当前位置:网站首页>Redis集群与扩展
Redis集群与扩展
2022-07-07 16:49:00 【一个正在努力的菜鸡】
Redis的高可用
1.为什么要高可用
- 防止单点故障,造成整个集群不可用
- 实现高可用通常的做法是将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务
- Redis实现高可用有三种部署模式:主从模式,哨兵模式,集群模式
2.主从模式
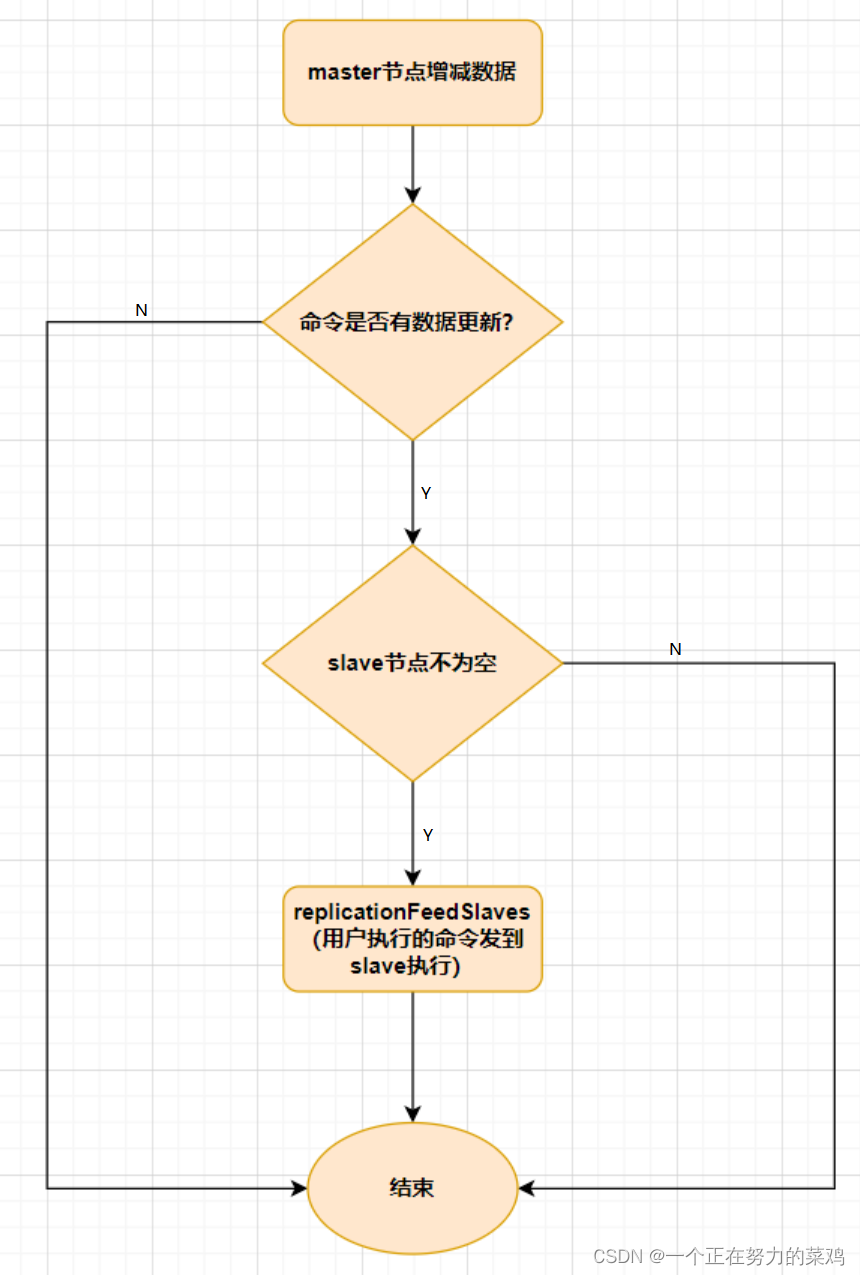
- 主节点负责读写操作
- 从节点只负责读操作
- 从节点的数据来自主节点,实现原理就是主从复制机制
- 主从复制包括全量复制,增量复制两种
- 当slave第一次启动连接master,或者认为是第一次连接就采用全量复制
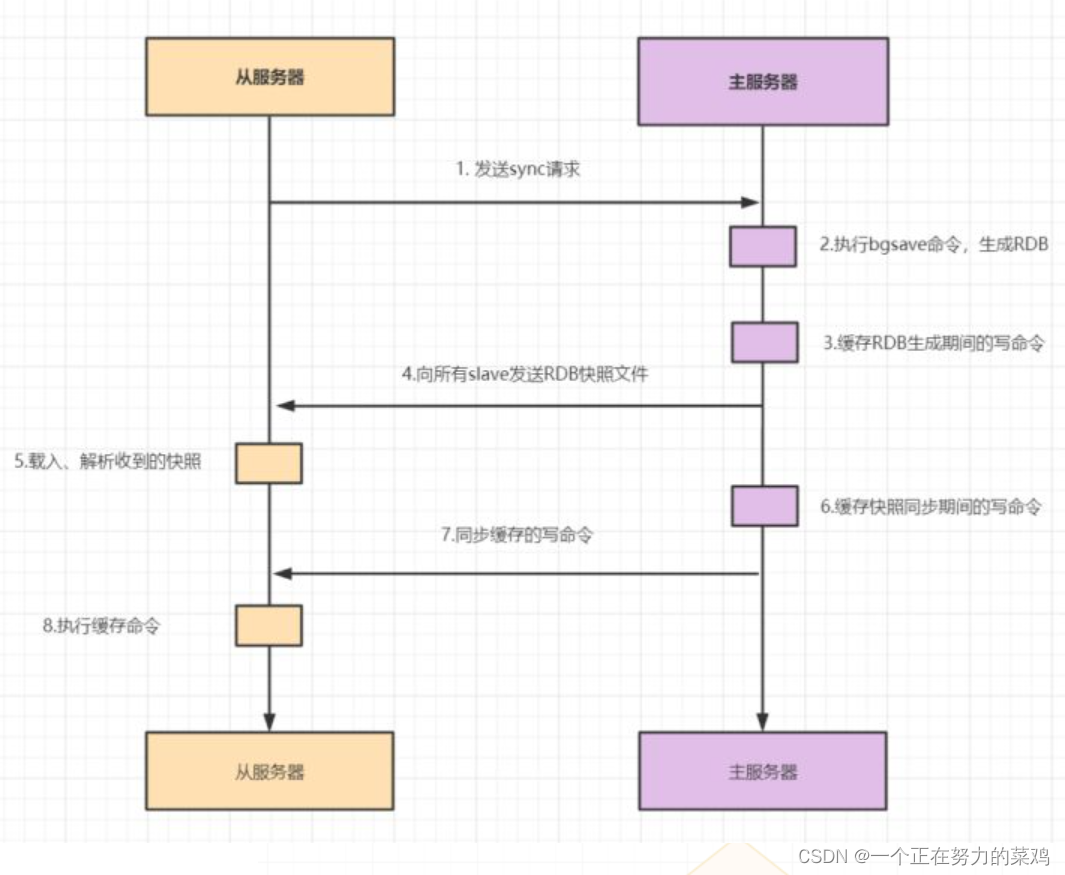
- slave与master全量同步之后,master上的数据如果再次发生更新,就会触发增量复制
3.哨兵模式
- 主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,显然多数业务场景都不能接受这种故障处理方式,Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题
- 哨兵模式是由一个或多个Sentinel实例组成的Sentinel系统,可以监视所有的Redis主节点和从节点,并在被监视的主节点进入下线状态时自动将下线主服务器属下的某个从节点升级为新的主节点
- 但是一个哨兵进程对Redis节点进行监控,就可能会出现问题(单点),因此可以使用多个哨兵来进行监控Redis节点,并且各个哨兵之间还会进行监控
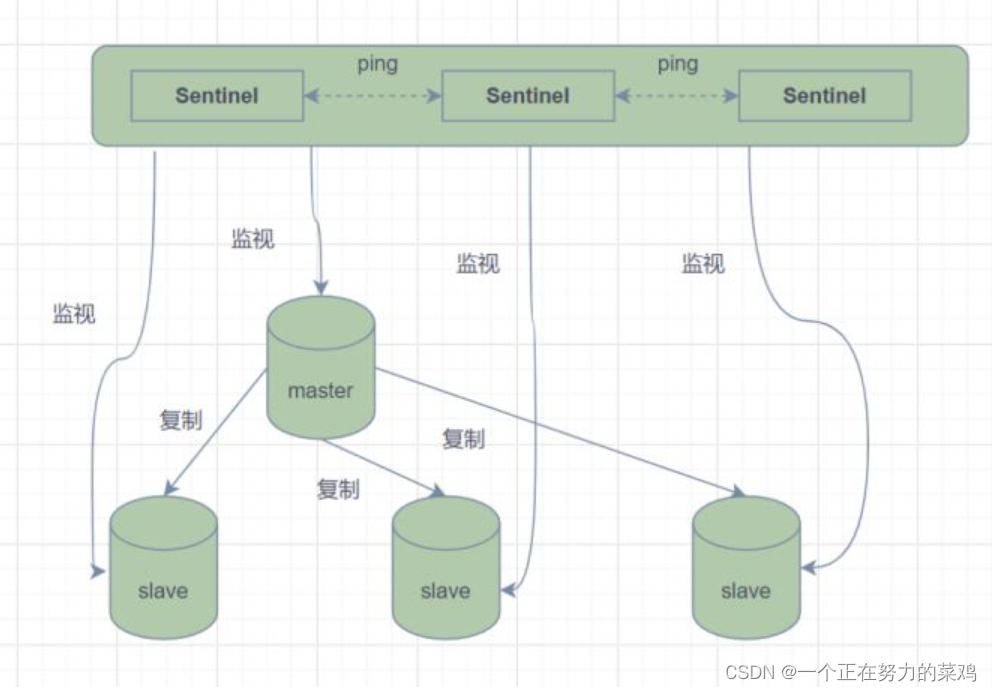
- 简单来说,哨兵模式就三个作用
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态
2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机
3.哨兵之间还会相互监控,从而达到高可用
- 故障切换过程如下
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线
当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作
切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线
这样对于客户端而言,一切都是透明的
- 哨兵的工作模式
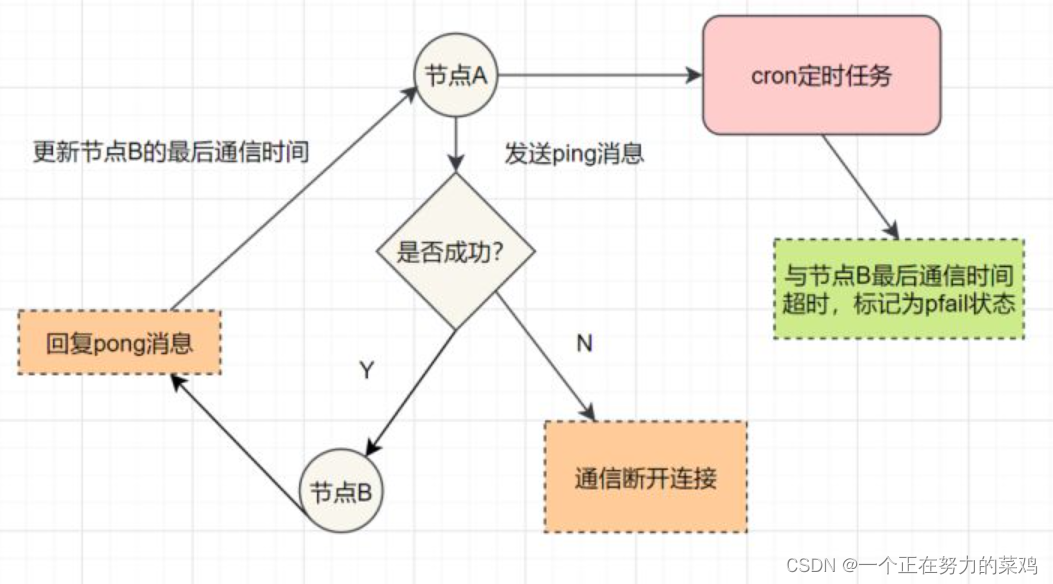
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令
如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线
如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态
当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线
一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令
当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次
若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
4.Cluster集群模式
- 哨兵模式基于主从模式,实现读写分离,还可以自动切换,系统可用性更高,但是它每个节点存储的数据是一样的,浪费内存,并且不好在线扩容,因此Cluster集群应运而生,它在Redis3.0加入的
- Cluster集群实现Redis的分布式存储,对数据进行分片,也就是说每台Redis节点上存储不同的内容,来解决在线扩容的问题,并且它也提供复制和故障转移的功能
- Redis Cluster集群通过Gossip协议进行通信,节点之间不断交换信息,交换的信息内容包括节点出现故障、新节点加入、主从节点变更信息、slot信息等等,常用的Gossip消息分别是ping、pong、meet、fail
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息
meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
- Hash Slot插槽算法
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法
插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个
使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽
集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有:
节点A负责0~5460号哈希槽
节点B负责5461~10922号哈希槽
节点C负责10923~16383号哈希槽
Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作
为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点
Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
5.实现高可用后的故障转移问题
- 主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况
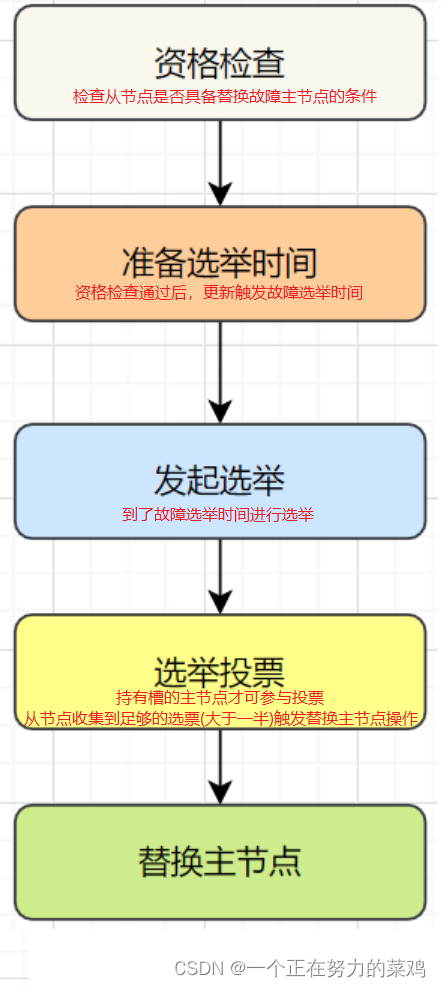
- 客观下线: 标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果,如果是持有槽的主节点故障,需要为该节点进行故障转移
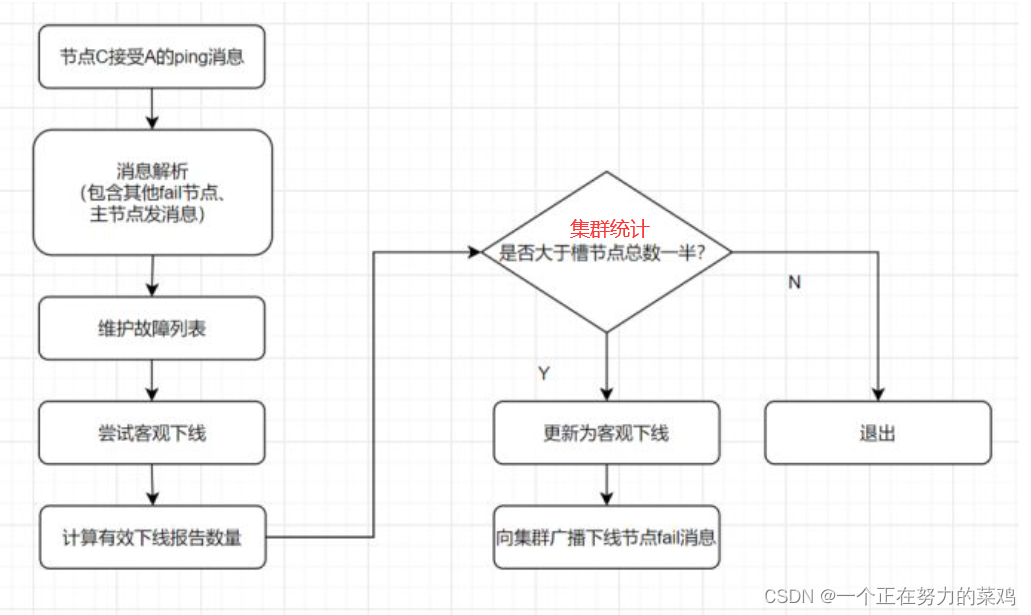
- 故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用
Redis分布式锁带来的系列问题及解决
1.Redisson
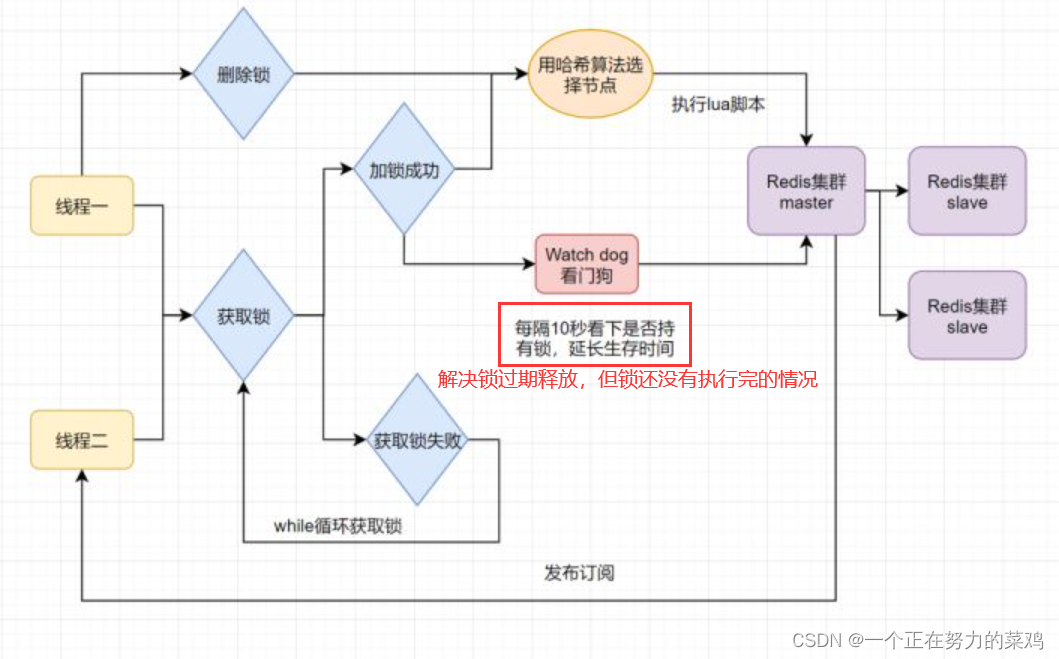
- 分布式锁可能存在锁过期释放,业务没执行完的问题
- 能不能将锁的过期时间设置得长点来解决此问题呢?显然是不太好的,业务的执行时间是不确定的
- Redisson解决该问题,给获得锁得线程开启定时守护线程,每隔一段时间检查锁是否存在,存在则延长锁的过期时间,防止锁过期提前释放
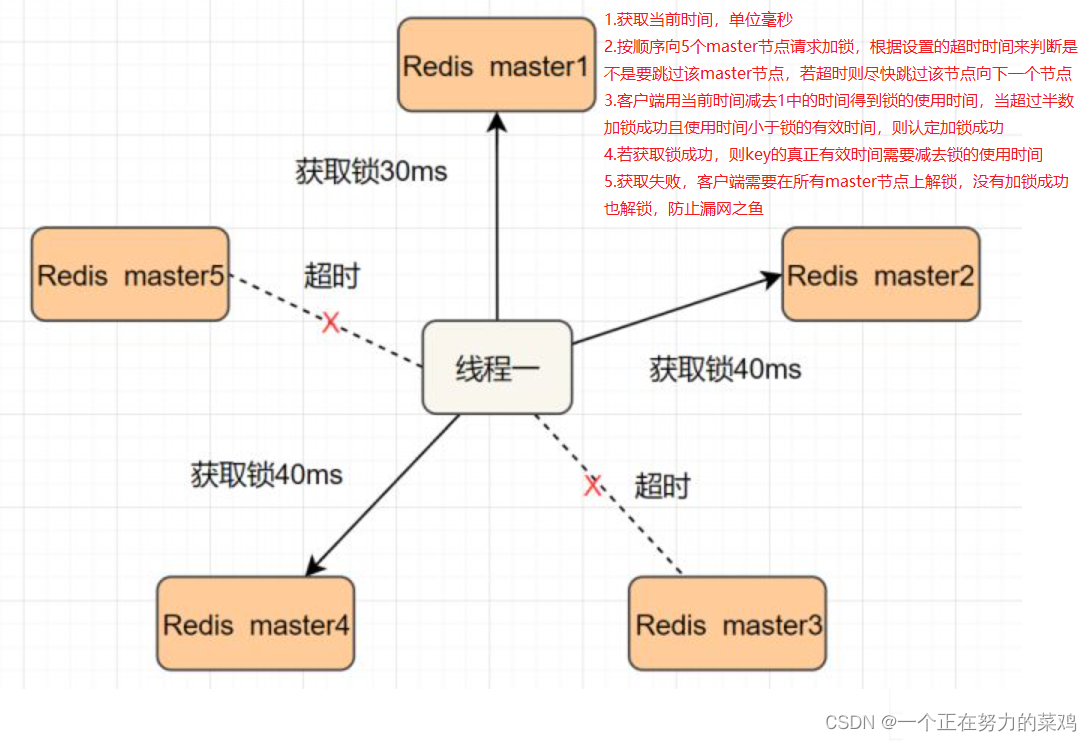
2.Redlock算法
- 线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点,恰好这时master节点发生故障,一个slave节点就会升级为master节点,线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了
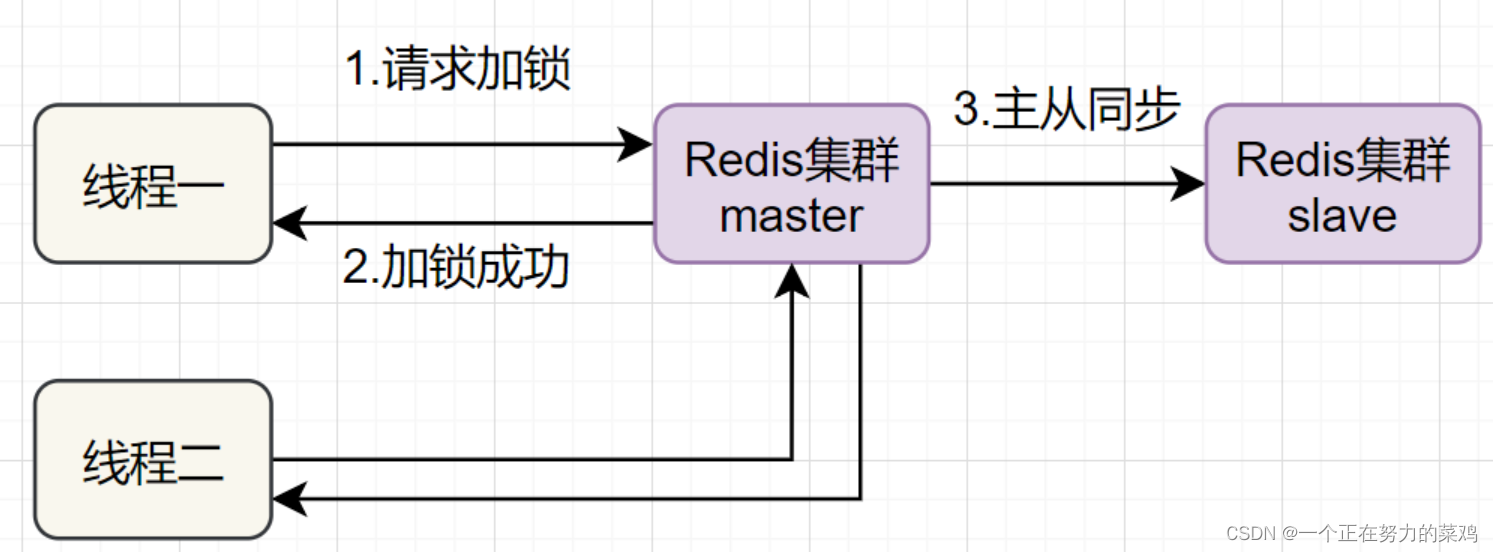
- Redlock解决这个问题,即部署多个Redis master以保证它们不会同时宕掉,并且这些master节点是完全相互独立的,相互之间不存在数据同步,实现步骤如下
MySQL与Redis如何保证双写一致性
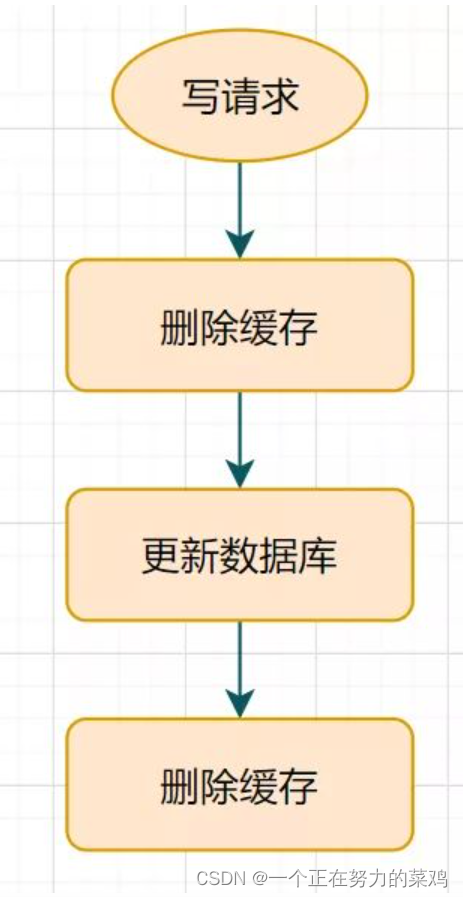
1.延时双删
- 更新数据库后延迟休眠一会再删除缓存
- 这种方案还可以,只有休眠那一会可能有脏数据,一般业务也会接受的
- 但是如果第二次删除缓存失败呢?缓存和数据库的数据还是可能不一致
- 给Key设置一个自然的expire过期时间,让它自动过期怎样?业务在该过期时间内接受的数据的不一致怎么办?还是有其他更佳方案
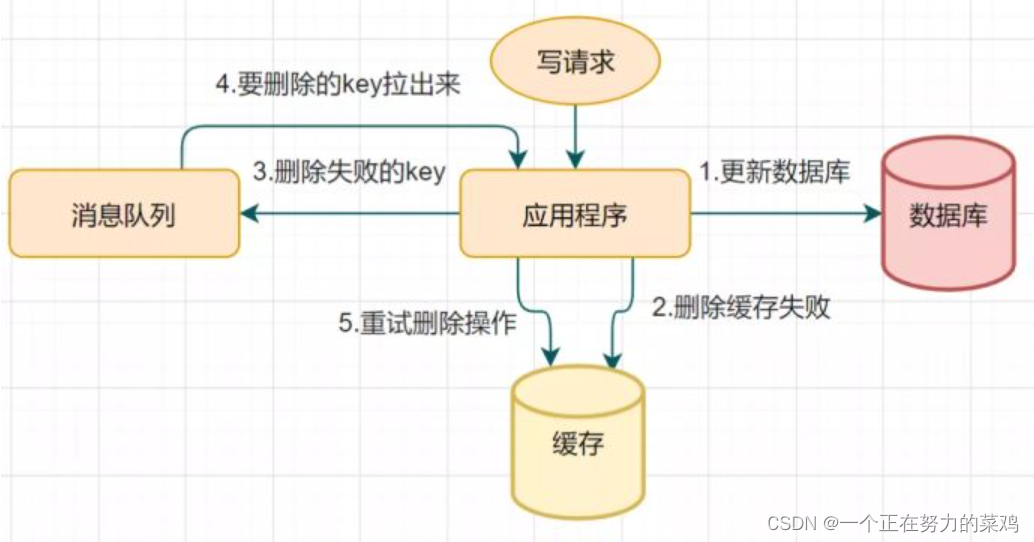
2.删除缓存重试机制
- 延时双删可能会存在第二步的删除缓存失败,导致的数据不一致问题
- 删除失败就多删除几次呀,保证删除缓存成功就可以了呀,所以可以引入删除缓存重试机制
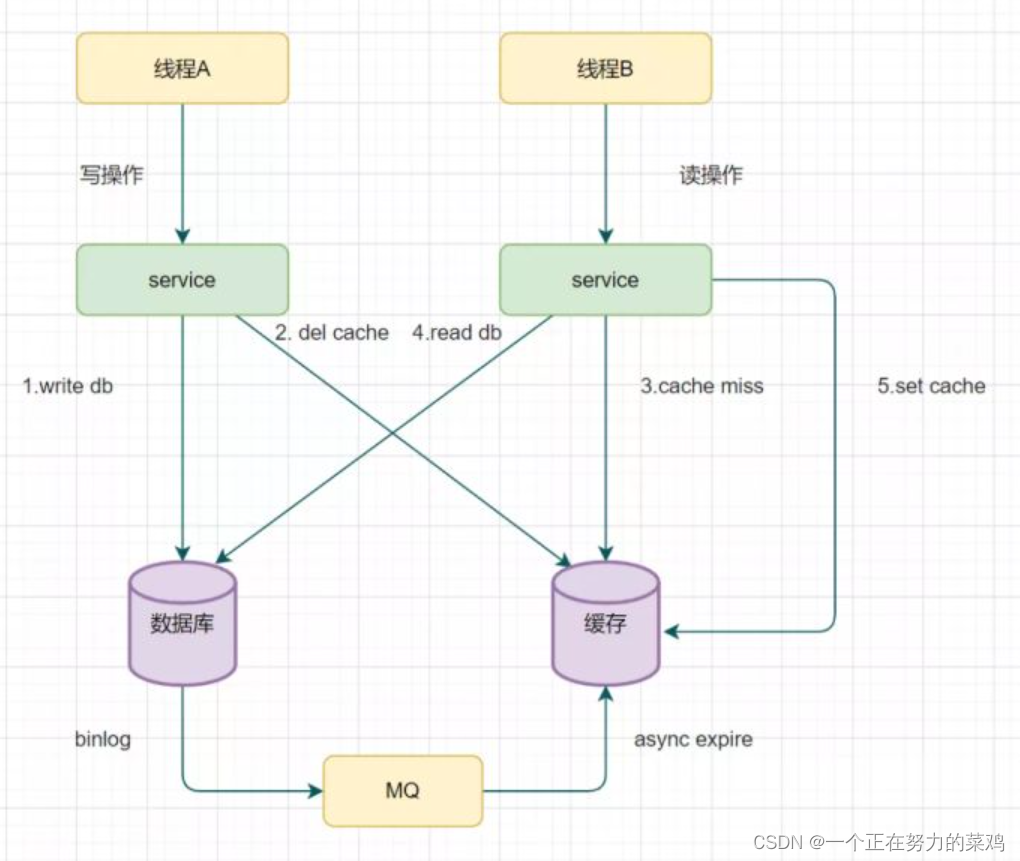
3.读取biglog异步删除缓存
- 重试删除缓存机制会造成好多业务代码入侵,所以引入读取biglog异步删除缓存
边栏推荐
- Introduction of common API for socket programming and code implementation of socket, select, poll, epoll high concurrency server model
- gsap动画库
- Kubernetes DevOps CD工具对比选型
- 高考填志愿规则
- 低代码助力企业数字化转型会让程序员失业?
- Will domestic software testing be biased
- Tips of this week 135: test the contract instead of implementation
- 线程池和单例模式以及文件操作
- Sports Federation: resume offline sports events in a safe and orderly manner, and strive to do everything possible for domestic events
- Kirk borne's selection of learning resources this week [click the title to download directly]
猜你喜欢
卖空、加印、保库存,东方甄选居然一个月在抖音卖了266万单书

Some key points in the analysis of spot Silver
保证接口数据安全的10种方案
NAT地址转换
What skills can you master to be a "master tester" when doing software testing?

元宇宙带来的创意性改变
Introduction de l'API commune de programmation de socket et mise en œuvre de socket, select, Poll et epoll
![Kirk borne's selection of learning resources this week [click the title to download directly]](/img/df/98aa3edf0a70b870684963d52e7c72.png)
Kirk borne's selection of learning resources this week [click the title to download directly]

【蓝桥杯集训100题】scratch从小到大排序 蓝桥杯scratch比赛专项预测编程题 集训模拟练习题第17题
![[paper sharing] where's crypto?](/img/27/9b47bfcdff8307e63f2699d6a4e1b4.png)
[paper sharing] where's crypto?
随机推荐
The highest level of anonymity in C language
Chapter 3 business function development (safe exit)
[principle and technology of network attack and Defense] Chapter 7: password attack technology Chapter 8: network monitoring technology
Tsinghua, Cambridge and UIC jointly launched the first Chinese fact verification data set: evidence-based, covering many fields such as medical society
go语言的字符串类型、常量类型和容器类型
数学分析_笔记_第11章:Fourier级数
小试牛刀之NunJucks模板引擎
AI 击败了人类,设计了更好的经济机制
Summary of debian10 system problems
用存储过程、定时器、触发器来解决数据分析问题
GSAP animation library
Afghan interim government security forces launched military operations against a hideout of the extremist organization "Islamic state"
【Unity Shader】插入Pass实现模型遮挡X光透视效果
单臂路由和三层交换的简单配置
Wireshark分析抓包数据*.cap
debian10系统问题总结
Introduction de l'API commune de programmation de socket et mise en œuvre de socket, select, Poll et epoll
Classification of regression tests
Tips of this week 141: pay attention to implicit conversion to bool
伺服力矩控制模式下的力矩目标值(fTorque)计算