range is greater than or equal to 0. Represents the number of times each element is expected to be extracted
// The third parameter : Random number seed
val sampleRDD1: RDD[Int] = dataRDD.sample(true, 2)
sampleRDD1.collect().foreach(println)
//4. Close the connection
sc.stop()
}
}
distinct operator
De duplication of internal elements
Use a distributed approach to weight ratio HashSet The collection method is more efficient and not easy OOM
map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
Its essence uses reduceByKey, So we need to go shuffle
package com.hpu.value
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:14 * @version 1.0 */
object Test10_Dis {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext( conf )
//3. Write code
val intRDD = sc.makeRDD( List( 1, 2, 3, 4, 1, 2 ), 2 )
val value = intRDD.distinct()
value.mapPartitionsWithIndex( (num, list) => list.map( (num, _) ) )
.collect()
.foreach( println )
//4. close sc
sc.stop()
}
}

coalesce operator
Merge partitions
Reduce the number of partitions , Used after big data set filtering , Improve the execution efficiency of small data sets .
Default not executed shuffle
When increasing the number of partitions , go shuffle
Source code analysis : Merge partitions directly

package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:19 * @version 1.0 */
object Test11_Coalesce {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 5)
val result = listRDD.coalesce( 2 )
result.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
println("========================")
val listRDD1 = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
val result1 = listRDD1.coalesce( 4, true )
result1.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
repartition operator
This operation actually performs coalesce operation , Parameters shuffle The default value is true. Regardless of the number of partitions RDD Convert to less partitions RDD, Or the one with fewer partitions RDD Convert to a with a large number of partitions RDD,repartition All operations can be completed , Because it will go through shuffle The process .
package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:27 * @version 1.0 */
object Test12_Repartition {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value = listRDD.repartition( 4 )
value.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
coalesce and repartition difference
coalesce Repartition , You can choose whether to shuffle The process . By the parameter shuffle: Boolean = false/true decision .
repartition It's actually called coalesce, Conduct shuffle.
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) }
sortBy operator
This operation is used to sort the data . Before sorting , Data can be passed through f Function to process , And then according to f Function to sort the results , The default is positive order . New after sorting RDD The number of partitions is the same as the original RDD The number of partitions is consistent .
sortBy Need to go shuffle
package com.hpu.value
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:33 * @version 1.0 */
object Test13_SortBy {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(7, 8, 5, 2, 9, 1, 2, 3, 4), 2)
// spark The sorting of can achieve global order
// Guarantee 0 The data of partition No. is less than or equal to 1 Data from partition number
// sortBy Need to go shuffle
listRDD.sortBy(i => i).mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
println("======")
val value: RDD[(Int, Int)] = sc.makeRDD( List( (2, 1), (1, 2), (1, 1), (2, 2) ) )
val value1 = value.sortBy( _._1 )
value1.collect().foreach(println)
//4. close sc
sc.stop()
}
}
2、 double Value Type operators
Intersection and union difference operator
// Ask the meeting to break up and repartition I need to go shuffle
// By default, partitions with more intersections are used
// Union
// Union does not go shuffle
// Just put two RDD Get the partition data of The number of partitions is equal to two RDD The sum of the number of partitions
// Difference set
// Need to rewrite partition go shuffle You can write the number of partitions by yourself
package com.hpu.doublevalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:37 * @version 1.0 */
object Test01_intersection {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)
val listRDD1: RDD[Int] = sc.makeRDD(List(5, 6, 3, 4, 2, 1), 2)
val result = listRDD.intersection( listRDD1 )
result.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
val result1 = listRDD.union( listRDD1 )
result1.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
println("===")
val result2 = listRDD.subtract( listRDD1 )
result2.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
zip operator
Put two RDD Combine into Key/Value Formal RDD, There are two default RDD Of partition Number as well as Element quantity All the same , Otherwise, an exception will be thrown .
package com.hpu.doublevalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:44 * @version 1.0 */
object Test02_Zip {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val listRDD1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val value: RDD[(Int, Int)] = listRDD.zip( listRDD1 )
// Zip the elements at the corresponding positions of the same partition together Become a 2 Tuples
// zip Only two can be operated rdd Have the same number of partitions and elements
value.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
3、Key-Value Type operators
partitionBy operator
take RDD[K,V] Medium K As specified Partitioner Repartitioning ;
If the original RDD And the new RDD If it's consistent, no zoning will be done , Otherwise, it will occur Shuffle The process .
package com.hpu.keyvalue
import org.apache.spark.{
HashPartitioner, SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:48 * @version 1.0 */
object Test01_PartitionBy {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD = sc.makeRDD( List( 1, 2, 3, 4 ), 2 )
val tupleRDD = listRDD.map( (_, 1) )
val value = tupleRDD.partitionBy( new HashPartitioner( 3 ) )
// Fill in the partition Repartition of data using a divider
// Partition can only be used for key To operate
value.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
Custom partition
To implement a custom partition , Need to inherit org.apache.spark.Partitioner class , And implement the following three methods .
(1)numPartitions: Int: Return the number of partitions created .
(2)getPartition(key: Any): Int: Returns the partition number of the given key (0 To numPartitions-1).
(3)equals():Java The standard way to judge equality . The implementation of this method is very important ,Spark You need to use this method to check whether your partition object is the same as other partition instances , such Spark To judge two RDD Is the partition method the same
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
Partitioner, SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:52 * @version 1.0 */
object Test02_Partitioner {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
val value: RDD[(Int, Int)] = listRDD.map((_, 1))
value.partitionBy(new MyPartitioner(2))
.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
class MyPartitioner(partitions:Int) extends Partitioner{
override def numPartitions: Int = partitions
// Get the partition number => According to the key value Determine which partition to assign
// spark The partition of can only be used for key partition
override def getPartition(key: Any): Int = {
key match {
case i:Int => i%2
case _ => 0
}
}
}
}
reduceByKey operator
This operation can make RDD[K,V] The elements in follow the same K Yes V Aggregate .
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 18:58 * @version 1.0 */
object Test03_ReduceByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext( conf )
//3. Write code
val listRDD = sc.makeRDD( List( 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4 ), 2 )
val tupleRDD = listRDD.map( (_, 1) )
tupleRDD.collect().foreach(println)
// Use set common functions for reduction
// reduce Use the first element as the initial value
// val list = List(1, 1, 1)
// val i: Int = list.reduce((res, elem) => res - elem)
// println(i)
// By default, the number of partitions before is used
// It will automatically create one hash Comparator
// Will be the same key A set of element data (1,1,1)
// reduceByKey Take the first element as the initial value
println("-=============")
val value = tupleRDD.reduceByKey( _ - _ )
value.collect().foreach(println)
// The verification results
// It needs to be reduced twice In the primary partition Primary partition
// The first element between partitions depends on the number of partitions The smaller the number, the higher
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 1), ("a", 1), ("a", 1), ("b", 1), ("b", 1), ("b", 1), ("b", 1), ("a", 1),("c",1)), 2)
val value2: RDD[(String, Int)] = value1.reduceByKey(_ - _)
value2.collect().foreach(println)
//4. close sc
sc.stop()
}
}
groupByKey operator
groupByKey For each key To operate , But only one seq, No aggregation .
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 19:10 * @version 1.0 */
object Test04_GroupByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext( conf )
//3. Write code
val listRDD: RDD[Int] = sc.makeRDD( List( 1, 2, 3, 4, 1, 2, 3, 4 ), 2 )
val tupleRDD: RDD[(Int, Int)] = listRDD.map( (_, 1) )
val result = tupleRDD.groupBy( _._1 )
result.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
println("===================")
val result1 = tupleRDD.groupByKey()
// groupByKey operator
// Can only be used for binary type RDD
// contrast groupBy, After aggregation value value It's a collection The element inside only contains the current element value value
result1.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}

reduceByKey and groupByKey difference
1)reduceByKey: according to key Aggregate , stay shuffle Before a combine( pre ( Local ) polymerization ) operation , The return is RDD[K,V].
2)groupByKey: according to key Grouping , Go straight ahead shuffle.
3) Development Guide : Without affecting the business logic , Priority selection reduceByKey. Summation does not affect business logic , Averaging affects business logic .
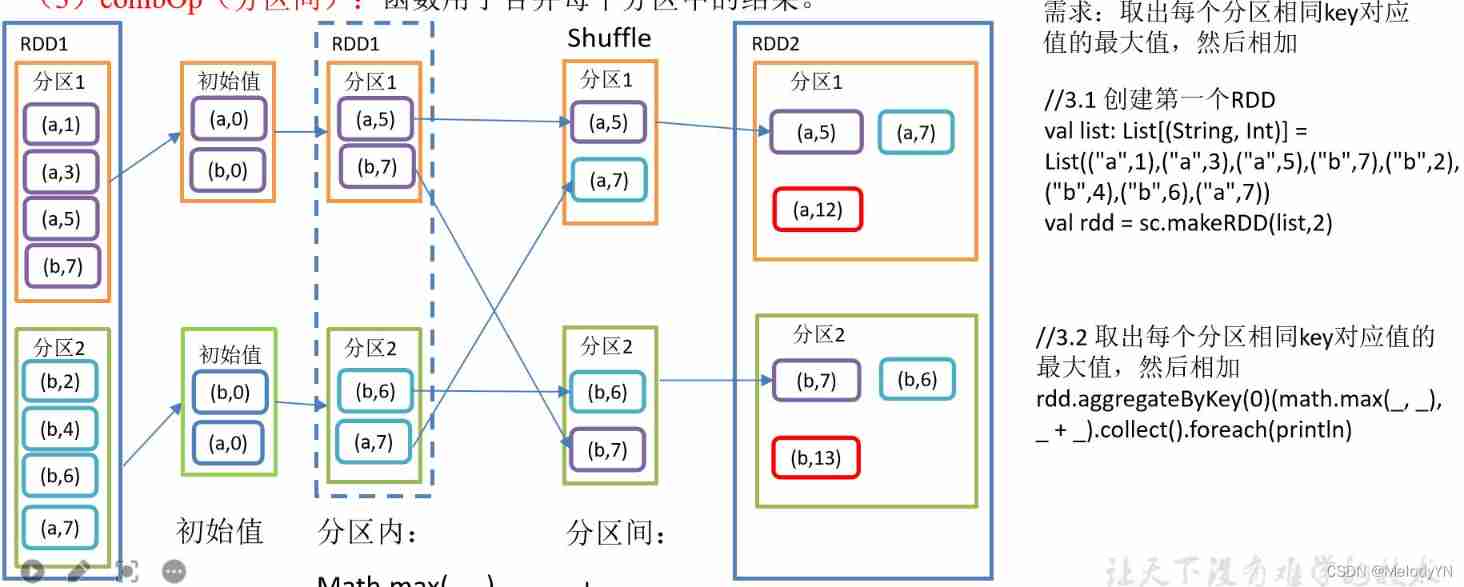
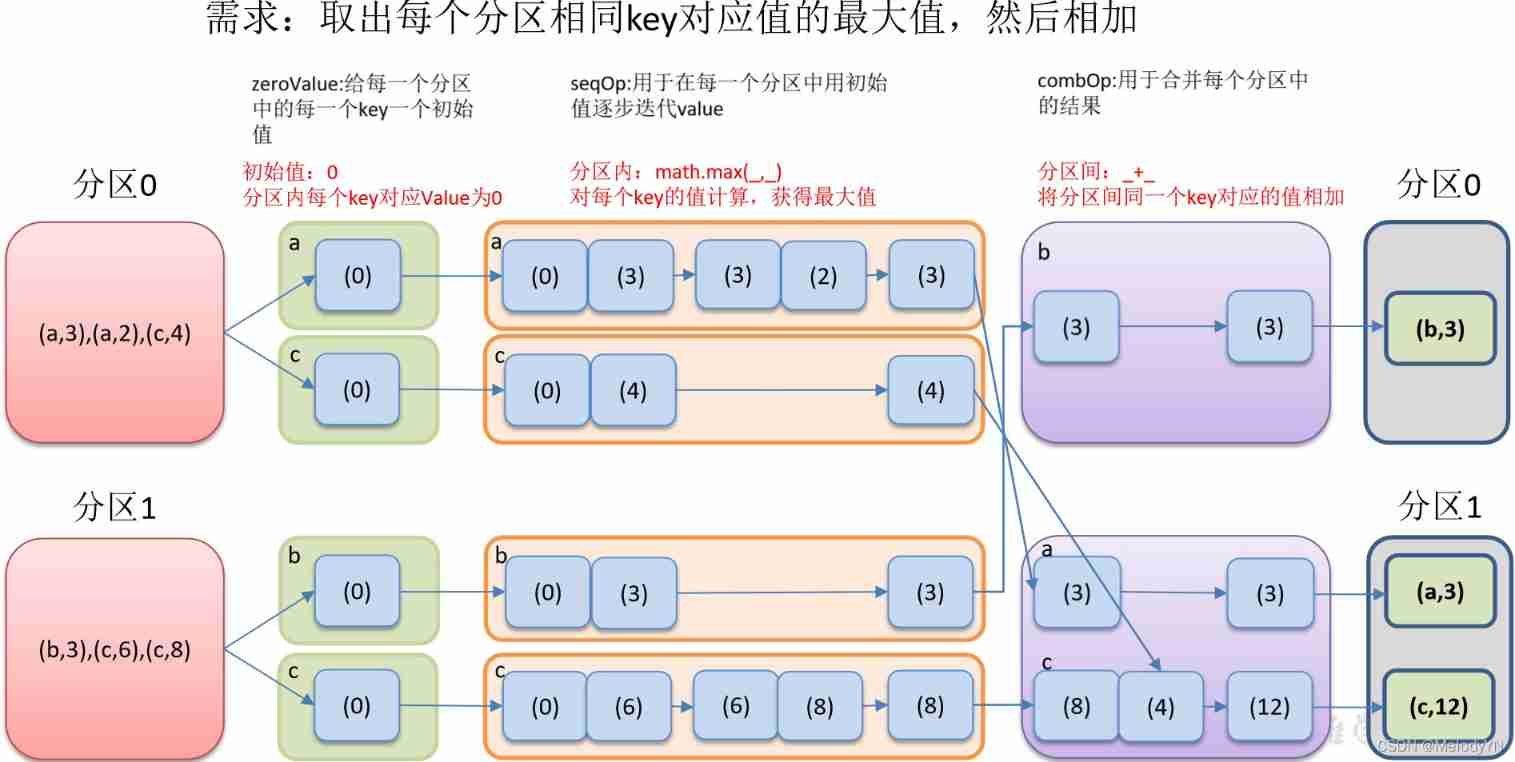
aggregateByKey operator
according to K Handle intra - and inter partition logic
(1 ) zeroValue( Initial value ): Give each type in each partition key An initial value ;
(2 ) seqOp( Within the Division ): The function is used to iterate over each partition step by step with the initial value value ;
(3)combOp( Between partitions ): Function to merge the results in each partition .
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 19:15 * @version 1.0 */
object Test05_aggregateByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
// The calculation within the partition needs to use the initial value
// Every one of every partition key There will be an initial value to accumulate
val result: RDD[(String, Int)] = value1.aggregateByKey( 10 )( _ + _, _ + _ )
result.collect().foreach(println)
println("=======")
// Find the maximum value in the partition Accumulate between partitions
val result1 = value1.aggregateByKey( 10 )( (res, elem) => math.max( res, elem ), _ + _ )
result1.collect().foreach(println)
//4. close sc
sc.stop()
}
}
foldByKey operator
The processing logic within and between partitions is the same aggregateByKey()
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 19:23 * @version 1.0 */
object Test06_FoldByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
// foldByKey You can use custom initial values
// When doing the calculation There will also be pre polymerization The settlement logic within the partition is consistent with that between partitions
// Only use the initial value in the inner area
val result = value1.foldByKey( 10 )( _ + _ )
result.collect().foreach(println)
println("====")
val result1 = value1.foldByKey( 0 )( (res, elem) => math.max( res, elem ) )
result1.collect().foreach(println)
//4. close sc
sc.stop()
}
}
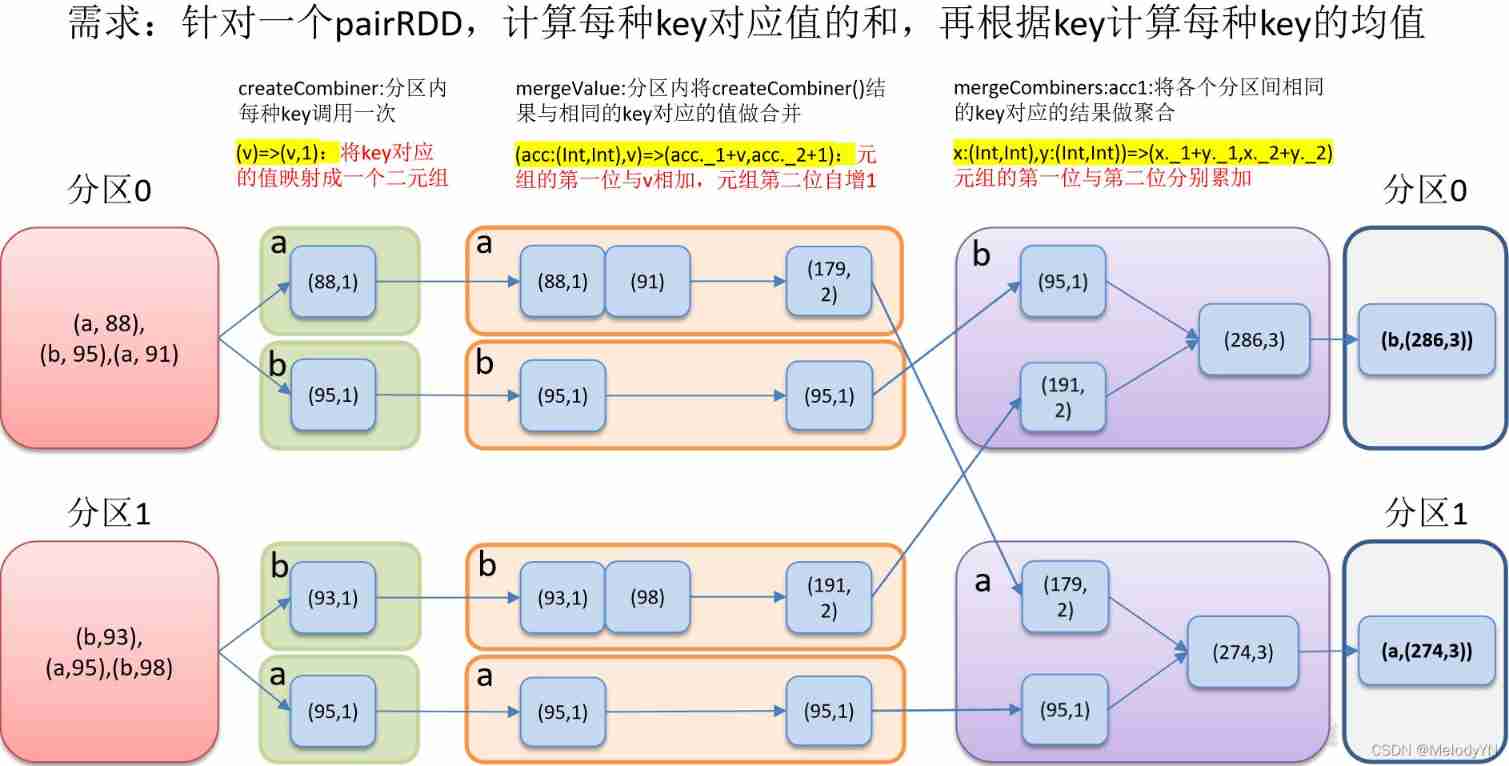
combineByKey operator
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
(1)createCombiner( Transform the structure of the data ): combineByKey() Will traverse all elements in the partition , So the keys for each element have either not yet met , Or it's the same key as the previous element . If this is a new element ,combineByKey() Will use a name called createCombiner() To create the initial value of the accumulator corresponding to that key
(2)mergeValue( Within the Division ): If this is a key that has been encountered before processing the current partition , It will use mergeValue() Method merges the current value corresponding to the key's accumulator with the new value
(3)mergeCombiners( Between partitions ): Because each partition is handled independently , So there can be multiple accumulators for the same key . If there are two or more partitions with accumulators corresponding to the same key , You need to use the mergeCombiners() Method to merge the results of each partition .
Average
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/9 19:27 * @version 1.0 */
object Test07_CombineByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
// Reduce the above elements ( word ,("product",21))
val result = value1.combineByKey(
i => ("product", i),
(res: (String, Int), elem: Int) => (res._1, res._2 * elem),
(res1: (String, Int), elem: (String, Int)) => (elem._1, res1._2 * elem._2)
)
result.collect().foreach(println)
println("========================")
// Create a pairRDD, according to key Calculate each key Average value .
// ( Count each one first key The number of occurrences and the sum of the corresponding values , Divide them up again to get the result )
val list: List[(String, Int)] = List(
("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val tupleRDD: RDD[(String, Int)] = sc.makeRDD(list)
val result1 = tupleRDD.combineByKey(
// take (a,88) => (a,(88,1)) Because the operator has internally followed key Aggregated So when writing, only write value
i => (i, 1),
// Accumulate within the partition Make the same partition the same key Merge the values of (88,1) and 91 => (179,2)
(res: (Int, Int), elem: Int) => (res._1 + elem, res._2 + 1),
// Accumulation between partitions Make different partitions the same key The binary combination of (179,2) and (95,1) => (274,3)
(res: (Int, Int), elem: (Int, Int)) => (res._1 + elem._1, res._2 + elem._2)
)
result1.collect().foreach(println)
result1.mapValues(tuple => tuple match {
case (sum:Int,count:Int) => sum.toDouble/count
}).collect().foreach(println)
//4. close sc
sc.stop()
}
}
WordCount Case study
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
/// establish Spark Context object
val sc = new SparkContext(conf)
// Read the data of the file
val textRDD: RDD[String] = sc.textFile("input/2.txt",2)
// flat , according to " " To cut a
val wordRDD: RDD[String] = textRDD.flatMap {
case x => {
x.split(" ")
}
}
// Transformation structure
val mapRDD: RDD[(String, Int)] = wordRDD.map {
case x => {
(x, 1)
}
}
val combinRDD3: RDD[(String, Int)] = mapRDD.combineByKey(
i => i,
(acc: Int, v:Int) => acc + v,
(acc1: Int, acc2: Int) => (acc1 + acc2)
)
combinRDD3.collect().foreach(println)
}
}
reduceByKey、foldByKey、aggregateByKey、combineByKey

SortByKey operator
In a (K,V) Of RDD On the call ,K Must be realized Ordered Interface , Return to a press key sorted (K,V) Of RDD
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/11 18:35 * @version 1.0 */
object Test08_SortByKey {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1 = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
// By default range Comparator
// Fixed use of key Sort Can't use value
val result = value1.sortByKey( false )
val result1: RDD[(Int, String)] = value1.sortBy( _._1 )
val result2: RDD[(Int, String)] = value1.map( {
case (key, value) => (key, (key, value))
} ).sortByKey().map( _._2 )
result1.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
MapValues operator
Aim at (K,V) The type of form is only for V To operate
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/11 18:47 * @version 1.0 */
object Test09_MapValues {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
val result = value1.mapValues( _ * 2 )
result.collect().foreach(println)
//4. close sc
sc.stop()
}
}
join operator
Equate to sql Inner connection in , Relevance , Irrelevant abandonment
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/11 18:49 * @version 1.0 */
object Test10_Join {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 12), ("b", 21)), 4)
val value2: RDD[(String, Int)] = sc.makeRDD(
List(("a", 11), ("b", 17), ("c", 31), ("d", 22)), 4)
val result: RDD[(String, (Int, Int))] = value1.join( value2 )
// Will be the same key Merge
// join go shuffle Use hash Comparator
// Try to make sure that join Before key It's not repeated If there is duplication The final result will be repeated
result.mapPartitionsWithIndex((num,list)=>list.map((num,_)))
.collect()
.foreach(println)
//4. close sc
sc.stop()
}
}
cogroup operator
Be similar to sql Full connection of , But in the same RDD Chinese vs key polymerization
In the type of (K,V) and (K,W) Of RDD On the call , Return to one (K,(Iterable,Iterable)) Type of RDD
package com.hpu.keyvalue
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SparkConf, SparkContext}
/** * @author zyn * @date 2022/2/11 18:51 * @version 1.0 */
object Test11_Cogroup {
def main(args: Array[String]): Unit = {
//1. establish SparkConf And set up App name
val conf = new SparkConf().setAppName( "WordCount" ).setMaster( "local[*]" )
//2. establish SparkContext, The object is to submit Spark App Entrance
val sc = new SparkContext(conf)
//3. Write code
val value1: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("b", 21)), 4)
val value2: RDD[(String, Int)] = sc.makeRDD(
List(("a", 10), ("b", 7), ("a", 11), ("d", 21)), 4)
val result: RDD[(String, (Iterable[Int], Iterable[Int]))] = value1.cogroup( value2 )
result.collect().foreach(println)
//4. close sc
sc.stop()
}
}
边栏推荐
- Link sharing of STM32 development materials
- NEON优化:矩阵转置的指令优化案例
- NEON优化:log10函数的优化案例
- from . cv2 import * ImportError: libGL. so. 1: cannot open shared object file: No such file or direc
- 斗地主游戏的案例开发
- Informatics Olympiad YBT 1171: factors of large integers | 1.6 13: factors of large integers
- [JS] obtain the N days before and after the current time or the n months before and after the current time (hour, minute, second, year, month, day)
- Telerik UI 2022 R2 SP1 Retail-Not Crack
- Cause of handler memory leak
- 接收用户输入,身高BMI体重指数检测小业务入门案例
猜你喜欢
Part VI, STM32 pulse width modulation (PWM) programming
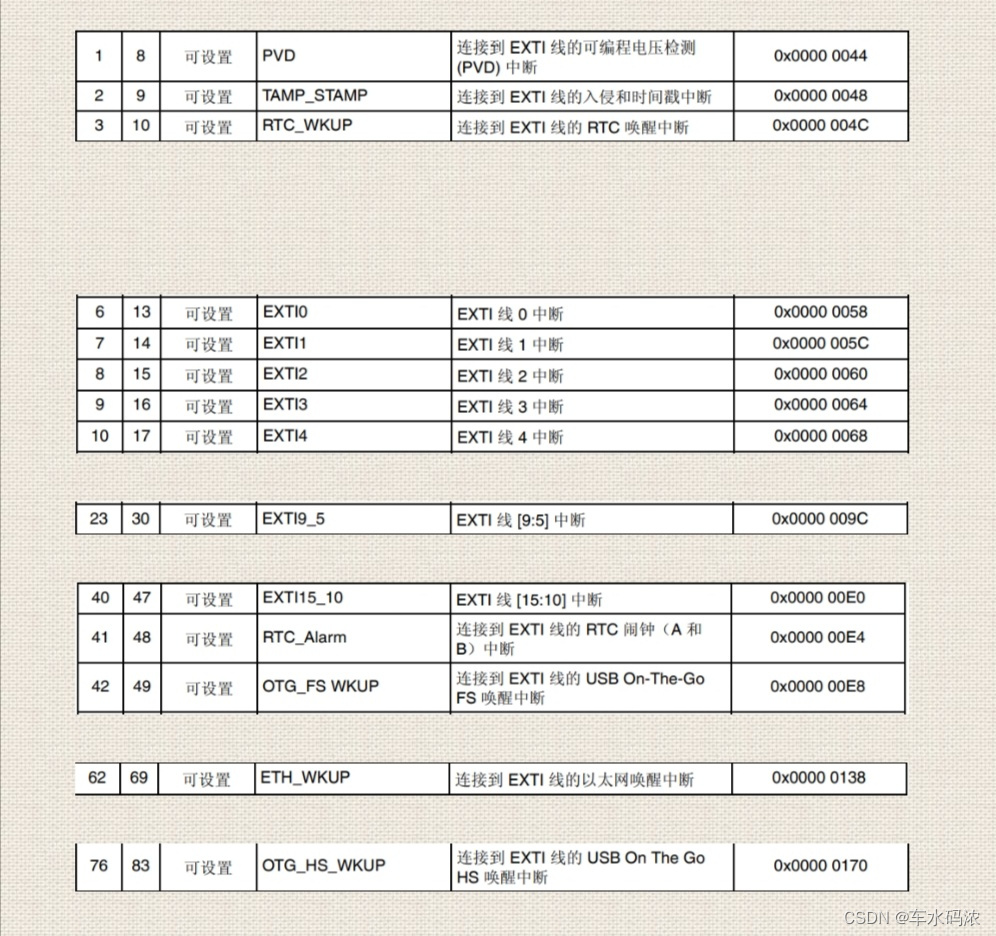
第四篇,STM32中断控制编程

身体质量指数程序,入门写死的小程序项目
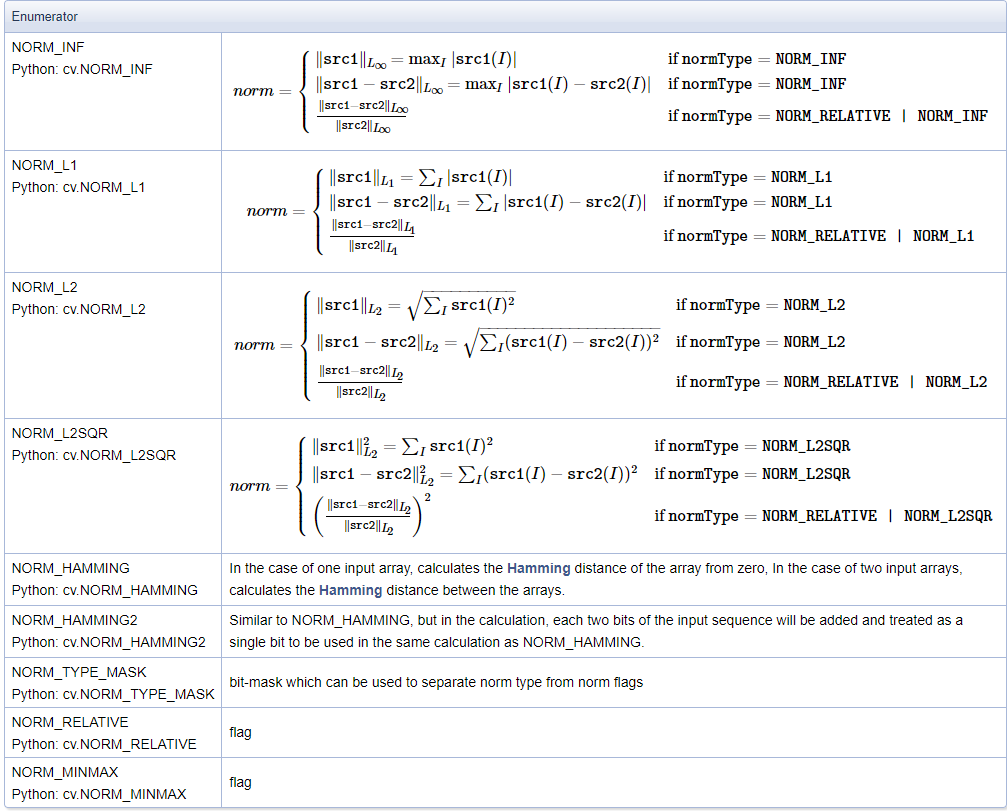
详解OpenCV的矩阵规范化函数normalize()【范围化矩阵的范数或值范围(归一化处理)】,并附NORM_MINMAX情况下的示例代码

Come on, don't spread it out. Fashion cloud secretly takes you to collect "cloud" wool, and then secretly builds a personal website to be the king of scrolls, hehe
![[100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)](/img/7a/bd03943c39d3f731afb51fe2e0f898.png)
[100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)
Part IV: STM32 interrupt control programming
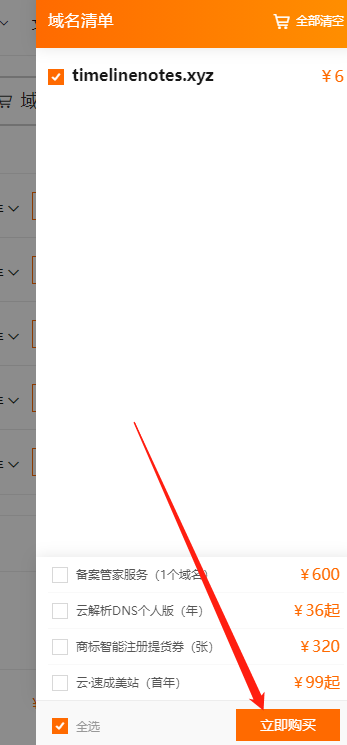
Build your own website (17)
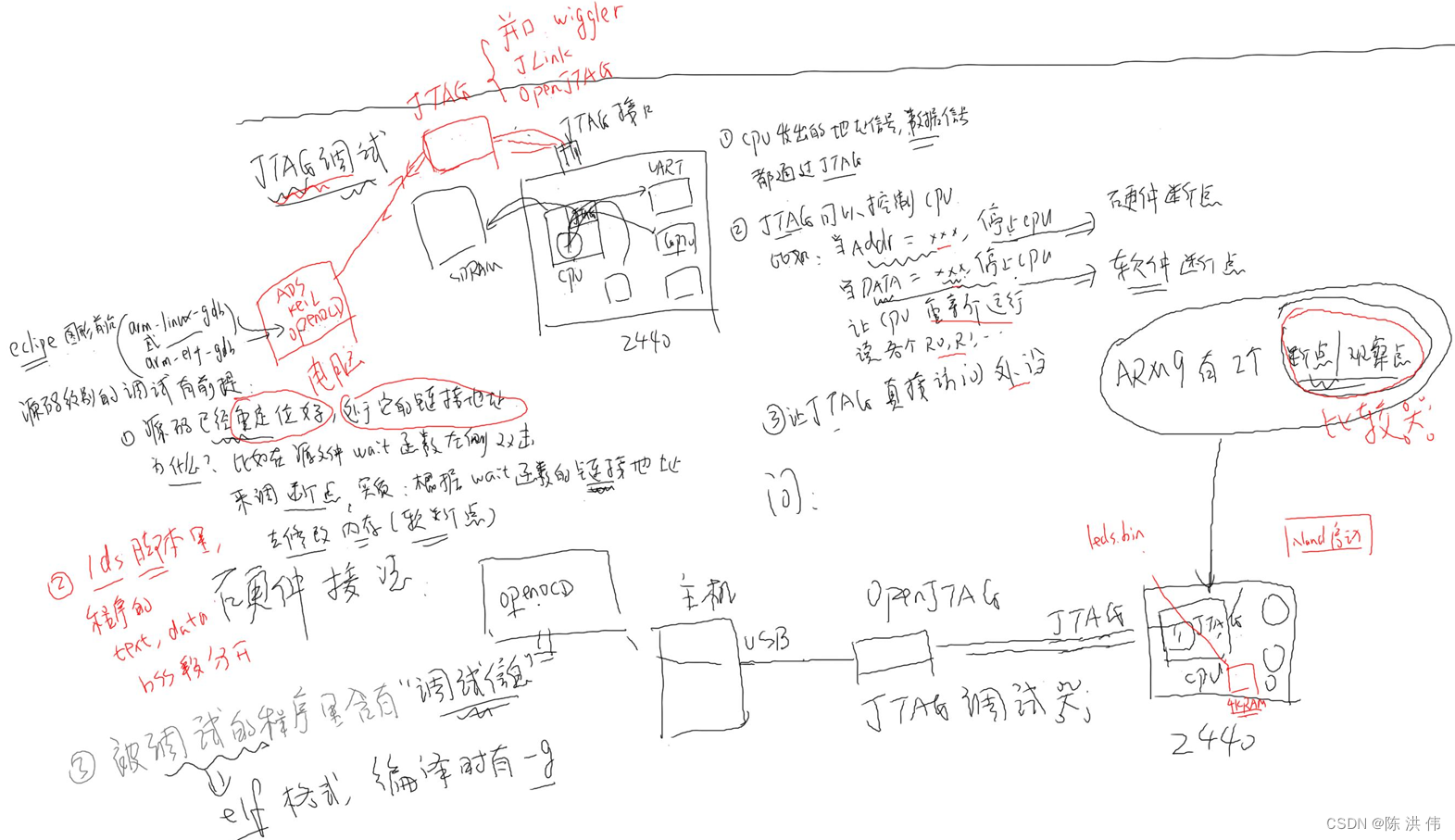
JTAG principle of arm bare board debugging

Analysis of mutex principle in golang
随机推荐
Maidong Internet won the bid of Beijing life insurance to boost customers' brand value
【JVM调优实战100例】04——方法区调优实战(上)
深度学习框架TF安装
Part V: STM32 system timer and general timer programming
[HFCTF2020]BabyUpload session解析引擎
Dell笔记本周期性闪屏故障
第三方跳转网站 出现 405 Method Not Allowed
Fastdfs data migration operation record
HMM 笔记
NEON优化:性能优化经验总结
MySQL中回表的代价
「精致店主理人」青年创业孵化营·首期顺德场圆满结束!
[batch dos-cmd command - summary and summary] - jump, cycle, condition commands (goto, errorlevel, if, for [read, segment, extract string]), CMD command error summary, CMD error
Lldp compatible CDP function configuration
【js】获取当前时间的前后n天或前后n个月(时分秒年月日都可)
Case development of landlord fighting game
《安富莱嵌入式周报》第272期:2022.06.27--2022.07.03
力扣1037. 有效的回旋镖
实现mysql与ES的增量数据同步
Your cache folder contains root-owned files, due to a bug in npm ERR! previous versions of npm which