当前位置:网站首页>PVTV2--Pyramid Vision TransformerV2学习笔记
PVTV2--Pyramid Vision TransformerV2学习笔记
2022-07-07 05:23:00 【麻花地】
PVTV2–Pyramid Vision TransformerV2学习笔记
PVTv2: Improved Baselines with Pyramid Vision Transformer
Abstract
Transformer最近在计算机视觉方面取得了令人鼓舞的进展。在这项工作中,我们通过添加三种设计来改进原始金字塔视觉变换器(PVTv1),提出了新的基线,包括**(1)线性复杂度注意层,(2)重叠面片嵌入和(3)卷积前馈网络**。通过这些修改,PVTv2将PVTv1的计算复杂度降低为线性,并在基本视觉任务(如分类、检测和分割)上实现了显著改进。值得注意的是,拟议的PVTv2实现了与最近的工作(如Swin变压器)相当或更好的性能。我们希望这项工作将促进计算机视觉领域最先进的变压器研究。代码位于https://github.com/whai362/PVT.
1. Introduction
最近关于视觉变换器的研究正在汇聚在主干网络[8、31、33、34、23、36、10、5]上,该主干网络用于下游视觉任务,例如图像分类、对象检测、实例和语义分割。迄今为止,已经取得了一些有希望的结果。例如,视觉变换器(ViT)[8]首先证明了纯变换器可以在图像分类中保持最先进的性能。金字塔视觉变换器(PVTv1)[33]表明,纯变换器主干在密集预测任务(如检测和分割任务)[22,41,?]方面也可以超过CNN。之后,Swin Transformer[23]、CoaT[36]、LeViT[10]和Twins[5]进一步提高了Transformer主干的分类、检测和分割性能。
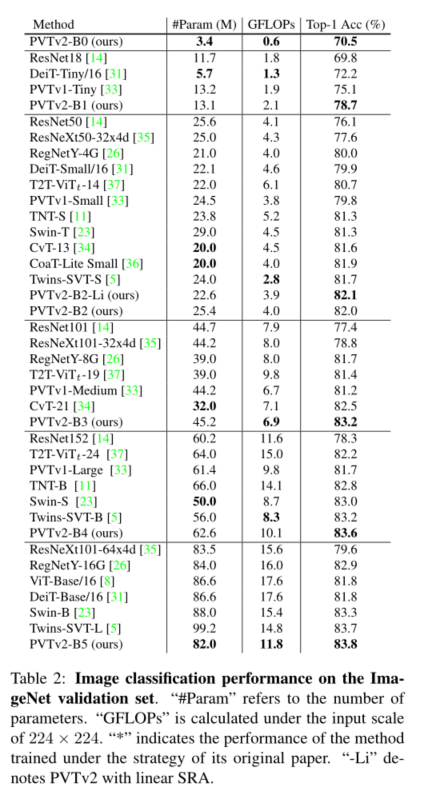
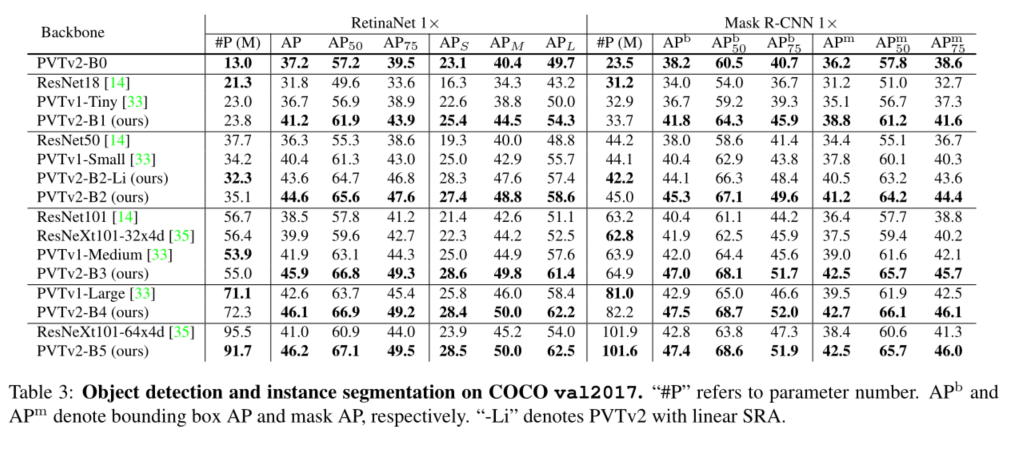
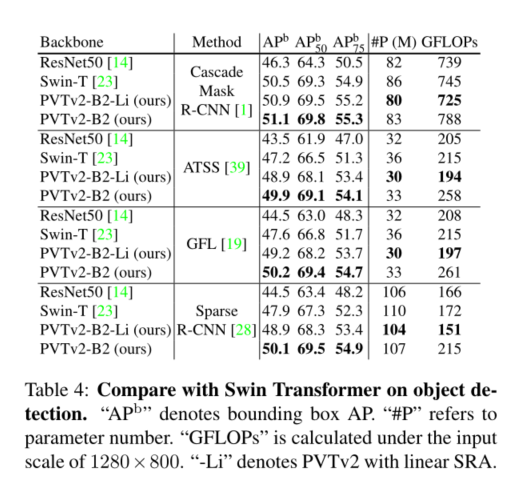
这项工作的目的是在PVTv1框架上建立更强大、更可行的基线。我们报告了三种设计改进,即**(1)线性复杂度注意层、(2)重叠面片嵌入和(3)卷积前馈网络与PVTv1框架正交**,当与PVTv1一起使用时,它们可以带来更好的图像分类、对象检测、实例和语义分割性能。改进后的框架称为PVTv2。具体来说,PVTv2-B51在ImageNet上产生83.8%的top-1误差,优于Swin-B[23]和Twins-SVT-L[5],而我们的模型具有更少的参数和GFLOP。此外,具有PVT-B2的GFL[19]在COCO val2017上记录了50.2 AP,比具有Swin-T的GFL[23]高2.6 AP,比具有ResNet50的GFL[13]高5.7 AP。我们希望这些改进的基线将为未来视觉转换器的研究提供参考。
2. Related Work
我们主要讨论与本工作相关的变压器主干。ViT[8]将每个图像视为具有固定长度的令牌序列(面片),然后将其馈送到多个Transformer层以执行分类。这是首次证明,当训练数据足够时(例如ImageNet-22k[7],JFT300M),纯Transformer也可以在图像分类中存档最先进的性能。DeiT[31]进一步探索了ViT的数据高效训练策略和蒸馏方法。
为了提高图像分类性能,最近的方法对ViT进行了定制更改。T2T ViT[37]将重叠滑动窗口内的令牌逐步连接为一个令牌。TNT[11]利用内部和外部变换块分别生成像素和面片嵌入。CPVT[6]用条件位置编码取代了ViT中固定大小的位置嵌入,使处理任意分辨率的图像变得更容易。CrossViT[2]通过双分支变压器处理不同大小的图像块。LocalViT[20]将深度卷积合并到视觉变换器中,以改善特征的局部连续性。
适应密集预测任务,如对象数据识别,实例和语义分割,还有一些方法[33、23、34、36、10、5]将CNN中的金字塔结构引入变压器主干的设计。PVTv1是第一个金字塔结构变换器,它提出了一个具有四个阶段的层次变换器,表明纯变换器主干可以像CNN主干一样通用,并且在检测和分割任务中表现更好。然后,对[23、34、36、10、5]进行了一些改进,以增强特征的局部连续性,并消除固定大小的位置嵌入。例如,Swin Transformer[23]用相对位置偏差取代了固定大小的位置嵌入,并限制了移动窗口内的自注意力。CvT[34]、CoaT[36]和LeViT[10]将卷积运算引入视觉变换器。Twins[5]将局部注意力和全局注意力机制相结合,以获得更强的特征表示。
3. Methodology
3.1. Limitations in PVTv1
PVTv1[33]有三个主要限制:(1)与ViT[8]类似,当处理高分辨率输入(例如,短边为800像素)时,PVTv1的计算复杂度相对较大。(2) PVTv1[33]将图像视为非重叠面片序列,这在一定程度上失去了图像的局部连续性;(3) PVTv1中的位置编码是固定大小的,对于任意大小的处理图像来说是不灵活的。这些问题限制了PVTv1在视觉任务上的性能。
为了解决这些问题,我们提出了PVTv2,它通过第3.2、3.3和3.4节中列出的三种设计改进了PVTv1。
3.2. Linear Spatial Reduction Attention
首先,为了减少注意力操作引起的高计算成本,我们提出了线性空间注意力 (SRA)层如图1所示。与使用卷积进行空间缩减的SRA[33]不同,线性SRA在注意力操作之前使用平均池将空间维度(即h×w)减少到固定大小(即P×P)。因此,线性SRA像卷积层一样具有线性计算和内存成本。具体来说,给定大小为h×w×c的输入,SRA和线性SRA的复杂度为:
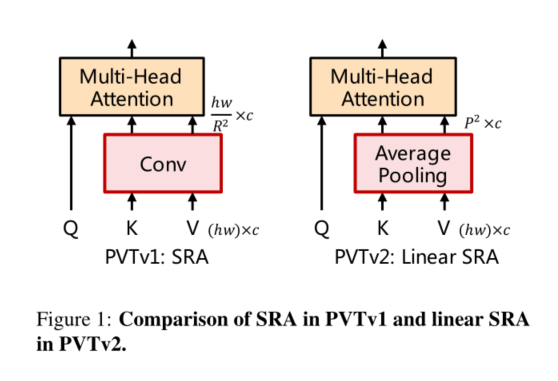
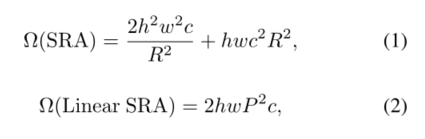
其中R是SRA的空间缩减率[33]。P是线性SRA的池大小,设置为7。
3.3. Overlapping Patch Embedding
其次,为了建模局部连续性信息,我们利用重叠面片嵌入来标记图像。如图2(a)所示,**我们放大了面片窗口,使相邻窗口重叠一半的面积,并用零填充特征图以保持分辨率。在这项工作中,我们使用零填充卷积来实现重叠面片嵌入。**具体来说,给定一个大小为h×w×c的输入,我们将其输入到S步长的卷积中,核大小为2S− 1.S− 1的填充大小和 c ′ c^{'} c′的核数。输出大小为 h / S × w / S × C ′ h/S×w/S×C^{'} h/S×w/S×C′。
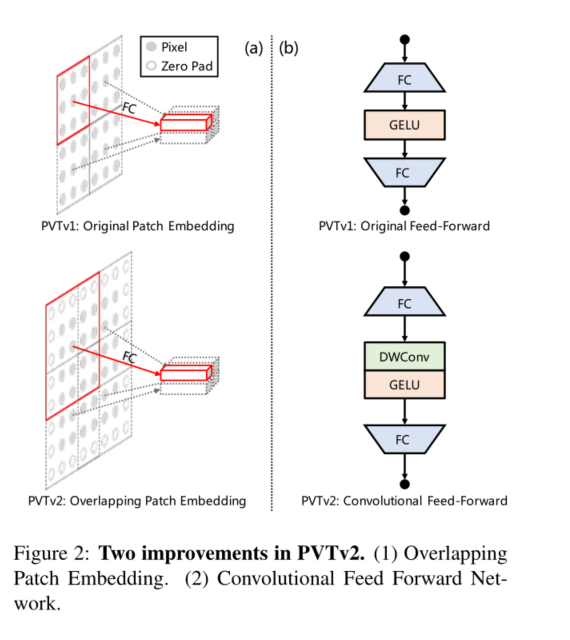
3.4. Convolutional Feed-Forward
**第三,受[17,6,20]的启发,我们删除了固定大小的位置编码[8],并将零填充位置编码引入到PVT中。**如图2(b)所示,我们在前馈网络中的第一个完全连接(FC)层和GELU[15]之间添加了3×3深度卷积[16],填充大小为1。
3.5. Details of PVTv2 Series
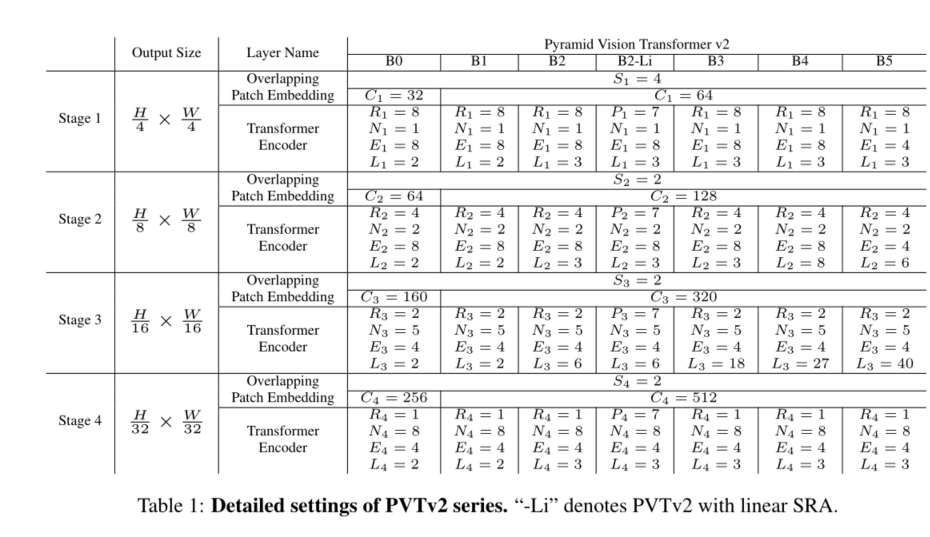
我们通过改变超参数将PVTv2从B0扩展到B5。具体如下:
S i S_i Si:第一阶段重叠面片嵌入的步长
C i C_i Ci:第一阶段输出的通道数
L i L_i Li:第一阶段的编码器层数
R i R_i Ri:第一阶段SRA的减速比
P i P_i Pi:阶段i中线性SRA的自适应平均池大小
N i N_i Ni:第一阶段有效自我注意的头数
E i E_i Ei:第一阶段前馈层[32]的膨胀比;
选项卡。1显示了PVTv2系列的详细信息。我们的设计遵循ResNet[14]的原则。(1) 随着层的加深,通道维数增加,而空间分辨率收缩。(2) 第3阶段分配给大部分计算成本。
3.6. Advantages of PVTv2
结合这些改进,PVTv2可以**(1)获得更多图像和特征地图的局部连续性;(2) 更灵活地处理可变分辨率输入;(3) 享受与CNN相同的线性复杂度。**
4. Experiment

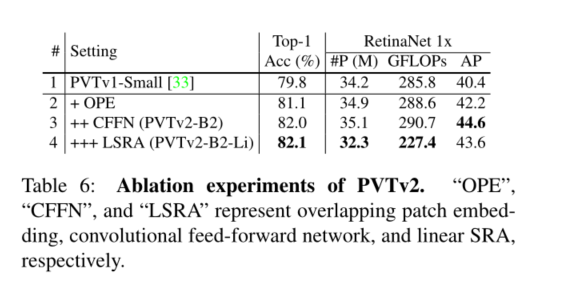
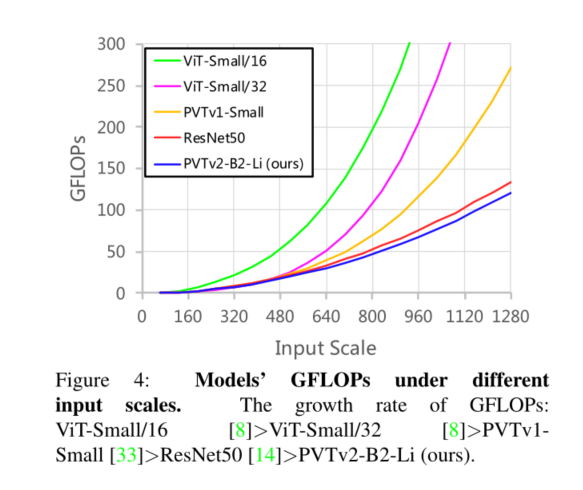
5. Conclusion
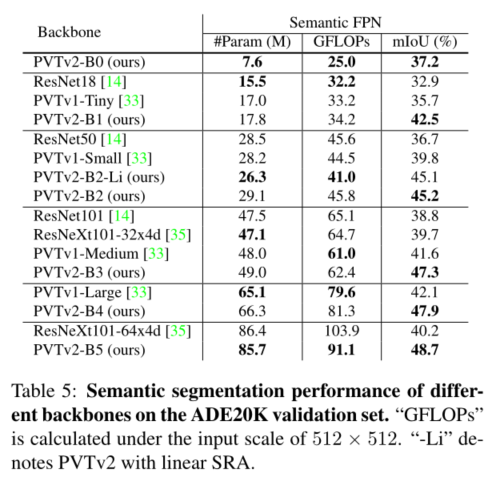
我们研究了金字塔视觉变换器(PVTv1)的局限性,并通过三种设计对其进行了改进,即重叠面片嵌入、卷积前馈网络和线性空间归约注意层。在图像分类、目标检测和语义分割等不同任务上的大量实验表明,在相同数量的参数下,所提出的PVTv2比其前身PVT和其他最先进的基于变换器的主干更强。我们希望这些改进的基线将为未来视觉转换器的研究提供参考。
边栏推荐
- Use of any superclass and generic extension function in kotlin
- 利用 Helm 在各类 Kubernetes 中安装 Rainbond
- 在 Rainbond 中一键安装高可用 Nacos 集群
- Qinglong panel - today's headlines
- 电池、电机技术受到很大关注,反而电控技术却很少被提及?
- Blob 对象介绍
- 王爽 《汇编语言》之寄存器
- CCTV is so warm-hearted that it teaches you to write HR's favorite resume hand in hand
- Fast parsing intranet penetration escorts the document encryption industry
- DNS server configuration
猜你喜欢

The largest 3 same digits in the string of leetcode simple question

Interactive book delivery - signed version of Oracle DBA work notes
Network learning (II) -- Introduction to socket

柯基数据通过Rainbond完成云原生改造,实现离线持续交付客户
![[IELTS speaking] Anna's oral learning records part2](/img/c4/ad7ba2394ee7a52b67b643aa45a7ae.png)
[IELTS speaking] Anna's oral learning records part2
在Rainbond中一键部署高可用 EMQX 集群

opencv学习笔记三——图像平滑/去噪处理

Notes on PHP penetration test topics
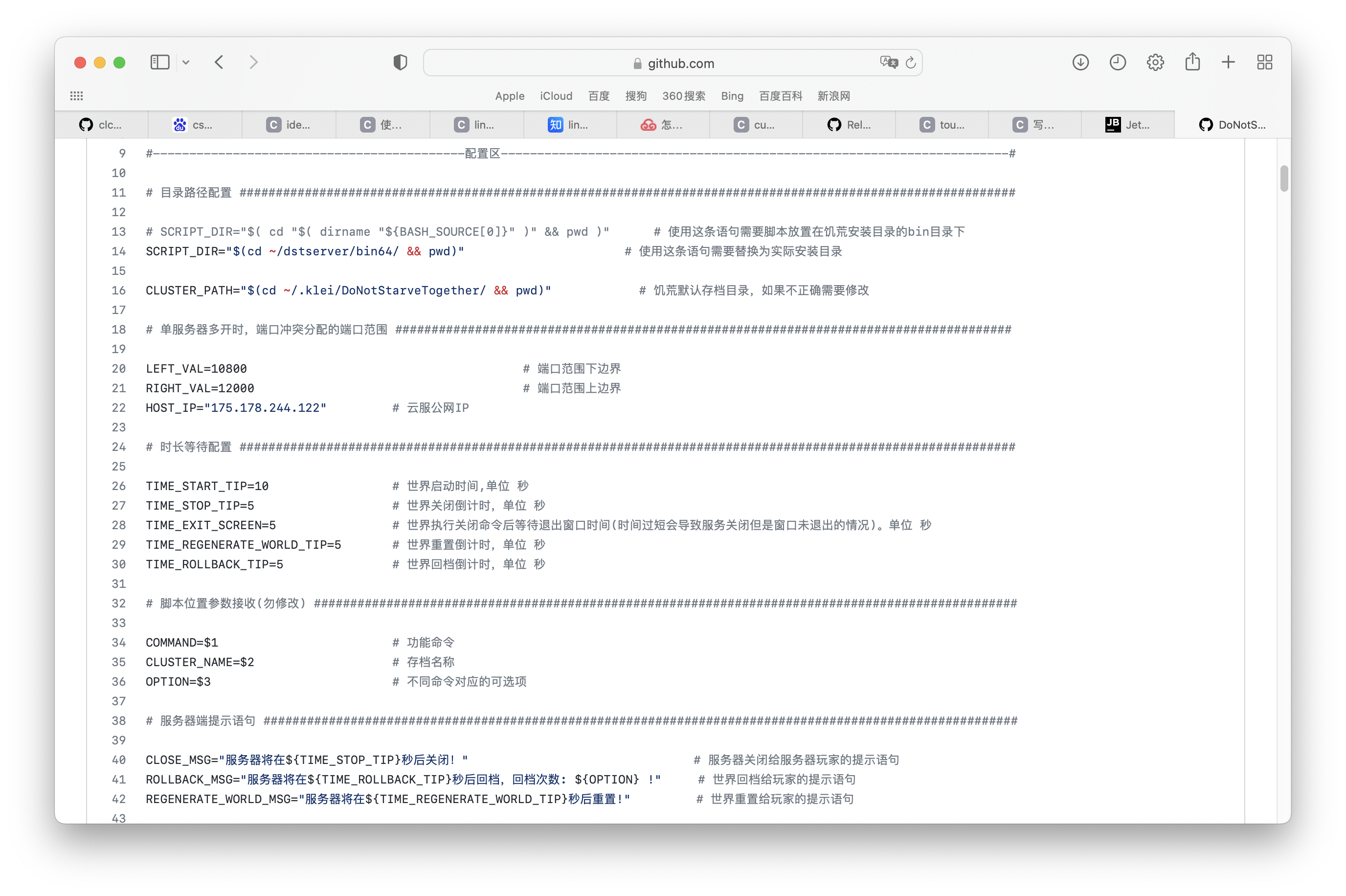
Famine cloud service management script

Real time monitoring of dog walking and rope pulling AI recognition helps smart city
随机推荐
The simple problem of leetcode is to judge whether the number count of a number is equal to the value of the number
使用 Nocalhost 开发 Rainbond 上的微服务应用
Call pytorch API to complete linear regression
Vulnerability recurrence easy_ tornado
Register of assembly language by Wang Shuang
Avatary的LiveDriver试用体验
拓维信息使用 Rainbond 的云原生落地实践
Recursive method constructs binary tree from middle order and post order traversal sequence
Hisense TV starts the developer mode
Introduction à l'objet blob
电池、电机技术受到很大关注,反而电控技术却很少被提及?
Vulnerability recurrence fastjson deserialization
What is the function of paralleling a capacitor on the feedback resistance of the operational amplifier circuit
在 Rainbond 中一键安装高可用 Nacos 集群
CDC (change data capture technology), a powerful tool for real-time database synchronization
It's too true. There's a reason why I haven't been rich
Make LIVELINK's initial pose consistent with that of the mobile capture actor
Leetcode simple question: find the K beauty value of a number
Splunk中single value视图使用将数值替换为文字
Full text query classification