当前位置:网站首页>ucore lab5
ucore lab5
2022-07-06 09:25:00 【湖大金胜宇】
ucore lab5
实验目的:
- 了解第一个用户进程创建过程
- 了解系统调用框架的实现机制
- 了解ucore如何实现系统调用sys_fork/sys_exec/sys_exit/sys_wait来进行进程管理
实验内容:
实验4完成了内核线程,但到目前为止,所有的运行都在内核态执行。实验5将创建用户进程,让用户进程在用户态执行,且在需要ucore支持时,可通过系统调用来让ucore提供服务。为此需要构造出第一个用户进程,并通过系统调用sys_fork/sys_exec/sys_exit/sys_wait来支持运行不同的应用程序,完成对用户进程的执行过程的基本管理。相关原理介绍可看附录B。
练习
练习0:填写已有实验
本实验依赖实验1/2/3/4。请把你做的实验1/2/3/4的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”的注释相应部分。注意:为了能够正确执行lab5的测试应用程序,可能需对已完成的实验1/2/3/4的代码进行进一步改进。
这里首先使用meld来对比目录和文件内部的内容,修改在实验1/2/3/4的代码填入实验五中。
- kdebug.c
- trap.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- proc.c
有一些代码需要进行进一步改进:
改进的alloc_proc函数:
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
proc->state = PROC_UNINIT;
proc->pid = -1;
proc->runs = 0;
proc->kstack = 0;
proc->need_resched = 0;
proc->parent = NULL;
proc->mm = NULL;
memset(&(proc->context), 0, sizeof(struct context));
proc->tf = NULL;
proc->cr3 = boot_cr3;
proc->flags = 0;
memset(proc->name, 0, PROC_NAME_LEN);
proc->wait_state = 0; //PCB新增的条目,初始化进程等待状态
proc->cptr = proc->optr = proc->yptr = NULL;//设置指针
}
return proc;
}
改进的内容为:
这两行代码主要是初始化进程等待状态、和进程的相关指针,例如父进程、子进程、同胞等等。其中的wait_state是进程控制块中新增的条目。避免之后由于未定义或未初始化导致管理用户进程时出现错误。
proc->wait_state = 0; //初始化进程等待状态
proc->cptr = proc->optr = proc->yptr = NULL; //指针初始化
改进的do_fork函数:
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC;
struct proc_struct *proc;
if (nr_process >= MAX_PROCESS) {
goto fork_out;
}
ret = -E_NO_MEM;
if ((proc = alloc_proc()) == NULL) {
goto fork_out;
}
proc->parent = current;
assert(current->wait_state == 0); //确保进程在等待
if (setup_kstack(proc) != 0) {
goto bad_fork_cleanup_proc;
}
if (copy_mm(clone_flags, proc) != 0) {
goto bad_fork_cleanup_kstack;
}
copy_thread(proc, stack, tf);
bool intr_flag;
local_intr_save(intr_flag);
{
proc->pid = get_pid();
hash_proc(proc);
set_links(proc); //设置进程链接
}
local_intr_restore(intr_flag);
wakeup_proc(proc);
ret = proc->pid;
fork_out:
return ret;
bad_fork_cleanup_kstack:
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
改进的内容为:
assert(current->wait_state == 0); //确保进程在等待
set_links(proc); //设置进程链接
第一行代码需要确保当前进程正在等待,我们在alloc_proc中初始化wait_state为0。
改进trap_dispatch函数:
设置每100次时间中断后,当前正在执行的进程准备被调度。同时,注释掉原来的"100ticks"输出
ticks ++;
if (ticks % TICK_NUM == 0) {
assert(current != NULL);
current->need_resched = 1;
//原代码中的print_ticks();改成上面两句
}
break;
这里主要是将时间片设置为需要调度,说明当前进程的时间片已经用完了。
改进 idt_init 函数:
void idt_init(void) {
extern uintptr_t __vectors[];
int i;
for (i = 0;i<sizeof(idt)/sizeof(struct gatedesc);i ++) {
SETGATE(idt[i],0,GD_KTEXT,__vectors[i], DPL_KERNEL);
}
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);
lidt(&idt_pd);
}
改进的内容为:
SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER);这里主要是设置相应的中断门
设置一个特定中断号的中断门,专门用于用户进程访问系统调用,即设置中断T_SYSCALL的触发特权级为DPL_USER。
练习1: 加载应用程序并执行(需要编码)
do_execv函数调用load_icode(位于kern/process/proc.c中)来加载并解析一个处于内存中的ELF执行文件格式的应用程序,建立相应的用户内存空间来放置应用程序的代码段、数据段等,且要设置好proc_struct结构中的成员变量trapframe中的内容,确保在执行此进程后,能够从应用程序设定的起始执行地址开始执行。需设置正确的trapframe内容。
请在实验报告中简要说明你的设计实现过程。
请在实验报告中描述当创建一个用户态进程并加载了应用程序后,CPU是如何让这个应用程序最终在用户态执行起来的。即这个用户态进程被ucore选择占用CPU执行(RUNNING态)到具体执行应用程序第一条指令的整个经过。
首先,我们看到do_execv函数:
do_execve函数主要做的工作就是先回收自身所占用户空间,然后调用load_icode,用新的程序覆盖内存空间,形成一个执行新程序的新进程。
//主要目的在于清理原来进程的内存空间,为新进程执行准备好空间和资源
int do_execve(const char *name, size_t len, unsigned char *binary, size_t size)
{
struct mm_struct *mm = current->mm;
if (!user_mem_check(mm, (uintptr_t)name, len, 0)) {
return -E_INVAL;
}
if (len > PROC_NAME_LEN) {
len = PROC_NAME_LEN;
}
char local_name[PROC_NAME_LEN + 1];
memset(local_name, 0, sizeof(local_name));
memcpy(local_name, name, len);
//如果mm不为NULL,则不执行该过程
if (mm != NULL)
{
//将cr3页表基址指向boot_cr3,即内核页表
lcr3(boot_cr3);//转入内核态
if (mm_count_dec(mm) == 0)
{
//下面三步实现将进程的内存管理区域清空
exit_mmap(mm);//清空内存管理部分和对应页表
put_pgdir(mm);//清空页表
mm_destroy(mm);//清空内存
}
current->mm = NULL;//最后让它当前的页表指向空,方便放入自己的东西
}
int ret;
//填入新的内容,load_icode会将执行程序加载,建立新的内存映射关系,从而完成新的执行
if ((ret = load_icode(binary, size)) != 0) {
goto execve_exit;
}
//给进程新的名字
set_proc_name(current, local_name);
return 0;
execve_exit:
do_exit(ret);
panic("already exit: %e.\n", ret);
}
接下来看到load_icode函数:
下面是loab_icode函数的主要实现思路:
- 为用户进程创建新的mm结构
- 创建页目录表
- 校验ELF文件的魔数是否正确
- 创建虚拟内存空间,即往mm结构体添加vma结构
- 分配内存,并拷贝ELF文件的各个program section到新申请的内存上
- 为BSS section分配内存,并初始化为全0
- 分配用户栈内存空间
- 设置当前用户进程的mm结构、页目录表的地址及加载页目录表地址到cr3寄存器
- 设置当前用户进程的tf结构
static int
load_icode(unsigned char *binary, size_t size) {
if (current->mm != NULL) {
//当前进程的内存为空
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM; //记录错误信息:未分配内存
struct mm_struct *mm;
//(1) create a new mm for current process
if ((mm = mm_create()) == NULL) {
//分配内存
goto bad_mm; //分配失败,返回
}
//(2) create a new PDT, and mm->pgdir= kernel virtual addr of PDT
if (setup_pgdir(mm) != 0) {
//申请一个页目录表所需的空间
goto bad_pgdir_cleanup_mm; //申请失败
}
//(3) copy TEXT/DATA section, build BSS parts in binary to memory space of process
struct Page *page;
//(3.1) get the file header of the bianry program (ELF format)
struct elfhdr *elf = (struct elfhdr *)binary;
//(3.2) get the entry of the program section headers of the bianry program (ELF format)
struct proghdr *ph = (struct proghdr *)(binary + elf->e_phoff); //获取段头部表的地址
//(3.3) This program is valid?
if (elf->e_magic != ELF_MAGIC) {
//读取的ELF文件不合法
ret = -E_INVAL_ELF; //ELF文件不合法错误
goto bad_elf_cleanup_pgdir; //返回
}
uint32_t vm_flags, perm;
struct proghdr *ph_end = ph + elf->e_phnum;//段入口数目
for (; ph < ph_end; ph ++) {
//遍历每一个程序段
//(3.4) find every program section headers
if (ph->p_type != ELF_PT_LOAD) {
//当前段不能被加载
continue ; //continue
}
//虚拟地址空间大小大于分配的物理地址空间
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
//当前段大小为0
continue ;
}
//(3.5) call mm_map fun to setup the new vma ( ph->p_va, ph->p_memsz)
vm_flags = 0, perm = PTE_U;
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
unsigned char *from = binary + ph->p_offset;
size_t off, size;
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
//(3.6) alloc memory, and copy the contents of every program section (from, from+end) to process's memory (la, la+end)
end = ph->p_va + ph->p_filesz;
//(3.6.1) copy TEXT/DATA section of bianry program
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
memcpy(page2kva(page) + off, from, size);
start += size, from += size;
}
//(3.6.2) build BSS section of binary program
end = ph->p_va + ph->p_memsz;
if (start < la) {
/* ph->p_memsz == ph->p_filesz */
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la) {
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
}
}
//(4) build user stack memory
vm_flags = VM_READ | VM_WRITE | VM_STACK;
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
//(5) set current process's mm, sr3, and set CR3 reg = physical addr of Page Directory
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//(6) setup trapframe for user environment
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = USTACKTOP;
tf->tf_eip = elf->e_entry;
tf->tf_eflags = FL_IF;
ret = 0;
out:
return ret;
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
该load_icode函数的主要工作就是给用户进程建立一个能够让用户进程正常运行的用户环境。
具体的实现部分如下:
/* load_icode - 加载二进制程序的内容(ELF格式)作为当前进程的新内容 1. @binary: 二进制程序内容的内存地址 2. @size: 二进制程序内容的大小 */
static int
load_icode(unsigned char *binary, size_t size) {
...
/* tf_cs设置为用户态 tf_ds=tf_es=tf_ss=用户态 tf_esp设置为用户栈的栈顶 tf_eip设置为二进制程序的入口 tf_eflags设置为打开中断 */
//下面6句为根据注释补充的部分
tf->tf_cs = USER_CS;//将tf_cs设置为用户态
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;//tf_ds=tf_es=tf_ss也需要设置为用户态
tf->tf_esp = USTACKTOP;//需要将esp设置为用户栈的栈顶,直接使用之前建立用户栈时的参数USTACKTOP就可以。
tf->tf_eip = elf->e_entry;//eip是程序的入口,elf类的e_entry函数直接声明了,直接使用。
tf->tf_eflags = FL_IF;//FL_IF打开中断
ret = 0;
...
}
回答问题:
用户态进程从被ucore选择到执行第一条指令的过程如下:
- 内核线程initproc在创建完成用户态进程userproc后,调用do_wait函数,do_wait函数在确认存在RUNNABLE的子进程后,调用schedule函数。
- schedule函数通过调用proc_run来运行新线程,proc_run做了三件事情:
- 设置userproc的栈指针esp为userproc->kstack + 2 * 4096,即指向userproc申请到的2页栈空间的栈顶
- 加载userproc的页目录表。用户态的页目录表跟内核态的页目录表不同,因此要重新加载页目录表
- 切换进程上下文,然后跳转到userproc->context.eip指向的函数,即forkret
- forkret函数直接调用forkrets函数,forkrets先把栈指针指向userproc->tf的地址,然后跳到__trapret
- __trapret先将userproc->tf的内容pop给相应寄存器,然后通过iret指令,跳转到userproc->tf.tf_eip指向的函数,即kernel_thread_entry
- kernel_thread_entry先将edx保存的输入参数(NULL)压栈,然后通过call指令,跳转到ebx指向的函数,即user_main
- user_main先打印userproc的pid和name信息,然后调用kernel_execve
- kernel_execve执行exec系统调用,CPU检测到系统调用后,会保存eflags/ss/eip等现场信息,然后根据中断号查找中断向量表,进入中断处理例程。这里要经过一系列的函数跳转,才真正进入到exec的系统处理函数do_execve中:vector128 -> __alltraps -> trap -> trap_dispatch -> syscall -> sys_exec -> do_execve
- do_execve首先检查用户态虚拟内存空间是否合法,如果合法且目前只有当前进程占用,则释放虚拟内存空间,包括取消虚拟内存到物理内存的映射,释放vma,mm及页目录表占用的物理页等。
- 调用load_icode函数来加载应用程序
- 为用户进程创建新的mm结构
- 创建页目录表
- 校验ELF文件的魔鬼数字是否正确
- 创建虚拟内存空间,即往mm结构体添加vma结构
- 分配内存,并拷贝ELF文件的各个program section到新申请的内存上
- 为BSS section分配内存,并初始化为全0
- 分配用户栈内存空间
- 设置当前用户进程的mm结构、页目录表的地址及加载页目录表地址到cr3寄存器
- 设置当前用户进程的tf结构
- load_icode返回到do_exevce,do_execve设置完当前用户进程的名字为“exit”后也返回了。这样一直原路返回到__alltraps函数时,接下来进入__trapret函数
- __trapret函数先将栈上保存的tf的内容pop给相应的寄存器,然后跳转到userproc->tf.tf_eip指向的函数,也就是应用程序的入口(exit.c文件中的main函数)。注意,此处的设计十分巧妙:__alltraps函数先将各寄存器的值保存到userproc->tf中,接着将userproc->tf的地址压入栈后,然后调用trap函数;trap返回后再将current->tf的地址出栈,最后恢复current->tf的内容到各寄存器。这样看来中断处理前后各寄存器的值应该保存不变。但事实上,load_icode函数清空了原来的current->tf的内容,并重新设置为应用进程的相关状态。这样,当__trapret执行iret指令时,实际上跳转到应用程序的入口去了,而且特权级也由内核态跳转到用户态。接下来就开始执行用户程序(exit.c文件的main函数)。
练习2: 父进程复制自己的内存空间给子进程(需要编码)
创建子进程的函数do_fork在执行中将拷贝当前进程(即父进程)的用户内存地址空间中的合法内容到新进程中(子进程),完成内存资源的复制。具体是通过copy_range函数(位于kern/mm/pmm.c中)实现的,请补充copy_range的实现,确保能够正确执行。
请在实验报告中简要说明如何设计实现”Copy on Write 机制“,给出概要设计,鼓励给出详细设计。
Copy-on-write(简称COW)的基本概念是指如果有多个使用者对一个资源A(比如内存块)进行读操作,则每个使用者只需获得一个指向同一个资源A的指针,就可以该资源了。若某使用者需要对这个资源A进行写操作,系统会对该资源进行拷贝操作,从而使得该“写操作”使用者获得一个该资源A的“私有”拷贝—资源B,可对资源B进行写操作。该“写操作”使用者对资源B的改变对于其他的使用者而言是不可见的,因为其他使用者看到的还是资源A。
函数调用过程:
do_fork()---->copy_mm()---->dup_mmap()---->copy_range()
我们回顾一下 do_fork 的执行过程,它完成的工作主要如下:
- 1、分配并初始化进程控制块( alloc_proc 函数);
- 2、分配并初始化内核栈,为内核进程(线程)建立栈空间( setup_stack 函数);
- 3、根据 clone_flag 标志复制或共享进程内存管理结构( copy_mm 函数);
- 4、设置进程在内核(将来也包括用户态)正常运行和调度所需的中断帧和执行上下文 ( copy_thread 函数);
- 5、为进程分配一个 PID( get_pid() 函数);
- 6、把设置好的进程控制块放入 hash_list 和 proc_list 两个全局进程链表中;
- 7、自此,进程已经准备好执行了,把进程状态设置为“就绪”态;
- 8、设置返回码为子进程的 PID 号。
查看do_fork函数:
int
do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) {
int ret = -E_NO_FREE_PROC; //尝试为进程分配内存
struct proc_struct *proc; //定义新进程
if (nr_process >= MAX_PROCESS) {
//分配进程数大于4096,返回
goto fork_out; //返回
}
ret = -E_NO_MEM; //因内存不足而分配失败
if ((proc = alloc_proc()) == NULL) {
//分配内存失败
goto fork_out; //返回
}
proc->parent = current; //设置父进程名字
if (setup_kstack(proc) != 0) {
//分配内核栈
goto bad_fork_cleanup_proc; //返回
}
if (copy_mm(clone_flags, proc) != 0) {
//复制父进程内存信息
goto bad_fork_cleanup_kstack; //返回
}
copy_thread(proc, stack, tf); //复制中断帧和上下文信息
bool intr_flag;
local_intr_save(intr_flag); //屏蔽中断,intr_flag置为1
{
proc->pid = get_pid(); //获取当前进程PID
hash_proc(proc); //建立hash映射
list_add(&proc_list,&(proc->list_link));//加入进程链表
nr_process ++; //进程数加一
}
local_intr_restore(intr_flag); //恢复中断
wakeup_proc(proc); //唤醒新进程
ret = proc->pid; //返回当前进程的PID
fork_out: //已分配进程数大于4096
return ret;
bad_fork_cleanup_kstack: //分配内核栈失败
put_kstack(proc);
bad_fork_cleanup_proc:
kfree(proc);
goto fork_out;
}
do_fork函数调用的copy_mm函数,创建一个进程,并放入CPU中调度,而本次我们主要关注的是父子进程之间如何拷贝内存。
查看copy_mm函数:
static int
copy_mm(uint32_t clone_flags, struct proc_struct *proc) {
struct mm_struct *mm, *oldmm = current->mm;
/* current is a kernel thread */
if (oldmm == NULL) {
//当前进程地址空间为NULL
return 0;
}
if (clone_flags & CLONE_VM) {
//可以共享地址空间
mm = oldmm; //共享地址空间
goto good_mm;
}
int ret = -E_NO_MEM;
if ((mm = mm_create()) == NULL) {
//创建地址空间未成功
goto bad_mm;
}
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
lock_mm(oldmm); //打开互斥锁,避免多个进程同时访问内存
{
ret = dup_mmap(mm, oldmm); //调用dup_mmap函数
}
unlock_mm(oldmm); //释放互斥锁
if (ret != 0) {
goto bad_dup_cleanup_mmap;
}
good_mm:
mm_count_inc(mm); //共享地址空间的进程数加一
proc->mm = mm; //复制空间地址
proc->cr3 = PADDR(mm->pgdir); //复制页表地址
return 0;
bad_dup_cleanup_mmap:
exit_mmap(mm);
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
return ret;
}
调用copy_mm进行内存空间的复制,在该函数中,进一步调用了dup_mmap函数。
查看dup_mmap函数:
int
dup_mmap(struct mm_struct *to, struct mm_struct *from) {
assert(to != NULL && from != NULL); //必须非空
//mmap_list为虚拟地址空间的首地址
list_entry_t *list = &(from->mmap_list), *le = list;
while ((le = list_prev(le)) != list) {
//遍历所有段
struct vma_struct *vma, *nvma;
vma = le2vma(le, list_link); //获取某一段
nvma = vma_create(vma->vm_start, vma->vm_end, vma->vm_flags);
if (nvma == NULL) {
return -E_NO_MEM;
}
insert_vma_struct(to, nvma); //向新进程插入新创建的段
bool share = 0;
//调用copy_range函数
if (copy_range(to->pgdir, from->pgdir, vma->vm_start, vma->vm_end, share) != 0) {
return -E_NO_MEM;
}
}
return 0;
}
在这个函数中,遍历了父进程的所有合法虚拟内存空间,并且将这些空间的内容复制到子进程的内存空间中去,具体进行内存复制的函数就是我们在本次练习中需要完善的copy_range。
完善copy_range函数:
//将实际的代码段和数据段搬到新的子进程里面去,再设置好页表的相关内容
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
//确保start和end可以整除PGSIZE
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
//以页为单位进行复制
do {
//得到A&B的pte地址
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL)
{
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
//为B分一个页的空间
struct Page *npage=alloc_page();
assert(page!=NULL);
assert(npage!=NULL);
int ret=0;
//下面四句代码为本练习实现部分
//1.找寻父进程的内核虚拟页地址
void * kva_src = page2kva(page);
//2.找寻子进程的内核虚拟页地址
void * kva_dst = page2kva(npage);
//3.复制父进程内容到子进程
memcpy(kva_dst, kva_src, PGSIZE);
//4.建立物理地址与子进程的页地址起始位置的映射关系
ret = page_insert(to, npage, start, perm);
assert(ret == 0);
}
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
从上述代码可以知道copy_range函数就是调用一个memcpy将父进程的内存直接复制给子进程即可。
具体的实现思路也就是:
- 找到父进程指定的某一物理页对应的内核虚拟地址
- 找到需要拷贝过去的子进程的对应物理页对应的内核虚拟地址
- 将前者的内容拷贝到后者中去
- 为子进程当前分配这一物理页映射上对应的在子进程虚拟地址空间里的一个虚拟页
回答问题:
首先,Copy on Write 是在复制一个对象的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向源对象的位置,并把那块内存的Copy-On-Write位设置为1。通俗来说一下这样做的好处:如果复制的对象只是对内容进行"读"操作,那其实不需要真正复制,这个指向源对象的指针就能完成任务,这样便节省了复制的时间并且节省了内存。但是问题在于,如果复制的对象需要对内容进行写的话,单单一个指针可能满足不了要求,因为这样对内容的修改会影响其他进程的正确执行,所以就需要将这块区域复制一下,当然不需要全部复制,只需要将需要修改的部分区域复制即可,这样做大大节约了内存并提高效率。
因为如果设置原先的内容为只可读,则在对这段内容进行写操作时候便会引发Page Fault,这时候我们便知道这段内容是需要去写的,在Page Fault中进行相应处理即可。也就是说利用Page Fault来实现权限的判断,或者说是真正复制的标志。
基于原理和之前的用户进程创建、复制、运行等机制进行分析,设计思想:
- 设置一个标记位,用来标记某块内存是否共享,实际上dup_mmap函数中有对share的设置,因此首先需要将share设为1,表示可以共享。
- 在pmm.c中为copy_range添加对共享页的处理,如果share为1,那么将子进程的页面映射到父进程的页面即可。由于两个进程共享一个页面之后,无论任何一个进程修改页面,都会影响另外一个页面,所以需要子进程和父进程对于这个共享页面都保持只读。
- 当程序尝试修改只读的内存页面的时候,将触发Page Fault中断,这时候我们可以检测出是超出权限访问导致的中断,说明进程访问了共享的页面且要进行修改,因此内核此时需要重新为进程分配页面、拷贝页面内容、建立映射关系
练习3: 阅读分析源代码,理解进程执行 fork/exec/wait/exit 的实现,以及系统调用的实现(不需要编码)
请在实验报告中简要说明你对 fork/exec/wait/exit函数的分析。并回答如下问题:
- 请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
- 请给出ucore中一个用户态进程的执行状态生命周期图(包执行状态,执行状态之间的变换关系,以及产生变换的事件或函数调用)。(字符方式画即可)
执行:make grade。如果所显示的应用程序检测都输出ok,则基本正确。(使用的是qemu-1.0.1)
fork函数:
调用过程:
fork->SYS_fork->do_fork+wakeup_proc
- 进程调用
fork系统调用,进入正常的中断处理机制,最终交由syscall函数进行处理 - 在
syscall函数中,根据系统调用,交由sys_fork函数处理 - 该函数进一步调用了
do_fork函数。
练习二已经介绍过do_fork函数的的主要工作。这里就不在赘述,注意这里的wakeup_proc函数主要是将进程的状态设置为等待。
exec函数:
调用过程:
SYS_exec->do_execve
该函数的主要实现部分在do_execve。
do_execve的代码如下:
int
do_execve(const char *name, size_t len, unsigned char *binary, size_t size) {
struct mm_struct *mm = current->mm;
if (!user_mem_check(mm, (uintptr_t)name, len, 0)) {
return -E_INVAL;
}
if (len > PROC_NAME_LEN) {
len = PROC_NAME_LEN;
}
char local_name[PROC_NAME_LEN + 1];
memset(local_name, 0, sizeof(local_name));
memcpy(local_name, name, len);
//为加载新的执行码做好用户态内存空间清空准备
if (mm != NULL) {
lcr3(boot_cr3); //设置页表为内核空间页表
if (mm_count_dec(mm) == 0) {
//如果没有进程再需要此进程所占用的内存空间
exit_mmap(mm);//释放进程所占用户空间内存和进程页表本身所占空间
put_pgdir(mm);
mm_destroy(mm);
}
current->mm = NULL; //把当前进程的mm内存管理指针为空
}
int ret;
/*加载应用程序执行码到当前进程的新创建的用户态虚拟空间中。这里涉及到读ELF格式 的文件,申请内存空间,建立用户态虚存空间,加载应用程序执行码等。load_icode函数完成了整个复杂的工作 */
if ((ret = load_icode(binary, size)) != 0) {
goto execve_exit;
}
set_proc_name(current, local_name);
return 0;
execve_exit:
do_exit(ret);
panic("already exit: %e.\n", ret);
}
主要完成的工作如下:
- 首先为加载新的执行码做好用户态内存空间清空准备。如果mm不为NULL,则设置页表为内核空间页表,且进一步判断mm的引用计数减1后是否为0,如果为0,则表明没有进程再需要此进程所占用的内存空间,为此将根据mm中的记录,释放进程所占用户空间内存和进程页表本身所占空间。最后把当前进程的mm内存管理指针为空。
- 接下来是加载应用程序执行码到当前进程的新创建的用户态虚拟空间中。之后就是调用load_icode从而使之准备好执行。
wait函数:
调用过程:
SYS_wait->do_wait
主要的实现部分同样也在do_wait函数,接下来让我们看到do_wait函数:
int
do_wait(int pid, int *code_store) {
struct mm_struct *mm = current->mm;
if (code_store != NULL) {
if (!user_mem_check(mm, (uintptr_t)code_store, sizeof(int), 1)) {
return -E_INVAL;
}
}
struct proc_struct *proc;
bool intr_flag, haskid;
repeat:
haskid = 0;
//如果pid!=0,则找到进程id为pid的处于退出状态的子进程
if (pid != 0) {
proc = find_proc(pid);
if (proc != NULL && proc->parent == current) {
haskid = 1;
if (proc->state == PROC_ZOMBIE) {
goto found; //找到进程
}
}
}
else {
//如果pid==0,则随意找一个处于退出状态的子进程
proc = current->cptr;
for (; proc != NULL; proc = proc->optr) {
haskid = 1;
if (proc->state == PROC_ZOMBIE) {
goto found;
}
}
}
if (haskid) {
//如果没找到,则父进程重新进入睡眠,并重复寻找的过程
current->state = PROC_SLEEPING;
current->wait_state = WT_CHILD;
schedule();
if (current->flags & PF_EXITING) {
do_exit(-E_KILLED);
}
goto repeat;
}
return -E_BAD_PROC;
//释放子进程的所有资源
found:
if (proc == idleproc || proc == initproc) {
panic("wait idleproc or initproc.\n");
}
if (code_store != NULL) {
*code_store = proc->exit_code;
}
local_intr_save(intr_flag);
{
unhash_proc(proc);//将子进程从hash_list中删除
remove_links(proc);//将子进程从proc_list中删除
}
local_intr_restore(intr_flag);
put_kstack(proc); //释放子进程的内核堆栈
kfree(proc); //释放子进程的进程控制块
return 0;
}
主要过程如下:
首先检查用于保存返回码的code_store指针地址位于合法的范围内
根据PID找到需要等待的子进程PCB,循环询问正在等待的子进程的状态,直到有子进程状态变为ZOMBIE
如果没有需要等待的子进程,那么返回E_BAD_PROC
如果子进程正在可执行状态中,那么将当前进程休眠,在被唤醒后再次尝试
如果子进程正在可执行状态中,那么将当前进程休眠,在被唤醒后再次尝试
exit函数:
调用过程:
SYS_exit->exit
do_exit函数:
int
do_exit(int error_code) {
if (current == idleproc) {
panic("idleproc exit.\n");
}
if (current == initproc) {
panic("initproc exit.\n");
}
struct mm_struct *mm = current->mm;
if (mm != NULL) {
//如果该进程是用户进程
lcr3(boot_cr3); //切换到内核态的页表
if (mm_count_dec(mm) == 0){
exit_mmap(mm);
/*如果没有其他进程共享这个内存释放current->mm->vma链表中每个vma描述的进程合法空间中实际分配的内存,然后把对应的页表项内容清空,最后还把页表所占用的空间释放并把对应的页目录表项清空*/
put_pgdir(mm); //释放页目录占用的内存
mm_destroy(mm); //释放mm占用的内存
}
current->mm = NULL; //虚拟内存空间回收完毕
}
current->state = PROC_ZOMBIE; //僵死状态
current->exit_code = error_code;//等待父进程做最后的回收
bool intr_flag;
struct proc_struct *proc;
local_intr_save(intr_flag);
{
proc = current->parent;
if (proc->wait_state == WT_CHILD) {
wakeup_proc(proc); //如果父进程在等待子进程,则唤醒
}
while (current->cptr != NULL) {
/*如果当前进程还有子进程,则需要把这些子进程的父进程指针设置为内核线程initproc,且各个子进程指针需要插入到initproc的子进程链表中。如果某个子进程的执行状态是PROC_ZOMBIE,则需要唤醒initproc来完成对此子进程的最后回收工作。*/
proc = current->cptr;
current->cptr = proc->optr;
proc->yptr = NULL;
if ((proc->optr = initproc->cptr) != NULL) {
initproc->cptr->yptr = proc;
}
proc->parent = initproc;
initproc->cptr = proc;
if (proc->state == PROC_ZOMBIE) {
if (initproc->wait_state == WT_CHILD) {
wakeup_proc(initproc);
}
}
}
}
local_intr_restore(intr_flag);
schedule(); //选择新的进程执行
panic("do_exit will not return!! %d.\n", current->pid);
}
主要过程如下:
- 释放进程的虚拟内存空间
- 设置当期进程状态为PROC_ZOMBIE即标记为僵尸进程
- 如果父进程处于等待当期进程退出的状态,则将父进程唤醒
- 如果当前进程有子进程,则将子进程设置为initproc的子进程,并完成子进程中处于僵尸状态的进程的最后的回收工作
- 主动调用调度函数进行调度,选择新的进程去执行
系统调用函数:
系统调用的英文名字是System Call。操作系统为什么需要实现系统调用呢?其实这是实现了用户进程后,自然引申出来需要实现的操作系统功能。用户进程只能在操作系统给它圈定好的“用户环境”中执行,但“用户环境”限制了用户进程能够执行的指令,即用户进程只能执行一般的指令,无法执行特权指令。如果用户进程想执行一些需要特权指令的任务,比如通过网卡发网络包等,只能让操作系统来代劳了。于是就需要一种机制来确保用户进程不能执行特权指令,但能够请操作系统“帮忙”完成需要特权指令的任务,这种机制就是系统调用。
关于系统调用的定义主要在syscall.c中,在这里定义了许多系统调用函数,包括sys_exit、sys_fork、sys_wait、sys_exec等。syscall是内核程序为用户程序提供内核服务的一种方式。
在中断处理例程中,程序会根据中断号,执行syscall函数(注意该syscall函数为内核代码,非用户库中的syscall函数)。内核syscall函数会一一取出六个寄存器的值,并根据系统调用号来执行不同的系统调用。而那些系统调用的实质就是其他内核函数的wrapper。以下为syscall函数实现的代码:
COPYvoid syscall(void) {
struct trapframe *tf = current->tf;
uint32_t arg[5];
int num = tf->tf_regs.reg_eax;
if (num >= 0 && num < NUM_SYSCALLS) {
if (syscalls[num] != NULL) {
arg[0] = tf->tf_regs.reg_edx;
arg[1] = tf->tf_regs.reg_ecx;
arg[2] = tf->tf_regs.reg_ebx;
arg[3] = tf->tf_regs.reg_edi;
arg[4] = tf->tf_regs.reg_esi;
tf->tf_regs.reg_eax = syscalls[num](arg);
return ;
}
}
print_trapframe(tf);
panic("undefined syscall %d, pid = %d, name = %s.\n",
num, current->pid, current->name);
}
等相应的内核函数结束后,程序通过之前保留的trapframe返回用户态。一次系统调用结束。
回答问题:
- 请分析fork/exec/wait/exit在实现中是如何影响进程的执行状态的?
fork不会影响当前进程的执行状态,但是会将子进程的状态标记为RUNNALB,使得可以在后续的调度中运行起来;
exec不会影响当前进程的执行状态,但是会修改当前进程中执行的程序;
wait系统调用取决于是否存在可以释放资源(ZOMBIE)的子进程,如果有的话不会发生状态的改变,如果没有的话会将当前进程置为SLEEPING态,等待执行了exit的子进程将其唤醒;
exit会将当前进程的状态修改为ZOMBIE态,并且会将父进程唤醒(修改为RUNNABLE),然后主动让出CPU使用权;
2.请给出ucore中一个用户态进程的执行状态生命周期图(包执行状态,执行状态之间的变换关系,以及产生变换的事件或函数调用)。(字符方式画即可)
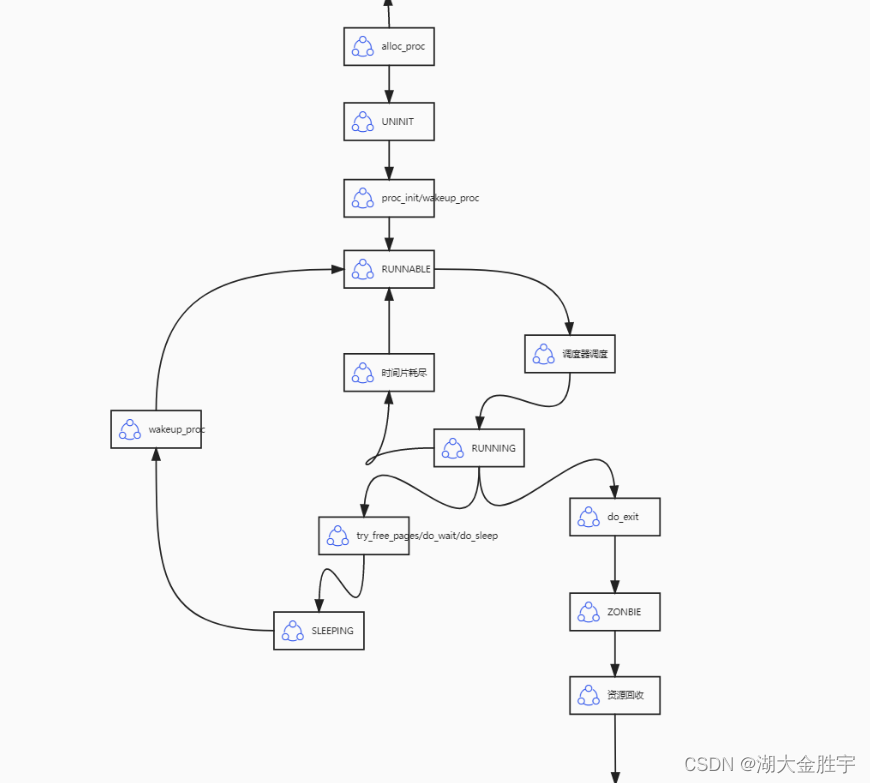
实验结果:
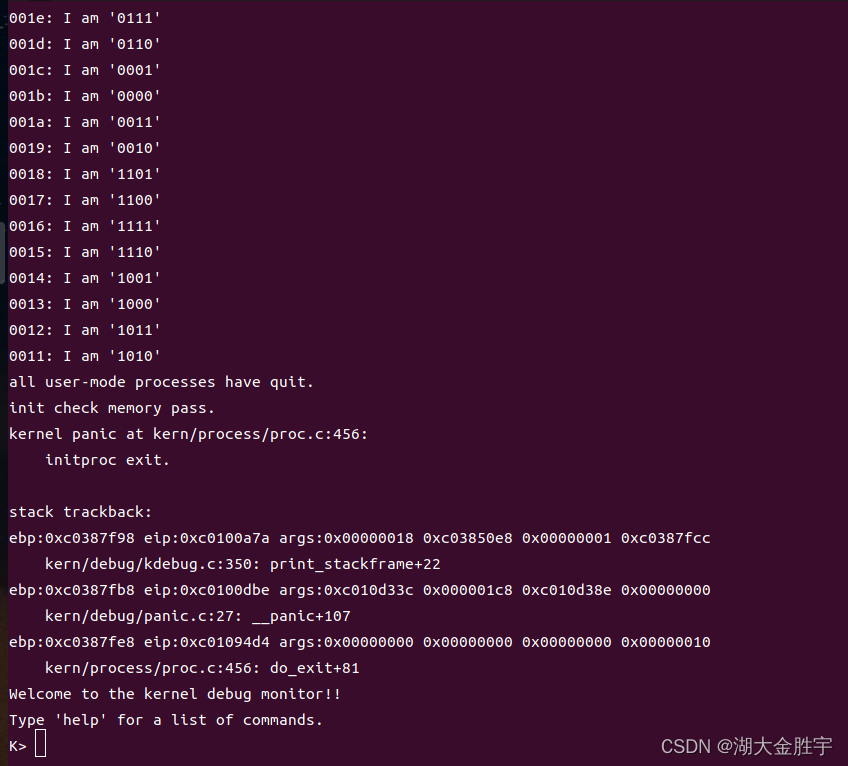
输入指令make qemu查看运行结果:
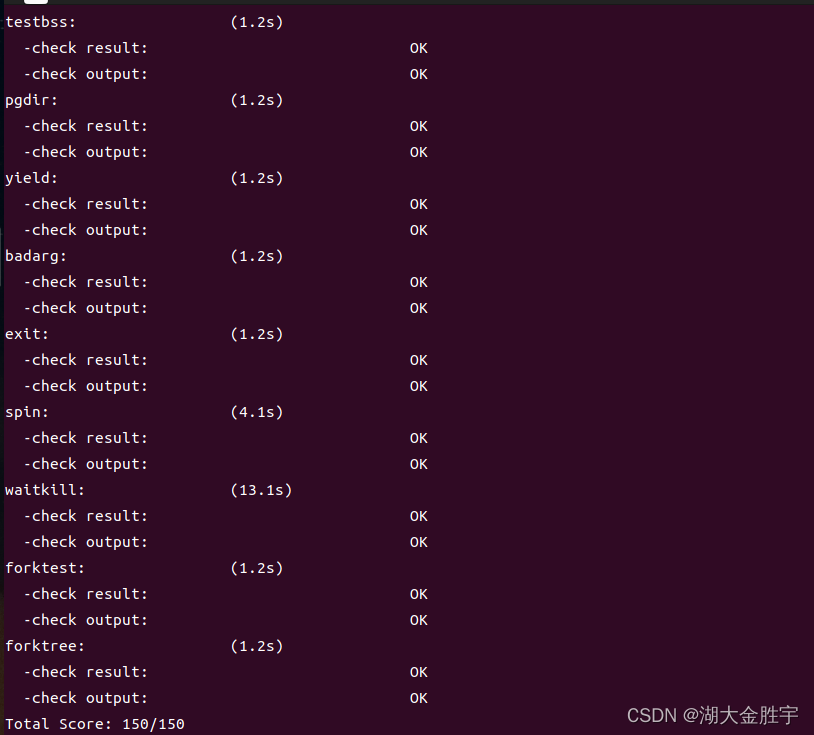
输入make grade查看成绩:
扩展练习 Challenge :实现 Copy on Write (COW)机制
给出实现源码,测试用例和设计报告(包括在cow情况下的各种状态转换(类似有限状态自动机)的说明)。
这个扩展练习涉及到本实验和上一个实验“虚拟内存管理”。在ucore操作系统中,当一个用户父进程创建自己的子进程时,父进程会把其申请的用户空间设置为只读,子进程可共享父进程占用的用户内存空间中的页面(这就是一个共享的资源)。当其中任何一个进程修改此用户内存空间中的某页面时,ucore会通过page fault异常获知该操作,并完成拷贝内存页面,使得两个进程都有各自的内存页面。这样一个进程所做的修改不会被另外一个进程可见了。请在ucore中实现这样的COW机制。
由于COW实现比较复杂,容易引入bug,请参考 https://dirtycow.ninja/ 看看能否在ucore的COW实现中模拟这个错误和解决方案。需要有解释。
这是一个big challenge.
首先,Copy on Write 是在复制一个对象的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向源对象的位置,并把那块内存的Copy-On-Write位设置为1。通俗来说一下这样做的好处:如果复制的对象只是对内容进行"读"操作,那其实不需要真正复制,这个指向源对象的指针就能完成任务,这样便节省了复制的时间并且节省了内存。但是问题在于,如果复制的对象需要对内容进行写的话,单单一个指针可能满足不了要求,因为这样对内容的修改会影响其他进程的正确执行,所以就需要将这块区域复制一下,当然不需要全部复制,只需要将需要修改的部分区域复制即可,这样做大大节约了内存并提高效率。
因为如果设置原先的内容为只可读,则在对这段内容进行写操作时候便会引发Page Fault,这时候我们便知道这段内容是需要去写的,在Page Fault中进行相应处理即可。也就是说利用Page Fault来实现权限的判断,或者说是真正复制的标志。
基于原理和之前的用户进程创建、复制、运行等机制进行分析,设计思想:
设置一个标记位,用来标记某块内存是否共享,实际上dup_mmap函数中有对share的设置,因此首先需要将share设为1,表示可以共享。
在pmm.c中为copy_range添加对共享页的处理,如果share为1,那么将子进程的页面映射到父进程的页面即可。由于两个进程共享一个页面之后,无论任何一个进程修改页面,都会影响另外一个页面,所以需要子进程和父进程对于这个共享页面都保持只读。
当程序尝试修改只读的内存页面的时候,将触发Page Fault中断,这时候我们可以检测出是超出权限访问导致的中断,说明进程访问了共享的页面且要进行修改,因此内核此时需要重新为进程分配页面、拷贝页面内容、建立映射关系
基于该思想,对代码进行修改
首先,将vmm.c中的dup_mmap函数中队share变量的设置进行修改,因为dup_mmap函数中会调用copy_range函数,copy_range函数有一个参数为share,因此修改share为1标志着启动了共享机制。
int dup_mmap(struct mm_struct *to, struct mm_struct *from) {
...
bool share = 1;
if (copy_range(to->pgdir, from->pgdir, vma->vm_start, vma->vm_end, share)!= 0) {
return -E_NO_MEM;
}
...
}
之后,在pmm.c中为copy_range添加对共享页的处理,如果share为1,那么将子进程的页面映射到父进程的页面即可。由于两个进程共享一个页面之后,无论任何一个进程修改页面,都会影响另外一个页面,所以需要子进程和父进程对于这个共享页面都保持只读。
//在这里进行修改,令子进程和父进程共享一个页面,但是保持二者为只读
int
copy_range(pde_t *to, pde_t *from, uintptr_t start, uintptr_t end, bool share) {
assert(start % PGSIZE == 0 && end % PGSIZE == 0);
assert(USER_ACCESS(start, end));
do {
//call get_pte to find process A's pte according to the addr start
pte_t *ptep = get_pte(from, start, 0), *nptep;
if (ptep == NULL) {
start = ROUNDDOWN(start + PTSIZE, PTSIZE);
continue ;
}
if (*ptep & PTE_P) {
if ((nptep = get_pte(to, start, 1)) == NULL) {
return -E_NO_MEM;
}
uint32_t perm = (*ptep & PTE_USER);
//get page from ptep
struct Page *page = pte2page(*ptep);
assert(page!=NULL);
//-----------------修改部分---------------------
int ret=0;
//由于之前设置了可分享,故这里将继续执行if语句
if (share) {
// 如果share=1,完成页面分享
page_insert(from, page, start, perm & (~PTE_W));
ret = page_insert(to, page, start, perm & (~PTE_W));
} else {
//如果不分享的话 就正常分配页面,和之前实现一致
struct Page *npage=alloc_page();
assert(npage!=NULL);
uintptr_t src_kvaddr = page2kva(page);
uintptr_t dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
ret = page_insert(to, npage, start, perm);
}
assert(ret == 0);
}
//-----------------修改部分---------------------
start += PGSIZE;
} while (start != 0 && start < end);
return 0;
}
完成这里的话,已经实现了读的共享,但是并没有对写做处理,因此需要对由于写了只能读的页面导致的页错误进行处理:当程序尝试修改只读的内存页面的时候,将触发Page Fault中断,这时候我们可以检测出是超出权限访问导致的中断,说明进程访问了共享的页面且要进行修改,因此内核此时需要重新为进程分配页面、拷贝页面内容、建立映射关系。
这些步骤主要在于do_pgfault中,在其中我们检测到该错误并做相应处理即可。
int do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr)
{
.....
if (*ptep == 0)
{
//如果物理页不存在的话,分配物理页并建立好相关的映射关系
if (pgdir_alloc_page(mm->pgdir, addr, perm) == NULL)
{
cprintf("pgdir_alloc_page in do_pgfault failed\n");
goto failed;
}
}
//通过error_code & 3==3判断得到是COW导致的错误
else if (error_code & 3 == 3)
{
//因此在这里就需要完成物理页的分配,并实现代码和数据的复制
//实际上,我们将之前的copy_range过程放在了这里执行,只有必须执行时才执行该过程
struct Page *page = pte2page(*ptep);
struct Page *npage = pgdir_alloc_page(mm->pgdir, addr, perm);
uintptr_t src_kvaddr = page2kva(page);
uintptr_t dst_kvaddr = page2kva(npage);
memcpy(dst_kvaddr, src_kvaddr, PGSIZE);
}
else
{
...
}
...
}
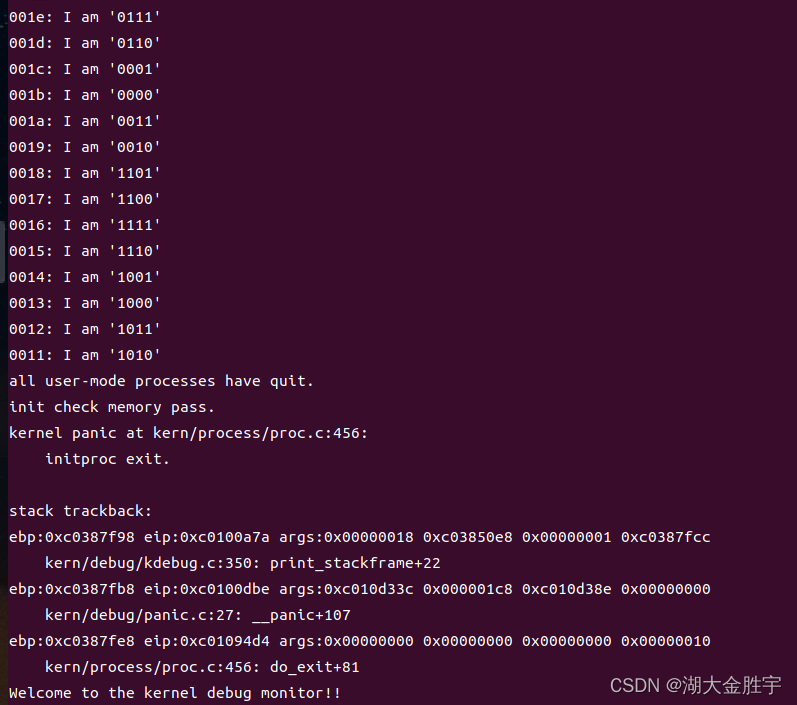
运行make qemu查看运行结果:
参考答案分析
接下来将对提供的参考答案进行分析比较:
- 在完善先前实验内容部分与参考答案基本一致;
- 在完成load_icode的部分与参考答案基本一致,但是存在一个比较细节的区别,在设置trapframe上的eflags寄存器的时候,参考答案仅仅将寄存器上的IF位置成了1,但是根据Intel IA32的开发者手册,知道eflags的第1位(低地址数起)是默认设置成1的,因此正确的写法应当将这一位也置成1;
- 在完成copy_range函数部分与参考答案没有区别;
实验中涉及的知识点列举
本次实验中主要涉及到的知识点有:
- 从内核态切换到用户态的方法;
- ELF可执行文件的格式;
- 用户进程的创建和管理;
- 简单的进程调度;
- 系统调用的实现;
对应的操作系统中的知识点有:
- 创建、管理、切换到用户态进程的具体实现;
- 加载ELF可执行文件的具体实现;
- 对系统调用机制的具体实现;
他们之间的关系为:
- 前者的知识点为后者具体在操作系统中实现具体的功能提供了基础知识;
实验中未涉及的知识点列举
本次实验中为涉及到的知识点有:
- 操作系统的启动;
- 操作系统对内存的管理;
- 进程间的共享、互斥、同步问题;
- 文件系统的实现;
边栏推荐
- Capitalize the title of leetcode simple question
- Global and Chinese market of barrier thin film flexible electronics 2022-2028: Research Report on technology, participants, trends, market size and share
- Brief introduction to libevent
- UCORE lab5 user process management experiment report
- MySQL transactions
- CSAPP家庭作業答案7 8 9章
- 自动化测试你必须要弄懂的问题,精品总结
- Global and Chinese market for antiviral coatings 2022-2028: Research Report on technology, participants, trends, market size and share
- The latest query tracks the express logistics and analyzes the method of delivery timeliness
- Global and Chinese markets for GaN on diamond semiconductor substrates 2022-2028: Research Report on technology, participants, trends, market size and share
猜你喜欢
What are the software testing methods? Show you something different

Heap, stack, queue

C4D quick start tutorial - creating models
CSAPP家庭作業答案7 8 9章
Statistics 8th Edition Jia Junping Chapter 2 after class exercises and answer summary

The minimum sum of the last four digits of the split digit of leetcode simple problem
Leetcode simple question: check whether the numbers in the sentence are increasing
ucore lab2 物理内存管理 实验报告
The salary of testers is polarized. How to become an automated test with a monthly salary of 20K?

STC-B学习板蜂鸣器播放音乐

随机推荐
Opencv recognition of face in image
软件测试需求分析之什么是“试纸测试”
软件测试方法有哪些?带你看点不一样的东西
Threads and thread pools
ucore lab8 文件系统 实验报告
[HCIA continuous update] advanced features of routing
UCORE lab8 file system experiment report
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
線程及線程池
Mysql database (II) DML data operation statements and basic DQL statements
如何成为一个好的软件测试员?绝大多数人都不知道的秘密
Practical cases, hand-in-hand teaching you to build e-commerce user portraits | with code
Future trend and planning of software testing industry
Leetcode simple question: check whether two strings are almost equal
Global and Chinese markets of electronic grade hexafluorobutadiene (C4F6) 2022-2028: Research Report on technology, participants, trends, market size and share
Global and Chinese market of barrier thin film flexible electronics 2022-2028: Research Report on technology, participants, trends, market size and share
If the position is absolute, touchablehighlight cannot be clicked - touchablehighlight not clickable if position absolute
CSAPP homework answers chapter 789
Global and Chinese markets for complex programmable logic devices 2022-2028: Research Report on technology, participants, trends, market size and share
MySQL数据库(四)事务和函数