当前位置:网站首页>Chapter 1 overview of MapReduce
Chapter 1 overview of MapReduce
2022-07-06 16:36:00 【Can't keep the setting sun】
1.1 MapReduce Definition
MapReduce Is a programming framework for distributed applications , It's user development “ be based on Hadoop Data analysis application ” The core framework of .
MapReduce The core function is to integrate the business logic code written by the user and the default components into a complete distributed computing program , Running concurrently in a Hadoop On the cluster .
1.2 MapReduce Advantages and disadvantages
1.2.1 advantage
(1) MapReduce Easy to program , Simply implement some excuses , You can complete a distributed program , This distributed program can be distributed to a large number of cheap PC Machine running . It's exactly the same as writing a simple serial program .
(2) Good scalability , When computing resources are insufficient , Computing power can be expanded by adding machines .
(3) High fault tolerance ,MapReduce The original intention of the design is to enable the program to be deployed in cheap PC On the machine , This requires it to have high fault tolerance . for example , One of the machines is down , It can transfer the above computing tasks to another node to run , Not to fail the whole task , And this process does not require human participation , Completely by Hadoop Internally completed .
(4) fit PB Massive data processing above level , Can achieve thousands of server cluster concurrent work , Provide data processing capabilities .
1.2.2 shortcoming
(1) Not good at real-time computing ,MapReduce Not like MySQL equally , Returns results in milliseconds or seconds .
(2) Not good at streaming Computing , The input data of streaming computing is dynamic , and MapReduce The input data for is static , Can't change dynamically . from MapReduce Suitable for batch processing characteristics .
(3) Not good at DAG( Directed graph ) Calculation , Multiple applications have dependencies , The input of the latter application is the output of the former . under these circumstances ,MapReduce It's not that you can't do it , It is MapReduce The output of the job is written to disk , It's going to create a lot of disks IO, Resulting in very low performance .
1.3 MapReduce The core idea
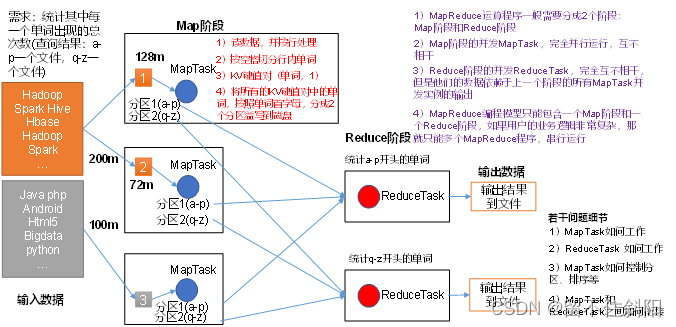
(1) Distributed computing programs often need to be divided into at least 2 Stages .
(2) First stage MapTask Concurrent instance , Full parallel operation , Irrelevant .
(3) Second stage ReduceTask Concurrent instances are irrelevant , But their data depends on everything from the previous stage MapTask Output of concurrent instances .
(4) MapReduce The programming model can only contain one Map Stage and a Reduce Stage , If the user's business logic is very complex , There's only one MapReduce Program , Serial operation .
1.4 MapReduce process
A complete MapReduce There are three types of instance processes in distributed runtime
- MrAppMaster: Responsible for process scheduling and state coordination of the whole program ;
- MapTask: be responsible for Map The whole data processing flow of the stage ;
- ReduceTask: be responsible for Reduce The whole data flow of the stage ;
1.5 Common data serialization types
Common data types correspond to Hadoop Data serialization type , As shown in the following table
| Java type | Hadoop Writable type |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
1.6 MapReduce Programming specification
The program written by the user is divided into three parts :Mapper、Reducer and Driver.
Mapper Stage
- User defined Mapper Inheritance Mapper Parent class ;
- Mapper The input data for is KV On the form of (KV The type can be customized );
- Mapper The business logic in is written in map() In the method ;
- Mapper The output data of is KV On the form of (KV The type can be customized );
- map() Method (MapTask process ) For each <K,V> Call once ;
Reducer Stage
- User defined Reducer Inheritance Reducer Parent class ;
- Reducer The input data type of corresponds to Mapper The type of output data , It's also KV;
- Reducer Your business logic is reduce() In the method ;
- ReduceTask The process is the same for each group K Of <k, v> Group call once reduce() Method ;
Driver Stage
- amount to YARN Cluster clients , Used to submit the whole program to YARN colony , What is submitted is that it encapsulates MapReduce Program related operation parameters Job object ;
1.7 WordCount Case study
1. demand
In the given text file statistics output the total number of times each word appears
2. Demand analysis
according to MapReduce Programming specification , Write separately Mapper,Reducer,Driver, As shown in the figure
input data
java hello apple
hadoop spark
spark java hello
hello
Output data
apple 1
hadoop1
hello 3
java 2
spark 2
To write Mapper
- take MapTask The transmitted text content is converted into string
- Cut a line into words according to the spaces
- Output the word as < word , 1>
To write Reducer
- Summarize each key The number of ;
- Output key Total number of ;
To write Driver
- Get configuration information , obtain Job Instance object ;
- Specify this procedure jar The local path of the package ;
- relation Mapper/Reducer Business class ;
- Appoint Mapper Of output data kv type ;
- Specifies the of the final output data kv type ;
- Specify the directory of input data ;
- Specify the path where the output results are located ;
- Submit the assignment ;
3. Environmental preparation
(1) establish maven engineering
(2) stay pom.xml Add the following dependencies to the file
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
(3) In the project src/main/resources Under the table of contents , Create a new file named “log4j.properties”, Fill in the file with .
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4. Programming
(1) To write Mapper class
package com.test.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = value.toString();
// 2 cutting
String[] words = line.split(" ");
// 3 Output
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
(2) To write Reducer class
package com.test.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 Sum by accumulation
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 Output
v.set(sum);
context.write(key,v);
}
}
(3) To write Driver Drive class
package com.test.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 Get configuration information and encapsulate tasks
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 Set up Driver class
job.setJarByClass(WordcountDriver.class);
// 3 Set up map and reduce class
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 Set up map Output
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 Set the final output kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 Sets the input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 Submit
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
5. Local testing
(1) If the computer system is win7 Will win7 Of hadoop jar Unzip the package to a non Chinese path , And in Windows Configuration on Environment HADOOP_HOME environment variable . If it's a computer win10 operating system , Just unzip win10 Of hadoop jar package , And configuration HADOOP_HOME environment variable .
Be careful :win8 Computer and win10 There may be a problem with the home operating system , You need to recompile the source code or change the operating system .
(2) stay Eclipse/Idea Run the program on
6. Test on the cluster
use maven hit jar package , The packaged plug-ins that need to be added depend on
Be careful :com.test.mr.WordcountDriver You need to replace it with your own project main class
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.test.mr.WordcountDriver</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Be careful : If the project shows a Red Cross . Right click on the project ->maven->update project that will do .
Type the program as jar package , And then copy to Hadoop In the cluster
perform WordCount Program
[[email protected] software]$ hadoop jar wc.jar
com.test.wordcount.WordcountDriver /user/test/input /user/test/output
边栏推荐
- Research Report on market supply and demand and strategy of China's tetraacetylethylenediamine (TAED) industry
- China double brightening film (dbef) market trend report, technical dynamic innovation and market forecast
- Sanic异步框架真的这么强吗?实践中找真理
- Radar equipment (greedy)
- QT realizes window topping, topping state switching, and multi window topping priority relationship
- Codeforces - 1526C1&&C2 - Potions
- 力扣:第81场双周赛
- How to insert mathematical formulas in CSDN blog
- 【锟斤拷】的故事:谈谈汉字编码和常用字符集
- QT simulates mouse events and realizes clicking, double clicking, moving and dragging
猜你喜欢
Hbuilder X格式化快捷键设置

图像处理一百题(11-20)

Read and save zarr files
Installation and configuration of MariaDB
Chapter 2 shell operation of hfds
Raspberry pie 4B installation opencv3.4.0
拉取分支失败,fatal: ‘origin/xxx‘ is not a commit and a branch ‘xxx‘ cannot be created from it
软通乐学-js求字符串中字符串当中那个字符出现的次数多 -冯浩的博客

Summary of game theory
js封装数组反转的方法--冯浩的博客
随机推荐
Discussion on QWidget code setting style sheet
(lightoj - 1354) IP checking (Analog)
Maximum product (greedy)
(lightoj - 1370) Bi shoe and phi shoe (Euler function tabulation)
Codeforces Round #801 (Div. 2)A~C
第5章 消费者组详解
Calculate the time difference
解决Intel12代酷睿CPU单线程调度问题(二)
本地可视化工具连接阿里云centOS服务器的redis
图图的学习笔记-进程
Spark独立集群动态上线下线Worker节点
Bisphenol based CE Resin Industry Research Report - market status analysis and development prospect forecast
Chapter 6 rebalance details
Codeforces Round #799 (Div. 4)A~H
新手必会的静态站点生成器——Gridsome
Spark独立集群Worker和Executor的概念
It is forbidden to trigger onchange in antd upload beforeupload
Read and save zarr files
图像处理一百题(11-20)
QT按钮点击切换QLineEdit焦点(含代码)