当前位置:网站首页>第7章 __consumer_offsets topic
第7章 __consumer_offsets topic
2022-07-06 09:29:00 【留不住斜阳】
7.1 基本结构
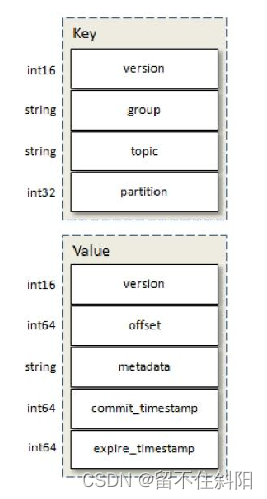
key
- version:版本字段,不同kafka版本version不同
- group: 对应消费者组的groupid,这条消息要发送到__consumer_offsets的哪个分区,是由这个字段决定的
- topic:主题名称
- partition:主题的分区
value
- version:版本字段,不同kafka版本的version不同
- offset:这个group消费这个topic到哪个位置了
- metadata:自定义元数据信息
- commit_timestamp:提交消费位移的时间
- expire_timestamp:过期时间,当数据过期时会有一个定时任务去清理过期的消息
- 查询__consumer_offsets topic所有内容
注意:运行下面命令前先要在consumer.properties中设置exclude.internal.topics=false
0.11.0.0之前版本
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
0.11.0.0之后版本(含)
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
- 获取指定consumer group位移信息
消息存储分区
Math.abs("test".hashCode()) % 50;//48, 表示test这个groupid的offset记录提交到了__consumer_offset的48号分区里
- 查看__consumer_offsets的数据结构
//kafka 0.11以后(含)
kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 指定分区 --broker-list localhost:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
//kafka0.11以前
kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 指定分区 --broker-list localhost:9092 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter"
可以看到__consumer_offsets topic的每一日志项的格式都是
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
7.2 kafka 消费者offset存储方式
在kafka 0.9 版本开始提供了新的consumer及consumer group,位移的管理与保存机制发生了很大的变化,新版本的consumer默认将不再保存位移到zookeeper中,而是__consumer_offsets topic中
- 如果消费者根据java api来消费,也就是
kafka.javaapi.consumer.ConsumerConnector,通过配置参数zookeeper.connect来消费。这种情况,消费者的offset会更新到zookeeper的/kafka/consumers/<group.id>/offsets/<topic>/<partitionId>,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。 - 因此kafka提供了另一种解决方案:增加__consumer_offsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖(指保存offset这件事情)。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息。
7.3 创建消费者获取__consumer_offsets topic内容
import kafka.common.OffsetAndMetadata;
import kafka.coordinator.*;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.nio.ByteBuffer;
import java.util.Collections;
import java.util.Properties;
public class KafkaCli {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "cdh003:9092");
//每个消费者分配独立的组号
props.put("group.id", "test_1");
//如果value合法,则自动提交偏移量
props.put("enable.auto.commit", "true");
//设置多久一次更新被消费消息的偏移量
props.put("auto.commit.interval.ms", "1000");
//设置会话响应的时间,超过这个时间kafka可以选择放弃消费或者消费下一条消息
props.put("session.timeout.ms", "30000");
//该参数表示从头开始消费该主题
props.put("auto.offset.reset", "earliest");
//注意反序列化方式为ByteArrayDeserializer
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArrayDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.ByteArrayDeserializer");
KafkaConsumer<byte[], byte[]> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("__consumer_offsets"));
System.out.println("Subscribed to topic " + "__consumer_offsets");
while (true) {
ConsumerRecords<byte[], byte[]> records = consumer.poll(100);
for (ConsumerRecord<byte[], byte[]> record : records) {
// 这里直接将record的全部信息写到System.out打印流中
// GroupMetadataManager.OffsetsMessageFormatter formatter = new GroupMetadataManager.OffsetsMessageFormatter();
// formatter.writeTo(record, System.out);
//对record的key进行解析,注意这里的key有两种OffsetKey和GroupMetaDataKey
//GroupMetaDataKey中只有消费者组ID信息,OffsetKey中还包含了消费的topic信息
BaseKey key = GroupMetadataManager.readMessageKey(ByteBuffer.wrap(record.key()));
if (key instanceof OffsetKey) {
GroupTopicPartition partition = (GroupTopicPartition) key.key();
String topic = partition.topicPartition().topic();
String group = partition.group();
System.out.println("group : " + group + " topic : " + topic);
System.out.println(key.toString());
} else if (key instanceof GroupMetadataKey) {
System.out.println("groupMetadataKey:------------ "+key.key());
}
//对record的value进行解析
OffsetAndMetadata om = GroupMetadataManager.readOffsetMessageValue(ByteBuffer.wrap(record.value()));
//System.out.println(om.toString());
}
}
}
}
Key的解析输出信息如下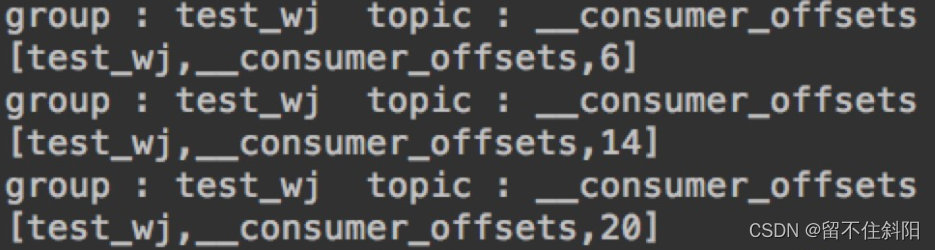
Value的解析输出信息如下
使用这种解析方式过一会儿就出现如下异常:
Exception in thread "main" org.apache.kafka.common.protocol.types.SchemaException: Error reading field 'metadata': Error reading string of length 25970, only 12 bytes available
at org.apache.kafka.common.protocol.types.Schema.read(Schema.java:72)
at kafka.coordinator.GroupMetadataManager$.readOffsetMessageValue(GroupMetadataManager.scala:958)
at kafka.coordinator.GroupMetadataManager.readOffsetMessageValue(GroupMetadataManager.scala)
at com.wangjian.KafkaCli.main(KafkaCli.java:68)
当key类型为GroupMetadataKey时,去解析OffsetAndMetadata会抛异常,应该用如下方法去解析GroupMetadata
if (key instanceof GroupMetadataKey) {
System.out.println("groupMetadataKey: " + key.key());
//第一个参数为group id,先将key转换为GroupMetadataKey类型,再调用它的key()方法就可以获得group id
GroupMetadata groupMetadata = GroupMetadataManager.readGroupMessageValue(((GroupMetadataKey) key).key(), ByteBuffer.wrap(record.value()));
System.out.println("GroupMetadata: "+groupMetadata.toString());
}
输出如下
groupMetadataKey: test_1
GroupMetadata: [test_1,Some(consumer),Stable,Map(consumer-1-2b952983-41bd-4bdb-bc65-89ceedd91d26 -> [consumer-1-2b952983-41bd-4bdb-bc65-89ceedd91d26,consumer-1,/172.18.89.153,30000])]
可以看到GroupMetadata中保存了该消费者组中每个消费者的具体信息,包括了消费者所在IP等
使用formatter方式写到System.out输出信息如下
GroupMetadataManager.OffsetsMessageFormatter formatter = new GroupMetadataManager.OffsetsMessageFormatter();
formatter.writeTo(record, System.out);

这是完整的OffsetMessage信息,同时也可以看到__consumer_offsets topic的每一日志项的格式都是
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
7.4 总结
kafka存储到__consumer_offsets 的topic的元数据信息有两种
- key:OffsetKey —————————> value:OffsetAndMetadata 保存了消费者组各个partition的offset位移信息元数据
- key:GroupMetadataKey ————————> value:GroupMetadata 保存了消费者组中各个消费者的信息
在通过java 开发consumer去消费该topic获取元数据时,应注意区分这两种情况,还有反序列化方式。
对于spark streaming来说,其中DStream中,DStream的本质是RDD序列,读取kafka时,也就是KafkaRDD,通过读取KafkaRDD的getPartitions方法,可以发现,KafkaRDD 的 partition 数据与 Kafka topic 的某个 partition 的 o.fromOffset 至 o.untilOffset 数据是相对应的,也就是说 KafkaRDD 的 partition 与 Kafka partition 是一一对应的。
边栏推荐
- Input can only input numbers, limited input
- Flask框架配置loguru日志库
- window11 conda安装pytorch过程中遇到的一些问题
- Suffix expression (greed + thinking)
- SF smart logistics Campus Technology Challenge (no T4)
- (POJ - 1458) common subsequence (longest common subsequence)
- Flask框架配置loguru日志庫
- (lightoj - 1354) IP checking (Analog)
- Sanic异步框架真的这么强吗?实践中找真理
- Generate random password / verification code
猜你喜欢
300th weekly match - leetcode

1013. Divide the array into three parts equal to and
1855. Maximum distance of subscript alignment

使用jq实现全选 反选 和全不选-冯浩的博客

antd upload beforeUpload中禁止触发onchange
解决Intel12代酷睿CPU【小核载满,大核围观】的问题(WIN11)

去掉input聚焦时的边框
1903. Maximum odd number in string
Local visualization tools are connected to redis of Alibaba cloud CentOS server

Codeforces Round #799 (Div. 4)A~H
随机推荐
Local visualization tools are connected to redis of Alibaba cloud CentOS server
Educational Codeforces Round 130 (Rated for Div. 2)A~C
力扣:第81场双周赛
Specify the format time, and fill in zero before the month and days
Openwrt build Hello ipk
VMware Tools和open-vm-tools的安装与使用:解决虚拟机不全屏和无法传输文件的问题
简单尝试DeepFaceLab(DeepFake)的新AMP模型
605. Planting flowers
Click QT button to switch qlineedit focus (including code)
Radar equipment (greedy)
Some problems encountered in installing pytorch in windows11 CONDA
Codeforces Round #802(Div. 2)A~D
(POJ - 3685) matrix (two sets and two parts)
China double brightening film (dbef) market trend report, technical dynamic innovation and market forecast
Market trend report, technological innovation and market forecast of China's double sided flexible printed circuit board (FPC)
Share an example of running dash application in raspberry pie.
Flask框架配置loguru日志库
Generate random password / verification code
QT implementation window gradually disappears qpropertyanimation+ progress bar
树莓派4B64位系统安装miniconda(折腾了几天终于解决)