当前位置:网站首页>[nas1] (2021cvpr) attentivenas: improving neural architecture search via attentive sampling (unfinished)
[nas1] (2021cvpr) attentivenas: improving neural architecture search via attentive sampling (unfinished)
2022-07-05 08:21:00 【Three nights is no more than string Ichiro】
【 notes 】: It is recommended to understand the multi-objective optimization problem first PF The concept of , And SPOS Basic flow .
One sentence summary : This paper improves SPOS Uniform sampling strategy in the training process (best up, worst up), Effective identification PF, Further improve the accuracy of the model .
Abstract
The problem background :NAS It has been designed to be precise and efficient SOTA Great achievements have been made in the model . At present , Two stages NAS, Such as BigNAS Decoupled the model training and search process and achieved good results . Two stages NAS You need to sample from the search space during training , It directly affects the accuracy of the model finally searched .
Raise questions : Due to the simplicity of uniform sampling , It has been widely used in two stages NAS During the training , however It is similar to the performance of the model PF irrelevant , It will lose the opportunity to further improve the accuracy of the model .
In this paper, we do : Committed to improving sampling strategies And to put forward AttentiveNAS, Effectively identify PF the front .
experimental result : Search the model family , be called AttentiveNAS models, stay ImageNet Admiral top-1 The precision of is from 77.3% Up to the 80.7%. The only 491MFLOPs Under the premise of , Realization ImageNet On 80.1% The accuracy of the .
1. Introduction
NAS Development Review :NAS For Automation DNN Design provides a useful tool . It optimizes the model architecture and model parameters at the same time , Created a challenging nested optimization problem . Conventional NAS Use evolutionary search or reinforcement learning , But these methods need to train thousands of models in a single experiment , The calculation cost is very expensive . Current NAS Decouple parameter training and architecture optimization into 2 An independent stage .
- In the first stage, the parameters of all candidate networks in the search space are optimized through weight sharing , Make all networks achieve optimal performance at the end of training ;
- The second stage uses a typical search algorithm , For example, evolutionary algorithm searches for the optimal model under various resource constraints .
In this way NAS Normal form search is very efficient and has excellent performance .
Discover scientific problems : Two stages NAS The success of depends strongly on the training of candidate networks in the first stage . In order to achieve the best performance of all candidate networks , They sample from the search space , And pass one-step stochastic gradient descent (SGD) Optimize each sample . Its The key is to figure out in each SGD Which network to sample in step . Existing methods use uniform sampling strategy to sample Networks , Experiments have proved that the uniform sampling strategy makes NAS The training of has nothing to do with the search stage , namely How to improve is not considered in the training stage PF, It cannot further improve network performance .
The work of this paper : Put forward AttentiveNAS Improve uniform sampling , Pay more attention to the possibility of producing better PF The network architecture of . This article specifically answers the following 2 A question :
- Which candidate networks should be sampled during training ?
- How can we effectively sample these candidate networks without introducing too much computational cost ?
For the first question , This article explores 2 There are different sampling strategies . The first strategy BestUp—— The optimal PF Perceptual sampling strategy , Put more training costs on improving the current best PF On ; The second strategy WorstUp, Candidate networks that focus on improving the worst performance tradeoffs , The worst Pareto Model , Be similar to hard example mining. Push the worst Pareto Set can help update the optimized parameters in the weight sharing network , So that all parameters are fully trained .
For the second question , Determine the optimal / The worst PF The network on is not straightforward . Using training loss and accuracy, we propose 2 Methods .
2. Related Work and Background
NAS Formulaic description of :
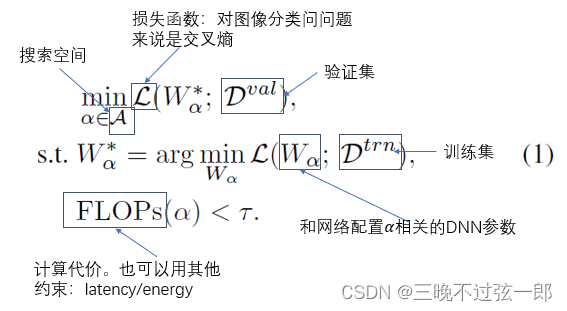
solve NAS, That's the formula (1) Early methods of : Often based on reinforcement learning or evolutionary algorithms , These methods need to train a large number of networks from scratch to get accurate performance estimates , Its calculation is very expensive .
The current method uses Weight sharing : Often train a weight sharing network and adopt a shape network , Through the way of inheritance right, we can directly obtain effective subnet performance estimation . This method alleviates the computational cost of training all networks from scratch and significantly accelerates NAS The process .
Based on weight sharing NAS Solve by continuous difference relaxation : Based on weight sharing NAS Constraints are often solved by continuous difference relaxation and gradient descent (1) type . But these methods are suitable for random seeds / Super parameters such as data division are very sensitive , Different DNNs The performance ranking correlation of also varies greatly in different experiments , It needs many rounds of repeated tests to obtain good performance . And the inherited weight is often suboptimal . therefore , This approach often requires retraining the discovered network architecture from scratch , Additional computational burden is introduced .
2.1 Two-stage NAS
Raise questions : type (1) The search scope is limited to a small subnet , Generate a challenging optimization problem —— Cannot take advantage of parameterization . Besides , type (1) Limited to a single resource constraint . Optimize under various resource constraints DNN It usually requires multiple independent searches .
Two stages NAS Introduce : Will optimize (1) Decompose into 2 Stages :(1) Unconstrained pre training : Jointly optimize all possible candidate networks through weight sharing ;(2) Resource constrained search : Find the best subnet under given resource constraints . Recent work in this direction includes BigNAS, SPOS, FairNAS, OFA, HAT etc. .

3. NAS via Attentive Samping
边栏推荐
- STM32 single chip microcomputer -- debug in keil5 cannot enter the main function
- Communication standard -- communication protocol
- Explication de la procédure stockée pour SQL Server
- Correlation based template matching based on Halcon learning [II] find_ ncc_ model_ defocused_ precision. hdev
- MHA High available Cluster for MySQL
- Measurement fitting based on Halcon learning [II] meaure_ pin. Hdev routine
- 实例010:给人看的时间
- Network port usage
- DokuWiki deployment notes
- 【云原生 | 从零开始学Kubernetes】三、Kubernetes集群管理工具kubectl
猜你喜欢
Take you to understand the working principle of lithium battery protection board

Tailq of linked list
Working principle and type selection of common mode inductor
How to copy formatted notepad++ text?
Array integration initialization (C language)
Step motor generates S-curve upper computer
Soem EtherCAT source code analysis attachment 1 (establishment of communication operation environment)
Negative pressure generation of buck-boost circuit

STM32 single chip microcomputer - external interrupt
Simple design description of MIC circuit of ECM mobile phone
随机推荐
Step motor generates S-curve upper computer
【云原生 | 从零开始学Kubernetes】三、Kubernetes集群管理工具kubectl
After installing the new version of keil5 or upgrading the JLINK firmware, you will always be prompted about the firmware update
C # joint configuration with Halcon
C WinForm [get file path -- traverse folder pictures] - practical exercise 6
My-basic application 1: introduction to my-basic parser
[tutorial 15 of trio basic from introduction to proficiency] trio free serial communication
QEMU STM32 vscode debugging environment configuration
MySQL之MHA高可用集群
Summary -st2.0 Hall angle estimation
Class of color image processing based on Halcon learning_ ndim_ norm. hdev
Count the number of inputs (C language)
Array integration initialization (C language)
Explain task scheduling based on Cortex-M3 in detail (Part 2)
Bootloader implementation of PIC MCU
PMSM dead time compensation
Buildroot system for making raspberry pie cm3
STM32 outputs 1PPS with adjustable phase
Weidongshan Internet of things learning lesson 1
More than 90% of hardware engineers will encounter problems when MOS tubes are burned out!