当前位置:网站首页>ucorelab4
ucorelab4
2022-07-06 15:24:00 【Hu Da jinshengyu】
lab4
The experiment purpose
- Learn about kernel thread creation / Management process implemented
- Understand the switching and basic scheduling process of kernel threads
Experimental content
experiment 2/3 Completed physical and virtual memory management , This creates a kernel thread ( Kernel thread is a special process ) Laid the foundation for providing memory management . When a program is loaded into memory to run , First, through ucore OS The memory management subsystem allocates appropriate space , Then you need to think about how to use time-sharing CPU Come on “ Concurrent ” Execute multiple programs , Let each program run ( Here, thread or process is used to represent )“ feel ” They each have “ own ” Of CPU.
This experiment will first touch the management of kernel threads . Kernel thread is a special process , There are two differences between kernel threads and user processes :
- Kernel thread only runs in kernel state
- User processes run alternately in user mode and kernel mode
- All kernel threads share ucore Kernel memory space , There is no need to maintain separate memory space for each kernel thread
- User processes need to maintain their own user memory space
See the appendix for the introduction of relevant principles B:【 principle 】 process / Thread properties and characteristics analysis .
practice 0: Fill in the existing experiment
This experiment relies on experiments 1/2/3. Please take your experiment 1/2/3 Fill in the code in this experiment. There are “LAB1”,“LAB2”,“LAB3” The corresponding part of the notes .
Use meld Will experiment 1/2/3 Fill the corresponding part of the code in Experiment 4 :

among , The part to be modified is :
default_pmm.c
pmm.c
swap_fifo.c
vmm.c
trap.c
practice 1: Allocate and initialize a process control block ( Need to code )
alloc_proc function ( be located kern/process/proc.c in ) Assign and return a new struct proc_struct structure , Used to store the management information of the newly established kernel thread .ucore This structure needs to be initialized at the most basic level , You need to complete this initialization process .
【 Tips 】 stay alloc_proc Function implementation , Need to initialize proc_struct The member variables in the structure include at least :state/pid/runs/kstack/need_resched/parent/mm/context/tf/cr3/flags/name.
Please briefly describe your design and implementation process in the experimental report . Please answer the following questions :
- Please explain proc_struct in struct context context and struct trapframe *tf What is the meaning of member variables and their role in this experiment ?( Tip: you can tell by looking at the code and programming debugging )
Prepare knowledge
Some knowledge about the process
The process includes all the status information of a running program , Including code 、 data 、 Register, etc .
Some characteristics of the process :
dynamic : You can create... Dynamically 、 The end of the process
And issued : The process can be called independently and occupy the processor to run
independence : The work between different processes is not affected
conditionality : Multiple processes access shared data 、 Constraints arising from synchronization between resources or processes
Process control block (PCB) It is a collection of information used to manage and control the operation of processes .PCB Is the only sign that a process exists , Each process has a corresponding PCB, For the operating system PCB To describe the basic information of the process and the running changes .PCB Usually contains the process identifier 、 Processor information 、 Process scheduling information 、 Process control information .
Process switching ( Context switch ): Pause the current process , Change from running state to other state , Call another process to change from ready state to running state . In the process , You need to save the process context before switching , So that the process can be resumed later , And switch as quickly as possible ( Therefore, the code of process switching process is usually written in assembly ).CPU Give each task a certain service time , When the time goes round , You need to save the current state , Load the next task at the same time , At this time, context switching is performed .
Classic process five state model (new,ready,waitting,running,terminated):
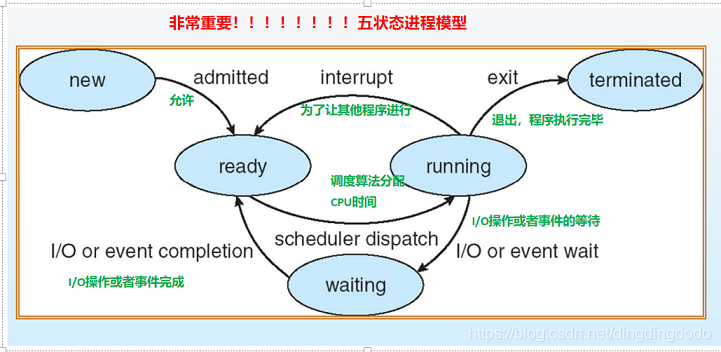
process was suspended : The process image in the suspended state is on disk , The purpose is to reduce the memory occupied by the process . In contrast, it becomes process activation , Activate the process in the suspended state , Transfer the process from external memory to memory .
Realization
The operating system is process centric , So its first task is to establish archives for the process , The process file is used to represent 、 Identify or describe the process , Process control block . What needs to be done here is the initialization of a process control block .
Here we allocate a kernel thread PCB, It is usually just a small piece of code or function in the kernel , No user space . And because after the operating system starts , The entire core memory space has been managed , The core virtual space is established by setting the page table ( namely boot_cr3 The space described by the secondary page table pointed to ). Therefore, all threads in the kernel no longer need to establish their own page tables , Just share this core virtual space to access the entire physical memory .
First, in the kern/process/proc.h It defines PCB, That is, the structure of the process control block proc_struct, as follows :
struct proc_struct {
// Process control block
enum proc_state state; // Process status
int pid; // process ID
int runs; // The elapsed time
uintptr_t kstack; // Kernel stack location
volatile bool need_resched; // Whether it needs to be scheduled
struct proc_struct *parent; // The parent process
struct mm_struct *mm; // Virtual memory of the process
struct context context; // Process context
struct trapframe *tf; // Pointer to the current interrupt frame
uintptr_t cr3; // Current page table address
uint32_t flags; // process
char name[PROC_NAME_LEN + 1];// Process name
list_entry_t list_link; // Process linked list
list_entry_t hash_link; // Process hash table
};
Combined with the experimental instructions to analyze PCB Meaning of parameters :
- state: The state of the process .
- PROC_UNINIT // No initial state
- PROC_SLEEPING // sleep ( Blocking ) state
- PROC_RUNNABLE // Running and ready
- PROC_ZOMBIE // A dead state
- pid: process id Number .
- kstack: Records the assigned to the process / The location of the kernel of the thread .
- need_resched: Whether it needs to be scheduled
- parent: The parent process of the user process .
- mm: That is, the structure describing the process virtual memory in Experiment 3
- context: The context of the process , For process switching .
- tf: Pointer to the interrupt frame , Always point to a location on the kernel stack . The interrupt frame records the status of the process before it is interrupted .
- cr3: The address of the currently used page table is recorded
see alloc_proc function , This function is responsible for creating and initializing a new proc_struct Structure stores kernel thread information , adopt kmalloc Function can apply for memory space for related data information , Then initialize . There is a trick in the initial process , For member variables that contain more variables or variables that occupy a larger space , have access to memset To initialize . Pay attention to the reasonable initialization of each variable ( Initialize to 0 Or some special values ). Initialize the variables one by one according to the prompt of the code comment , Generally speaking, it is relatively easy .
// alloc_proc - Responsible for creating and initializing a new proc_struct Structure stores kernel thread information
static struct proc_struct *
alloc_proc(void)
{
// Apply for space for the created thread
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL)
{
//LAB4:EXERCISE1 YOUR CODE
// Because there is no physical page allocated , Therefore, the thread state is initially set to the initial state
proc->state=PROC_UNINIT;
proc->pid=-1; //id Initialize to -1
proc->runs=0; // Run at 0
proc->kstack=0;
proc->need_resched=0; // No need to release CPU, Because it has not been allocated
proc->parent=NULL; // There is currently no parent process , For the initial null
proc->mm=NULL; // Currently unallocated memory , For the initial null
// use memset It's very convenient to context All member variables in the variable are set to 0
// Avoid the trouble of assigning values one by one ..
memset(&(proc -> context), 0, sizeof(struct context));
proc->tf=NULL; // There are currently no interrupt frames , For the initial null
proc->cr3=boot_cr3; // Kernel thread ,cr3 be equal to boot_cr3
proc->flags=0;
memset(proc -> name, 0, PROC_NAME_LEN);
}
return proc;
}
The running process of the entire allocation initialization function is :
- Allocate a memory space on the heap to store process control blocks
- Initialize the parameters in the process control block
- Return the allocated process control block
Question 1 :struct context context and struct trapframe *tf member Meaning and function of variables
According to the prompt, we check the relevant code ( By looking up definitions tf as well as context Function of ):
First we found kernel_thread Functions and copy_thread function , It is known that this function is right tf Set up , Also on context Of esp and eip Set up ( The specific setting process is given in the code comments ):
/* kernel_thread Function uses local variables tf To place a temporary interrupt frame that holds the kernel thread , And pass the pointer of the interrupt frame to do_fork function , and do_fork Function will call copy_thread Function to allocate a space on the newly created process kernel stack for the interrupt frame of the process */
int kernel_thread(int (*fn)(void *), void *arg, uint32_t clone_flags) {
struct trapframe tf;
memset(&tf, 0, sizeof(struct trapframe));
//kernel_cs and kernel_ds The code and data segments representing the kernel thread are in the kernel
tf.tf_cs = KERNEL_CS;
tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS;
//fn Refers to the actual thread entry address
tf.tf_regs.reg_ebx = (uint32_t)fn;
tf.tf_regs.reg_edx = (uint32_t)arg;
//kernel_thread_entry Used to do some initialization work
tf.tf_eip = (uint32_t)kernel_thread_entry;
return do_fork(clone_flags | CLONE_VM, 0, &tf);
}
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf)
{
// take tf To initialize
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
// Set up tf Of esp, Information indicating interrupt stack
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
// Yes context Set it up
//forkret It mainly deals with the returned interrupt , Basically, it can be regarded as an interrupt processing and recovery
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
By combining the above functions switch.S Chinese vs context The operation of , Save the values of various registers to context in . We can know context It is related to context switching , and tf It is related to the processing of interrupts .
Specific answer :
context effect :
The context of the process , For process switching . It mainly saves the site of the previous process ( Status of each register ). stay uCore in , All processes are relatively independent in the kernel . Use context The purpose of saving registers is to switch between contexts in kernel mode . The actual use of context The function for context switching is in kern/process/switch.S In the definition of switch_to.
tf effect :
Pointer to the interrupt frame , Always point to a location on the kernel stack : When a process jumps from user space to kernel space , The interrupt frame records the status of the process before it is interrupted . When the kernel needs to jump back into user space , The interrupt frame needs to be adjusted to recover the values of each register that allows the process to continue execution . besides ,uCore The kernel allows nested interrupts . Therefore, to ensure that nested interrupts occur tf Always able to point to the current trapframe,uCore Maintained on the kernel stack tf Chain .
practice 2: Allocate resources for newly created kernel threads ( Need to code )
Creating a kernel thread requires a lot of resources to be allocated and set up .kernel_thread Function by calling do_fork Function to complete the creation of specific kernel threads .do_kernel Function will call alloc_proc Function to allocate and initialize a process control block , but alloc_proc Just found a small piece of memory to record the necessary information of the process , These resources are not actually allocated .ucore Usually by do_fork Actually create a new kernel thread .do_fork The role of is , Create a copy of the current kernel thread , Their execution context 、 Code 、 The data are the same , But the storage location is different . In the process , New kernel threads need to be allocated resources , And copy the state of the original process . You need to finish in kern/process/proc.c Medium do_fork Processing procedure in function . Its general execution steps include :
- call alloc_proc, First, get a block of user information .
- Assign a kernel stack to the process .
- Copy the memory management information of the original process to the new process ( But kernel threads don't have to do this )
- Copy the original process context to the new process
- Add a new process to the process list
- Wake up a new process
- Return the new process number
Please briefly describe your design and implementation process in the experimental report . Please answer the following questions :
- Please explain ucore Whether to give each new fork A unique thread id? Please explain your analysis and reasons .
Prepare knowledge
According to the notes, we know the purpose and usage of several functions :
// Create a proc And initialize all member variables
void alloc_proc(void)
// Allocate physical pages for a kernel thread
static int setup_kstack(struct proc_struct *proc)
// I haven't seen its use for the time being , Maybe later lab use
static int copy_mm(uint32_t clone_flags, struct proc_struct *proc)
// Copy the original process context to the new process
static void copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf)
// Return to one pid
static int get_pid(void)
// take proc Add to hash_list
static void hash_proc(struct proc_struct *proc)
// Wake up the thread , Set the status of this thread to be able to run
void wakeup_proc(struct proc_struct *proc);

Above, eflags register
Macro definition :
#define local_intr_save(x) \ do {
x = __intr_save(); } while (0)
#define FL_IF 0x00000200
#define local_intr_restore(x) __intr_restore(x);
The following is the specific implementation process :
According to the requirements ,do_fork() The implementation steps of the function include seven steps , Then, according to the comments, the general implementation process is as follows :
① call alloc_proc() Function request memory block , If you fail , Directly return to processing .alloc_proc() The function was implemented in exercise 1 , If the allocation process PCB Failure , in other words , The process starts with NULL, Then it will be if(proc!=NULL) Judged as no , Then initialization resources will not be allocated , There are no initialization resources , So it's going to return NULL.
② call setup_kstack() Function to allocate a kernel stack for the process . You can see from the function code below , If the page is not empty , Meeting return 0, That is to say, the allocation of kernel stack is successful ( The basis for this speculation is , the last one return -E_NO_MEM, Presumably, it is an initialized or wrong state , Because in the first part of this function, you don't need to implement , This value is assigned to ret), So it's going to return 0, Otherwise, it returns a strange thing . therefore , We call this function to allocate a kernel stack space , And judge whether the allocation is successful .
static int
setup_kstack(struct proc_struct *proc) {
struct Page *page = alloc_pages(KSTACKPAGE);
if (page != NULL) {
proc->kstack = (uintptr_t)page2kva(page);
return 0;
}
return -E_NO_MEM;
}
③ call copy_mm() function , Copy the memory information of the parent process to the child process . For this function, you can see , process proc Copy or share the current process current, It's based on clone_flags To decide , If it is clone_flags & CLONE_VM( It's true ), Then you can copy . Nothing seems to be done in this function , Just make sure current Whether the virtual memory of the current process is empty , Then the specific operation , Just pass in what it needs clone_flag Can , We don't need to do the rest .
static int
copy_mm(uint32_t clone_flags, struct proc_struct *proc) {
assert(current->mm == NULL);
/* do nothing in this project */
return 0;
}
④ call copy_thread() Function copies the interrupt frame and context information of the parent process .copy_thread() The function requires three parameters passed in , The first is more familiar , What has been achieved in exercise 1 PCB modular proc The object of the structure , The second parameter , It's a stack , The basis of judgment is its data type , In exercise one PCB Module , The data type defined for the stack is uintptr_t, The third parameter is also familiar , It is practice one PCB Pointer to the interrupt frame in .
static void
copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) {
proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1;
*(proc->tf) = *tf;
proc->tf->tf_regs.reg_eax = 0;
proc->tf->tf_esp = esp;
proc->tf->tf_eflags |= FL_IF;
proc->context.eip = (uintptr_t)forkret;
proc->context.esp = (uintptr_t)(proc->tf);
}
⑤ Add a new process to the process's (hash) In the list . call hash_proc This function can add the current new process to the Hash list of the process , analysis hash Features of functions , Call directly hash(proc) that will do .
hash_proc(struct proc_struct *proc) {
list_add(hash_list + pid_hashfn(proc->pid), &(proc->hash_link));
}
⑥ Wake up a new process .
⑦ Return to the new process pid.
do_fork Implementation of function :
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS) {
goto fork_out;
}
ret = -E_NO_MEM;
//1: call alloc_proc() Function request memory block , If you fail , Directly return to processing
if ((proc = alloc_proc()) == NULL) {
goto fork_out;
}
//2. Set the parent node of the child process as the current process
proc->parent = current;
//3. call setup_stack() Function to allocate a kernel stack for the process
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
//4. call copy_mm() Function copies the memory information of the parent process to the child process
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
//5. call copy_thread() Function copies the interrupt frame and context information of the parent process
copy_thread(proc, stack, tf);
//6. Add a new process to the process's hash In the list
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc); // Building mapping
nr_process ++; // Number of processes plus 1
list_add(&proc_list, &(proc->list_link));// Add the process to the linked list of the process
}
local_intr_restore(intr_flag);
// 7. Everything is ready. , Wake up subprocess
wakeup_proc(proc);
// 8. Returns the pid
ret = proc->pid;
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
Question 1 :ucore Whether to give each new fork A unique thread id?
uCore in , Every new fork There is only one thread ID, For the following reasons :
- In function get_pid in , If static member last_pid Less than next_safe, The currently allocated last_pid It must be safe , The only one PID.
- But if last_pid Greater than or equal to next_safe, perhaps last_pid The value of exceeds MAX_PID, Then the current last_pid Is not necessarily the only PID, At this point, you need to traverse proc_list, Back to the last_pid and next_safe Set it up , For the next time get_pid Call to lay the foundation .
Next, you may want to analyze the content of this function :
Two static local variables are used in this function next_safe and last_pid, According to the naming conjecture , Every time you enter get_pid Function , The values between the values of these two variables are legal pid( That is to say, it has not been used ), In this case , If there are strict next_safe > last_pid + 1, Then you can directly take last_pid + 1 As new pid( need last_pid Not beyond MAX_PID To become 1);
If you enter the function , There is no legal value after these two variables , in other words next_safe > last_pid + 1 Don't set up , Then enter the cycle , Pass first in the cycle if (proc->pid == last_pid) This branch ensures that there are no processes pid And last_pid coincidence , And then through if (proc->pid > last_pid && next_safe > proc->pid) This judgment statement ensures that there is no existing pid Satisfy :last_pid < pid < next_safe, This ensures that such a conditional interval can be found in the end , Get legal pid;
The reason why such a tortuous method is used in this function , Maintain a legal pid The range of , To optimize time efficiency , If it's simple violence , Every time you need to enumerate all pid, And traverse all threads , This makes the cost of time too high , And different calls get_pid When calling this function, you cannot use the intermediate result of the previous call to this function ;
getpid Function as follows :
// get_pid - alloc a unique pid for process
static int
get_pid(void) {
// actually , It was defined before MAX_PID=2*MAX_PROCESS, signify ID The total number of is greater than PROCESS The total number of
// So there will be no part PROCESS nothing ID Separable situation
static_assert(MAX_PID > MAX_PROCESS);
struct proc_struct *proc;
list_entry_t *list = &proc_list, *le;
//next_safe and last_pid Two variables , Here we need to pay attention to ! They are static Global variables !!!
static int next_safe = MAX_PID, last_pid = MAX_PID;
//++last_pid>-MAX_PID, explain pid And to the end , We need to start all over again
if (++ last_pid >= MAX_PID)
{
last_pid = 1;
goto inside;
}
if (last_pid >= next_safe)
{
inside:
next_safe = MAX_PID;
repeat:
//le Equal to the chain header of the thread
le = list;
// Go through the list
// Cycle through each current process : When an existing process number and last_pid When equal , Will last_pid+1;
// When the existing process number is greater than last_pid when , This means that in the process of scanning
//[last_pid,min(next_safe, proc->pid)] This process number has not been occupied , Continue scanning .
while ((le = list_next(le)) != list)
{
proc = le2proc(le, list_link);
// If proc Of pid And last_pid equal , Will last_pid Add 1
// Of course , If last_pid>=MAX_PID,then Turn it into 1
// Ensure that there is no process pid And last_pid coincidence
if (proc->pid == last_pid)
{
if (++ last_pid >= next_safe)
{
if (last_pid >= MAX_PID)
{
last_pid = 1;
}
next_safe = MAX_PID;
goto repeat;
}
}
//last_pid<pid<next_safe, Make sure you can finally find such a qualified interval , Get legal pid;
else if (proc->pid > last_pid && next_safe > proc->pid)
{
next_safe = proc->pid;
}
}
}
return last_pid;
}
practice 3: Reading the code , understand proc_run Function and the function it calls how to complete process switching .( No coding work )
Please briefly explain your understanding of proc_run Analysis of functions . And answer the following questions :
- During the execution of this experiment , Several kernel threads were created and run ?
- sentence
local_intr_save(intr_flag);....local_intr_restore(intr_flag);What is the role here ? Please give reasons
After the code is written , Compile and run the code :make qemu
If you can get something like appendix A As shown in ( For reference only , Not standard answer output ), Is basically correct .
Prepare knowledge
The experimental instruction is based on ,uCore in , The first process of the kernel idleproc Will execute cpu_idle function , And call... From it schedule function , Ready to start scheduling process , Complete process scheduling and process switching .
void cpu_idle(void) {
while (1)
if (current->need_resched)
schedule();
}
schedule Function code analysis :
/* Macro definition : #define le2proc(le, member) \ to_struct((le), struct proc_struct, member)*/
void
schedule(void) {
bool intr_flag; // Define interrupt variables
list_entry_t *le, *last; // At present list, Next list
struct proc_struct *next = NULL; // Next process
local_intr_save(intr_flag); // Interrupt inhibit function
{
current->need_resched = 0; // Setting the current process does not require scheduling
//last Whether it is idle process ( The first process created ), If it is , Search from the header
// Otherwise, get the next linked list
last = (current == idleproc) ? &proc_list : &(current->list_link);
le = last;
do {
// Cycle all the time , Until you find a process that can be scheduled
if ((le = list_next(le)) != &proc_list) {
next = le2proc(le, list_link);// Get the next process
if (next->state == PROC_RUNNABLE) {
break; // Find a process that can be scheduled ,break
}
}
} while (le != last); // Cycle through the entire linked list
if (next == NULL || next->state != PROC_RUNNABLE) {
next = idleproc; // No process can be scheduled
}
next->runs ++; // Number of runs plus one
if (next != current) {
proc_run(next); // Run new process , call proc_run function
}
}
local_intr_restore(intr_flag); // Allow the interrupt
}
You can see ucore What we achieve is FIFO Scheduling algorithm :
1 When scheduling starts , Mask the interrupt first .
2 In the process linked list , Find the first program that can be scheduled
3 Run new process , Allow the interrupt
chedule Function will clear the scheduling flag first , And start from the position of the current process in the linked list , Traverse the process control block , Until you find the process in the ready state .
After performing proc_run function , Switch the environment to the context of the process and continue execution .
Mention context switching , You need to use switch_to function :
switch_to: # switch_to(from, to)
# save from's registers
movl 4(%esp), %eax # preservation from The first address
popl 0(%eax) # Save the return value to context Of eip
movl %esp, 4(%eax) # preservation esp Value to context Of esp
movl %ebx, 8(%eax) # preservation ebx Value to context Of ebx
movl %ecx, 12(%eax) # preservation ecx Value to context Of ecx
movl %edx, 16(%eax) # preservation edx Value to context Of edx
movl %esi, 20(%eax) # preservation esi Value to context Of esi
movl %edi, 24(%eax) # preservation edi Value to context Of edi
movl %ebp, 28(%eax) # preservation ebp Value to context Of ebp
# restore to's registers
movl 4(%esp), %eax # preservation to First address to eax
movl 28(%eax), %ebp # preservation context Of ebp To ebp register
movl 24(%eax), %edi # preservation context Of ebp To ebp register
movl 20(%eax), %esi # preservation context Of esi To esi register
movl 16(%eax), %edx # preservation context Of edx To edx register
movl 12(%eax), %ecx # preservation context Of ecx To ecx register
movl 8(%eax), %ebx # preservation context Of ebx To ebx register
movl 4(%eax), %esp # preservation context Of esp To esp register
pushl 0(%eax) # take context Of eip Pressure into the stack
ret
therefore switch_to The function mainly completes the context switching of the process , First save the value of the current register , Then save the context information of the next process to the corresponding register .
proc_run function
void
proc_run(struct proc_struct *proc) {
if (proc != current) {
bool intr_flag;// Define interrupt variables
struct proc_struct *prev = current, *next = proc;
local_intr_save(intr_flag); // Mask interrupt
{
current = proc;// Modify the current process as a new process
load_esp0(next->kstack + KSTACKSIZE);// modify esp
lcr3(next->cr3);// Modify page table entry , Complete the page table switching between processes
switch_to(&(prev->context), &(next->context));// Context switch
}
local_intr_restore(intr_flag); // Allow the interrupt
}
}
Realize the idea :
- Give Way current Point to next Kernel thread initproc;
- Set the task status segment ts Medium privileged state 0 Top of stack pointer under esp0 by next Kernel thread initproc The top of the kernel stack , namely next->kstack + KSTACKSIZE ;
- Set up CR3 The value of the register is next Kernel thread initproc The starting address of the page table of contents next->cr3, This actually completes the page table switching between processes ;
- from switch_to Function to switch between two threads , That is, switch each register , When switch_to Function execution finished “ret” After the instruction , Just switch to initproc Yes
Question 1 : During the execution of this experiment , Several kernel threads were created and run ?
Two , Namely idleproc and initproc.
- idleproc: The first kernel process , Complete the initialization of each subsystem in the kernel , Then dispatch immediately , Perform other processes .
- initproc: The kernel process scheduled to complete the function of the experiment .
Question two : sentence A What is the role here ? Please give reasons .
The functions are shielding interrupt and opening interrupt , To prevent other processes from scheduling when the process switches . That is to protect the process switching from being interrupted , To prevent other processes from scheduling when the process switches , It's equivalent to a mutex . This operation is also required when adding processes to the list in step 6 , Because when the process enters the list , A series of scheduling events may occur , For example, we are familiar with steals and so on , Adding such a protection mechanism can ensure that the process execution is not disrupted .
experimental result
Input make qemu Compare with the experimental instruction :
Found the same , It shows that the experiment is successful .
Next , Input make grade The following results can be obtained :
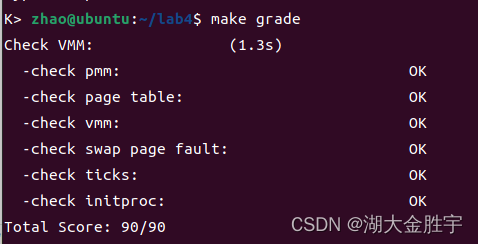
Extended exercises Challenge: The implementation supports memory allocation algorithms of any size
This is not the content of this experiment , In fact, it is the expansion of memory in the last experiment , But considering the present slab The algorithm is complex , It is necessary to implement a relatively simple arbitrary size memory allocation algorithm . Refer to slab How to call the page based memory allocation algorithm ( Be careful , Not for your attention slab The concrete realization of ) To achieve first-fit/best-fit/worst-fit/buddy Support memory allocation algorithm of any size .
Implementation process
With a few modifications , You can use the experiment 2 Extended exercises achieve Slub Algorithm .
- initialization Slub Algorithm : Initialize at the end of initializing physical memory Slub ;
void pmm_init(void) {
...
kmem_int();
}
- stay vmm.c Use in Slub Algorithm :
In order to use Slub Algorithm , You need to declare the pointer of the warehouse .
struct kmem_cache_t *vma_cache = NULL;
struct kmem_cache_t *mm_cache = NULL;
Create a warehouse when the virtual memory is initialized .
void vmm_init(void) {
mm_cache = kmem_cache_create("mm", sizeof(struct mm_struct), NULL, NULL);
vma_cache = kmem_cache_create("vma", sizeof(struct vma_struct), NULL, NULL);
...
}
stay mm_create and vma_create Use in Slub Algorithm .
struct mm_struct *mm_create(void) {
struct mm_struct *mm = kmem_cache_alloc(mm_cache);
...
}
struct vma_struct *vma_create(uintptr_t vm_start, uintptr_t vm_end, uint32_t vm_flags) {
struct vma_struct *vma = kmem_cache_alloc(vma_cache);
...
}
stay mm_destroy Free memory in .
void
mm_destroy(struct mm_struct *mm) {
...
while ((le = list_next(list)) != list) {
...
kmem_cache_free(mm_cache, le2vma(le, list_link)); //kfree vma
}
kmem_cache_free(mm_cache, mm); //kfree mm
...
}
- stay proc.c Use in Slub Algorithm :
Declare warehouse pointer .
struct kmem_cache_t *proc_cache = NULL;
Create a warehouse in the initialization function .
void proc_init(void) {
...
proc_cache = kmem_cache_create("proc", sizeof(struct proc_struct), NULL, NULL);
...
}
stay alloc_proc Use in Slub Algorithm .
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmem_cache_alloc(proc_cache);
...
}
Refer to the answer analysis :
It is almost the same as the reference answer .
The knowledge points involved in the experiment are listed :
- process
- Process control block
- Process status
- process was suspended
- Threads
- Concept
- Advantages and disadvantages
- User thread and kernel thread
- Comparison between thread and process
Experience and experience :
This experiment is compared with lab1、lab2 as well as lab3 experiment , Generally speaking, the content of the experiment is less , But the knowledge needed is more in-depth . Learned more knowledge .
}
kmem_cache_free(mm_cache, mm); //kfree mm
...
}
- stay proc.c Use in Slub Algorithm :
Declare warehouse pointer .
```c
struct kmem_cache_t *proc_cache = NULL;
Create a warehouse in the initialization function .
void proc_init(void) {
...
proc_cache = kmem_cache_create("proc", sizeof(struct proc_struct), NULL, NULL);
...
}
stay alloc_proc Use in Slub Algorithm .
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmem_cache_alloc(proc_cache);
...
}
Refer to the answer analysis :
It is almost the same as the reference answer .
The knowledge points involved in the experiment are listed :
- process
- Process control block
- Process status
- process was suspended
- Threads
- Concept
- Advantages and disadvantages
- User thread and kernel thread
- Comparison between thread and process
Experience and experience :
This experiment is compared with lab1、lab2 as well as lab3 experiment , Generally speaking, the content of the experiment is less , But the knowledge needed is more in-depth . Learned more knowledge .
边栏推荐
- How to become a good software tester? A secret that most people don't know
- LeetCode#268. Missing numbers
- [pytorch] simple use of interpolate
- LeetCode#204. Count prime
- 基于485总线的评分系统双机实验报告
- 软件测试行业的未来趋势及规划
- Brief introduction to libevent
- STM32学习记录:输入捕获应用
- What are the software testing methods? Show you something different
- [C language] twenty two steps to understand the function stack frame (pressing the stack, passing parameters, returning, bouncing the stack)
猜你喜欢




随机推荐
Lab 8 file system
ArrayList set
Take you to use wxpy to create your own chat robot (plus wechat interface basic data visualization)
ucore lab5
JDBC介绍
Knowledge that you need to know when changing to software testing
CSAPP homework answers chapter 789
Scoring system based on 485 bus
ucore lab 2
ucorelab4
Iterators and generators
如何成为一个好的软件测试员?绝大多数人都不知道的秘密
Global and Chinese market of RF shielding room 2022-2028: Research Report on technology, participants, trends, market size and share
Crawler series of learning while tapping (3): URL de duplication strategy and Implementation
ArrayList集合
Leetcode notes - dynamic planning -day6
ucore lab7 同步互斥 实验报告
LeetCode#36. Effective Sudoku
Flex --- detailed explanation of flex layout attributes
How to write the bug report of software test?