1. What is? Scrapy-Redis
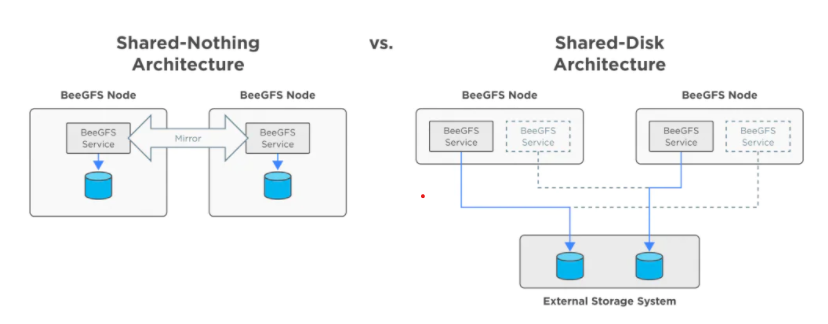
- Scrapy-Redis yes scrapy Based on the framework of redis Distributed components of , yes scrapy An extension of ; Distributed crawlers combine multiple hosts , Complete a climbing task together , Improve the crawling efficiency quickly and efficiently .
- The original scrapy Your request is placed in memory , Get from memory .scrapy-redisr Put the request in redis Inside , Each host checks whether the request has been crawled , I haven't climbed , Queue up , Take out the host and crawl . Climb over and see the next request .
- Data of each host spiders Write the final parsed data to redis in
- advantage : Speed up the project ; The instability of a single node does not affect the stability of the whole system ; Support endpoint crawling
- shortcoming : A lot of hardware resources need to be invested , Hardware 、 Network bandwidth, etc

- stay scrapy Based on the framework process , Put storage request The object is put in redis In an ordered set of , The request queue is realized by using the ordered set
- Also on request Object generate fingerprint object , Also stored in the same redis The collection of , utilize request Fingerprints avoid sending duplicate requests
2.Scrapy-Redis Distributed strategy
Suppose there are three computers :Windows 10、Ubuntu 16.04、Windows 10, Any computer can be used as Master End or Slaver End , such as :
- Master End ( Core server ) : Use Windows 10, Building a Redis database , Not responsible for crawling , Only responsible for url Fingerprint weight 、Request The distribution of , And data storage .
- Slaver End ( Crawler execution end ) : Use Ubuntu 16.04、Windows 10, Responsible for executing the crawler program , Submit a new Request to Master.
First Slaver End slave Master Take the task (Request、url) Grab data ,Slaver While grabbing data , To create a new task Request Then submit it to Master Handle
Master There is only one end Redis database , Be responsible for taking care of what is not handled Request De duplication and task allocation , Will deal with the Request Join queue to be crawled , And store the crawled data .
Scrapy-Redis The default is this strategy , It's easy for us to realize , Because of task scheduling and so on Scrapy-Redis It's all done for us , We just need to inherit RedisSpider、 Appoint redis_key That's it .
The disadvantage is that ,Scrapy-Redis The scheduled task is Request object , There's a lot of information in it ( It's not just about url, also callback function 、headers Etc ), The possible result is that it will slow down the speed of the reptiles 、 And will occupy Redis A lot of storage space , So if we want to ensure efficiency , Then we need a certain level of hardware .
3.Scrapy-Redis Installation and project creation
3.1. install scrapy-redis
pip install scrapy-redis

3.2. Pre preparation for project creation
- win 10
- Redis install :redis Refer to this for related configurations https://www.cnblogs.com/gltou/p/16226721.html; If you learn this from your notes , The previous link redis edition 3.0 Too old , You need to reinstall the new version , New version download link :https://pan.baidu.com/s/1UwhJA1QxDDIi2wZFFIZwow?pwd=thak, Extraction code :thak;
- Another Redis Desktop Manager: This software is used to view redis Data stored in , It's easy to install , Just take the next step ; Download link :https://pan.baidu.com/s/18CC2N6XtPn_2NEl7gCgViA?pwd=ju81 Extraction code :ju81
Redia Simple explanation of installation : After the installation package is downloaded , Click next to continue the installation , Record the installation path ; Note that it is necessary to install redis Add the installation directory of to the environment variable ; Whenever you modify the configuration file , Need to restart redis when , Remember to restart the service


Another Redis Desktop Manager Simple explanation : Click on 【New Connection】 add to redis Connect , The connection is as follows ( Address 、 Port, etc ), password Auth And a nickname Name Not required .

You can see redis Installed environment 、 At present redis Version of 、 Memory 、 Number of connections and other information . Later, our notes will explain how to view the data to be captured through the software URL as well as URL The fingerprints of 
3.3. Project creation
Create common scrapy Reptile project , Transform into scrapy-redis project ; Ordinary reptiles are divided into four stages : Create project 、 Clear objectives 、 Create crawler 、 Save the content ;
scrapy After the crawler project is created , To transform , The specific transformation points are as follows :
- Import scrapy-redis Distributed crawler classes in
- Inheritance class
- notes start_url & allowed_domains
- Set up redis_key obtain start_urls
- edit settings file
3.3.1. establish scrapy Reptiles
step-1: Create project
establish scrapy_redis_demo Catalog , Enter the command in this directory scrapy startproject movie_test , Generate scrapy project cd To movie_test Under the project cd .\movie_test\ Enter the command scrapy genspider get_movie 54php.cn Generate spiders Template file ; This process is not clear , go to https://www.cnblogs.com/gltou/p/16400449.html Study



step-2: Clear objectives
stay items.py In file , Make clear what data we need to crawl from the target website this time .

1 # Define here the models for your scraped items
2 #
3 # See documentation in:
4 # https://docs.scrapy.org/en/latest/topics/items.html
5
6 import scrapy
7
8
9 class MovieTestItem(scrapy.Item):
10 # define the fields for your item here like:
11 # name = scrapy.Field()
12
13 # The title of the movie
14 tiele = scrapy.Field()
15
16 # A detailed description of the film
17 desc= scrapy.Field()
18
19 # Of the movie URL
20 download_url=scrapy.Field()
step-3: Create crawler

Import items.py Class , stay get_movie.py Write our crawler file in the file , The following is get_movie.py Of code Code
import scrapy
from ..items import MovieTestItem class GetMovieSpider(scrapy.Spider):
name = 'get_movie'
allowed_domains = ['54php.cn']
start_urls = ['http://movie.54php.cn/movie/'] def parse(self, response):
movie_item=response.xpath("//div[2][@class='row']/div")
for i in movie_item:
# Details page url
detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first()
yield scrapy.Request(url=detail_url,callback=self.parse_detail) next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first()
if next_page:
next_page_url='http://movie.54php.cn{}'.format(next_page)
yield scrapy.Request(url=next_page_url,callback=self.parse) def parse_detail(self,response):
""" Analysis details page """
movie_info=MovieTestItem()
movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first()
movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first()
movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first()
yield movie_info
stay settings.py Enabled in file USER_AGENT And put the website value Put it in ; take ROBOTSTXT_OBEY Agreement changed to False

step-4: Save the content
Don't write... Here for the time being , Ignore first , Change the back to scrapy-redis write in redis when , Then write relevant code
step-5: Run crawler , View results
Enter the command scrapy crawl get_movie Run crawler , View results ; finish_reason by finished End of run 、 item_scraped_count Climb and take 1060 Data 、 log_count/DEBUG Log file DEBUG Total records 2192 And other result information .

scrapy The project was created and run successfully , Next, we will carry on scrapy-redis reform
3.3.2. Change it to scrapy-redis Reptiles
step-1: Modify the crawler file
get_movie.py Crawler file import scrapy_redis Of RedisSpider class , And inherit him ; take allowed_domains and start_urls Comment out ; newly added redis_key , value value It's a key-value pair ,key Namely name Value is the name of the crawler ,value Namely start_urls This variable name
1 import scrapy
2 from ..items import MovieTestItem
3 from scrapy_redis.spiders import RedisSpider
4
5 class GetMovieSpider(RedisSpider):
6 name = 'get_movie'
7 # allowed_domains = ['54php.cn']
8 # start_urls = ['http://movie.54php.cn/movie/']
9 redis_key = "get_movie:start_urls"
10
11 def parse(self, response):
12 movie_item=response.xpath("//div[2][@class='row']/div")
13 for i in movie_item:
14 # Details page url
15 detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first()
16 yield scrapy.Request(url=detail_url,callback=self.parse_detail)
17
18 next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first()
19 if next_page:
20 next_page_url='http://movie.54php.cn{}'.format(next_page)
21 yield scrapy.Request(url=next_page_url,callback=self.parse)
22
23 def parse_detail(self,response):
24 """ Analysis details page """
25 movie_info=MovieTestItem()
26 movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first()
27 movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first()
28 movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first()
29 yield movie_info
30
31
step-2: modify redis The configuration file
take redis.windows.conf and redis.windows-service.conf In file bind Set to 0.0.0.0 , restart redis service



step-3:redis Deposit seeds url
cmd Input redis-cli Get into redis Command line , If you have a password , Additional orders auth password Pictured

Will reptile get_movie.py Set in file redis_key ( It's a key-value pair ,key Namely name Value is the name of the crawler ,value Namely start_urls This variable name ), stay redis in lpush once ;redis Command line input lpush The command format will be brought out later , Don't worry about him , stay lpush Type in key and value value

lpush Of key Values are in the code redis_key Value ,value yes start_urls Value , After the input of , Press down Enter key

stay Another Redis Desktop Manager Check whether the addition is successful in the software , Found added successfully

step-4: Add components and... To the configuration file redis Parameters
settings.py Add settings to the file to reassemble and schedule components , add to redis Connection information ;
1 # Set to reassemble
2 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
3 # The scheduling component
4 SCHEDULER = "scrapy_redis.scheduler.Scheduler"
5
6 #redis Connection information
7 REDIS_HOST = "127.0.0.1"
8 REDIS_PORT = 6379
9 REDIS_ENCODING = 'utf-8'
10 #REDIS_PARAMS = {"password":"123456"}

doubt : Someone will definitely ask , I am here settings.py Added... To the file redis Information about ,scrapy How did you get the framework ?
answer : Actually in https://www.cnblogs.com/gltou/p/16400449.html This note has already mentioned ,scrapy Framework of the scrapy.cfg The file will tell the framework where the configuration file is , Pictured , That is to say movie_test In the catalog settings In file

then scrapy Running fear from the file is through cmdline Of execute Method running , This method executes get_project_settings( ) Method , Import the global configuration file scrapy.cfg, Then import the project settings .py

adopt get_project_settings( ) This method is project.py file , We are from Some of you see the import Settings, Interested people can study the source code by themselves 
step-5: Run the crawler file
pycharm Enter the command scrapy crawl get_movie Run the crawler file

It's common to report mistakes :

Error reporting analysis : This is because we installed scrapy Version problems , install Scrapy==2.5.1 Version can
Solution :
pip install -U Scrapy==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/

Be careful : stay pycharm After reinstallation , Start the crawler file and report an error . stay cmd The window executes again pip command , The problem is solved

Run the crawler script , During crawling , Find out redis There are two tables ( Easy to understand description ), get_movie:dupefilter Represents what has been crawled URL, get_movie:requests Represents the to be crawled url

The crawler script was executed successfully , see redis, Find out value There are a lot of data in it , All these data are hash value , Already crawled url It'll take hash The way to store to value Inside , In this way, you won't crawl the same url. After crawling ,pycharm Press ctrl+c Stop script 
step-6: Crawl again
After the execution of the crawler script ,redis Inside the seeds url period . Want to execute the crawler script again , The seeds need to be distributed again redis, That is, execute again lpush command , You can execute the crawler script again .

Distribute the seeds again


Execute the script to crawl again

3.3.3. Breakpoint creep
When the crawler breaks halfway , After setting breakpoint continuous climbing , Reptiles will then crawl , Instead of crawling data again . How to realize breakpoint continuous climbing , It's simple , Again settings.py Open the breakpoint to continue crawling in the file
1 # Breakpoint creep
2 SCHEDULER_PERSIST = True

Example
scene : Halfway through the reptile we CTRL+C Stop the crawler script and start the crawler script again after crawling , No seeds url Execute the crawler script again
step :
step-1:redis Put the seeds url Execute the crawler , Force to stop the crawler script
LPUSH get_movie:start_urls http://movie.54php.cn/movie/



result : Climb to half , We force the crawler script to stop , Find out redis Inside requests The data is still , It didn't disappear
step-2: Start the crawler file again


result : At the end of the script, the number of crawls counted is the number of crawls for the second time , Not the total quantity
step-3: When the crawl is over , We start the crawler file again


result : The console tells us start_urls It's been grabbed , What you want to grab url stay get_movie:dupefilter It's all inside , Don't crawl anymore
------------------------------------------------------------------------------------------------------------------------------------
reflection : Don't give the seed again url Under the circumstances , I just want to crawl many times ?
Solution : In crawler files parse Method inside yield When it comes back , Add parameters dont_filter=True You can crawl again ;dont_filter yes scrapy Filter repeated requests , The default is False Can filter dupefilter Past requests have been captured in , Avoid repeated grabs , Change it to True After that, it is not filtered , You can request crawling again ,scrapy Providing this parameter allows you to decide whether the data should be filtered or retrieved repeatedly

Example
step-1: Distribute seeds url, Execute the crawler , Wait for the reptile to finish



step-2: End of climb , Press down CTRL+C Stop script , Click as shown Flush DB Empty DB, Execute the crawler script again ; No incoming seeds URL Under the circumstances , Reptiles can crawl as usual

3.4. Implement distributed crawlers
Explain the implementation of distributed crawler through an example project ;
The content is more , In the new essay :https://www.cnblogs.com/gltou/p/16433539.html
Reptiles (14) - Scrapy-Redis Distributed crawlers (1) | More related articles in detail
- 【Python3 Reptiles 】 The first step in learning distributed crawlers --Redis First experience of distributed crawler
One . Write it at the front The reptiles written before are all single reptiles , I haven't tried distributed crawlers yet , This is the first experience of a distributed crawler . So called distributed crawlers , It is to use multiple computers to crawl data at the same time , Compared to a single reptile , The crawling speed of distributed reptiles is faster , Can also better deal with I ...
- scrapy Conduct distributed crawler
today , Refer to Mr. Cui Qingcai's reptile practice course , Practice the distributed crawler , It's not as mysterious as previously thought , It's very simple , I believe after you read this article , In less than an hour , You can start to complete a distributed crawler ! 1. Principle of distributed crawler First, let's take a look ...
- scrapy Add - Distributed crawlers
spiders Introduce : In the project is to create a crawler py file #1.Spiders It consists of a series of classes ( Defines a URL or group of URLs that will be crawled ) form , Specifically, it includes how to perform crawling tasks and how to extract structured data from pages . #2. Sentence change ...
- Python Detailed explanation of the photo example of the crawler's crawling Amoy girl
This article mainly introduces Python Detailed explanation of the photo example of the crawler's crawling Amoy girl , In this paper, the example code is introduced in detail , It has certain reference learning value for everyone's study or work , Friends in need, let's study together with Xiaobian The goal of this article Grab Taobao MM ...
- Xiaobai advanced Scrapy Chapter 6 Scrapy-Redis Detailed explanation ( turn )
Scrapy-Redis Detailed explanation Usually when we collect at a station , If it's a small station We use scrapy Itself can meet . But if you are facing some large sites , Single scrapy It seems that I can't do it . want ...
- Scrapy The command line of the framework 【 turn 】
Scrapy The command line of the framework Please praise the author --> Link to the original text This article is mainly right scrapy An introduction to the use of the command line Create a crawler project scrapy startproject Examples of project names are as follows : loca ...
- Reflection implementation Model Comparison of contents before and after revision 【API call 】 Tencent cloud SMS Windows Under the operating system Redis Service installation details Redis Introduction learning
Reflection implementation Model Comparison of contents before and after revision In the development process , We're going to have this problem , After editing an object , We want to save what the object has changed , So that we can see and trace the responsibility in the future . First we need to create a User class 1 p ...
- redis Five data structures are explained in detail (string,list,set,zset,hash)
redis Five data structures are explained in detail (string,list,set,zset,hash) Redis It's not just about supporting simple key-value Data of type , It also provides list,set,zset,hash And so on ...
- NoSQL And Redis Advanced practical command details -- Security and master-slave replication
Android IOS JavaScript HTML5 CSS jQuery Python PHP NodeJS Java Spring MySQL MongoDB Redis NOSQL Vim ...
- Redis Details of the transaction function of
Redis Details of the transaction function of MULTI.EXEC.DISCARD and WATCH The order is Redis The foundation of transaction function .Redis Transactions allow a set of commands to be executed in a single step , And we can guarantee the following two important things : >Re ...
Random recommendation
- Use Git Project management
First, in the https://git.oschina.net Register and login After logging in , If you want to create a project , Can be in Click the plus button , Project creation 3. Take creating a private project as an example : When you're done typing , Click on “ establish ”, Enter next ...
- Node.js Learning from -- Use cheerio Grab web data
I'm going to write an open class website , Lack of data , I decided to go to Netease open class to grab some data . I saw it a while ago Node.js, and Node.js It's more suitable to do this , I'm going to use Node.js To grab data . The key is to grab the web page ...
- Build from scratch mongo A simple method of partition cluster
One . Catalog 1.mongo route ,config Data path ,shard Data path
- Maven Use notes ( One )Maven Installation and common commands
1.Windows Lower installation Maven First download Maven Installation package ,http://maven.apache.org/download.cgi, The latest version is Maven 3.2.3 . Unzip to local , You can see ...
- 【 turn 】HTML, CSS and Javascript Introduction to debugging
turn http://www.cnblogs.com/PurpleTide/archive/2011/11/25/2262269.html HTML, CSS and Javascript Introduction to debugging This article introduces some new ideas ...
- php frame Symfony Information
1.http://snippets.symfony-project.org/snippets/tagged/criteria/order_by/date 2.Propel API: http://ap ...
- Hbase split The process and the condition of the solution
One .Split The trigger condition 1. There's either one of them Hfile The size of is larger than the default 10G when , It's all going on split 2. Reaching this value doesn't mean splitting , The default is int_max, Do not split 3.compact ...
- XML Entity reference for
Entity reference stay XML in , Some characters have a special meaning . If you put the characters "<" Put it in XML In the elements , There will be mistakes , This is because the parser takes it as the beginning of a new element . This will produce XML error : ...
- supervisor The centralized management of
1.supervisor Very good , Unfortunately, it's a stand-alone version , So go on github I found a management tool on the Internet supervisord-monitor. github Address : https://github.com/mlazarov/s ...
- Spring Boot Used in Spring Security and JWT
The goal is 1.Token authentication 2.Restful API 3.Spring Security+JWT Start Self built Spring Boot engineering Introduce dependency <dependency> < ...
![[play with Linux] [docker] MySQL installation and configuration](/img/04/6253ef9fdf7d2242b42b4c7fb2c607.png)