当前位置:网站首页>EKLAVYA -- 利用神经网络推断二进制文件中函数的参数
EKLAVYA -- 利用神经网络推断二进制文件中函数的参数
2022-07-02 06:26:00 【MezereonXP】
EKLAVYA – 利用神经网络推断二进制文件中函数的参数
这一次介绍一篇文章,名为 Neural Nets Can Learn Function Type Signatures From Binaries
来自于新加坡国立大学Zhenkai Liang团队,发在了Usenix Security 2017上
问题介绍以及形式化定义
该工作主要关注的问题是函数的参数推断,包含两个部分:
- 参数的个数
- 参数的类型,比如int, float等
传统方法通常会使用一些先验知识,将指令的语义,ABI惯例 (Application Binary Interface),编译器的风格等进行编码。
一旦编译器发生了改变,指令集合发生了改变,那么我们就需要重新引入一些先验知识。
如果我们可以摆脱,或者说是减少这些先验知识的利用,那么就不会受限了!
那么,使用神经网络来进行自动化的学习和推断,就是一种思路了。
前提假设
- 我们首先能知道一个函数的边界 (boundary)
- 在一个函数内部,我们知道它的指令边界
- 我们知道代表一个函数调用(function dispatch)的指令,比如call
通过反汇编工具,我们可以满足上述假设。
值得一提的是,函数边界也可以使用神经网络来做,有兴趣的读者可以参考 Dawn Song 发在Usenix Security 2015 的 Recognizing functions in binaries with neural networks.
这里,首先给出一些符号的定义:
我们定义我们的模型为 M ( ⋅ ) M(\cdot) M(⋅)
定义函数 a a a 反汇编出来的代码为 T a T_a Ta , T a [ i ] T_a[i] Ta[i] 代表函数 a a a 的第 i i i 个字节
函数 a a a 的第 k k k 条指令可以被写成 I a [ k ] : = < T a [ m ] , T a [ m + 1 ] , . . . , T a [ m + l ] > I_a[k]:= <T_a[m], T_a[m+1],...,T_a[m+l]> Ia[k]:=<Ta[m],Ta[m+1],...,Ta[m+l]>
- 其中 m m m 是对应指令的起始字节的位置索引
- l l l 是该指令所包含的字节数
一个包含 p p p 条指令的函数 a a a 可以被表示为 T a : = < I a [ 1 ] , I a [ 2 ] , I a [ p ] > T_a:=<I_a[1],I_a[2],I_a[p]> Ta:=<Ia[1],Ia[2],Ia[p]>
如果一个函数 b b b 有一个直接调用 call 对于函数 a a a, 我们将该条call指令之前的所有指令拿出来,称为 caller snippet,可译为调用者片段。定义为 C b , a [ j ] : = < I b [ 0 ] , . . . , I b [ j − 1 ] > C_{b,a}[j]:=<I_b[0],...,I_b[j-1]> Cb,a[j]:=<Ib[0],...,Ib[j−1]>
- 其中 I b [ j ] I_b[j] Ib[j] 对应 call 函数 a a a 的那一条指令
- 如果 I b [ j ] I_b[j] Ib[j] 是一个间接调用,我们令 C b , a [ j ] : = ∅ C_{b,a}[j]:=\empty Cb,a[j]:=∅
我们会收集函数 a a a 的所有调用者的调用者片段,记为 D a : = T a ∪ ( ⋃ b ∈ S a ( ⋃ 0 ≤ j ≤ ∣ T b ∣ C a , b [ j ] ) ) \mathcal{D}_a:=T_a\cup(\bigcup_{b\in S_a}(\bigcup_{0\leq j\leq |T_b|}C_{a,b}[j])) Da:=Ta∪(⋃b∈Sa(⋃0≤j≤∣Tb∣Ca,b[j]))
- 其中 S a S_a Sa 是调用 a a a 的所有函数的集合
由于调用者片段的长度可能非常长,这里文章设置为不超过500条指令
我们的函数 M ( ⋅ ) M(\cdot) M(⋅) 接受输入 D a \mathcal{D}_a Da , 输出两个变量:
- 函数 a a a 的参数个数
- 函数 a a a 的每一个参数的类型
- C-风格的参数类型可以被定义为 int, char, float, void*, enum, union, struct
方法设计
我们这里先直接给出整体的方法流程图:
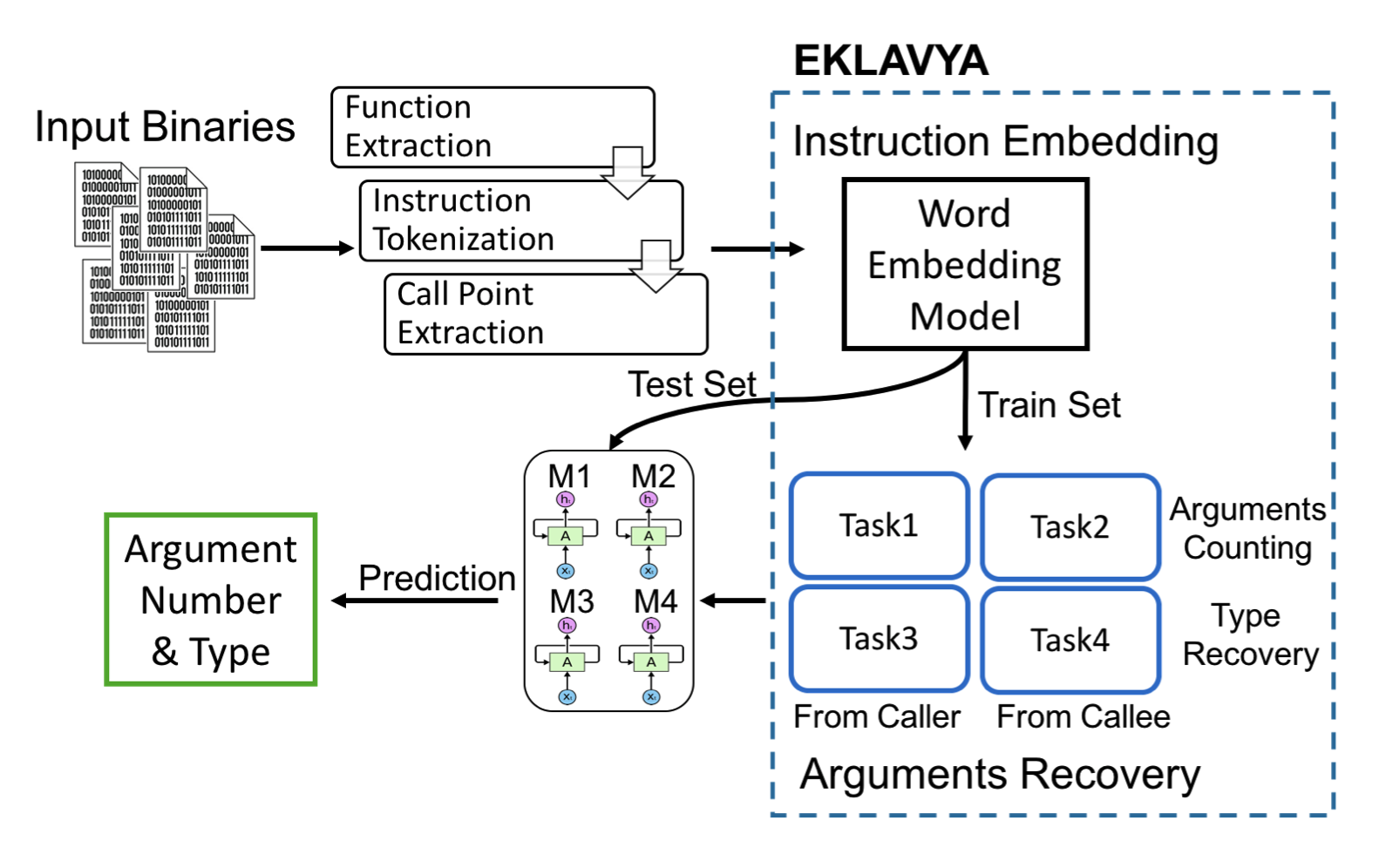
简单来说,可以划分成两个模块:
- 指令编码模块
- 首先,将输入的二进制文件进行函数抽取、指令的分割、调用点的抽取。
- 然后对指令进行Word Embedding编码,得到对应的向量表示,这一部分可以参照 NLP 中的 Word2Vec。
- 参数还原模块
- 将这些数据切分成训练集和测试集,分别使用4个递归神经网络(RNN)来从两个方面(调用者和被调用者)推断函数参数的个数以及类型,也就是对应上图中的4个任务(Task2,Task4 对应被调用者,Task1,Task3对应调用者)。
究竟是怎么推断多个参数类型的呢?
一个RNN,输入一个序列,只能推断出来一个类型。
所以这篇文章的实现是,训练多个RNN,每一个RNN独立推断固定位置的参数类型。
先用一个RNN推断出来参数个数,然后分别使用多个RNN来推断不同的位置的参数。
数据准备
该文章使用一些linux的包,然后使用clang和gcc来进行编译,通过设定debug模式,就可以直接在binary中的DWARF字段找到对应函数边界、参数个数以及类型,作为ground truth。
构建了两个数据集:
- 数据集1: 包含了3个流行的linux包(binutils,coreutils 以及 findutils), 使用了O0到O3的优化等级进行编译
- 数据集2: 将数据集1包含的linux包进行扩展,多增加5个 (sg3utils, utillinux, inetutils, diffutils 和 usbutils), 也在4个优化等级上进行编译
训练集和测试集的划分比例为8:2
不平衡的数据
在数据集的构造中,会出现不同类的数据比例相距甚远的情况。比如参数为pointer类型的数据就是union类型的数百倍,大部分函数都是少于3个参数。该文章中并没有解决这个问题。
实验结果
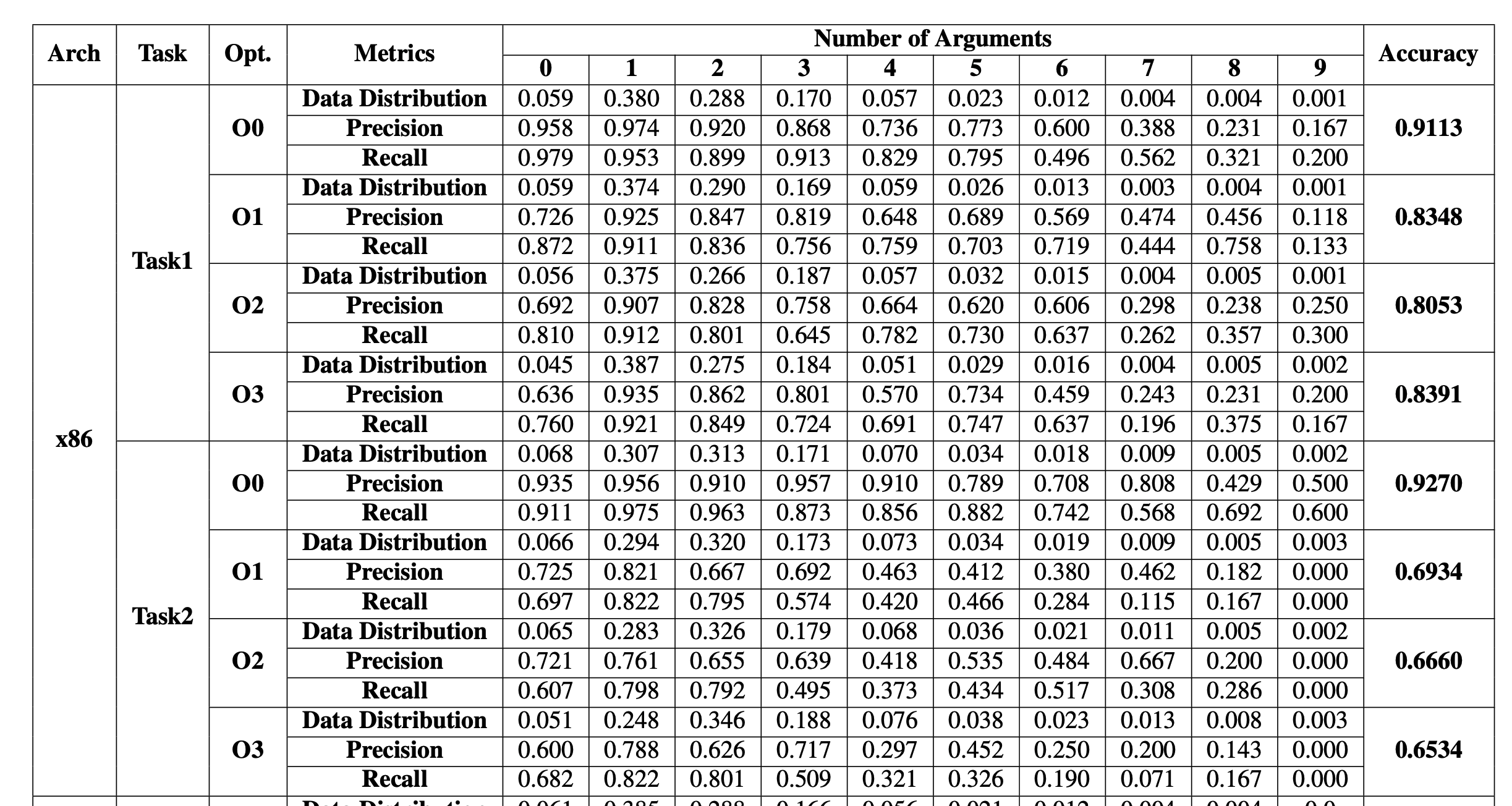
这里贴出来Task1和Task2,也就是通过调用者和被调用者,推断参数个数的结果
可以看到:
- 优化级别越高,越难推断,但并没有严格的递增关系
- 参数个数越多,越难推断,和训练数据量也有关系
- 从调用者方面,更容易推断出来参数个数

上面是,关于参数类型推断的结果
可以看到:
- 优化级别似乎干扰性不强,甚至优化级别越高,推断类型越精确
- 参数的位置越靠后,越难推断出来了类型
- 从调用者和被调用者两方面来推断,差别不是很大
边栏推荐
- 【TCDCN】《Facial landmark detection by deep multi-task learning》
- [binocular vision] binocular correction
- Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
- Faster-ILOD、maskrcnn_benchmark安装过程及遇到问题
- Use Baidu network disk to upload data to the server
- PointNet原理证明与理解
- 【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
- Point cloud data understanding (step 3 of pointnet Implementation)
- Common CNN network innovations
- Using MATLAB to realize: Jacobi, Gauss Seidel iteration
猜你喜欢
![[mixup] mixup: Beyond Imperial Risk Minimization](/img/14/8d6a76b79a2317fa619e6b7bf87f88.png)
[mixup] mixup: Beyond Imperial Risk Minimization
【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
Alpha Beta Pruning in Adversarial Search
Memory model of program
【多模态】CLIP模型
程序的内存模型

【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》

基于pytorch的YOLOv5单张图片检测实现
ABM thesis translation

Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
随机推荐
How do vision transformer work?【论文解读】
CONDA common commands
超时停靠视频生成
[binocular vision] binocular correction
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
Conversion of numerical amount into capital figures in PHP
Implementation of yolov5 single image detection based on pytorch
论文tips
Two dimensional array de duplication in PHP
(15) Flick custom source
open3d学习笔记三【采样与体素化】
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
Execution of procedures
CPU register
基于pytorch的YOLOv5单张图片检测实现
How to turn on night mode on laptop
parser. parse_ Args boolean type resolves false to true
【Batch】learning notes
Yolov3 trains its own data set (mmdetection)
【深度学习系列(八)】:Transoform原理及实战之原理篇