当前位置:网站首页>Deep learning classification Optimization Practice
Deep learning classification Optimization Practice
2022-07-02 07:36:00 【wxplol】
List of articles
Recently, I have done some experiments related to classification , It mainly studies some optimization methods in the process of model development , Record here , In this paper, the related models and algorithms are implemented and tested , As a whole , Some optimization methods can increase the accuracy of the model , Some may have no effect , The general record is shown below . The data set used in this paper is CIFAR-100 .
Code address : Portal
One 、 Optimization strategy
1、CIFAR-100 Data set profile
First , We need to get the data and clarify our tasks . Here we use cifar-100 For example , It is 8000 A subset of 10000 tiny image data sets , They were Alex Krizhevsky,Vinod Nair and Geoffrey Hinton collect .CIFAR -100 Data sets (100 Categories ) yes Tiny Images A subset of a dataset , from 60000 individual 32x32 Color image composition .CIFAR-100 Medium 100 The categories are divided into 20 A superclass . Each class has 600 Zhang image . Each image comes with a “ fine ” label ( The class it belongs to ) And a “ rough ” label ( The superclass it belongs to ). Each class has 500 A training image and 100 A test image .
Simply speaking , We need to target CIFAR-100 Data sets , Design 、 build 、 Training machine learning models , Be able to distinguish the labels of test data as accurately as possible .
Refer to the connection :
CIFAR100 Data set introduction and usage
2、 Model evaluation indicators
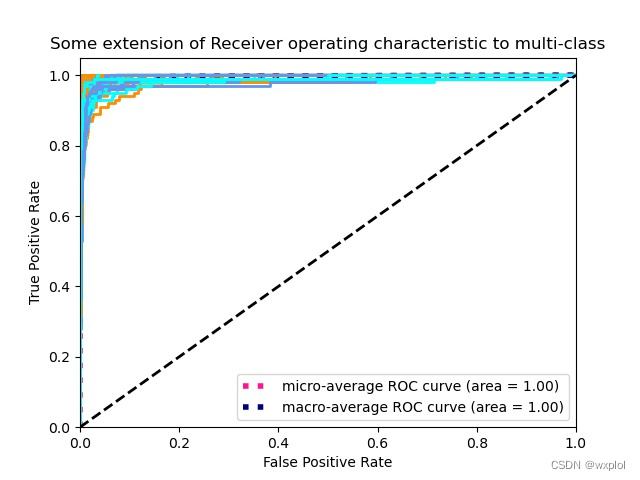
For classification models , The most important thing is to see the accuracy of the model . Of course , Light from the accuracy can not fully evaluate the performance of the model , I also need to look at the classification of each category from the confusion matrix ,PR Curve analysis of the accuracy and recall of our model ,ROC Generalization ability of curve evaluation model . For specific implementation, please refer to the code in this article utils/metric.py.
- Confusion matrix

Through observation , It can be seen that the model can classify each category well .
- PR curve

- ROC curve
3、 data ! data ! data !
3.1、 Data to enhance
Data enhancement is a better means to solve the problem of over fitting , Its essence is to expand the training data samples to a certain extent , Avoid fitting the model to the noise in the training set , Therefore, it is particularly necessary to design a good data enhancement scheme . stay CV Tasks , Common data enhancements include RandomCrop( Random deduction )、Padding( Patch )、RandomHorizontalFlip( Random horizontal flip )、ColorJilter( Color jitter ) etc. . There are other advanced data enhancement techniques , such as RandomEreasing( Random erase )、MixUp、CutMix、AutoAugment, And the latest AugMix and GridMask etc. . In actual training , How to choose , We need to focus on specific experiments , We mainly need to refer to some excellent papers , What to use for reference . In this task, in addition to some commonly used enhancement methods , Also choose some optimization means of bonus points , Then through the selection of experiments , Choose a more appropriate data enhancement scheme . Concrete realization utils/augment/augment.py.
The main comparisons are as follows :
| method | acc |
|---|---|
| RandomCrop+RandomHorizontalFlip+RandomRotation | 0.78 |
| RandomCrop+RandomHorizontalFlip+RandomRotation+random_erase | 0.79 |
| RandomCrop+RandomHorizontalFlip+RandomRotation+random_erase+autoaugment | 0.81 |
3.2、 The data distribution
This article uses CIFAR-100 Each class of the data set belongs to a relatively balanced data , But in the actual classification , Most of them are unbalanced long tail data , At this time, we need to reduce the impact of this imbalance on prediction . Of course , In addition to the influence of long tail distribution , There are also similar effects between classes , For example, the two classes are relatively close , No matter the shape 、 Size or color , Algorithms are needed to further distinguish or minimize the impact on classification . Commonly used means to solve the long tail distribution are : Resampling ( It needs to be done without affecting the original distribution , Such as abnormal detection , In this case, resampling will change the original distribution of data , Instead, it will reduce the accuracy , Because it's just / There are many negative samples )、 The redesign loss( Such as Focal loss、OHEM、Class Balanced Loss)、 Or it can be transformed into anomaly detection and One-class Classification models, etc .
For multi class problems , The same picture may have multiple classes , At this point, the traditional CE loss There are certain defects in the design of . Because in multi label classification , There can be multiple correct classes in a data point . therefore , The multi label classification problem needs to detect each object in the image . and CE loss Will try to fit one-hot label , It is easy to cause over fitting , The generalization ability of the model cannot be guaranteed , At the same time, because the label cannot be guaranteed to be 100% correct , There may be some wrong labels , But the model will also fit these wrong labels , For the above reasons , Proposed label smoothing , For soft labels , It belongs to a kind of regularization , Can prevent over fitting .label smoothing See utils/losses.py.
Reference link :
Dealing with imbalance in visual classification tasks loss Compare
The solution of long tail distribution classification problem
4、 Model selection
The choice of models gives priority to the latest and best models , You can refer to Portal , Choose the right model . here , I choose the ResNet Model as baseline backbone.
Here we compare different models , The experiment is as follows :
| method | acc |
|---|---|
| resnet18 | 0.75 |
| resnet50 | 0.78 |
| resnet101 | 0.79 |
It can be seen that the more complex the model , It can improve the accuracy of our model . So we also chose wideresnet Training with such a large model will greatly improve the accuracy of the model . Of course , Later, you can also choose the latest transformer Model , Such as :VIT、Swin、CaiT etc. , As our training model .
Reference link :
Transformer A profound ( One ):Vision Transformer
5、 Model optimization
5.1、 Learning rate selection
We enumerate different learning rates loss Value select the optimal learning rate ( Concrete realization tool/lr_finder.py), Draw the curve as follows :

It can be seen from observation that ,lr=0.1 when loss The minimum , At this time, the learning rate is the best .
5.2、 Optimizer selection
For deep learning , There are many optimizers , Such as :SGD、Adagrad、Adadelta、RMSprop、Adam etc. . Of course , There are also the latest optimizers , Such as :Ranger、SAM etc. ( Concrete realization utils/optim.py).
Here we compare different optimizers , The experiment is as follows :
| method | acc |
|---|---|
| SGD | 0.79 |
| adam | 0.79 |
| ranger | 0.65 |
| SAM | 0.8311 |
It can be seen from observation that , choice SAM The optimizer is optimal .
Reference link :
Don't worry about fitting anymore
5.3、 Learning rate update strategy selection
Here we choose warmup Warm up update strategy , Concrete realization utils/scheduler.py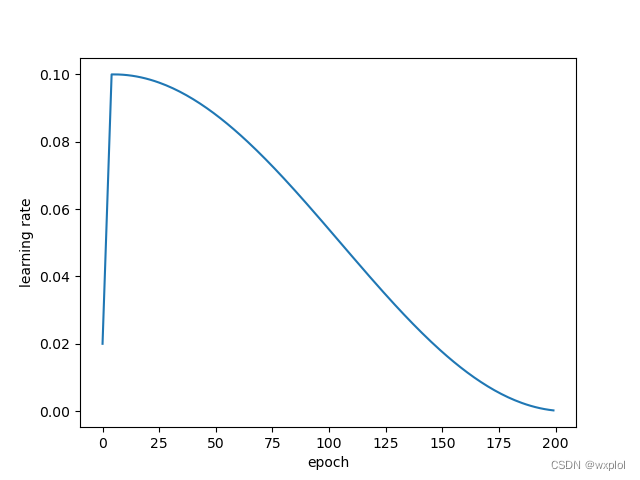
5.4、loss choice
In the previous data analysis , We discussed the problem of data distribution , Because our data is a multi classification problem , So we need to add label smoothing to the cross entropy loss function , This can better train , Prevent over fitting .
Here we compare different loss functions , The experiment is as follows :
| method | acc |
|---|---|
| CE | 0.8311 |
| smooth_CE | 0.833 |
6、 The whole idea
- lr:
- warmup (5 epoch)
- cosine lr decay
- lr=0.1
- total epoch(200 epoch)
- bs=128
- aug:
- Random Crop and resize
- Random left-right flipping
- Random rotation
- AutoAugment
- Normalization
- Random Erasing
- weight decay=5e-4 (bias and bn undecayed)
- kaiming weight init
- optimizer: SAM
- loss: smooth_CE
- TTA
Our preliminary training resnet50 As a basic model , The experimental test process is as follows :
| network | method | acc |
|---|---|---|
| resnet18 | SGD+warmup+CE | 0.75 |
| resnet50 | SGD+warmup+CE | 0.78 |
| resnet101 | SGD+warmup+CE | 0.79 |
| resnet50 | SGD+warmup+random_erase+CE | 0.79 |
| resnet50 | SGD+warmup+random_erase+autoaugment+CE | 0.815 |
| resnet50 | adam+warmup+random_erase+autoaugment+CE | 0.79 |
| resnet50 | ranger+warmup+random_erase+autoaugment+CE | 0.65 |
| resnet50 | SAM+warmup+random_erase+autoaugment+CE | 0.8311 |
| resnet50 | SAM+warmup+random_erase+autoaugment+smooth_CE | 0.833 |
| wideresnet40_10 | SAM+warmup+random_erase+autoaugment+smooth_CE | 0.840 |
| wideresnet40_10 | SAM+warmup+random_erase+autoaugment+smooth_CE+TTA | 0.8437 |
Through the experiment , We finally choose wideresnet40_10 As a feature extraction model , During the experiment Accuracy from 78% Upgrade to 84.37%.
Two 、pytorch actual combat
Installation requirements
- python3.6
- pytorch1.6.0+cu101
- tensorboard 2.2.2(optional)
function tensorboard
$ mkdir runs
$ tensorboard --logdir='runs' --port=6006 --host='localhost'
- Training models
$ python train.py -gpu
- test model
$ python test.py
Model reference links :
- vgg Very Deep Convolutional Networks for Large-Scale Image Recognition
- googlenet Going Deeper with Convolutions
- inceptionv3 Rethinking the Inception Architecture for Computer Vision
- inceptionv4, inception_resnet_v2 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- xception Xception: Deep Learning with Depthwise Separable Convolutions
- resnet Deep Residual Learning for Image Recognition
- resnext Aggregated Residual Transformations for Deep Neural Networks
- resnet in resnet Resnet in Resnet: Generalizing Residual Architectures
- densenet Densely Connected Convolutional Networks
- shufflenet ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- shufflenetv2 ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
- mobilenet MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- mobilenetv2 MobileNetV2: Inverted Residuals and Linear Bottlenecks
- residual attention network Residual Attention Network for Image Classification
- senet Squeeze-and-Excitation Networks
- squeezenet SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
- nasnet Learning Transferable Architectures for Scalable Image Recognition
- wide residual networkWide Residual Networks
- stochastic depth networksDeep Networks with Stochastic Depth
边栏推荐
- 使用Matlab实现:弦截法、二分法、CG法,求零点、解方程
- Oracle EBS DataGuard setup
- 深度学习分类优化实战
- Drawing mechanism of view (3)
- Regular expressions in MySQL
- 【信息检索导论】第六章 词项权重及向量空间模型
- 使用Matlab实现:幂法、反幂法(原点位移)
- CRP implementation methodology
- SSM second hand trading website
- A slide with two tables will help you quickly understand the target detection
猜你喜欢
PointNet理解(PointNet实现第4步)

Oracle EBs and apex integrated login and principle analysis
使用Matlab实现:Jacobi、Gauss-Seidel迭代
【深度学习系列(八)】:Transoform原理及实战之原理篇
Point cloud data understanding (step 3 of pointnet Implementation)
Illustration of etcd access in kubernetes
Play online games with mame32k
【论文介绍】R-Drop: Regularized Dropout for Neural Networks

腾讯机试题

Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
随机推荐
解决latex图片浮动的问题
SSM laboratory equipment management
图片数据爬取工具Image-Downloader的安装和使用
Ding Dong, here comes the redis om object mapping framework
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
生成模型与判别模型的区别与理解
parser.parse_args 布尔值类型将False解析为True
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
Message queue fnd in Oracle EBS_ msg_ pub、fnd_ Application of message in pl/sql
view的绘制机制(二)
win10解决IE浏览器安装不上的问题
[introduction to information retrieval] Chapter 6 term weight and vector space model
Win10+vs2017+denseflow compilation
allennlp 中的TypeError: Object of type Tensor is not JSON serializable错误
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
[introduction to information retrieval] Chapter 1 Boolean retrieval
A summary of a middle-aged programmer's study of modern Chinese history
Cognitive science popularization of middle-aged people
基于onnxruntime的YOLOv5单张图片检测实现
[medical] participants to medical ontologies: Content Selection for Clinical Abstract Summarization