当前位置:网站首页>How to make join run faster?
How to make join run faster?
2022-07-07 13:22:00 【Little white who loves programming】
JOIN It has always been a difficult problem of database performance optimization , Originally very fast query , Once several are involved JOIN, Performance will drop sharply . and , Participate in JOIN The bigger the watch, the more , The harder it is to improve performance .
Actually , Give Way JOIN The key to running fast is to be right JOIN classification , After classification , You can use all kinds of JOIN Performance optimization based on the characteristics of .
List of articles
JOIN classification
Yes SQL Students with development experience know , most JOIN It's all equivalent JOIN, That is, if the correlation condition is equal JOIN. non-equivalence JOIN Much less common , And in most cases, it can also be converted into equivalent JOIN To deal with it , So we can just talk about equivalence JOIN.
equivalence JOIN It can be divided into two main categories : Foreign key Association and primary key Association .
Foreign key association refers to the use of non primary key fields of a table , To associate the primary key of another table , The former is called the fact table , The latter is dimension table . As shown in the picture below , The order form is the fact form , Customer list 、 Product list 、 An employee table is a dimension table .
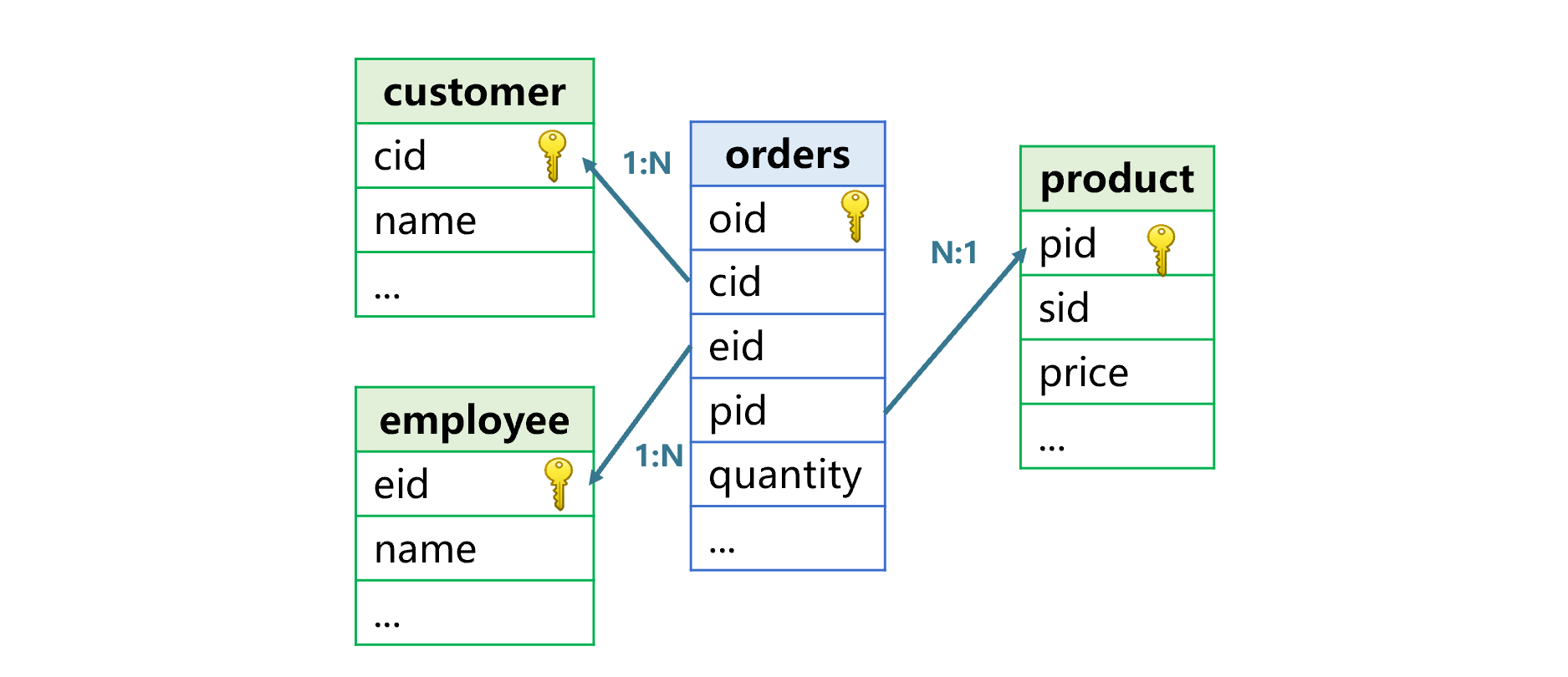
Foreign key tables are many to one relationships , And it is asymmetric , The positions of fact table and dimension table cannot be interchanged . It should be noted that , The primary key here refers to the logical primary key , That is, the value in the table is unique 、 A field that can be used to uniquely identify a record ( Or field group ), You may not have established a primary key on the database table .
Primary key association refers to associating the primary key of one table with the primary key or part of the primary key of another table . For example, customers and VIP Customer 、 Association between order table and order details .
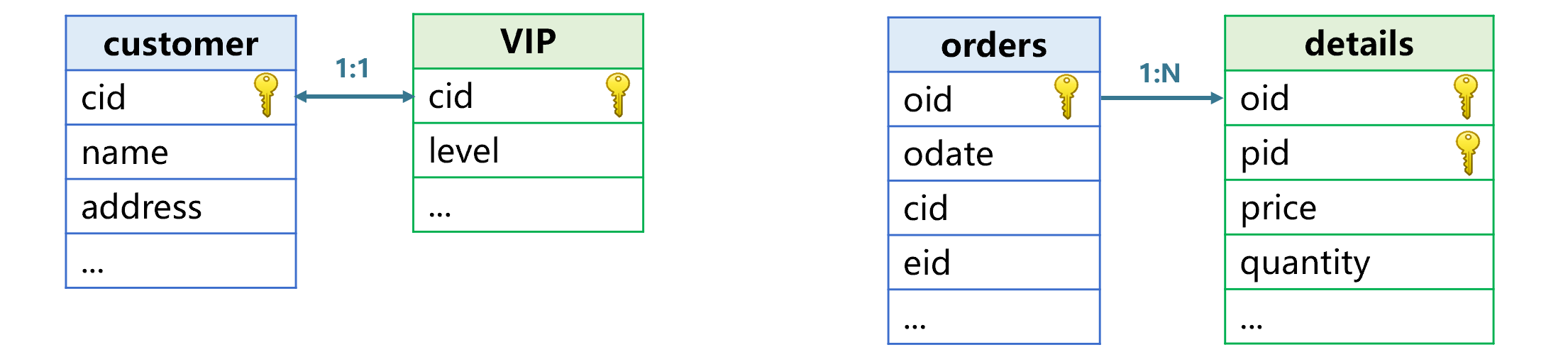
The customer and VIP Customers are associated by primary key , These two tables are of the same dimension as each other . Orders use primary keys to associate part of the primary keys of details , We call the order table the main table , A schedule is a sub table .
The same dimension table is a one-to-one relationship . And the same dimension tables are symmetrical , The two tables have the same status . The primary sub table is a one to many relationship , And it is asymmetric , There is a clear direction .
A close look will reveal , These two types of JOIN all The primary key is involved 了 . Without involving the primary key JOIN Can lead to many to many relationships , In most cases, it doesn't make business sense . let me put it another way , These two categories JOIN It covers almost all business meaningful JOIN. If we can take advantage of JOIN The primary key feature is always involved in performance optimization , Can solve these two categories JOIN, In fact, it means solving most JOIN Performance issues .
however ,SQL Yes JOIN The definition of does not involve primary keys , Only two tables do Cartesian product and then filter according to some conditions . This definition is simple and broad , Can describe almost everything . however , If we implement it strictly according to this definition JOIN, There is no way to use the characteristics of primary key in performance optimization .
SPL Changed the JOIN The definition of , Specifically for these two categories JOIN Deal with... Separately , The feature of primary key is used to reduce the amount of computation , So as to achieve the goal of performance optimization .
Let's take a look at SPL How to do it .
Foreign key link
If the fact table and dimension table are not too large , Can be fully loaded into memory ,SPL Provides Foreign key addressing Method : First, convert the foreign key field value in the fact table to the address of the corresponding dimension table record , When referencing dimension table fields later , Just take out the address .
Take the previous order form 、 Take the employee list as an example , Assume that these two tables have been read into memory . The working mechanism of foreign key addressing is as follows : For a record in the order form r Of eid Field , Find this in the employee list eid The record corresponding to the field value , Get its memory address a, then r Of eid Replace the field value with a. Do this conversion for all records in the order table , The foreign key addressing is completed . Now , Order form record r When you want to reference an employee table field , Direct use eid The address stored in the field a Just take out the employee table records and fields , It is equivalent to obtaining the fields of the employee table in a constant time , You don't need to look up the employee table again .
The fact table and dimension table can be read into memory when the system is started , And address foreign keys at one time , namely Pre Association . such , In the subsequent association calculation, you can directly use the address in the foreign key field of the fact table to get the dimension table records , Complete high performance JOIN Calculation .
For the detailed principles of foreign key addressing and pre Association, please refer to :【 performance optimization 】6.1 [ Foreign key link ] Foreign key addressing
SQL Usually use HASH Algorithm to do memory connection , Need to compute HASH Value and comparison , The performance will be much worse than reading directly from the address .
SPL The reason why foreign key addressing can be realized , It makes use of the feature that the associated field of the dimension table is the primary key . In the example above , Correlation field eid Is the primary key of the employee table , Have uniqueness . Every... In the order form eid There is only one employee record , That's why we can put every eid Convert to the address of the employee record that it uniquely corresponds to .
and SQL Yes JOIN There is no primary key convention in the definition of , You cannot assume that the dimension table records associated with foreign keys in the fact table are unique , It is possible to associate with multiple records . For the record of the order form ,eid There is no way to uniquely correspond to an employee record , You can't address foreign keys . and SQL There is no record of address data type , The result will be that each association still needs to be calculated HASH Value and compare .
Just two watches JOIN when , Foreign key addressing and HASH The difference in correlation is not very obvious . This is because JOIN It's not the ultimate goal ,JOIN There will be many other operations ,JOIN The proportion of operation time consumed by itself is relatively small . But fact tables often have multiple dimension tables , Even dimension tables have many layers . For example, order related products , Product related suppliers , Supplier's associated city , City related countries and so on . When there are many associated tables , The performance advantage of foreign key addressing will be more obvious .
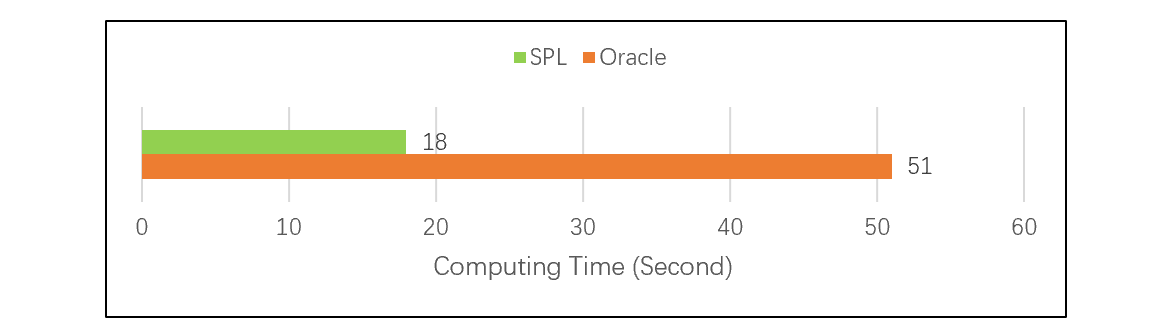
The following test , Compare when the number of associated tables is different SPL And Oracle The difference in performance , It can be seen that when there are many tables , The advantage of foreign key addressing is quite obvious :
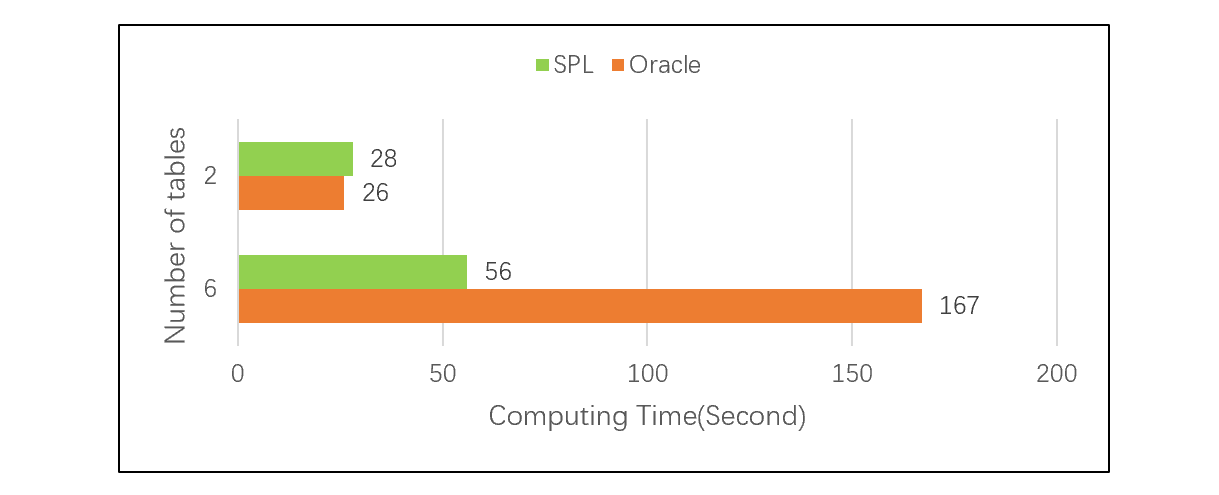
For details of the test, please refer to : Performance optimization techniques : Pre Association .
Only dimension tables can be loaded into memory , The fact table is very large and needs external storage ,SPL Provides Foreign key serialization Method : Convert the foreign key field value in the fact table into the serial number of the corresponding record in the dimension table in advance . Correlation calculation , Read in new fact sheet records in batches , Then take out the corresponding dimension table record with serial number .
Based on the above order form 、 Take the product list as an example , Assume that the product table has been loaded into memory , The order table is stored in external storage . The process of serialization of foreign keys is like this : First read in a batch of order data , Set one of the records r Medium pid It corresponds to the... Of the product table in memory i Bar record . We're going to r Medium pid Convert field values to i. After such conversion is completed for this batch of order records , When doing correlation calculation again , Read order data in batches from external storage . For the records r, It can be directly based on pid value , Go to the product table in the memory and take out the corresponding record with the location , It also avoids the search action .
For a more detailed introduction to the principle of foreign key serialization, please refer to :【 performance optimization 】6.3 [ Foreign key link ] Foreign key serialization .
Databases usually read small tables into memory , Then read in the big table data in batches , Use hash algorithm to make memory connection , You need to calculate the hash value and compare . and SPL Using serial number positioning is to read directly , No comparison is required , The performance advantages are obvious . Although it takes some cost to convert the foreign key field of the fact table into serial number in advance , But this pre calculation only needs to be done once , And it can be reused in multiple foreign key associations .
SPL The serialization of foreign keys also makes use of the feature that the associated fields of dimension tables are primary keys . As mentioned earlier ,SQL Yes JOIN There is no primary key convention in the definition of , This feature cannot be used to serialize foreign keys . in addition ,SQL Using the concept of unordered sets , Even if we serialize the foreign keys in advance , Databases can't take advantage of this feature , The mechanism of rapid sequence number positioning cannot be used on unordered sets , The fastest way is to use the index to find . and , The database doesn't know that foreign keys are serialized , Still calculate HASH Value and comparison .
The following test , In the case of different parallel numbers , contrast SPL and Oracle Complete the list of major events 、 The speed of small dimension table Association calculation ,SPL Running ratio Oracle fast 3 To 8 times . The test results are shown in the figure below :
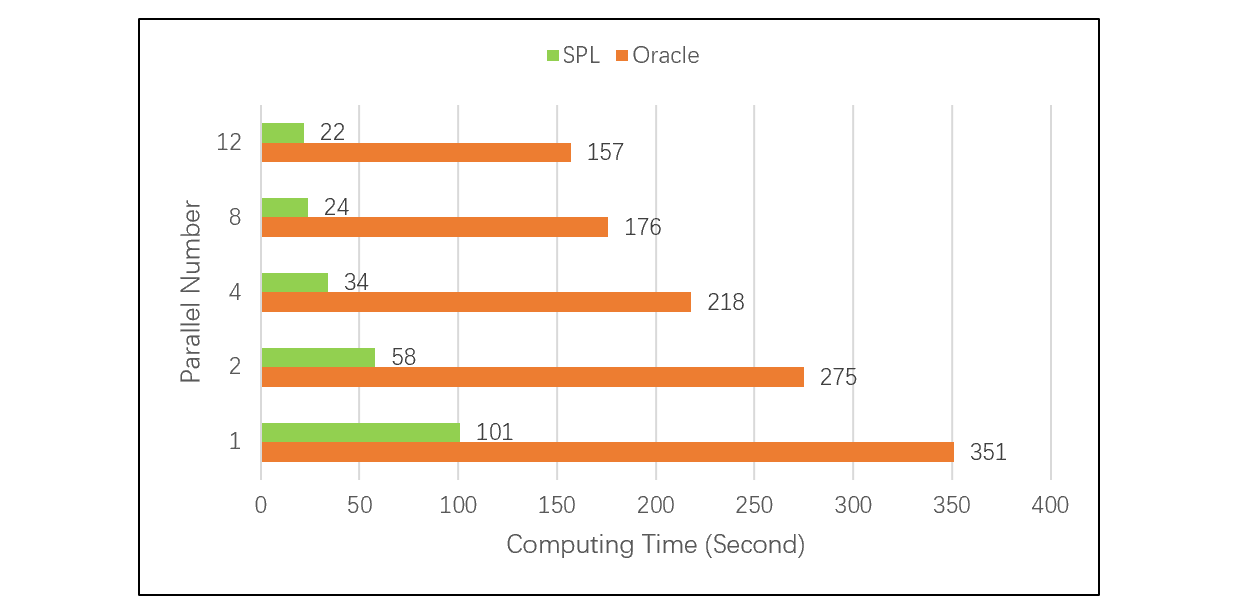
For more detailed information about this test, please refer to : Performance optimization techniques : Foreign key serialization .
If the dimension table is large, it also needs external storage , The fact table is small and can be loaded into memory ,SPL It provides Large dimension table lookup Mechanism . If both the dimension table and the fact table are large ,SPL Then use Unilateral heap splitting algorithm . For dimension table filtering and then Association ,SPL Provides Index reuse The method and Contraposition sequence Other methods .
When the amount of data is large enough to require distributed computing , If the dimension table is small ,SPL use Copy dimension table Mechanism , Copy the dimension table to multiple copies on the cluster node ; If the dimension table is large , Then Cluster dimension table Method to ensure random access . Both methods can effectively avoid Shuffle action . Compared with ,SQL The dimension table cannot be distinguished under the system ,HASH The splitting method needs to make both tables Shuffle action , The amount of network transmission is much larger .
The primary key link
The tables involved in primary key association are generally large , Need to be stored in external memory .SPL This provides Orderly merge Method : Store the external storage table in order according to the primary key in advance , When associating, take out the data in sequence for merging calculation .
With customers and VIP Take the internal connection between two tables of the customer as an example , Suppose you have pre - placed two tables by primary key cid Orderly storage in external memory . When connected , Read records from cursors of two tables , Compare... One by one cid value . If cid equal , Merge the records of the two tables into one record of the result cursor and return . If it's not equal , be cid The small cursor reads the record again , Continue to judge . Repeat these actions until the data of any table is fetched , The cursor returned is JOIN Result .
For two large table associations , Databases usually use hash heap splitting algorithm , Complexity is multiplicative . The complexity of ordered merging algorithm is additive , The performance will be much better . and , When the database performs external memory operation of big data , Hash heap splitting will produce read and write actions of cache files . The ordered merging algorithm only needs to traverse the two tables in turn , No need to use external memory cache , Can be significantly reduced IO The amount , It has great performance advantages .
Although the cost of sorting by primary key in advance is high , But it can be done at one time , In the future, we can always use the merging algorithm to realize JOIN, Performance can be improved a lot . meanwhile ,SPL It also provides a scheme to maintain the overall order of the data when there is additional data .
This kind of JOIN It is characterized in that the associated fields are primary keys or partial primary keys , The ordered merging algorithm is designed according to this feature . Because whether it's the same dimension table or the master sub table , The associated fields will not be fields other than the primary key , Therefore, we can sort and store the associated tables in order according to the primary key , There will be no redundancy . Foreign key associations do not have this feature , Ordered merging cannot be used . say concretely , Because the associated field of the fact table is not a primary key , There will be multiple foreign key fields to participate in the Association , We can't make the same fact table ordered by multiple fields at the same time .
SQL Yes JOIN The definition of does not distinguish JOIN type , Don't assume that some JOIN Always for primary keys , There is no way to use the characteristics of primary key Association at the algorithmic level . and , As I said before SQL Based on the concept of unordered set , The database will not deliberately ensure the physical order of data , It is difficult to implement an ordered merging algorithm .
The advantage of ordered merging algorithm is that it is easy to segment and parallel . By order and order details oid Take Association as an example , If the two tables are roughly divided into... According to the number of records 4 paragraph , Order No 2 Part of the oid It may appear in the... Of the details 3 paragraph , Similar misalignment can lead to incorrect calculation results .SPL Use the primary key again oid The order of , Provide synchronous segmentation mechanism , That solved the problem : First, divide the ordered order form into 4 paragraph , Then find the beginning and end records of each paragraph oid Values form 4 Intervals , The schedule is also divided into synchronized 4 paragraph . such , In parallel computing, the corresponding segments of the two tables will not be misplaced . Because the schedule is also applicable to oid Orderly , You can quickly follow the start and end oid location , Does not reduce the performance of ordered merging .
The principle of orderly merging and synchronous piecewise parallelism , See :SPL Ordered merge Association .
Conventional HASH It is more difficult to realize parallelism with heap splitting technology , Multithreading does HASH When splitting the heap, you need to write data to a certain heap at the same time , Cause shared resource conflict ; In the next step, a large amount of memory will be consumed when implementing a component heap Association , A large number of parallels cannot be implemented .
The actual test proves that , In the same case , Let's do a primary key association test on two large tables ( For details, see Performance optimization techniques : Orderly merge ), The result is SPL Than Oracle It's getting close 3 times :
In addition to orderly merging ,SPL It also provides many high-performance algorithms , Comprehensively improve the primary key Association JOIN The calculation speed of . Include : Schedule Mechanism , Multiple tables can be stored integrally , While reducing the amount of data stored , It is also equivalent to completing the association in advance , There's no need to compare ; Association location Algorithm , Filter first and then associate , Can avoid full table traversal , Get better performance and so on .
When the amount of data continues to increase , When multiple server clusters are required ,SPL Provide Compound table Mechanism , Distribute the large tables to be associated to the cluster nodes according to the primary key . Data with the same primary key is on the same node , Avoid data transmission between extensions , It's not going to happen Shuffle action .
Review and summarize
Review the above two categories 、 Scenes JOIN, use SPL High performance algorithm provided by case , Different types of JOIN Features speed up , Give Way JOIN Run faster .SQL For so many of the above JOIN General treatment of the scene , There's no way to be different JOIN To implement these high-performance algorithms . such as : When both fact and dimension tables are loaded into memory ,SQL Can only be calculated by key value HASH And comparison , Can't use address to directly correspond to ;SQL The data table is out of order , When large tables are associated according to the primary key, they cannot be merged orderly , Only use HASH Stacking , There may be multiple caches , The performance is uncontrollable .
Parallel computing ,SQL It is also easy to achieve piecewise parallelism in single table calculation , Generally, fixed segmentation can only be done in advance during multi table association operation , It is difficult to achieve synchronous dynamic segmentation , This makes it difficult to temporarily determine the number of parallels according to the load of the machine .
The same is true for cluster operations ,SQL In theory, we do not distinguish between dimension table and fact table , To achieve large tables JOIN It will inevitably take up a lot of network resources HASH Shuffle action , When the number of cluster nodes is too large , The delay caused by network transmission will outweigh the benefits of more nodes .
SPL A new computing and storage model is designed and applied , It can be solved in principle and implementation SQL These problems of . about JOIN Different categories and scenarios , Programmers adopt the above high-performance algorithms , You can get faster computing speed , Give Way JOIN Run faster .
SPL Information
Welcome to SPL Interested assistant (VX Number :SPL-helper), Into the SPL Technology exchange group
边栏推荐
- 【黑马早报】华为辟谣“军师”陈春花;恒驰5预售价17.9万元;周杰伦新专辑MV 3小时播放量破亿;法华寺回应万元月薪招人...
- MongoDB命令汇总
- Adopt a cow to sprint A shares: it plans to raise 1.85 billion yuan, and Xu Xiaobo holds nearly 40%
- MongoDB内部的存储原理
- 飞桨EasyDL实操范例:工业零件划痕自动识别
- Sequoia China completed the new phase of $9billion fund raising
- 如何让join跑得更快?
- 如何让electorn打开的新窗口在window任务栏上面
- Storage principle inside mongodb
- [etc.] what are the security objectives and implementation methods that cloud computing security expansion requires to focus on?
猜你喜欢

![[untitled]](/img/6c/df2ebb3e39d1e47b8dd74cfdddbb06.gif)


随机推荐
Why can basic data types call methods in JS
Cinnamon Applet 入门
Cloud detection 2020: self attention generation countermeasure network for cloud detection in high-resolution remote sensing images
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
API query interface for free mobile phone number ownership
[QNX Hypervisor 2.2用户手册]6.3.4 虚拟寄存器(guest_shm.h)
Practical case: using MYCAT to realize read-write separation of MySQL
【无标题】
存储过程的介绍与基本使用
clion mingw64中文乱码
【Presto Profile系列】Timeline使用
Mongodb command summary
JS缓动动画原理教学(超细节)
Lingyunguang of Dachen and Xiaomi investment is listed: the market value is 15.3 billion, and the machine is implanted into the eyes and brain
单片机原理期末复习笔记
JS中为什么基础数据类型可以调用方法
Aosikang biological sprint scientific innovation board of Hillhouse Investment: annual revenue of 450million yuan, lost cooperation with kangxinuo
My "troublesome" subordinates after 00: not bad for money, against leaders, and resist overtime
MySQL master-slave replication
leecode3. 无重复字符的最长子串