当前位置:网站首页>[Flink] Flink learning
[Flink] Flink learning
2022-07-06 11:31:00 【kiraraLou】
Preface
flink What is it? ?
Stateful computing engine for unbounded and bounded data flows
Common data architecture
- Traditional basic data architecture
- Microservice data architecture
- Big data architecture
- Stateful flow computing architecture
The biggest advantage of stateful flow based computing : There is no need to take the original data out of external storage again , So that we can do a full calculation , Because the cost of this kind of calculation may be very high .
Users do not need to use scheduling and various batch computing tools , Get statistical results from data warehouse , Then store on the floor , Reduce the time loss and hardware storage in the process of data calculation .
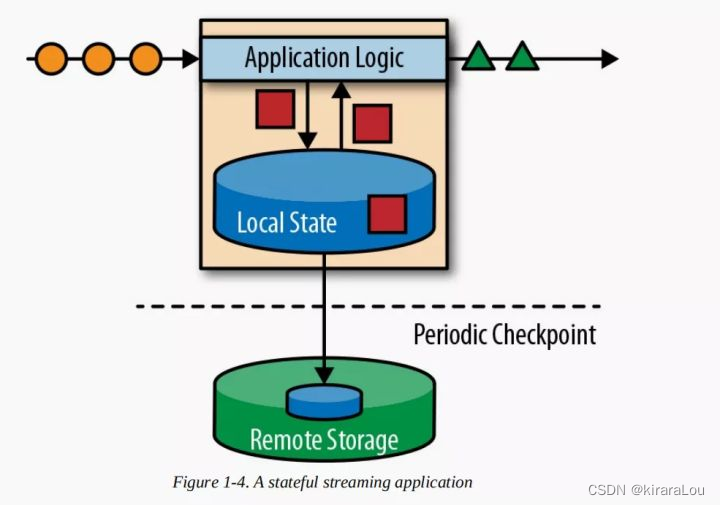
Why Flink
Flink It has the following advantages :
(1) At the same time, it supports high throughput 、 Low latency 、 High performance
Spark streaming Cannot achieve low latency .
Storm Unable to meet high throughput .
(2) Support event time (Event Time) Concept
In flow calculation , Window computing is very important , At present, most frame window calculations use system time (Process Time), That is, when time is transferred to the computing framework for processing , The current time of the system host .
Flink Able to support event based time Semantic window calculation . This time driven mechanism makes events arrive in disorder , The flow system can also calculate accurate results , Keep the timing of the event when it was originally generated .
(3) Support stateful Computing
The so-called state is to save the intermediate result data of the operator in memory or file system in the process of stream computing , After the next event enters the operator, the current result can be calculated after obtaining the intermediate result from the previous state . There is no need to count the results based on all the original data every time .
(4) Support highly flexible windows (Window) operation
The data is continuous , A window is needed to aggregate the data in a certain range .
(5) Lightweight distributed snapshot (Snapshot) Implemented fault tolerance
Flink It can automatically find errors in the process of event processing , Such as node downtime 、 Network transmission, etc , Distributed snapshot based checkpoint, Persist the state information during execution .
(6) be based on JVM Achieve independent memory management
Flink Self managing memory , Reduce... As much as possible JVM GC Impact on the system .Flink By serializing data / The deserialization method converts the data object into binary and stores it in memory , Reduce data storage size .
(7)Save Point ( Save it )
The termination of application in a period of time may lead to data loss or inaccurate calculation results , For example, cluster upgrade and downtime maintenance ,Flink adopt save point Technology saves snapshots of task execution on media , When the task is restarted , You can directly engage in the first saved Save point Restore the original calculation state .
Flink vs Spark
Can support both streaming computing and batch processing .
Data processing architecture
spark Through the batch processing mode to deal with different types of data sets , For stream data, data is divided into micro batches according to batches ( Bounded data sets ) To process .
Flink Process different types of data sets through stream processing mode . Bounded data can be transformed into unbounded data for statistical streaming , Finally, batch processing and streaming are unified in a set of streaming engines .
Data model
Spark It's using RDD Model .spark streaming Of DStream It is a small batch of data RDD Set .
Flink The basic data model is Data flow , And events (Even) Sequence .
Runtime architecture
spark It's batch calculation , take DAG Divide into different stage, Only after one is completed can we proceed to the next .
flink Is the standard flow computing architecture , After an event is processed at one node, it can be directly sent to the next node for processing .
Commit mode
- session Conversational mode
- Pre-job Single operation mode
- Application Application mode
The main difference is that : Cluster life cycle and resource allocation . And the application of (main Method ) Where in the end , client cllient still jobmanager.
边栏推荐
- Knowledge Q & A based on Apache Jena
- Rhcsa certification exam exercise (configured on the first host)
- QT creator test
- DICOM: Overview
- What does usart1 mean
- 引入了junit为什么还是用不了@Test注解
- Solution to the practice set of ladder race LV1 (all)
- {一周总结}带你走进js知识的海洋
- What does BSP mean
- AcWing 1298. Solution to Cao Chong's pig raising problem
猜你喜欢
Introduction and use of automatic machine learning framework (flaml, H2O)

AcWing 242. A simple integer problem (tree array + difference)
Why can't I use the @test annotation after introducing JUnit
图像识别问题 — pytesseract.TesseractNotFoundError: tesseract is not installed or it‘s not in your path
02 staff information management after the actual project
机器学习--人口普查数据分析
QT creator specifies dependencies
QT creator shape
How to build a new project for keil5mdk (with super detailed drawings)

QT creator design user interface
随机推荐
Software testing - interview question sharing
Test objects involved in safety test
[NPUCTF2020]ReadlezPHP
ES6 Promise 对象
QT creator shape
yarn安装与使用
AcWing 1298.曹冲养猪 题解
L2-007 家庭房产 (25 分)
Library function -- (continuous update)
QT creator support platform
Software testing and quality learning notes 3 -- white box testing
[MRCTF2020]套娃
安装numpy问题总结
Nanny level problem setting tutorial
How to set up voice recognition on the computer with shortcut keys
Introduction and use of automatic machine learning framework (flaml, H2O)
PyCharm中无法调用numpy,报错ModuleNotFoundError: No module named ‘numpy‘
MTCNN人脸检测
【yarn】Yarn container 日志清理
What does BSP mean