当前位置:网站首页>Cartoon: what is MapReduce?
Cartoon: what is MapReduce?
2022-07-05 16:09:00 【Small ash】
————— the second day —————
————————————
What is? MapReduce?
MapReduce It's a programming model , The theory comes from Google Three papers published by the company (MapReduce,BigTable,GFS) One of , It is mainly used in parallel computing of massive data .
MapReduce Can be divided into Map and Reduce Two parts of understanding .
1.Map: Mapping process , Put a set of data in a certain way Map Functions map to new data .
2.Reduce: Reduction process , Several groups of mapping results are summarized and output .
Let's look at a practical chestnut , How to efficiently count the number of people with all surnames in the country ?
We can use MapReduce Thought , Do parallel mapping for the population of each province , Some local results are obtained , And then sort out and summarize these local results :
What does this picture mean ? Let's explain the steps :
1.Map:
In provinces , Multiple threads read the population data of different provinces in parallel , Each record generates a Key-Value Key value pair . Here's just simplified data .
2.Shuffle
Shuffle This concept has not been mentioned before , Its Chinese meaning is “ Shuffle ”.Shuffle The process is to sort the data maps 、 grouping 、 Copy .
3.Reduce
Results grouped before execution , And summarize and output .
It should be noted that , Described here Shuffle It's just an abstract concept , In the course of actual implementation Shuffle It's divided into two parts , Part of it is Map In the task , Part of it is Reduce In the task .
Hadoop How to achieve MapReduce?
Hadoop yes Apache A distributed system framework developed by the foundation , Contains multiple components , Its core is HDFS and MapReduce.
For reasons of length , The text won't be right Hadoop Make a complete introduction , Just a brief introduction to Haddoop How to achieve MapReduce.
Here is the graph Hadoop The framework performs a MapReduce Job The whole process :
There are several entities that need to be explained :
HDFS:
Hadoop Distributed file system , by MapReduce Provide data sources and Job Information storage .
Client Node:
perform MapReduce Process of procedure , To submit MapReduce Job.
JobTracker Node:
Put the whole Job Split into several Task, Responsible for dispatching and coordinating all Task, amount to Master Role .
TaskTracker Node:
Responsible for the execution by JobTracker Assigned Task, amount to Worker Role . Of these Task It is divided into MapTask and ReduceTask.
Last , I wish you guys who aspire to be big data engineers , And all the readers of Xiaohui , Achieve your dream in the new year !
—————END—————
边栏推荐
- 利用GrayLog告警功能实现钉钉群机器人定时工作提醒
- Cs231n notes (top) - applicable to 0 Foundation
- Basic JSON operations of MySQL 5.7
- Information collection of penetration test
- Defining strict standards, Intel Evo 3.0 is accelerating the upgrading of the PC industry
- 【简记】解决IDE golang 代码飘红报错
- 项目sql中批量update的时候参数类型设置错误
- Lesson 4 knowledge summary
- 异常com.alibaba.fastjson.JSONException: not match : - =
- 21.[STM32]I2C协议弄不懂,深挖时序图带你编写底层驱动
猜你喜欢
![17. [stm32] use only three wires to drive LCD1602 LCD](/img/c6/b56c54da2553a451b526179f8b5867.png)
17. [stm32] use only three wires to drive LCD1602 LCD
Lesson 4 knowledge summary

abstract关键字和哪些关键字会发生冲突呢
Xiao Sha's arithmetic problem solving Report
Appium自动化测试基础 — APPium基础操作API(一)

【网易云信】超分辨率技术在实时音视频领域的研究与实践
MySQL overview
vlunhub- BoredHackerBlog Moriarty Corp
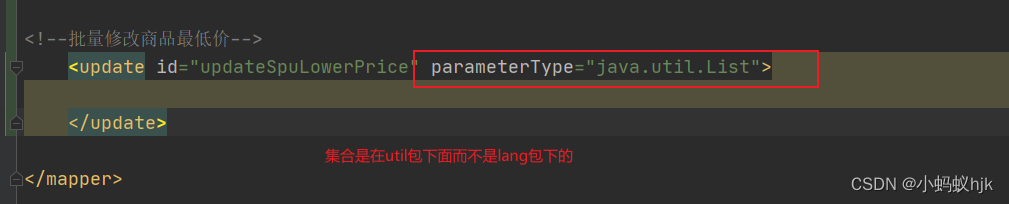
项目sql中批量update的时候参数类型设置错误
Summary of the third class
随机推荐
【簡記】解决IDE golang 代碼飄紅報錯
Li Kou today's question -729 My schedule I
RepLKNet:不是大卷积不好,而是卷积不够大,31x31卷积了解一下 | CVPR 2022
ES6 drill down - Async functions and symbol types
抽象类中子类与父类
事务回滚异常
Dataarts studio data architecture - Introduction to data standards
MySQL overview
Xiao Sha's arithmetic problem solving Report
18.[STM32]读取DS18B20温度传感器的ROM并实现多点测量温度
APICloud云调试解决方案
Go language programming specification combing summary
一文搞定vscode编写go程序
The difference between abstract classes and interfaces
国泰君安网上开户安全吗
MySQL table field adjustment
17. [stm32] use only three wires to drive LCD1602 LCD
List uses stream flow to add according to the number of certain attributes of the element
abstract关键字和哪些关键字会发生冲突呢
10分钟帮你搞定Zabbix监控平台告警推送到钉钉群