当前位置:网站首页>Persistence mechanism of redis
Persistence mechanism of redis
2022-07-04 22:39:00 【Ziqian 2014】
One 、Redis Implementation and principle of persistence mechanism based on
Redis Its strong performance is largely due to all its data stored in memory , Of course, if redis Restart or server failure redis restart , All data stored in memory will be lost . But in some cases , We hope Redis After restart, it can ensure that data will not be lost .
- take redis As nosql Database usage .
- take Redis As an efficient cache server , After the cache is broken down, the instantaneous pressure on the back-end database level is particularly large , Failure of all caches at the same time may lead to avalanche .
At this time, we hope Redis It can synchronize data from memory to hard disk in some form , After restart, the data can be recovered according to the records in the hard disk .Redis Support two ways of persistence , One is RDB The way 、 The other is AOF(append-only-file) The way , One of the two persistence methods can be used separately , You can also combine these two methods .
- RDB: According to the specified rules “ timing ” Store the data in memory on the hard disk .
- AOF: Record the command itself after each command execution .
Two 、RDB Pattern
RDB The way to persist is through snapshots (snapshotting) Accomplished , It is Redis Default persistence method , The configuration is as follows .
# save 3600 1
# save 300 100
# save 60 10000
Redis Allows users to customize snapshot conditions , When the snapshot conditions are met ,Redis The snapshot operation will be performed automatically . The conditions of snapshots can be configured by the user in the configuration file . The configuration format is as follows
save <seconds> <changes>
The first parameter is the time window , The second is the number of keys , in other words , The number of keys changed within the configuration range of the first time parameter is greater than the following changes when , That is, it meets the snapshot conditions . When the trigger condition ,Redis It will automatically generate a copy of the data in memory and store it on disk , This process is called “ snapshot ”, In addition to the above rules , There are also several ways to generate snapshots .
- Take automatic snapshots according to the configuration rules
- User execution SAVE perhaps GBSAVE command
- perform FLUSHALL command
- Perform replication (replication) when
2.1 Take automatic snapshots according to the configuration rules
modify redis.conf file , Express 5 Seconds , There is one key change , Will generate rdb file .
save 5 1 # Express 5s At least 1 individual key change ( newly added 、 modify 、 Delete ), Then rewrite rdb file
save 300 100
save 60 10000
Modify the file storage path
dir /data/program/redis/bin
Description of other parameter configurations 
If you need to close RDB Persistence mechanism of , You can refer to the following configuration , Turn on save , And annotate other rules
save ""
#save 900 1
#save 300 10
#save 60 10000
2.2 User execution SAVE perhaps GBSAVE command
Except for Jean Redis Automatic snapshot , When we restart the service or migrate the server, we need to manually intervene in the backup .redis Two commands are provided to complete this task
save command
As shown in the figure below , When executed save On command ,Redis Synchronize snapshot operations , All requests from clients will be blocked during snapshot execution . When redis When there is more data in memory , Passing this command will result in Redis Not responding for a long time . Therefore, it is not recommended to use this command in a production environment , It's recommended bgsave command 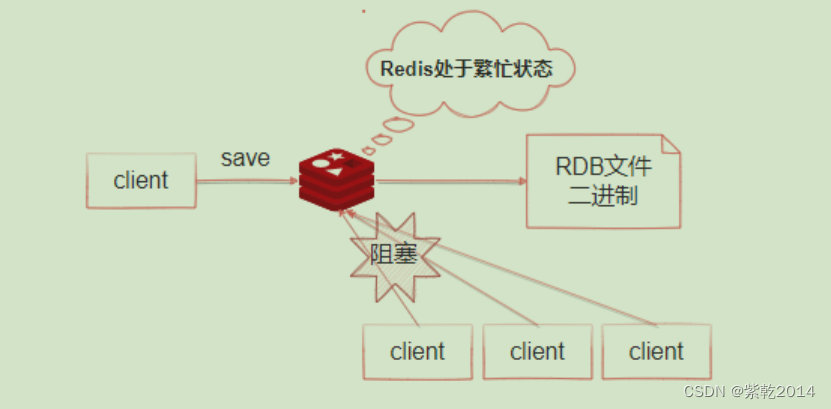
bgsave command
As shown in the figure below ,bgsave The command can perform snapshot operations asynchronously in the background , While taking a snapshot, the server can continue to respond to requests from the client . perform BGSAVE after ,Redis Will return immediately ok Indicates that the snapshot operation is started , stay redis-cli terminal , You can obtain the time of the last successful snapshot execution through the following command ( With UNIX Time stamp format means ).
LASTSAVE
bgsave Command execution process :
1:redis Use fork Function copies a copy of the current process ( Subprocesses )
2: The parent process continues to receive and process commands from the client , The subprocess begins to write the data in memory to temporary files in the hard disk
3: When the subprocess has finished writing all the data, it will replace the old one with the temporary one RDB file , thus , A snapshot operation is completed .
Be careful :redis It will not be modified during snapshot RDB file , Only after the end of the snapshot will the old file be replaced with the new , That is to say, any time RDB The documents are complete . This allows us to make regular backups RDB File to implement redis Backup of database , RDB Files are compressed binaries , It takes up less space than the data in memory , It's easier to transmit .
bgsave The snapshot is executed asynchronously ,bgsave The data written is fork Process time redis Data status of , Once that is done fork, The data changes caused by the new client commands executed later will not be reflected in this snapshot .
Redis It will read RDB Snapshot file , And load the data from the hard disk into memory . Depending on the amount of data and server performance , The loading time is also different .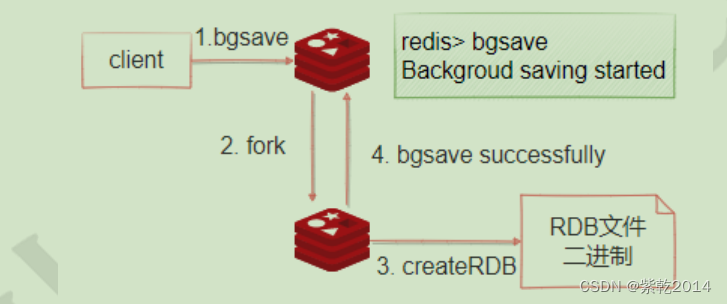
2.3 perform FLUSHALL command
The command clears redis All data in memory . After executing the command , as long as redis The snapshot rule configured in is not empty , That is to say save The rules exist .redis A snapshot operation will be performed . No matter what the rules are, they will be implemented . If no snapshot rule is defined , The snapshot operation will not be performed .
2.4 Perform replication (replication)
This operation is mainly in master-slave mode ,redis Automatic snapshot will be taken when replication is initialized . When performing a copy operation , Even if no automatic snapshot rules are defined , And there is no manual snapshot operation , It will still generate RDB Snapshot file .
2.5 RDB Data recovery demonstration
2.5.1 Analog data recovery
Prepare the initial data
redis> set k1 1
redis> set k2 2
redis> set k3 3
redis> set k4 4
redis> set k5 5
adopt shutdown Command off trigger save
redis> shutdown
Backup dump.rdb file ( For subsequent recovery )
cp dump.rdb dump.rdb.bak
Then start up redis-server(systemctl restart redis_6379), adopt keys Command view , Found the data still there
keys *
2.5.2 Analog data loss
perform flushall
redis> flushall
shutdown( Regenerate a snapshot without data , Used to simulate subsequent data recovery )
redis> shutdown
start-up redis, adopt keys Command view , here rdb There's no data in .
Restore previously backed up rdb file ( Previously saved data rdb snapshot )
mv dump.rdb.bak dump.rdb
Restart again redis, You can see the data saved by the previous snapshot
keys *
2.6 RDB The strengths and weaknesses of the document
One 、 advantage
1.RDB It's a very compact (compact) The file of , It has been saved. redis Data set at a certain point in time , This file is ideal for backup and disaster recovery .
2. Generate RDB When you file ,redis The main process will fork() A subprocess to handle all the saving work , The main process does not need any disks IO operation .
3.RDB Speed ratio when recovering large data sets AOF It's faster to recover .
Two 、 Inferiority
1、RDB Modal data cannot be persisted in real time / Second persistence . because bgsave Run every time fork Action create subprocess , Frequent execution cost is too high
2、 Make a backup at regular intervals , So if redis If it goes down unexpectedly , All changes since the last snapshot will be lost ( Data is missing ).
Be careful :
If the data is relatively important , Hope to minimize the loss , You can use AOF Way to persist .
3、 ... and 、AOF Pattern
AOF(Append Only File):Redis Not on by default .AOF Log every write operation , And add it to the file . After opening , Make changes Redis When data is ordered , Will write the command to AOF In file .Redis During the restart, the write instructions will be executed from the front to the back according to the contents of the log file to complete the data recovery .
3.1 AOF Configuration switch
# switch
appendonly no /yes
# file name
appendfilename "appendonly.aof"
By modifying the redis.conf restart redis after :systemctl restart redis_6379.
Run again redis Related operation commands of , You will find that in the specified dir Generate under directory appendonly.aof file , adopt vim View the file as follows
*2
$6
SELECT
$1
0
*3
$3
set
$4
name
$3
vip
*3
$3
set
$4
name
$3
123
3.2 AOF Answer relevant questions
problem 1: Is data persistent to disk in real time ?
Although every time a change is made Redis Operation of database content ,AOF Will record the command in AOF In file , But in fact , Because of the caching mechanism of the operating system , The data is not actually written to the hard disk , Instead, it enters the system's hard disk cache . By default, the system every 30 The synchronization operation will be performed once per second . So that the contents of the hard disk cache can really be written to the hard disk . Here 30 If the system exits abnormally during seconds, the data in the hard disk cache will be lost . Generally speaking, it can enable AOF The premise is that the business scenario cannot tolerate such data loss , This is the time Redis In the writing AOF After the file is, the system is actively required to synchronize the cached content to the hard disk . stay redis.conf The synchronization mechanism is set in the following configuration .
problem 2: The files are getting bigger , What do I do ?
because AOF Persistence is Redis Keep writing orders to AOF In file , With Redis Constantly running ,AOF It's going to get bigger and bigger , The bigger the file , The larger the server's memory and AOF The longer it takes to recover . for example set vip 666, perform 1000 Time , The result is vip=666. To solve this problem ,Redis New rewrite mechanism , When AOF When the file size exceeds the set threshold ,Redis Will start
AOF The content of the file is compressed , Keep only the smallest instruction set that can recover data . The following command can be used to trigger rewriting
redis> bgrewriteaof
AOF File rewriting is not about rearranging the original file , Instead, read the existing key value pairs of the server directly , Then use one command to replace the previous commands recording this key value pair , Create a new file and replace the original one AOF file .
The rewriting trigger mechanism is as follows 
When it starts ,Redis It will be executed one by one AOF File to load data from the hard disk into memory , The loading speed is relative to RDB It will be slower .
problem 3: In the process of rewriting ,redis What if the data is changed ?
Redis Can be in AOF When the file size becomes too large , Automatically in the background AOF Rewrite : The rewritten new AOF The file contains the minimum set of commands required to recover the current dataset .
The rewriting process is as follows :
1、 The main process will fork A sub process comes out and AOF rewrite , This rewriting process is not based on the original aof File to do , It's a bit like a snapshot , Full traversal of data in memory , Then serialize one by one to aof In file .
2、 stay fork Subprocesses in this process , The server can still provide external services , It was rewritten at this time aof Data and redis What if the memory data is inconsistent ? Never mind , In the process , Data update operation of the main process , Caches to aof_rewrite_buf in , That is to open up a separate cache to store commands received during rewriting , When the child process finishes rewriting, the data in the cache is appended to the new process aof file .
3、 When all the data is added to the new aof After in file , Put the new aof File rename official file name , After that, all operations will be written to the new aof file .
4、 If in rewrite Failure in the process , It won't affect the original aof Normal operation of documents , Only when rewrite The file will not be switched until it is finished . So the rewrite The process is more reliable .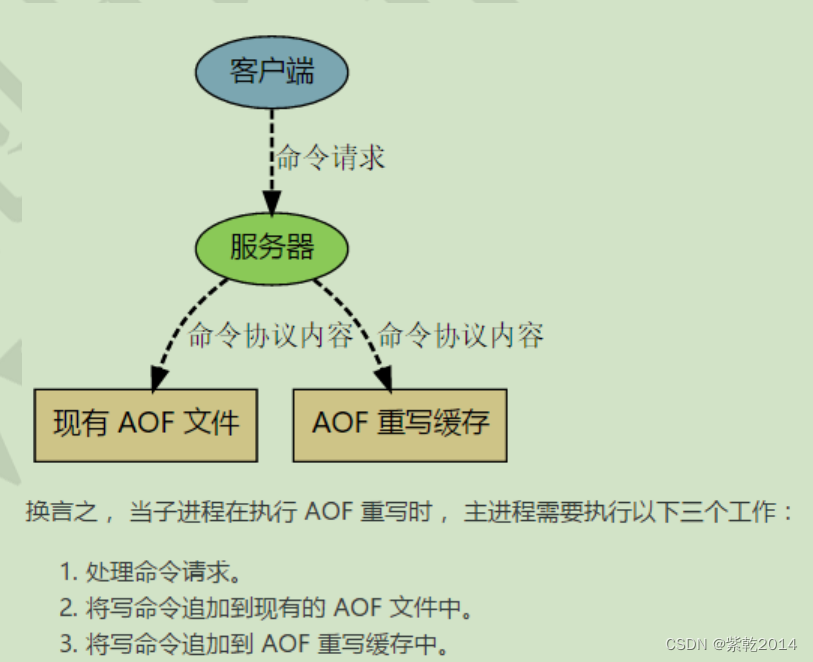
Redis Allow simultaneous opening of AOF and RDB, It not only ensures the data security, but also makes the operation such as backup very easy . If it is turned on at the same time ,Redis Restart will use AOF File to recover data , because AOF Persistence of methods may lose less data .
3.3 AOF Advantages and disadvantages of
advantage :
1、AOF The persistence method provides a variety of synchronization frequencies , Even if you use the default synchronization frequency to synchronize once per second ,Redis At most, it's lost 1 Seconds of data .
shortcoming :
1、 For... With the same data Redis,AOF Documents are usually better than RDB Larger file size (RDB It's a snapshot of the data ).
2、 although AOF Provides a variety of synchronous frequencies , By default , The frequency of synchronization once per second also requires high performance . In the case of high concurrency ,RDB Than AOF With good and better performance guarantee .
边栏推荐
- Nat. Commun.| Machine learning jointly optimizes the affinity and specificity of mutagenic therapeutic antibodies
- Concurrent optimization summary
- How to reset the password of MySQL root account
- 嵌入式开发:技巧和窍门——提高嵌入式软件代码质量的7个技巧
- 【lua】int64的支持
- MySQL storage data encryption
- How to manage 15million employees easily?
- Logo special training camp Section V font structure and common design techniques
- 短视频系统源码,点击屏幕空白处键盘不自动收起
- MD5 tool class
猜你喜欢
Kdd2022 | what features are effective for interaction?
Unity修仙手游 | lua动态滑动功能(3种源码具体实现)
Éducation à la transmission du savoir | Comment passer à un test logiciel pour l'un des postes les mieux rémunérés sur Internet? (joindre la Feuille de route pour l'apprentissage des tests logiciels)

Ascendex launched Walken (WLKN) - an excellent and leading "walk to earn" game

【OpenGL】笔记二十九、抗锯齿(MSAA)

虚拟人产业面临的挑战
国产数据库乱象
【愚公系列】2022年7月 Go教学课程 003-IDE的安装和基本使用

The Sandbox 和数字好莱坞达成合作,通过人力资源开发加速创作者经济的发展
堆排序代码详解
随机推荐
Concurrent network modular reading notes transfer
华泰证券是国家认可的券商吗?开户安不安全?
Common open source codeless testing tools
POM in idea XML dependency cannot be imported
PostgreSQLSQL高级技巧透视表
短视频系统源码,点击屏幕空白处键盘不自动收起
Logo special training camp Section V font structure and common design techniques
【lua】int64的支持
Test will: bug classification and promotion solution
Naacl-22 | introduce the setting of migration learning on the prompt based text generation task
Jvm-Sandbox-Repeater的部署
嵌入式开发:技巧和窍门——提高嵌入式软件代码质量的7个技巧
sobel过滤器
Redis sentinel simply looks at the trade-offs between distributed high availability and consistency
LOGO special training camp section I identification logo and Logo Design Ideas
It is said that software testing is very simple, but why are there so many dissuasions?
Close system call analysis - Performance Optimization
制作条形码的手机App推荐
环境加密技术解析
Erik baleog and Olaf, advanced area of misc in the attack and defense world