当前位置:网站首页>[paper reading] cavemix: a simple data augmentation method for brain vision segmentation
[paper reading] cavemix: a simple data augmentation method for brain vision segmentation
2022-07-04 23:54:00 【xiongxyowo】
[ Address of thesis ][ Code ][MICCAI 21]
Abstract
Segmentation of brain lesions (Brain Lesion Segmentation) It provides a valuable tool for clinical diagnosis , Convolutional neural networks (CNN) We have achieved unprecedented success in this task . Data enhancement is a widely used strategy , Can improve CNN Training effect , The design of enhancement methods for brain lesion segmentation is still an open problem . In this work , We propose a simple data enhancement method , go by the name of CarveMix, Used based on CNN Segmentation of brain lesions . With others based on " blend " The same way , Such as Mixup and CutMix,CarveMix Randomly combine two existing marker images to generate new marker samples . However , Different from these image combination based enhancement strategies ,CarveMix It is disease perception , Pay attention to pathological changes when combining , And create appropriate annotations for the generated image . say concretely , According to the location and geometry of the lesion , Carve a region of interest from a marked image (ROI),ROI The size of is sampled from a probability distribution . then , Carved ROI It replaces the corresponding voxel in the second marked image , The annotation of the second image is also replaced accordingly . In this way , We generate new tagged images for network training , And the lesion information is preserved . In order to evaluate the proposed method , We conducted experiments on two brain lesion datasets . It turns out that , Compared with other simple data enhancement methods , Our method improves the accuracy of segmentation .
Method
This paper is a data enhancement method specially proposed for brain lesion segmentation ——CarveMix. This method is also a method based on label fusion , such as MixUp(ICLR 18) Is to fuse the two labels linearly , and CarveMix(ICCV 19) It is a kind of nonlinear fusion . It should be noted that , These classical methods are used for image classification tasks , Therefore, there is a lack of label fusion methods for segmentation tasks .CarveMix The integration process of is as follows :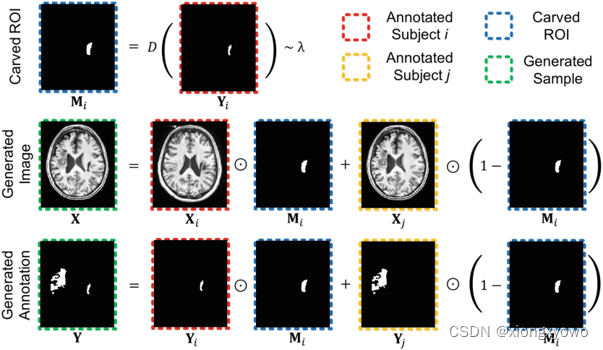
First look at the formula directly : Fused image X \mathbf{X} X And the label obtained by fusion Y \mathbf{Y} Y The final calculation process of is as follows : X = X i ⊙ M i + X j ⊙ ( 1 − M i ) \mathbf{X}=\mathbf{X}_{i} \odot \mathbf{M}_{i}+\mathbf{X}_{j} \odot\left(1-\mathbf{M}_{i}\right) X=Xi⊙Mi+Xj⊙(1−Mi) Y = Y i ⊙ M i + Y j ⊙ ( 1 − M i ) \mathbf{Y}=\mathbf{Y}_{i} \odot \mathbf{M}_{i}+\mathbf{Y}_{j} \odot\left(1-\mathbf{M}_{i}\right) Y=Yi⊙Mi+Yj⊙(1−Mi) For the sake of intuition , We take label fusion as an example to show the specific fusion process , The fusion of image itself is consistent with the fusion of label . Seen from the figure , The fusion of labels is basically equivalent to directly merging two original images mask Y i \mathbf{Y}_i Yi and Y j \mathbf{Y}_j Yj Add it up directly :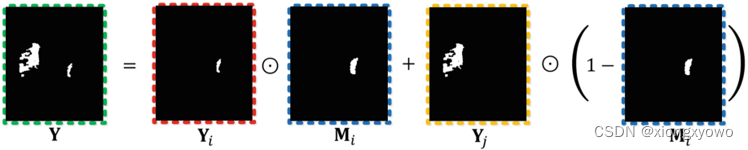
In fact, it is Y i \mathbf{Y}_i Yi Multiplied by a factor a a a After and Y j \mathbf{Y}_j Yj Multiplied by a factor b b b And then add up , Yes a + b = 1 a+b=1 a+b=1. In the figure "⊙" The symbol represents pixel by pixel , So you can even put M i \mathbf{M}_i Mi As a spatial attention map .
The problem now is actually how to calculate M i \mathbf{M}_i Mi 了 . As you can see from the diagram , M i \mathbf{M}_i Mi And Y i \mathbf{Y}_i Yi In fact, it is very similar , It's a bit like in M i \mathbf{M}_i Mi An expansion operation is carried out on the basis of . say concretely , M i \mathbf{M}_i Mi pass the civil examinations j j j A pixel value M i v \mathbf{M}_i^v Miv The calculation method is as follows : M i v = { 1 , D v ( Y i ) ≤ λ 0 , otherwise \mathbf{M}_{i}^{v}=\left\{\begin{array}{l} 1, D^{v}\left(\mathbf{Y}_{i}\right) \leq \lambda \\ 0, \text { otherwise } \end{array}\right. Miv={ 1,Dv(Yi)≤λ0, otherwise D v ( Y i ) = { − d ( v , ∂ Y i ) , if Y i v = 1 d ( v , ∂ Y i ) , if Y i v = 0 D^{v}\left(\mathbf{Y}_{i}\right)=\left\{\begin{aligned} -d\left(v, \partial \mathbf{Y}_{i}\right), & \text { if } \mathbf{Y}_{i}^{v}=1 \\ d\left(v, \partial \mathbf{Y}_{i}\right), & \text { if } \mathbf{Y}_{i}^{v}=0 \end{aligned}\right. Dv(Yi)={ −d(v,∂Yi),d(v,∂Yi), if Yiv=1 if Yiv=0 This d ( v , ∂ Y i ) d(v, \partial \mathbf{Y}_{i}) d(v,∂Yi) Refers to the current pixel v v v And " Lesion boundary " ∂ Y i \partial \mathbf{Y}_{i} ∂Yi Distance of . You can see , If v v v Itself is in the lesion area , that D v ( Y i ) D^{v}\left(\mathbf{Y}_{i}\right) Dv(Yi) Just give a negative number , So as to ensure that it has a greater probability of being selected ( That is less than λ \lambda λ); And if it is outside the lesion area , We think that the closer we are, the more we should be selected . It is worth noting that , This λ \lambda λ It's positive and negative , So as to ensure the pathological area " inflation " perhaps " shrinkage ". λ \lambda λ The specific calculation process of is more complex , Interested readers can read the original .
边栏推荐
- The initial trial is the cross device model upgrade version of Ruijie switch (taking rg-s2952g-e as an example)
- [kotlin] the third day
- Observable time series data downsampling practice in Prometheus
- How many triangles are there in the golden K-line diagram?
- [论文阅读] CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
- Design of emergency lighting evacuation indication system for urban rail transit station
- Hash table, hash function, bloom filter, consistency hash
- Advanced template
- Solve the problem that the virtual machine cannot be remotely connected through SSH service
- C语言中sizeof操作符的坑
猜你喜欢

Application of fire fighting system based on 3D GIS platform

企业公司项目开发好一部分基础功能,重要的事保存到线上第一a
Compare two vis in LabVIEW

Illustrated network: what is gateway load balancing protocol GLBP?
同事的接口文档我每次看着就头大,毛病多多。。。

Combien de temps faut - il pour obtenir un certificat PMP?
![[IELTS reading] Wang Xiwei reading P3 (heading)](/img/19/40564f2afc18fe3e34f218b7b44681.png)
[IELTS reading] Wang Xiwei reading P3 (heading)

Galera cluster of MariaDB - dual active and dual active installation settings
A mining of edu certificate station

他做国外LEAD,用了一年时间,把所有房贷都还清了
随机推荐
人生无常,大肠包小肠, 这次真的可以回家看媳妇去了。。。
"Xiaodeng" domain password policy enhancer in operation and maintenance
[论文阅读] CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
OSEK standard ISO_ 17356 summary introduction
Expand your kubecl function
ECCV 2022 | Tencent Youtu proposed disco: the effect of saving small models in self supervised learning
Selected cutting-edge technical articles of Bi Ren Academy of science and technology
Combien de temps faut - il pour obtenir un certificat PMP?
Cross domain request
45岁教授,她投出2个超级独角兽
他做国外LEAD,用了一年时间,把所有房贷都还清了
The caching feature of docker image and dockerfile
Galera cluster of MariaDB - dual active and dual active installation settings
How to effectively monitor the DC column head cabinet
Illustrated network: what is gateway load balancing protocol GLBP?
Using the uniapp rich text editor
【雅思阅读】王希伟阅读P4(matching2段落信息配对题【困难】)
Jar batch management gadget
How to do the project of computer remote company in foreign Internet?
Intelligence test to see idioms guess ancient poems wechat applet source code