当前位置:网站首页>WebRTC 音频抗弱网技术(上)
WebRTC 音频抗弱网技术(上)
2022-07-07 12:41:00 【51CTO】

人均社恐,钟爱语聊。以语聊房为代表的语音社交产品解锁陌生人社交新方式,也不断讲述着新的出圈故事。关注【融云全球互联网通信云】了解更多
而声音卡顿、断断续续、快进、慢放等现象会严重影响用户体验,直接导致用户离开,这些都是弱网引起的常见问题。
本文主要从音频应用的角度来分析常用的弱网对抗技术,主要有如下几种:
- 前向纠错技术(FEC、RED 等)
- 后向纠错技术(ARQ、PLC 等)
- 编码器抗弱网特性(本文重点关注 OPUS 编码器的特性)
- 抗抖动技术(JitterBuffer)
我们将用上、下两篇文章,结合 WebRTC 中使用或支持的音频抗弱网技术,对以上几类技术做分析,以实现音频通信服务在弱网环境下高可用。
上篇主要分享前向纠错技术、后向纠错技术及 OPUS 编解码抗弱网特性;下篇专题分享 WebRTC 使用的抗抖动模块 NetEQ。
前向纠错技术
FEC
前向纠错技术,最典型的就是 FEC 技术了。
发送端:生成冗余包来对抗传输过程中丢包的问题;
接收端:对收到的冗余包和正常包来重新恢复传输过程中丢失的包。
FEC 分带内和带外两种,WebRTC 中视频是通过带外 FEC(ULPFEC[1]、FLEXFEC[2])来产生冗余包,音频则是通过 OPUS 带内 FEC 来生成冗余包。
带内 FEC 由于会占用一部分编码码率,所以对音频的音质会有所降低。带外 FEC 不会影响音质,但会额外占用网络带宽,各有优缺点。
FEC 典型的编码方式有 XOR 和 Reed Solomon[3]。WebRTC 的带外 FEC 使用的是 XOR 编码方式(ULPFEC和FLEXFEC),其特点是计算量相对少,但其抗丢包能力有限。
在 WebRTC 中,带外 FEC,不论是 ULPFEC,还是 FLEXFEC 都是根据 MASK 掩码来确定 FEC 包和被保护的源 RTP 包的映射关系,其中定义了两种类型的掩码,RandMask 和 BurstMask,前者在随机丢包中保护效果要好些;后者则是对突发导致连续丢包效果会好些,但是不论哪种,都有其缺点;这里以 7-4 掩码(即 7 个原始包,将生成 4 个冗余包)举例:
将上面十六进制按照二进制展开如下:
上面的掩码表示根据 S1-S7 共 7 个原始包,发送端将生成 4 个冗余包 R1-R4,其中:
- R1 包保护 S3,S4,S5 三个原始包
- R2 包保护 S1,S5,S7 三个原始包
- R3 包保护 S1,S2,S6 三个原始包
- R4 包保护 S2,S3,S7 三个原始包
从上也可以看出,每个原始包都有被冗余包保护;当包丢失了,一般可以通过冗余包和收到的原始包来进行恢复,比如发送端发送了 S1-S7、R1-R4 共 11 个包,接收端收到了 S1、S3、S5、S7、R1、R2、R3、R4 共 8 个包,丢失了 S2、S4、S6 三个包;则 S2、S4、S6 修复过程如下:
- S2 可以被 R4、S3、S7 修复,即 S2 = R4 XOR S3 XOR S7
- S4 可以被 R1、S3、S5 修复,即 S4 = R1 XOR S3 XOR S5
- S6 可以被 R3、S1、S2 修复,即 S6 = R3 XOR S1 XOR S2
但是也有些包无法修复,比如丢失了 S1、S2、S7,则无法恢复,原因如下:
根据掩码保护关系可知,S1 的恢复可以通过 R2、S5、S7 或者 R3、S2、S6;但因为 S7 和 S2 丢失,要恢复 S1,需要先恢复 S2 或 S7
同样,S2 可以通过 R3、S1、S6 恢复,但因为 S1 丢失,则需要先恢复 S1
同理,S6 可以通过 R3、S1、S2 恢复,但是需要先恢复 S1、S2
所以,经过上面的分析可知 S1、S2、S7 均⽆法恢复
同理,要是丢失了 S3、S5、S7,也无法恢复,这是 WebRTC 中采用掩码来确定冗余包和原始包之间的保护关系的技术缺点。
即对于(M 个原始包 + N 个冗余包)一组包,有小于等于 N 个包丢失时,可能无法恢复丢失包的情况。
Reed Solomon 编码则可以做到对于(M 个原始包 + N 个冗余包)一组包,有小于等于 N 个包丢失,都可以将丢失的包恢复。
RS FEC 主要是使用范德蒙矩阵或者柯西矩阵来进行编解码[4],柯西矩阵效果比范德蒙矩阵计算量少,性能更优;但不论上面何种矩阵,它们都具有⼀个特性就是可逆,且任意子矩阵可逆,这就保证了在丢失小于等于 N 个包时,RS 能将其恢复。
下面以范德蒙矩阵做简要说明。以(7,4)为例,即 7 个原始包产生 4 个冗余包,原始包为 S1、S2、S3、S4、S5、S6、S7,冗余包为(R1、R2、R3、R4)。原始包和冗余包的关系如下:

图说
其中上面的范德蒙矩阵为 A,如下所示:
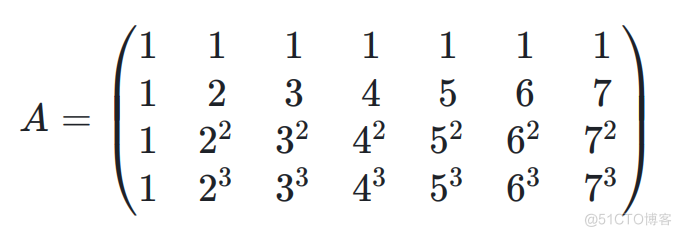
图说
单位矩阵表示如下:

图说
假设 S2 、S4 两数据包丢失了,则将公式 1 中的单位矩阵对应的行删除,则有如下:

图说
公式 2 左侧的矩阵记为 B,如下:

图说
根据范德蒙矩阵可逆特点, 所以 B 也是一个可逆矩阵,记为 B,则恢复包过程其实主要就是求解 B' 矩阵的过程,对公式 2 做如下推导,即可求解原始包,如下所示:
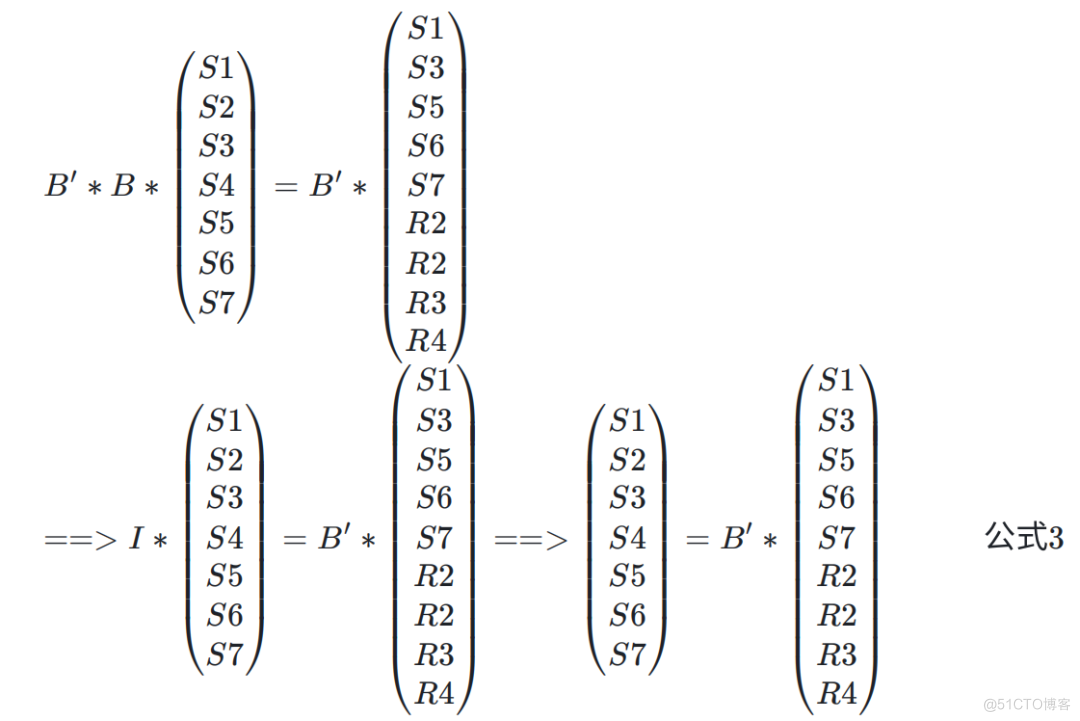
图说
即 (S1、S2、S3、S4、S5、S6、S7)中任何一个包都可以通过矩阵 B' 和收到的包进行恢复。所以 RS 的保护能力更强。
RED[5]
RED 也是前向纠错的⼀种方式,发送端通过主动发送冗余码,来在⼀定程度上抵抗包在传输网络丢失的问题。解码端可以通过冗余包恢复丢失的包,RED 的标准规范在 RFC2198 中定义,可用在视频和音频冗余包生成,WebRTC 音频在 m96 上开启了 RED 方式。
RED 的 payload 中不但包含当前包,还包含了历史包,这样 payload 在⼀定程度上具有冗余信息,起到抗丢包的作用。
下面简要介绍下 RED 的封装格式:RED block head
下面是一个 RED 包的示例:
WebRTC 中使用 RED 包来生成 audio 冗余包,其原理大致如下:
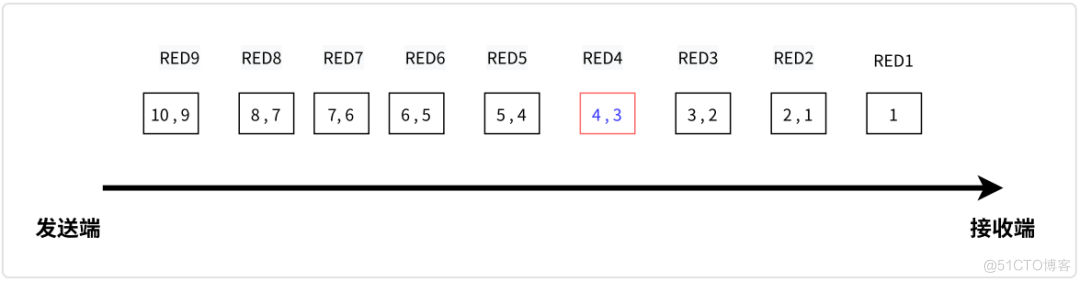
图说
上图中,发送端除了发送当前包,还会携带之前一个包做为冗余包,当上图的 RED4 包丢失,即 4,3 包丢掉时,后续的 RED5 包到达,包含了 5,4 包,结合之前 RED3 包(包含了 3, 2 包),可以恢复丢失的包。
后向纠错技术
ARQ
ARQ 为丢包重传技术,接收端通过向发送端请求重发丢失的包来恢复丢失的包。
这个相对于前向纠错技术来讲,延时偏高,在延时小的情况下,是个比较合适的选择。
原理如下所示:
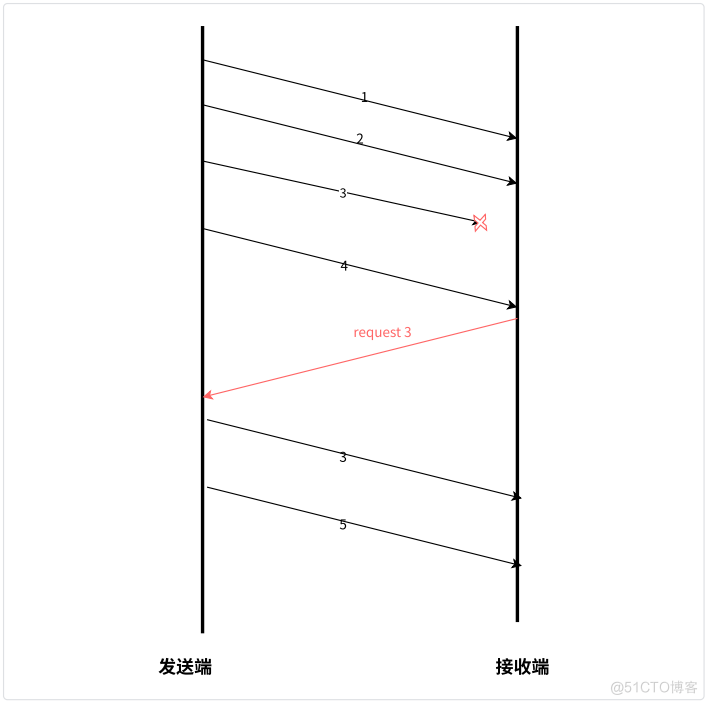
图
数据包 3 第⼀次发送时,接收端没有收到,便向发送端发起 3 的重传请求(WebRTC 中使⽤ NACK RTCP 包),发送端收到了接收的重传请求后,则再次重发报文 3。
下面是对 WebRTC 中使用的 NACK[6] RTCP 格式的简单介绍,NACK RTCP 在 RFC4585 中有介绍,NACK 属于反馈消息,即 Feedback Message,格式如下:
PT 有两种大类型:
NACK 对应的 FCI 消息格式如下:
PLC
PLC 称之为丢包隐藏技术,位于接收端,也即解码端;解码端根据历史语音帧,对其进行信号分析,通过线性预测系数进行 LPC 建模,来预测丢失的语音帧,这项技术的可行性是基于语音的短时语音相似性。
其优点是,不占用额外带宽;PLC 技术可以处理较小的丢包率(<15%)。
NetEQ 中的丢包隐藏是根据上一语音帧的线性预测系数 PLC 来建模,根据历史语音信号重建语音信号然后加载一定的随机噪声;
连续丢包隐藏时,均使用同一个线性预测系数 LPC 重建语音信号,注意这⾥需要减少连续重建信号间的相关性,因此丢包隐藏产生的数据包能量递减;
最后为了语音连续,需要做平滑处理。当需要进行丢包补偿时,从存储最近 70ms 的语音缓冲区中取出最新的一帧数据并计算该帧的 LPC 系数即可
WebRTC 的 NetEQ 模块和 OPUS 解码器都具有 PLC 的功能,要是 Decoder 支持 PLC,优先使用解码器的 PLC 功能,否则使用 NetEQ 的 PLC 功能,下一篇文章在介绍 NetEQ 模块时,会进行较详细说明。
编码器 OPUS 抗弱网特性[7]
OPUS 不但是开源且无专利的编解码器, 而且相比其它编解码器来说,性能十分优越。这也是 WebRTC 音频通常使用它的原因。
下面对 OPUS 的一些特性进行说明,这些特性在对抗弱网上都有非常大的帮助。
⽀持全频带带宽
OPUS 支持的码率可以从窄带 6kbps 到⾼品质立体声 510kbps,下面这幅图说明 OPUS 从窄带到高品质宽带都能覆盖,且相同码率下,品质更高。
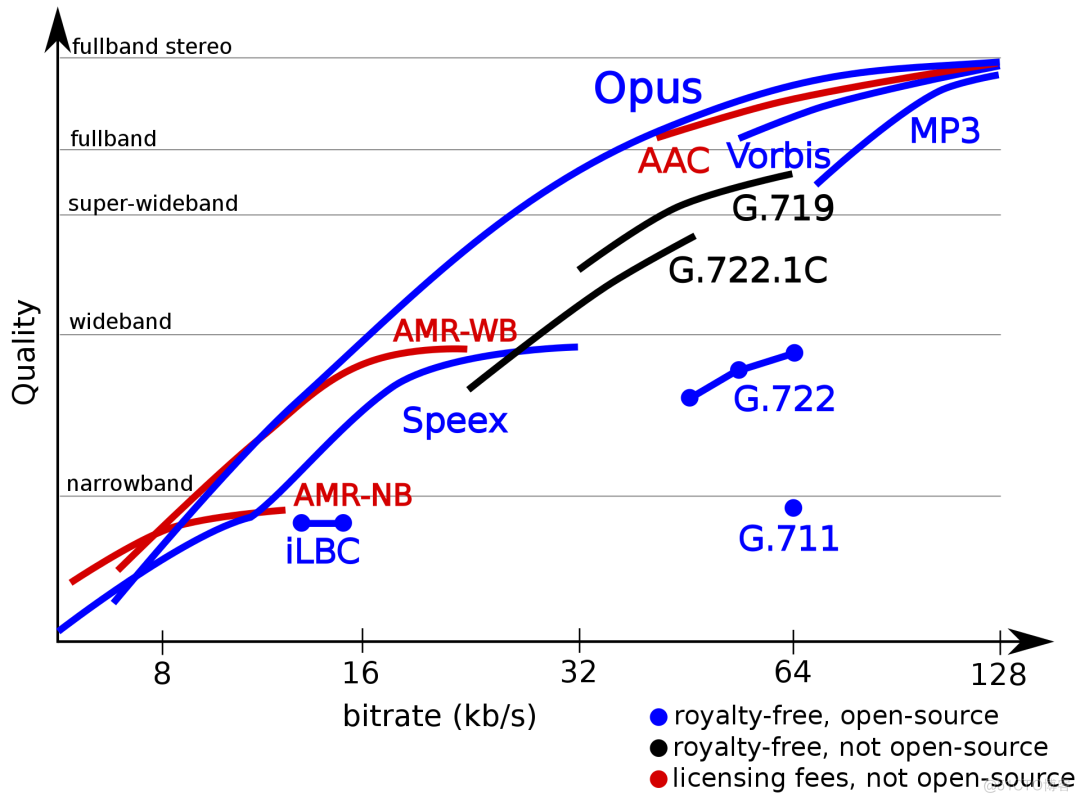
图说
OPUS 支持动态码率调准
可以无缝调节码高低,同等码率下,OPUS 的音效品质更高;同时在丢包情况下,当丢包率大于一定范围时,会将编码模式转换成为 SILK 模式,即低码率模式,以适应网络情况。
OPUS 延时更低
OPUS 结合了两种编解码技术,SILK(用于语音)和CELT(用于音乐),具有低延迟优势。
这对于用作低延迟音频通信链路的一部分是必不可少的, OPUS 可以以牺牲语音质量为代价将算法延迟减少到 5 毫秒。
现有的音乐编解码器(例如 MP3、Vorbis 和 HE-AAC)具有 100 毫秒或更多的延迟,而 OPUS 的延迟要低得多,但在质量上与比特率相当,如下图所示:
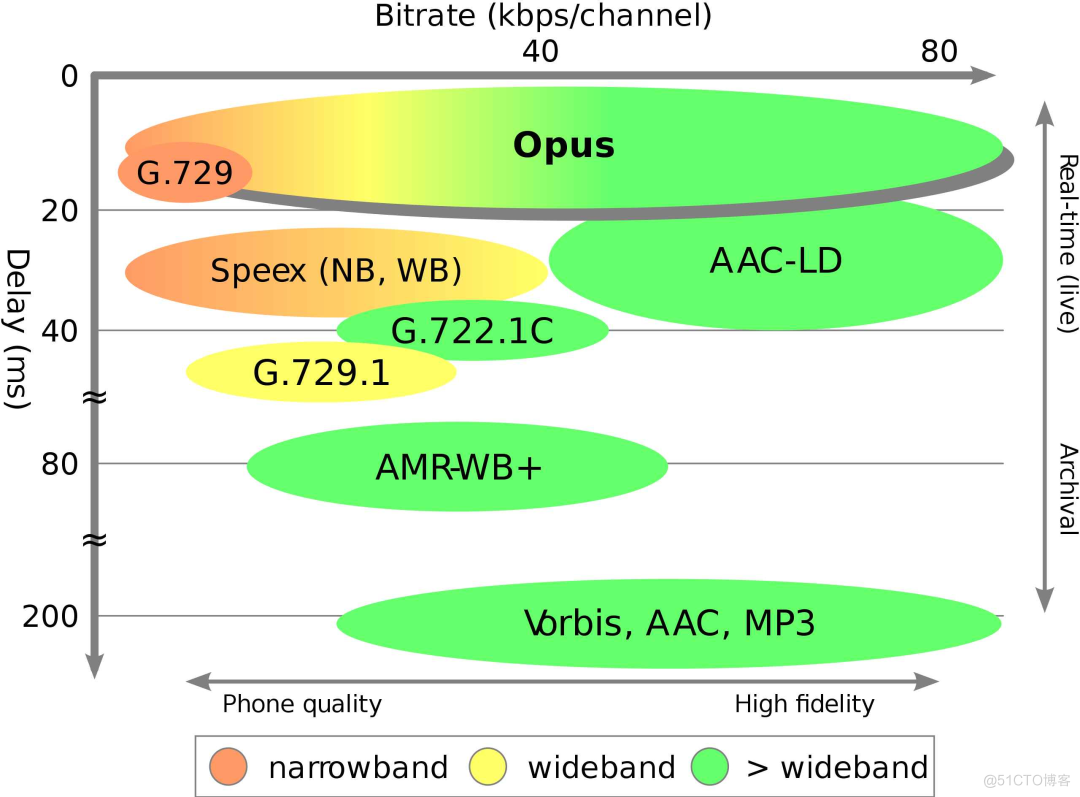
图说
OPUS 支持带内 FEC
OPUS 支持带内 FEC 功能,在使用 FEC 后,可以根据丢包率来生成冗余包,提高音频的抗丢包能力。
OPUS 的带内 FEC 功能使用方式类似 RED 方法,即发送当前包时,会携带上一个包的内容,只不过是上一个包是使用低码率编码来产生冗余包的,类似下面的方式:
|1| | -> |2|1| -> |3|2| -> |4|3| -> |5|4| -> |6|5|
下面是 OPUS 和 FEC 相关的几个接口:
这里需要指出的是,OPUS 内置的 FEC 包只在 SILK 模式下生成,CELT 编码模式下是不生成冗余包的。
WebRTC 中 FEC 的功能开启是通过 SDP 协商来完成的,如下所示:
下图是 OPUS 开启 FEC 和没开启 FEC 的效果对比图[8]
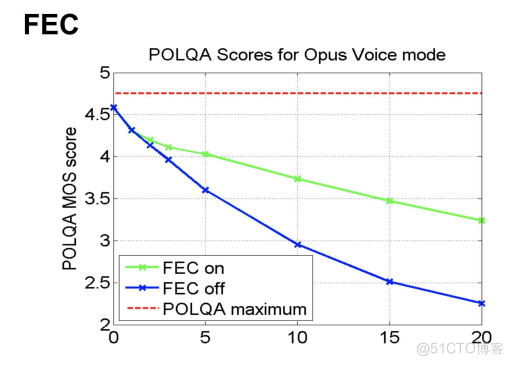
图说
从图中可以看出,FEC 开启后,在 20% 丢包情况下,音频 MOS 值提升还是非常明显的。
OPUS 解码端支持 PLC
OPUS 解码端支持丢包隐藏,其原理是根据语音信号具有短时相似性的特点,利用上一帧正常或恢复的语音信号,对其进行信号分析,重建和预测当前丢失的语音帧。
OPUS 语音功能支持 DTX
当不是音乐模式时,即在 VoIP 模式下,当检测到某个时间期间内没有说话声时,为了节省带宽,可以将开启 DTX。
这个时候,在没有检测到通话声音时,OPUS 会定期 400ms 发送静音包,达到降低带宽的目的,WebRTC 默认没有开启这个特性,要开启 DTX,只需要 SDP 协商时,在 a=ftmp 这一行中加入 usedtx=1 即可开启。
OPUS 本⾝具有很多抗弱网的特性,这些特性再配合丢包重传,可以使音频具备很强的抗弱网能力。
本文主要结合实际弱网处理工作经验,从前向纠错、后向纠错及 OPUS 编码器本身特性等方面,对音频弱网一些常用技术做简要说明和总结。
弱网处理还有一个关键的抗抖动技术,将在该系列的下一篇文章中详细介绍。
参考资料:
[1]: https://datatracker.ietf.org/doc/html/rfc5109
[2]: https://datatracker.ietf.org/doc/html/draft-ietf-payload-flexible-fec-scheme-03
[3]: https://tex2e.github.io/rfctranslater/html/rfc5510.html
[4]: https://www.scirp.org/pdf/6-2.16.pdf
[5]: https://datatracker.ietf.org/doc/html/rfc2198
[6] https://tex2e.github.io/rfc-translater/html/rfc4585.html
[7]: https://ja.wikipedia.org/wiki/OPUS_(%E9%9F%B3%E5%A3%B0%E5%9C%A7%E7%B8%AE)
[8]: https://www.OPUScodec.org/static/presentations/OPUS_voice_aes135.pdf
边栏推荐
- Data connection mode in low code platform (Part 2)
- 【立体匹配论文阅读】【三】INTS
- NLLB-200:Meta开源新模型,可互译200种语言
- Reverse non return to zero code, Manchester code and differential Manchester code of common digital signal coding
- C# 6.0 语言规范获批
- c#利用 TCP 协议建立连接
- oracle 非自动提交解决
- MicTR01 Tester 振弦采集模塊開發套件使用說明
- Mlgo: Google AI releases industrial compiler optimized machine learning framework
- leetcode:648. 单词替换【字典树板子 + 寻找若干前缀中的最短符合前缀】
猜你喜欢

云上“视界” 创新无限 | 2022阿里云直播峰会正式上线
Huawei cloud database DDS products are deeply enabled

UML state diagram
Reverse non return to zero code, Manchester code and differential Manchester code of common digital signal coding
The world's first risc-v notebook computer is on pre-sale, which is designed for the meta universe!
Substance painter notes: settings for multi display and multi-resolution displays
Selenium Library

The longest ascending subsequence model acwing 1012 Sister cities

Navigation — 这么好用的导航框架你确定不来看看?
MRS离线数据分析:通过Flink作业处理OBS数据
随机推荐
寺岗电子称修改IP简易步骤
Leetcode one question per day (636. exclusive time of functions)
CVPR2022 | 医学图像分析中基于频率注入的后门攻击
Attribute keywords ondelete, private, readonly, required
Oracle Linux 9.0 officially released
【愚公系列】2022年7月 Go教学课程 005-变量
C# 6.0 语言规范获批
课设之百万数据文档存取
GAN发明者Ian Goodfellow正式加入DeepMind,任Research Scientist
JS image to Base64
bashrc与profile
Navigation - are you sure you want to take a look at such an easy-to-use navigation framework?
Source code analysis of ArrayList
Half an hour of hands-on practice of "live broadcast Lianmai construction", college students' resume of technical posts plus points get!
Equipment failure prediction machine failure early warning mechanical equipment vibration monitoring machine failure early warning CNC vibration wireless monitoring equipment abnormal early warning
c#利用 TCP 协议建立连接
找到自己的价值
Oracle Linux 9.0 正式发布
2022PAGC 金帆奖 | 融云荣膺「年度杰出产品技术服务商」
多商戶商城系統功能拆解01講-產品架構