当前位置:网站首页>Hypothesis testing -- learning notes of Chapter 8 of probability theory and mathematical statistics
Hypothesis testing -- learning notes of Chapter 8 of probability theory and mathematical statistics
2022-07-05 04:23:00 【IOT classmate Huang】
Hypothesis testing ——《 Probability theory and mathematical statistics 》 Chapter VIII study notes
List of articles
Preface
Thanks to typhoon siemba , Let me not go back to the dormitory , Forced to spend the night in the Laboratory , reasoning , Cannot sleep! , Just as the final exam is approaching , Decided to write a study note of Chapter 8 .
Just like the previous series , Teaching materials remain unchanged . Content , Select the first three sections of Chapter 8 , Hypothesis testing , Normal mean , Knowledge points of three parts of normal variance , Why is there nothing else , Because I probably won't take this exam .
Formally , Compared with the previous chapters, many textbook definitions are written , This time I will have more personal understanding , Try to hit the test site directly .
MindMap
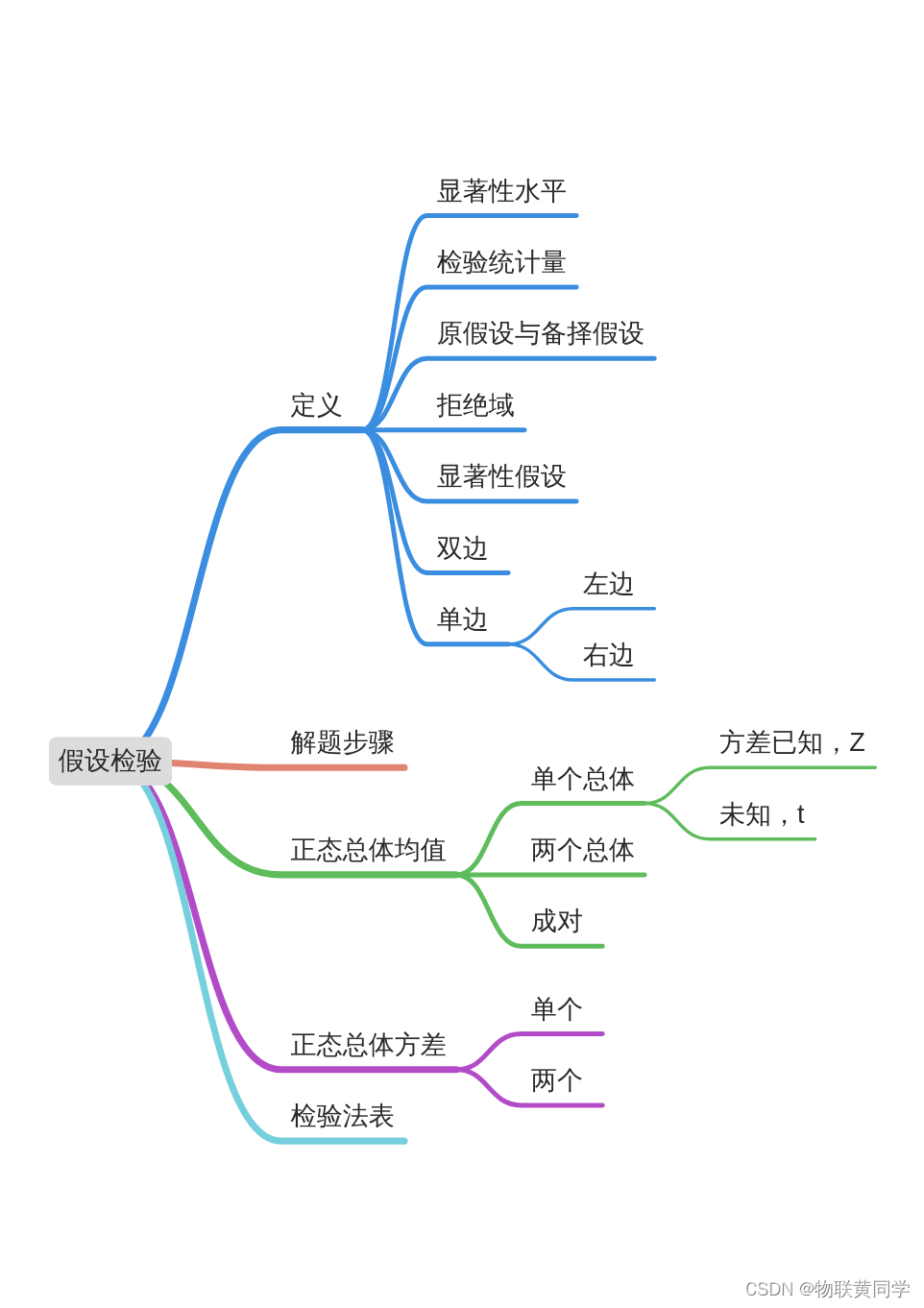
Hypothesis testing
This section actually tells you some definitions of hypothesis testing , And the process and steps of solving the problem of hypothesis testing .
Some definitions
Significance level
The standard we use to measure the inspection , Generally, in the formula α appear .
Test statistic
Z = X ‾ − μ 0 σ / n Z = \frac{\overline{X} - \mu_0}{\sigma/\sqrt n} Z=σ/nX−μ0
The null hypothesis And The alternative hypothesis
We describe the inspection problem as : At the level of significance α Next , Test the hypothesis :
H 0 : μ = μ 0 , H 1 : μ ≠ μ 0 H_0:\mu =\mu_0, \qquad H_1 : \mu \neq \mu_0 H0:μ=μ0,H1:μ=μ0
H0 by The null hypothesis , H1 by The alternative hypothesis .
Reject domain
Is to take a value in a certain area as When testing the value of Statistics , Refuse The null hypothesis , Or accept the alternative hypothesis , This region is the rejection domain , The boundary point of the rejection domain is actually called critical point .
Significance test
Because the test is based on samples , So the test is bound to make mistakes , There are two main mistakes :
- H0 It's true , But refuse .
- H1 It's true , But accept the original hypothesis .
We obviously hope that the probability of making these two kinds of mistakes is small , But in mathematical statistics , If the sample size is limited , While reducing the probability of making a kind of mistake , The probability of the other kind tends to increase . So in mathematical statistics , The first kind of control is adopted , Don't consider The second category . This test is Hypothesis testing .
Bilateral inspection and unilateral inspection
This is actually when we are making assumptions , about H1,μ May be greater than μ0, It may be less than μ0, If it is both possible , That's it Bilateral assumptions , And if it's just one possibility , That's it Unilateral assumptions , According to the direction, it can be divided into Check on the left and Check on the right . For direction , My personal understanding is to see Reject the domain or choose the assumed direction .
Problem solving steps for personal understanding
Through reading and understanding textbook examples , Found the solution process of hypothesis testing problem :
- First, determine the test hypothesis according to the topic .
- Determine the test statistics according to the parameters .
- Then judge the hypothesis according to the hypothesis and test statistics , Then determine the reject domain .
- sampling , In fact, it is to judge whether to accept the original hypothesis according to the observed value of the sample .
All the populations in this article are normal populations , For its two parameters , mean value μ And variance σ^2, There are two hypothesis tests .
Hypothesis test of normal population mean
Single population
Here, according to whether the variance is known , Can be divided into Z test and t test .
The variance is known ,Z test
It's very simple , According to the hypothesis, we need to test whether the sample mean meets the hypothesis , At the level of significance α And other parameters , The test statistic is :
Z = X ‾ − μ 0 σ / n Z ∼ N ( μ , σ 2 ) Z = \frac{\overline{X} - \mu_0}{\sigma/\sqrt n} \\ Z \sim N(\mu, \sigma^2) Z=σ/nX−μ0Z∼N(μ,σ2)
Next, we only need to solve it according to whether it is unilateral hypothesis or bilateral hypothesis .
Take two sides α/2, The absolute value of the test statistic is higher than Corresponding to the significance level The normal function value rejects the original assumption .
The variance is unknown ,t test
This is actually Sample variance is used s To approximate replacement Total variance σ, Of course, we need to use t Distribution .
X ‾ − μ 0 S / n ∼ t ( n − 1 ) \frac{\overline{X} - \mu_0}{S/\sqrt n} \sim t(n-1) S/nX−μ0∼t(n−1)
Two overall ——t test
For two independent normal populations
N ( μ 1 , σ 2 ) , N ( μ 2 , σ 2 ) N(\mu_1, \sigma^2), N(\mu_2, \sigma^2) N(μ1,σ2),N(μ2,σ2)
The variance is the same , The mean is different , So we can eliminate the test hypothesis :
H 0 : μ 1 − μ 2 = δ , H 1 : μ 1 − μ 2 ≠ δ H_0: \mu_1 - \mu_2 = \delta, \quad H_1:\mu_1 - \mu_2 \neq \delta H0:μ1−μ2=δ,H1:μ1−μ2=δ
So give the test statistics :
t = ( X ‾ − Y ‾ ) − δ S w 1 n 1 + 1 n 2 S w 2 = ( n 1 − 1 ) S 1 2 + ( n 2 − 1 ) S 2 2 n 1 n 2 − 2 t= \frac{(\overline{X} - \overline{Y})- \delta}{S_w\sqrt{\frac1{n_1} + \frac 1{n_2}}} \\ S_w^2 = \frac{(n_1 - 1)S_1^2 + (n_2 - 1)S^2_2}{n_1 n_2 - 2} t=Swn11+n21(X−Y)−δSw2=n1n2−2(n1−1)S12+(n2−1)S22
Test of paired data ——t test
In fact, here is to compare the two groups of data to find the difference , Then do the test , We usually subtract the data directly as a new normal population sample , The next step is actually a single overall situation .
Hypothesis test of normal population variance
Single population
In the mean , So here's what we're going to use Z and t test , To put it bluntly, it means using Normal distribution and t Distribution , But in the hypothesis test of variance , In fact, it uses
( n − 1 ) S 2 σ 0 2 ∼ χ 2 ( n − 1 ) \frac{(n-1)S^2}{\sigma_0^2} \sim \chi^2(n - 1) σ02(n−1)S2∼χ2(n−1)
Two overall
What is used is F Distribution
S 1 2 / S 2 2 σ 1 2 / σ 2 2 ∼ F ( n 1 − 1 , n 2 − 1 ) \frac{S_1^2/ S_2^2}{\sigma_1^2/ \sigma_2^2} \sim F(n_1-1, n_2 -1) σ12/σ22S12/S22∼F(n1−1,n2−1)
Test method table of normal population
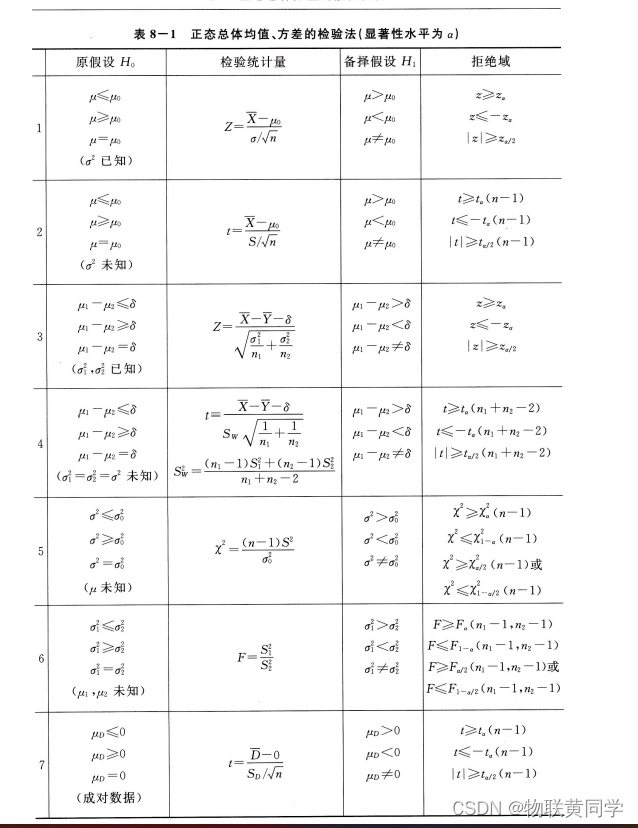
The latter
It's dawn , Go back to bed , This chapter will be better read in combination with the textbook .
边栏推荐
- PR video clip (project packaging)
- Threejs loads the city obj model, loads the character gltf model, and tweetjs realizes the movement of characters according to the planned route
- Common features of ES6
- [phantom engine UE] realize the animation production of mapping tripod deployment
- 直播预告 | 容器服务 ACK 弹性预测最佳实践
- Use threejs to create geometry and add materials, lights, shadows, animations, and axes
- 行为感知系统
- Threejs clicks the scene object to obtain object information, and threejs uses raycaster to pick up object information
- [popular science] basic knowledge of thermal design: heat dissipation analysis of 5g optical devices
- What is the reason why the webrtc protocol video cannot be played on the easycvr platform?
猜你喜欢
可观测|时序数据降采样在Prometheus实践复盘

How to realize real-time audio and video chat function
函數(易錯)
What is the reason why the webrtc protocol video cannot be played on the easycvr platform?
Threejs realizes the drawing of the earth, geographical location annotation, longitude and latitude conversion of world coordinates threejs coordinates
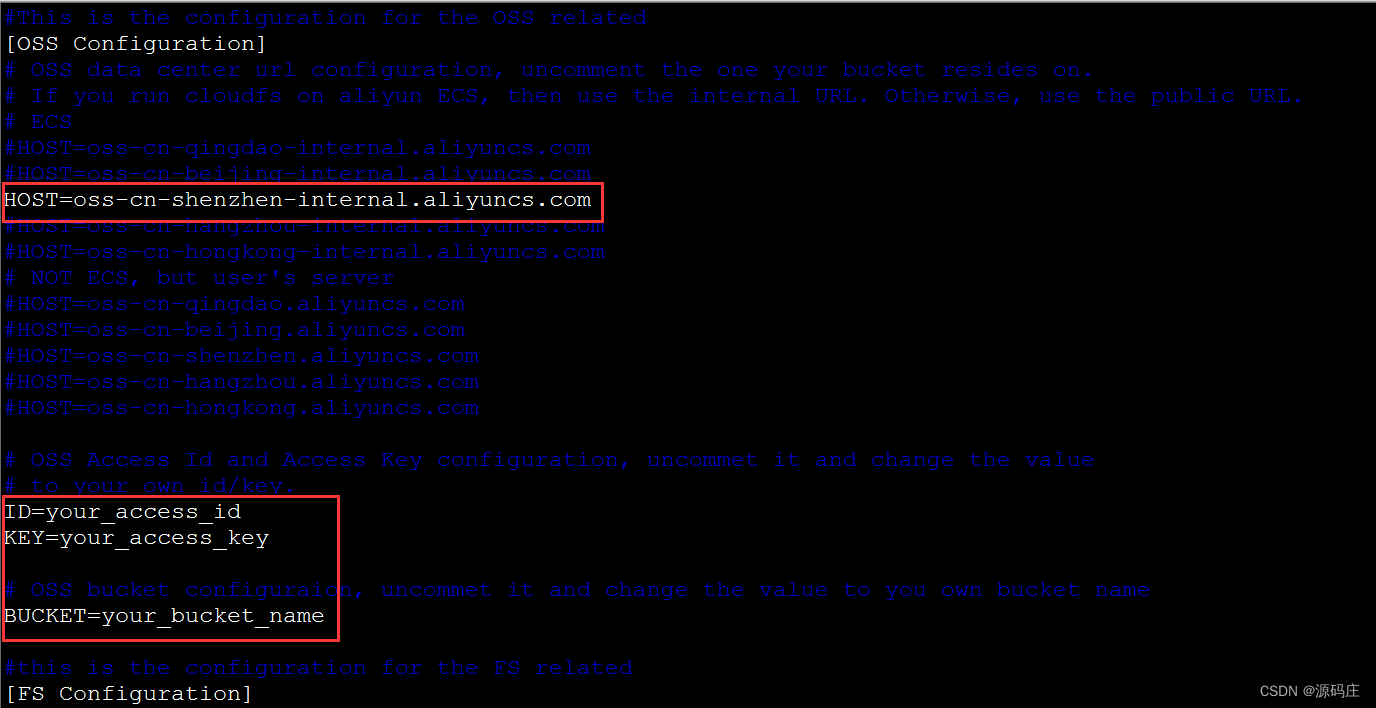
Alibaba cloud ECS uses cloudfs4oss to mount OSS

Threejs rendering obj+mtl model source code, 3D factory model

TPG x AIDU | AI leading talent recruitment plan in progress!
Use threejs to create geometry and add materials, lights, shadows, animations, and axes
小程序中实现文章的关注功能
随机推荐
Machine learning -- neural network
PHP读取ini文件并修改内容写入
Un réveil de l'application B devrait être rapide
American 5g open ran suffered another major setback, and its attempt to counter China's 5g technology has failed
长度为n的入栈顺序的可能出栈顺序
基于TCP的移动端IM即时通讯开发仍然需要心跳保活
Sequelize. JS and hasmany - belongsto vs hasmany in serialize js
Rome chain analysis
如何进行「小步重构」?
Moco is not suitable for target detection? MsrA proposes object level comparative learning target detection pre training method SOCO! Performance SOTA! (NeurIPS 2021)...
Threejs factory model 3DMAX model obj+mtl format, source file download
Rust blockchain development - signature encryption and private key public key
解密函数计算异步任务能力之「任务的状态及生命周期管理」
Kwai, Tiktok, video number, battle content payment
【虛幻引擎UE】實現UE5像素流部署僅需六步操作少走彎路!(4.26和4.27原理類似)
Online text line fixed length fill tool
TPG x AIDU | AI leading talent recruitment plan in progress!
Laravel8 export excel file
Alibaba cloud ECS uses cloudfs4oss to mount OSS
A應用喚醒B應該快速方法