当前位置:网站首页>Submit several problem records of spark application (sparklauncher with cluster deploy mode)
Submit several problem records of spark application (sparklauncher with cluster deploy mode)
2022-07-06 16:36:00 【Ruo Miaoshen】
List of articles
- ( One ) Cluster deployment mode submission is applied to Spark Independent clusters
- ( Two ) Cluster deployment mode submission is applied to yarn colony
It's all used SparkLauncher:
( One ) Cluster deployment mode submission is applied to Spark Independent clusters
colony (Cluster) Application submitted by deployment mode ( That is to say Driver) It runs in a cluster Worker Upper .
We cannot see the progress of implementation , The final result can only be stored in HDFS On ( Otherwise, you can't see anything ).
1.1 Windows Environment variables under
Reference link :JDK-8187776.
In short, it is Windows Keep a lot of DOS Strange environment variables left , I can't see , But with Java Submit Spark In cluster mode , These strange environment variables will also be copied , such =::,=C: The environment variable of the name causes Spark Report errors :
ERROR ClientEndpoint: Exception from cluster was: java.lang.IllegalArgumentException: Invalid environment variable name: "=::"
java.lang.IllegalArgumentException: Invalid environment variable name: "=::"
at java.lang.ProcessEnvironment.validateVariable(ProcessEnvironment.java:114)
at java.lang.ProcessEnvironment.access$200(ProcessEnvironment.java:61)
at java.lang.ProcessEnvironment$Variable.valueOf(ProcessEnvironment.java:170)
perhaps :
Invalid environment variable name: "=C:"
Uh , It's not Java Of bug Well ……
In short, I don't know how to solve ,Windows I have to use Client Mode submission , That is, application (driver) Run locally .
1.1.1 to update ( Unresolved )
Try to get rid of these environment variables with wrong names in the program first , Find out =:: Removed .
however =D: I can't see at all , So I can't go .
Invisible environment variables , Will be sent to the cluster , And then there's no way to recognize . It's hard to understand ……
Remove the environment variable code as follows :
protected static void removeBadEnv() throws Exception {
try {
Class<?> processEnvironmentClass = Class.forName("java.lang.ProcessEnvironment");
Field theEnvironmentField = processEnvironmentClass.getDeclaredField("theEnvironment");
theEnvironmentField.setAccessible(true);
Map<String, String> env = (Map<String, String>) theEnvironmentField.get(null);
env.remove("=::");
env.remove("=C:");
env.remove("=c:");
env.remove("=D:");
env.remove("=d:");
Field theCaseInsensitiveEnvironmentField = processEnvironmentClass.getDeclaredField("theCaseInsensitiveEnvironment");
theCaseInsensitiveEnvironmentField.setAccessible(true);
Map<String, String> cienv = (Map<String, String>) theCaseInsensitiveEnvironmentField.get(null);
cienv.remove("=::");
cienv.remove("=C:");
cienv.remove("=c:");
cienv.remove("=D:");
cienv.remove("=d:");
} catch (NoSuchFieldException e) {
Class[] classes = Collections.class.getDeclaredClasses();
Map<String, String> env = System.getenv();
for(Class cl : classes) {
if("java.util.Collections$UnmodifiableMap".equals(cl.getName())) {
Field field = cl.getDeclaredField("m");
field.setAccessible(true);
Object obj = field.get(env);
Map<String, String> map = (Map<String, String>) obj;
map.remove("=::");
map.remove("=C:");
map.remove("=D:");
}
}
}
}
1.2 Linux Under the state of :LOST
So we use Linux host , Submit Cluster Pattern , It's always OK .
It can , The command line returns soon after submission , Only in clusters WEB page , find driver Where to view progress :
The command line submission is as follows :
$ac@vm00 ~> spark-submit --class com.ac.GZBvH --master spark://vm00:7077 --deploy-mode cluster --driver-memory 1g --executor-memory 1g hdfs://vm00:9000/bin/MySparkApp_XXYYZZ.jar hdfs://vm00:9000 /TestData/GuiZhou/GPRS/1/ hdfs://vm00:9000/output/gzGPRS1/ 100 100 1
$ac@vm00 ~>
$ac@vm00 ~>
But with SparkLauncher Program submission Cluster The pattern program also returned soon .
The status of the report is LOST...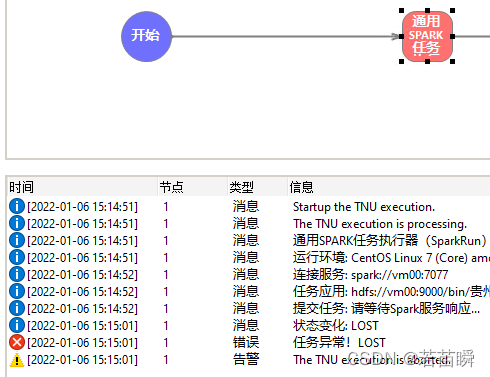
Then go to the cluster WEB Page view , Found in fact driver It works .
I don't know how to do this part , It doesn't seem easy to deal with in principle .
Take a note of it .
1.2.1 to update ( Unresolved )
notice : Official information .
One 3.1.0 New parameters for spark.standalone.submit.waitAppCompletion, Default false.
In standalone cluster mode, controls whether the client waits to exit until the application completes. If set to true, the client process will stay alive polling the driver’s status. Otherwise, the client process will exit after submission.
According to this setting , You can really wait until the application runs , Will not quit immediately .
The problem is that there is no application in Spark State changes running in independent clusters , You can't get basic APPID.
Plus, the final state is still LOST, Completely unable to handle .
yarn Clusters don't have this problem .
1.3 Python application
The official has already said ,Python The app cannot be submitted to Spark Independent clusters :
org.apache.spark.SparkException: Cluster deploy mode is currently not supported for python applications on standalone clusters.
1.4 give up
️ I can't use it at present SparkLauncher Program , To submit Cluster Mode tasks to independent clusters .
ha-ha ……
.
( Two ) Cluster deployment mode submission is applied to yarn colony
2.1 Windows Make a mistake 1,winutils edition
…java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX…
because winutils The version of is too low , I'm here Hadoop yes 3.3.1, however winutils.exe It seems to be 3.0.0.
The warehouse mentioned on the official website has no updated version , Reference resources This roast article The address of .
So I found Another warehouse Downloaded 3.3.1 Version of winutils.exe, No more errors .
2.2 Windows Make a mistake 2,HADOOP_CONF_DIR
org.apache.spark.SparkException: When running with master ‘yarn’ either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
This is easier to understand , Unclear hadoop perhaps yarn The location of .
hold HADOOP_CONF_DIR In the right place , Add to the system environment variable .
2.3 Windows Make a mistake 3, Library and configuration file not found
File file …/spark-***/spark_libs***.zip does not exist
File file …/.sparkStaging/application_TimeStamp/spark_conf.zip does not exist
be supposed to HADOOP_CONF_DIR Not configured properly .
Go to system environment variable configuration , Also go spark-env.sh Configuration of the , Then it doesn't work .
Linux Why is there no such problem after the next configuration ……
to update :
Later, it was found that it was not only the problem of environmental variables , Neither Windows and Linux difference ……
stay Windows and WSL Next , Because it is not inside the cluster , Even the user name is different , So many configurations have not been copied by brain .
For example, the machine that initiates the task here , No configuration at all Hadoop Of core-site.xml As a result of .
2.3.1 Need to be configured to use HDFS file system
Otherwise, those above cannot be found spark_conf,spark_libs All use the local directory of the host .
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm00:9000</value>
</property>
</configuration>
2.3.2 Set up HDFS File system permissions
I said before. , User names are different , So use HDFS After that, you need to set the directory permissions .
Otherwise, the client machine cannot put files to HDFS in , An unauthorized error will be reported .
WARN Client: Failed to cleanup staging dir hdfs://vm00:9000/user/Shion/.sparkStaging/application_XXXXYYYY_0057
org.apache.hadoop.security.AccessControlException: Permission denied: user=Shion, access=EXECUTE, inode="/user":ac:supergroup:drwx------
Only need to HDFS in /user Add operation permissions of other users to the directory (PS: You need to operate in the cluster HDFS)
$> hdfs dfs -chmod 777 /user
2.3.3 Unable to load main class
Cannot find or load main class org.apache.spark.deploy.yarn.ExecutorLauncher
This is because spark.yarn.jars But it is not formatted correctly .
Note that its value is not the directory name , It's a file wildcard .
spark.yarn.jars = hdfs://vm00:9000/bin/spark/jars/*.jar
If not set spark.yarn.jars, Or packaged spark.yarn.archive Tasks can also be run .
But I will use it every time spark A pile needed jar Package upload , And a warning appears :
WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
to update :
Set in the :hdfs://vm00:9000/bin/spark/jars/*.jar It doesn't exist out of thin air .
These files are from $SPARK_HOME/jars/*.jar.
So we have to put them on manually :
$> hdfs dfs -put $SPARK_HOME/jars/*.jar /bin/spark/jars/
In the end, it succeeded in !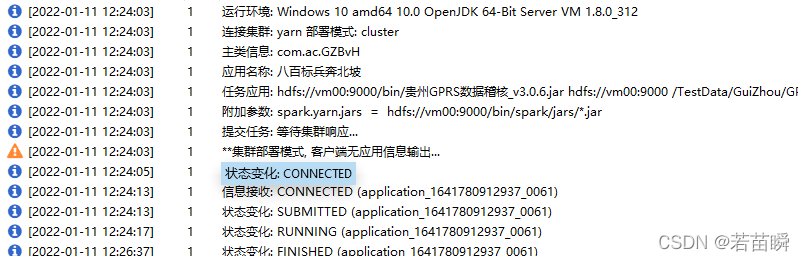
stay Yarn View applications in :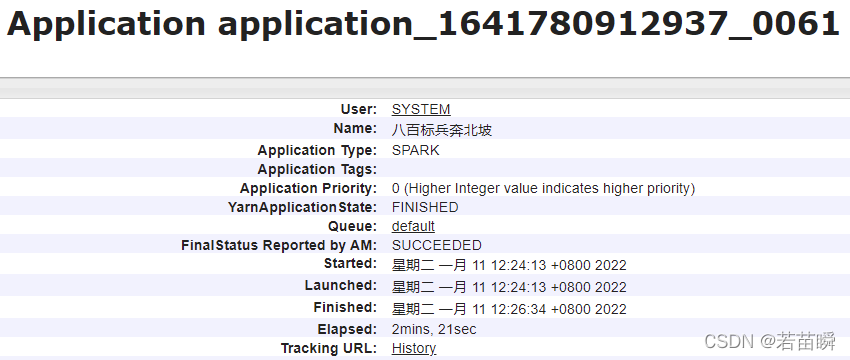
.
2.4 stay Linux It's a success
Of course , Because it is a cluster deployment mode ,driver The end also runs inside the cluster instead of the local machine .
So submit the log printout of the application itself , You can't see it here .
PS: Applied processing results , It should also be stored in HDFS On .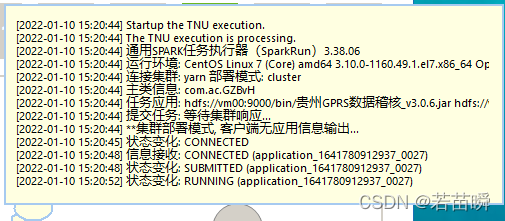
to update :
there Linux The host is in the cluster , All configurations are brainless , And there will be no mistakes ……
Is not Linux,Windows,WSL The difference between
.
2.5 Python application
It's amazing , Again python Version inconsistency .
Because there is more than one host in the cluster python edition .
front 《 stay Windows The next program passed SparkLauncher perform Spark Apply many pits 》 Inside , Mentioned that I set path To use the version installed by yourself . So for the moment , Only by path It's impossible to stay ahead .
modify spark-env.sh, increase PYSPARK_DRIVER_PYTHON and PYSPARK_PYTHON, Specify our own version python Program :
(PS: It's the executive program , Not a directory )
$> vim $SPARK_CONF_DIR/spark-env.sh
Add at the end :
export PYSPARK_DRIVER_PYTHON=/home/ac/python3/bin/python3
export PYSPARK_PYTHON=/home/ac/python3/bin/python3
PS: It seems to run successfully , But look at the log , Why did you still use the old version python 3.6.8??? I'll study it later ……
边栏推荐
- antd upload beforeUpload中禁止触发onchange
- 第 300 场周赛 - 力扣(LeetCode)
- Useeffect, triggered when function components are mounted and unloaded
- Market trend report, technical innovation and market forecast of China's desktop capacitance meter
- (POJ - 3258) River hopper (two points)
- (lightoj - 1323) billiard balls (thinking)
- Flask框架配置loguru日志库
- 300th weekly match - leetcode
- Research Report on market supply and demand and strategy of China's four flat leadless (QFN) packaging industry
- 图像处理一百题(11-20)
猜你喜欢





随机推荐
Codeforces Round #798 (Div. 2)A~D
Generate random password / verification code
Research Report on market supply and demand and strategy of China's four seasons tent industry
useEffect,函數組件掛載和卸載時觸發
生成随机密码/验证码
第5章 NameNode和SecondaryNameNode
Pull branch failed, fatal: 'origin/xxx' is not a commit and a branch 'xxx' cannot be created from it
QT模拟鼠标事件,实现点击双击移动拖拽等
分享一个在树莓派运行dash应用的实例。
The "sneaky" new asteroid will pass the earth safely this week: how to watch it
使用jq实现全选 反选 和全不选-冯浩的博客
Calculate the time difference
Hbuilder X格式化快捷键设置
拉取分支失败,fatal: ‘origin/xxx‘ is not a commit and a branch ‘xxx‘ cannot be created from it
CMake Error: Could not create named generator Visual Studio 16 2019解决方法
Codeforces Round #800 (Div. 2)AC
Research Report on market supply and demand and strategy of China's tetraacetylethylenediamine (TAED) industry
软通乐学-js求字符串中字符串当中那个字符出现的次数多 -冯浩的博客
AcWing——第55场周赛
(POJ - 3186) treatments for the cows (interval DP)