当前位置:网站首页>Neon Optimization: summary of performance optimization experience
Neon Optimization: summary of performance optimization experience
2022-07-07 01:14:00 【To know】
NEON Optimize : Performance optimization experience summary
NEON Optimization series :
- NEON Optimize 1: Software performance optimization 、 How to reduce power consumption ?link
- NEON Optimize 2:ARM Summary of optimized high frequency instructions , link
- NEON Optimize 3: Matrix transpose instruction optimization case ,link
- NEON Optimize 4:floor/ceil Optimization case of function ,link
- NEON Optimize 5:log10 Optimization case of function ,link
- NEON Optimize 6: About cross access and reverse cross access ,link
- NEON Optimize 7: Performance optimization experience summary ,link
- NEON Optimize 8: Performance optimization FAQs QA,link
This article summarizes the commonly used NEON Optimization techniques and important references .

photo from 《Practical approach to Arm Neon Optimization》, It shows various fields such as NEON Optimized excellent example code base ,Neon-enabled libraries.
Optimization techniques
High frequency common
Hotspot functions involve a large number of IO When reading and writing , The memory address of the data should be the same as NEON Array or system bit alignment , Such as 32 Bit alignment , It can reduce the access cost
run demo obtain profile, Look at the proportion of expenses Top5, It must be optimized for a version
Priority should be given to NEON Instruction Parallel Computing , It can greatly reduce the cost
for loop
- Circular numbers are not preferred 4 The row expands ; For large circulation 8 Parallel Computing
- Loop variable i, Try to set it to basic data type , Such as 32 position
- Such as for In circulation if Optimize ,if Chinese vs cnt Count , use 4 Registers are stored , At the end 4 Add register values
- When using the subtraction counter in the loop, the overhead can be reduced
- Such as : for (b = 0; b < num; b++)
- Change it to :for (b = 0; b < num - 3; b += 4)
- It can be changed :for (b = num - 1; b - 3 >= 0; b -= 4)
- It can be changed :for (b = num - 1; b >= 3; b -= 4)
- Be sure to remember when reading and writing data , Move the coordinates forward by the corresponding position , Original read :
cf[b], Today read :cf[b - 3]
Array index value
- Array index and the operation involved in the index , Try to replace it with pointer offset plus or minus
- Avoid large index jumps , Reduce cache miss, See... For specific examples : Matrix multiplication optimization , Divided into 4*4 Handle
Memory usage
- Local variables are preferred , Instead of malloc Heap memory , Reduce cache miss
- For specific variable types , Manual for Loop parallel copy value , Maybe it's better than memcpy() Functions are more efficient , because memcpy There is also a lot of judgment involved inside , To ensure platform compatibility
- involve IO When reading and writing , Soft imitation data may not accurately reflect hard imitation results , Hard copy shall prevail , Soft copy cannot simulate the latest chip level optimization
Instruction operation
- Matrix multiplication scene , Without significantly increasing register variables , External A It's also best to read more data in parallel , Follow B Column operations of , Reduce B Number of reads per column
- Multiply and add instructions ,add and mul Can be combined into mla, One instruction completes the multiply add operation
Algorithmic perspective
- Observe the algorithm of hot spot function , Optimize the time complexity from the algorithm level , Carry out equivalent implementation
- Whether the data is orderly ,for Whether the cycle can become dichotomy
- Whether bubble sorting can become merging
- Whether there is redundant logic , Redundant variable calculation
- Observe the algorithm of hot spot function , Optimize the time complexity from the algorithm level , Carry out equivalent implementation
details
- Bad 1 problem : Pay attention to... Again !
- It is found that parallel computing often occurs in loops :
-4, +=4Combination question , Even if there is 4 Values can only be calculated separately . - Should be changed to :
-3,+=4; Other similar :-7, +=8; Whether it's <=、< or >= scene . - give an example :
- original :
for (i = 0; i < size; i++) - parallel :
for (i = 0; i < size - 3; i += 4) - Finish up :
for (; i < size; i ++)
- original :
- principle : With 4 Take Lu as an example
- Parallel writing ,-3 The purpose of is to ensure from i From the beginning, there will be 4 Two available values ,+4 The goal is to i To iterate , Every time 4 Go forward once
- The last word , The purpose of adding finishing is to deal with size Can not be 4 The scene of division , Not enough at the end 4 The remaining values of are processed separately
- It is found that parallel computing often occurs in loops :
- NEON Optimize macro switches
- Commonly used
#ifndef XX_NO_NEONMacro switch to control NEON switch , Easy to fall back NEON Optimize the version debug
- Commonly used
- Bad 1 problem : Pay attention to... Again !
Compilation options
Initial compilation options :O0,Omemory( Optimize memory ), Open inline
Optimize compilation options :O2,Otime( Optimize time ), Do not open inline ; Generally open O2
When baseline optimization is recommended , Try to choose
Do not open inlining to improve the view, In order to observe the actual overhead in the hotspot function- Opened inline , It's easy to see , Some big overhead functions I Inline to X Function , But just look X The function can't be optimized for a long time
- Such as guanneilian , Then the overhead function I Is far more than X function , Become Top Hotspot overhead function , Convenient for optimization analysis
Try to use O3 Optimization is used O3, Some codes that cannot be used alone O2 Optimize compilation , Then link the module , Together O3 compile
Don't be easy restore default Compile settings , Otherwise, all configurations will fail , Such as compilation platform 、 Compilation options
matters needing attention
Cost calculation
- When calculating the cost of each frame , Make sure that the duration of each frame is 10ms、20ms, Modify the corresponding frame length
- RVDS Calculated in MCPS Essential for MIPS, Pay attention to distinguish it from the result of hard imitation
Other questions
use #ifndef XX_NO_NEON To define about NEON The macro , What's the intention , Why don't #ifdef XX_NEON?
#ifndef ALG_NO_NEON
// opt_neon_code
...
#else
// origin code
...
#endif
- ifndef The meaning of is , Because the baseline output view belongs to low-frequency operation , And check every time NEON The progress of optimization is high frequency operation , So by default NEON Optimize , When viewing the baseline, you only need to add the corresponding macro .
- Of course , Such as habit
#ifdef XX_NEONYou can't help it , It doesn't affect the effect .
Related resources
Attach good resources used in the learning process , The last reference link is colored eggs , involve :Optimizing Software in C++ - Agner Fog - PDF,C++ Software performance optimization .
This book is all C++ A book that programmers should read , It does everything from the language level 、 Compiler level 、 Memory access level 、 Multithreading level 、CPU Level describes how to tune software performance , It is a classic e-book , Welcome to advanced reading !
Data link summary :
- google keywords: neon optimization, A large number of relevant resources can be obtained
- NEON Optimize ARM The official introduction ,link
- NEON Optimize ARM Official introduction article translation ,link
- ARM Official programmers Neon Programming Guide ,link
- Optimizing C Code with Neon Intrinsics, link
- ARM Neon Intrinsics Learning points north : From the beginning 、 Advanced to learn a thorough ,link
- How to improve software performance with NEON, link
- ittiam: Professional optimization materials of Indian ether company ,link1,link2
- AI neural network CNN in im2col Calculation optimization of matrix convolution kernel ,link
- Google development cmath.h Of NEON Optimize , Library links :link, Library description :link
- blockbuster ! performance optimization PDF:Optimizing software in C++,An optimization guide for Windows, Linux, and Mac platforms,link
边栏推荐
- STM32开发资料链接分享
- 新手如何入门学习PostgreSQL?
- Build your own website (17)
- Supersocket 1.6 creates a simple socket server with message length in the header
- gnet: 一个轻量级且高性能的 Go 网络框架 使用笔记
- Building a dream in the digital era, the Xi'an station of the city chain science and Technology Strategy Summit ended smoothly
- Tensorflow GPU installation
- Atomic in golang and CAS operations
- 迈动互联中标北京人寿保险,助推客户提升品牌价值
- JTAG debugging experience of arm bare board debugging
猜你喜欢
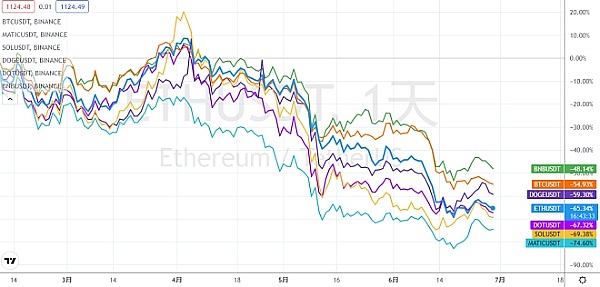
资产安全问题或制约加密行业发展 风控+合规成为平台破局关键
Anfulai embedded weekly report no. 272: 2022.06.27--2022.07.03

Force buckle 1037 Effective boomerang

Let's see through the network i/o model from beginning to end

View remote test data and records anytime, anywhere -- ipehub2 and ipemotion app
Dynamic planning idea "from getting started to giving up"
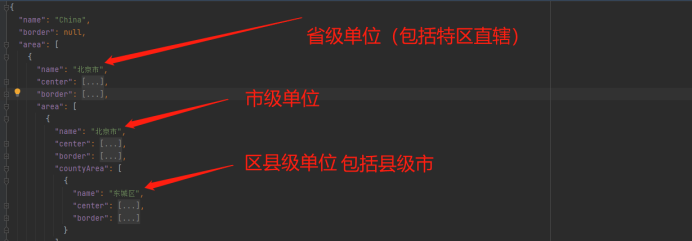
Provincial and urban level three coordinate boundary data CSV to JSON
![[HFCTF2020]BabyUpload session解析引擎](/img/db/6003129bc16f943ad9868561a2d5dc.png)
[HFCTF2020]BabyUpload session解析引擎
第七篇,STM32串口通信编程

golang中的Mutex原理解析
随机推荐
taro3.*中使用 dva 入门级别的哦
tensorflow 1.14指定gpu运行设置
C# 计算农历日期方法 2022
paddlehub应用出现paddle包报错的问题
Installation and testing of pyflink
Address information parsing in one line of code
阿里云中mysql数据库被攻击了,最终数据找回来了
Chenglian premium products has completed the first step to enter the international capital market by taking shares in halber international
资产安全问题或制约加密行业发展 风控+合规成为平台破局关键
Building a dream in the digital era, the Xi'an station of the city chain science and Technology Strategy Summit ended smoothly
Telerik UI 2022 R2 SP1 Retail-Not Crack
Realize incremental data synchronization between MySQL and ES
Periodic flash screen failure of Dell notebook
C Primer Plus Chapter 14 (structure and other data forms)
Supersocket 1.6 creates a simple socket server with message length in the header
How do novices get started and learn PostgreSQL?
【JVM调优实战100例】05——方法区调优实战(下)
Force buckle 1037 Effective boomerang
深度学习简史(一)
重上吹麻滩——段芝堂创始人翟立冬游记