当前位置:网站首页>【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
2022-07-02 06:26:00 【bryant_meng】


ECCV-2018
文章目录
1 Background and Motivation
语义分割可以广泛的应用于 AR、自动驾驶、监控等场景,these applications have a high demand for efficient inference speed
for fast interaction or response.
目前轻量级语义分割网络从如下三个方面对网络进行加速(图1-a)
1)restrict the input size,缺点,丢了 spatial details
2)prune the channels of the network,缺点,作者认为是丢了 spatial capacity(有点过于由过推因了,只能说特征表达能力肯定是弱了,分辨率毕竟还在)
3)drop the last stage of the model,缺点,丢了感受野
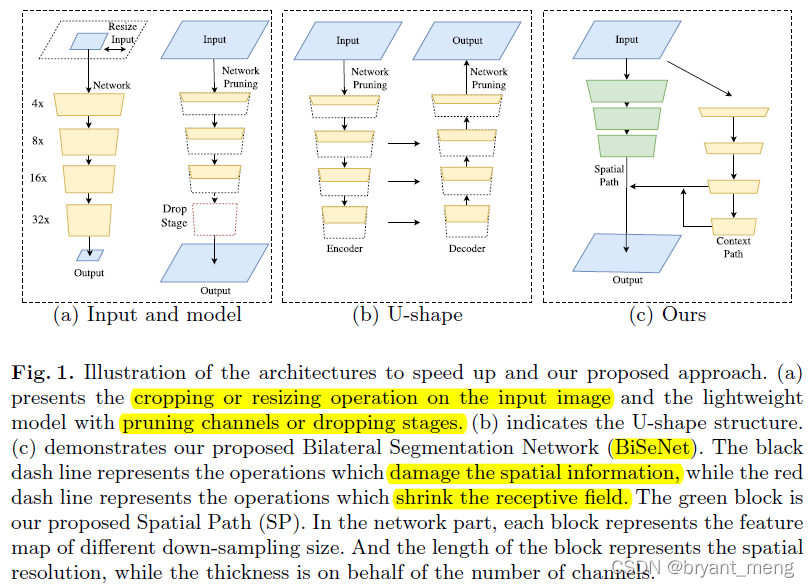
为缓解 spatial-detail 的丢失,人们提出了采用 U-shape 的结构(代表 U-Net),但是 U-shape 结构也存在如下的不足:
1)reduce the speed(引入了对高分辨率特征图的融合操作)
2)most spatial information lost in the pruning or cropping cannot be easily recovered by involving the shallow layers
U-shape technique is better to regard as a relief, rather than an essential solution(总结的很不错)
作者提出了轻量级语义分割网络 Bilateral Segmentation Network (BiSeNet) with two parts: Spatial Path (SP) and Context Path (CP) 来应对现有轻量级语义分割网络存在的空间信息丢失、感受野收缩的问题。
2 Related Work
- Spatial information
- U-Shape method
- Context information
- Attention mechanism
- Real time segmentation
3 Advantages / Contributions
设计提出 BiSeNet 轻量级分割网络,decouple the function of spatial information preservation and receptive field offering into two paths——Spatial Path and a Context Path.
设计了 two path 的特征融合模块 Feature Fusion Module (FFM) Attention Refinement Module (ARM)
在公开数据集上取得了 impressive results
4 Method

1)Spatial path
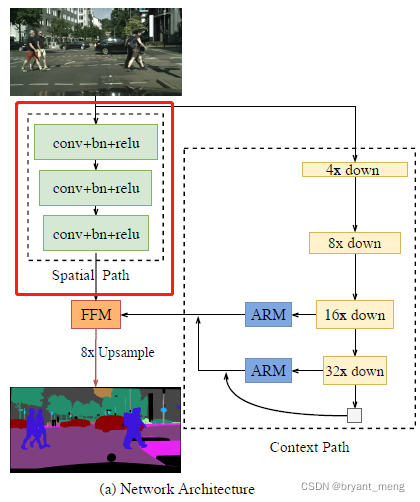
3 个步长为 2 的 conv,输出特征图分辨率为 1/8——wide network to capture adequate spatial information
2)Context path
consideration of the large receptive field and efficient computation simultaneously
a lightweight model to provide sufficient receptive field
主干 Xception39,down-sample rapidly,最后一层特征图接了个 global average pooling 来最大化的获取感受野
3)ARM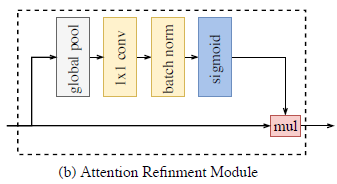
和 SENet 很像
4)FFM
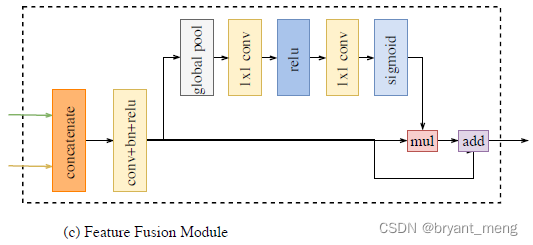
The features of the two paths are different in level of feature representation
不能简单的相加
concat 配合 BN,妙啊(因为 BN 的参数每个通道是不一样滴,如下图所示)
utilize the batch normalization to balance the scales of the features.

【BN】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
5)Loss function
所有损失都采用的是多类别的交叉熵损失
此外,作者在主干网络还引入了 auxiliary loss
l p l_p lp:principal loss of the concatenated output,也就是 FFM 上采样后和 GT 计算的 loss
l i l_i li: the auxiliary loss for stage i i i, K = 3 K = 3 K=3,也即主干网络的 stage2 和 stage3 上引入了监督
α \alpha α 文章中设置为 1
6)“poly” learning rate strategy
l r = b a s e _ l r ⋅ ( 1 − i t e r m a x _ i t e r ) p o w e r lr = base\_lr \cdot (1- \frac{iter}{max\_iter})^{power} lr=base_lr⋅(1−max_iteriter)power
p o w e r power power 文中设置的是 0.9
初始的学习率 b a s e _ l r base\_lr base_lr 为 2.5 e − 2 2.5e^{−2} 2.5e−2
5 Experiments
5.1 Datasets
- Cityscapes:19 classes(test)
- CamVid:11 semantic categories
- COCO-Stuff:对 COCO 数据集中全部 164K 图片做了像素级的标注,91 stuff classes and 1 class ’unlabeled’
5.2 Ablation study
1)主干
2)Ablation for U-shape
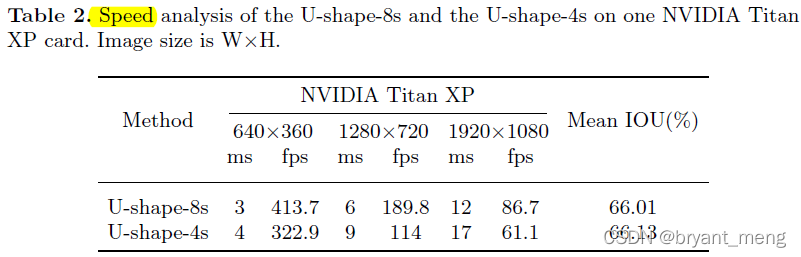
4 和 8 的含义:
The number represents the down-sampling factor of the output feature
3)Ablation for spatial path / attention refinement module / feature fusion module / global average pooling
5.3 Speed and Accuracy Analysis


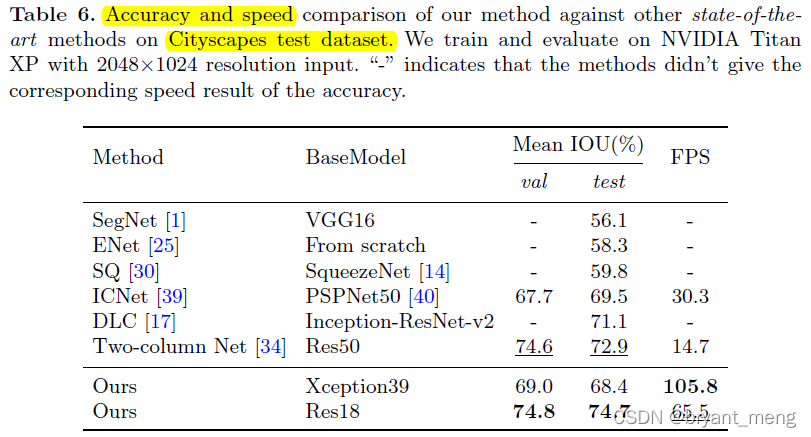
2048×1024 resize 到 1536×768 resolution for testing the speed and accuracy
再看看在公共数据集上的表现
Cityspaces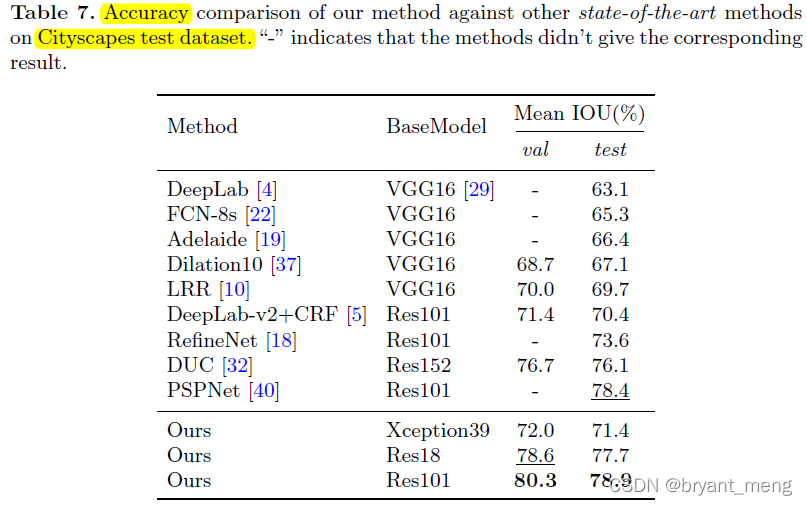
和 table6 的结果有点不一样,we take randomly take 1024×1024 crop as input
CamVid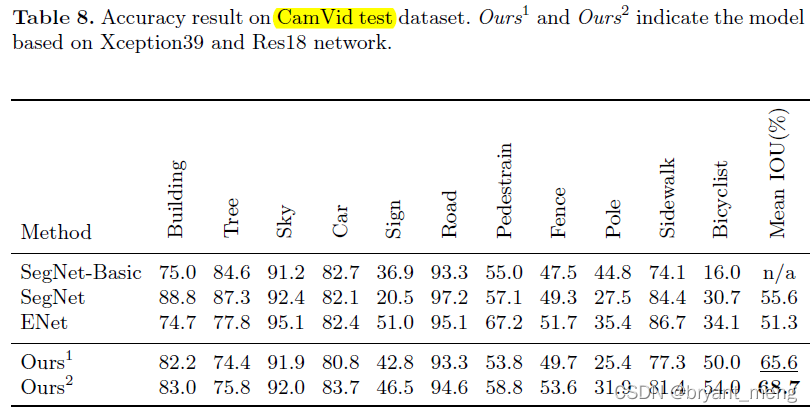
COCO-Stuff
6 Conclusion(own) / Future work
the spatial information of the image is crucial to predicting the detailed output
Semantic segmentation requires context information to generate a high-quality result
“ASPP” module is proposed to capture context information of different receptive field.
上下文 感受野
try to capture sufficient receptive field with pyramid pooling module, atrous spatial pyramid pooling or “large kernel”
the lightweight model damages spatial information with the channel pruning.
The scales contains { 0.75, 1.0, 1.5, 1.75, 2.0}. Finally, we randomly crop the image into fix size for training.
边栏推荐
- Calculate the difference in days, months, and years between two dates in PHP
- [torch] the most concise logging User Guide
- Execution of procedures
- 解决latex图片浮动的问题
- [introduction to information retrieval] Chapter 3 fault tolerant retrieval
- Thesis tips
- Sparksql data skew
- 【多模态】CLIP模型
- Two dimensional array de duplication in PHP
- 聊天中文语料库对比(附上各资源链接)
猜你喜欢
程序的执行
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization

Tencent machine test questions

SSM supermarket order management system

ModuleNotFoundError: No module named ‘pytest‘

【信息检索导论】第七章搜索系统中的评分计算

【Paper Reading】
![[model distillation] tinybert: distilling Bert for natural language understanding](/img/c1/e1c1a3cf039c4df1b59ef4b4afbcb2.png)
[model distillation] tinybert: distilling Bert for natural language understanding
ABM论文翻译

Drawing mechanism of view (I)
随机推荐
Common CNN network innovations
【论文介绍】R-Drop: Regularized Dropout for Neural Networks
Mmdetection installation problem
Proof and understanding of pointnet principle
PointNet理解(PointNet实现第4步)
Execution of procedures
label propagation 标签传播
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
Implementation of yolov5 single image detection based on onnxruntime
CONDA creates, replicates, and shares virtual environments
Memory model of program
Huawei machine test questions
latex公式正体和斜体
Spark SQL task performance optimization (basic)
Calculate the difference in days, months, and years between two dates in PHP
Ding Dong, here comes the redis om object mapping framework
win10解决IE浏览器安装不上的问题
Using MATLAB to realize: power method, inverse power method (origin displacement)
Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation