当前位置:网站首页>Spark TPCDS Data Gen
Spark TPCDS Data Gen
2022-07-07 01:16:00 【zhixingheyi_ tian】
Turn on Spark-Shell
$SPARK_HOME/bin/spark-shell --master local[10] --jars {PATH}/spark-sql-perf-1.2/target/scala-2.12/spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar
Gen Data
Gen TCPDS Parquet
val tools_path = "/opt/Beaver/tpcds-kit/tools"
val data_path = "hdfs://{IP}:9000/tpcds_parquet_tpcds_kit_1_0/1"
val database_name = "tpcds_parquet_tpcds_kit_1_0_scale_1_db"
val scale = "1"
val p = scale.toInt / 2048.0
val catalog_returns_p = (263 * p + 1).toInt
val catalog_sales_p = (2285 * p * 0.5 * 0.5 + 1).toInt
val store_returns_p = (429 * p + 1).toInt
val store_sales_p = (3164 * p * 0.5 * 0.5 + 1).toInt
val web_returns_p = (198 * p + 1).toInt
val web_sales_p = (1207 * p * 0.5 * 0.5 + 1).toInt
val format = "parquet"
val codec = "snappy"
val useDoubleForDecimal = false
val partitionTables = false
val clusterByPartitionColumns = partitionTables
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
spark.sqlContext.setConf(s"spark.sql.$format.compression.codec", codec)
val tables = new TPCDSTables(spark, spark.sqlContext, tools_path, scale, useDoubleForDecimal)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "call_center", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_page", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer", 6)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer_address", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer_demographics", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "date_dim", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "household_demographics", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "income_band", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "inventory", 6)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "item", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "promotion", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "reason", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "ship_mode", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "time_dim", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "warehouse", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_page", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_site", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_sales", catalog_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_returns", catalog_returns_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store_sales", store_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store_returns", store_returns_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_sales", web_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_returns", web_returns_p)
tables.createExternalTables(data_path, format, database_name, overwrite = true, discoverPartitions = partitionTables)
Gen TPCH ORC
import com.databricks.spark.sql.perf.tpch._
val tools_path = "/opt/Beaver/tpch-dbgen"
val format = "orc"
val useDoubleForDecimal = false
val partitionTables = false
val scaleFactor = "1"
val data_path = s"hdfs://{IP}:9000/tpch_${format}_${scaleFactor}"
val numPartitions =1
val databaseName = s"tpch_${format}_${scaleFactor}_db"
val clusterByPartitionColumns = partitionTables
val tables = new TPCHTables(spark, spark.sqlContext,
dbgenDir = tools_path,
scaleFactor = scaleFactor,
useDoubleForDecimal = useDoubleForDecimal,
useStringForDate = false)
spark.sqlContext.setConf("spark.sql.files.maxRecordsPerFile", "200000000")
tables.genData(
location = data_path,
format = format,
overwrite = true, // overwrite the data that is already there
partitionTables, // do not create the partitioned fact tables
clusterByPartitionColumns, // shuffle to get partitions coalesced into single files.
filterOutNullPartitionValues = false, // true to filter out the partition with NULL key value
tableFilter = "", // "" means generate all tables
numPartitions = numPartitions) // how many dsdgen partitions to run - number of input tasks.
// Create the specified database
sql(s"drop database if exists $databaseName CASCADE")
sql(s"create database $databaseName")
// Create metastore tables in a specified database for your data.
// Once tables are created, the current database will be switched to the specified database.
tables.createExternalTables(data_path, format, databaseName, overwrite = true, discoverPartitions = false)
establish Metadata
Parquet create database/tables
val tools_path = "/opt/Beaver/tpcds-kit/tools"
val data_path = "hdfs://10.1.2.206:9000/user/sparkuser/part_tpcds_decimal_1000/"
val database_name = "sr242_parquet_part_tpcds_decimal_1000"
val scale = "1000"
val useDoubleForDecimal = false
val format = "parquet"
val partitionTables = true
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
val tables = new TPCDSTables(spark, spark.sqlContext, tools_path, scale, useDoubleForDecimal)
tables.createExternalTables(data_path, format, database_name, overwrite = true, discoverPartitions = partitionTables)
Arrow create database/tables
val data_path= "hdfs://{IP}:9000/{PATH}/part_tpcds_decimal_1000/"
val databaseName = "arrow_part_tpcds_decimal_1000"
val tables = Seq("call_center", "catalog_page", "catalog_returns", "catalog_sales", "customer", "customer_address", "customer_demographics", "date_dim", "household_demographics", "income_band", "inventory", "item", "promotion", "reason", "ship_mode", "store", "store_returns", "store_sales", "time_dim", "warehouse", "web_page", "web_returns", "web_sales", "web_site")
val partitionTables = true
spark.sql(s"DROP database if exists $databaseName CASCADE")
if (spark.catalog.databaseExists(s"$databaseName")) {
println(s"$databaseName has exists!")
}else{
spark.sql(s"create database if not exists $databaseName").show
spark.sql(s"use $databaseName").show
for (table <- tables) {
if (spark.catalog.tableExists(s"$table")){
println(s"$table has exists!")
}else{
spark.catalog.createTable(s"$table", s"$data_path/$table", "arrow")
}
}
if (partitionTables) {
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table RECOVER PARTITIONS").show
}catch{
case e: Exception => println(e)
}
}
}
}
Use ALTER modify meta Information
val data_path= "hdfs://{IP}:9000/{PATH}/part_tpcds_decimal_1000/"
val databaseName = "parquet_part_tpcds_decimal_1000"
val tables = Seq("call_center", "catalog_page", "catalog_returns", "catalog_sales", "customer", "customer_address", "customer_demographics", "date_dim", "household_demographics", "income_band", "inventory", "item", "promotion", "reason", "ship_mode", "store", "store_returns", "store_sales", "time_dim", "warehouse", "web_page", "web_returns", "web_sales", "web_site")
spark.sql(s"use $databaseName").show
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table SET LOCATION '$data_path/$table'").show
}catch{
case e: Exception => println(e)
}
}
边栏推荐
- docker 方法安装mysql
- Taro 小程序开启wxml代码压缩
- Deeply explore the compilation and pile insertion technology (IV. ASM exploration)
- Meet in the middle
- mysql: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such
- Mongodb client operation (mongorepository)
- 阿里云中mysql数据库被攻击了,最终数据找回来了
- Atomic in golang, and cas Operations
- Cause of handler memory leak
- NEON优化:log10函数的优化案例
猜你喜欢

ARM裸板调试之JTAG调试体验

The MySQL database in Alibaba cloud was attacked, and finally the data was found
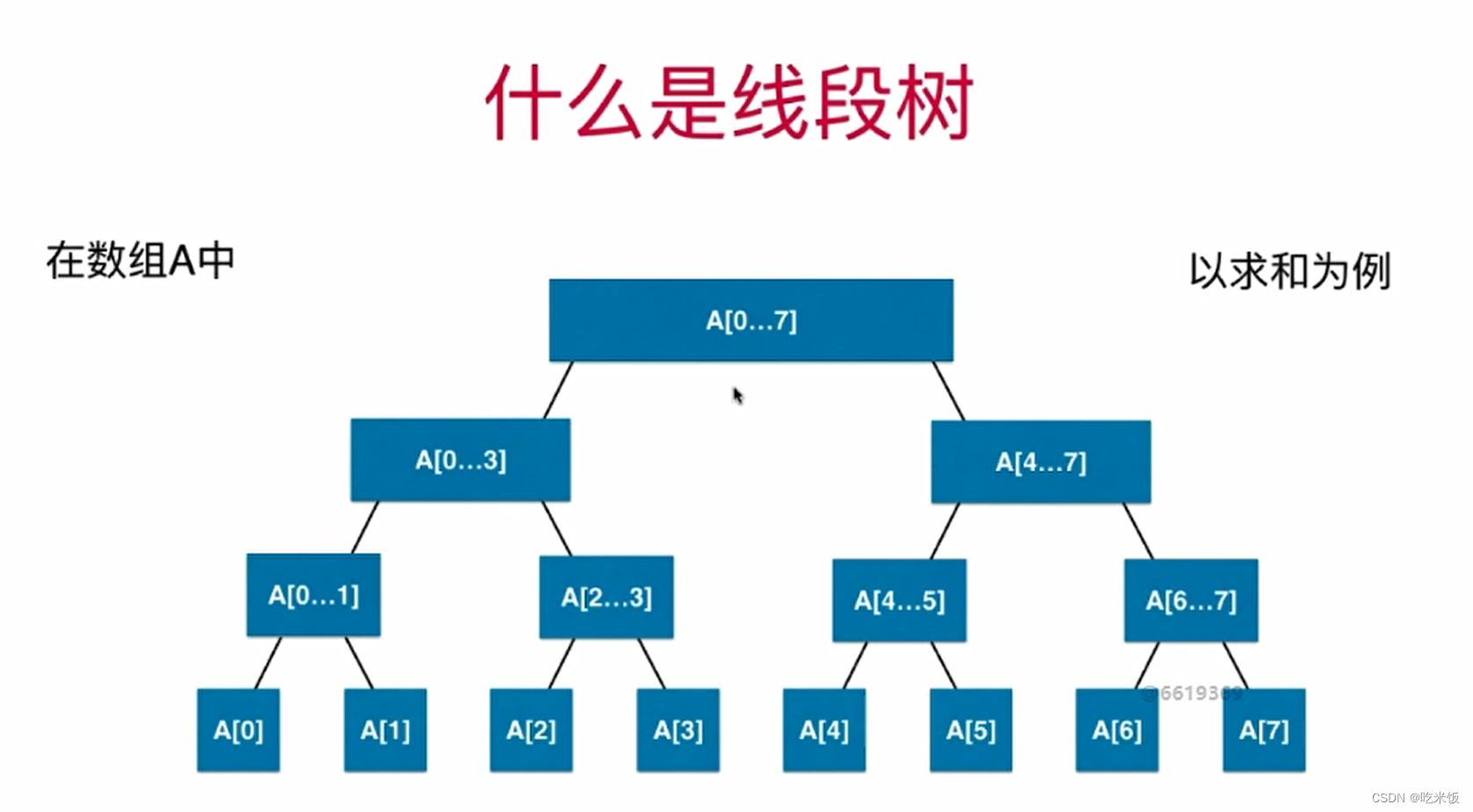
Segmenttree
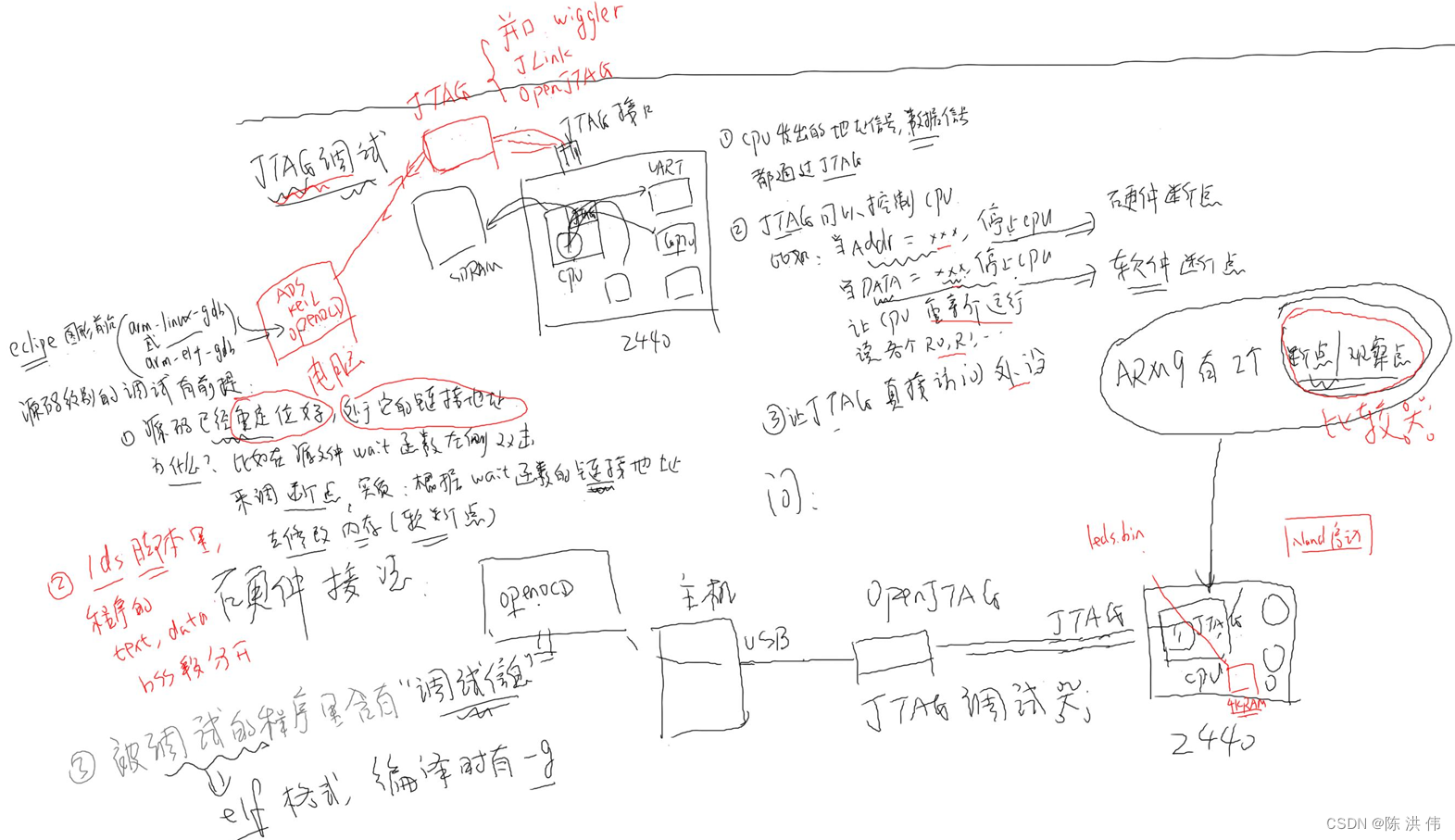
ARM裸板调试之JTAG原理
Part IV: STM32 interrupt control programming
界面控件DevExpress WinForms皮肤编辑器的这个补丁,你了解了吗?

Maidong Internet won the bid of Beijing life insurance to boost customers' brand value

UI控件Telerik UI for WinForms新主题——VS2022启发式主题
Do you understand this patch of the interface control devaxpress WinForms skin editor?
![[Niuke] b-complete square](/img/bd/0812b4fb1c4f6217ad5a0f3f3b8d5e.png)
[Niuke] b-complete square
随机推荐
Taro中添加小程序 “lazyCodeLoading“: “requiredComponents“,
golang中的Mutex原理解析
[Niuke] [noip2015] jumping stone
【JVM调优实战100例】05——方法区调优实战(下)
THREE.AxesHelper is not a constructor
[100 cases of JVM tuning practice] 05 - Method area tuning practice (Part 2)
动态规划思想《从入门到放弃》
Link sharing of STM32 development materials
接收用户输入,身高BMI体重指数检测小业务入门案例
Install Firefox browser on raspberry pie /arm device
Niuke cold training camp 6B (Freund has no green name level)
Gazebo的安装&与ROS的连接
UI control telerik UI for WinForms new theme - vs2022 heuristic theme
Address information parsing in one line of code
Body mass index program, entry to write dead applet project
Gnet: notes on the use of a lightweight and high-performance go network framework
自旋与sleep的区别
[batch dos-cmd command - summary and summary] - view or modify file attributes (attrib), view and modify file association types (Assoc, ftype)
界面控件DevExpress WinForms皮肤编辑器的这个补丁,你了解了吗?
线段树(SegmentTree)