当前位置:网站首页>Paddy serving v0.9.0 heavy release multi machine multi card distributed reasoning framework
Paddy serving v0.9.0 heavy release multi machine multi card distributed reasoning framework
2022-07-05 22:37:00 【Paddlepaddle】
This article has been published on the official account of the flying oar , Please check the link :
Paddle Serving v0.9.0 Heavy release of multi machine multi card distributed reasoning framework
since 2018 Since then ,BERT、ERNIE、GPT And other large-scale pre training models have developed rapidly , stay NLP、 Multimodal 、 Great breakthroughs have been made in the biomedical field . The parameter scale of the super large pre training model ranges from one billion 、 Expand from 10 billion to 100 billion 、 One trillion , Model size breakthrough single card video memory , Even single machine multi card video memory limitation . Large models have less annotation data 、 The effect of the model is better 、 Stronger creativity and flexible customization of scenes . therefore , How to fully deploy the super large pre training model in the production environment , And get a complete model effect , Became the focus of the industry's attention .
Paddle Serving As a flying oar (PaddlePaddle) Open source service deployment framework , In order to better solve the problem of full deployment of super large pre training model in the production environment , Release v0.9.0 edition —— Multi machine multi card distributed reasoning framework . Support natural language understanding 、 dialogue 、 Different kinds of large model structures such as cross modal generation , Realize high-speed reasoning , Let the big model really be applied .
Mingu community —— Baidu recently released a creative community based on Wenxin big model , yes Paddle Serving A typical application of landing . Adopted by mingu community Paddle Serving The distributed reasoning framework deploys ten billion 、 100 billion level parameter super large model , Baidu self-developed has been successfully deployed and launched in this community 4 A big model ( Intelligent painting 『 Everyone is an artist 』、 Intelligent conversation 『AI Let's talk 』、 Intelligent creation 『 Lyrics generation 』 And story generation 『AI Dream maker 』), The industrial application of large model has been launched .

Sweep code experience
「 Pengcheng - Baidu · Literary heart 」( Code name ERNIE 3.0 Titan), On 2021 year 12 Created by Baidu United Pengcheng Laboratory , As the world's first 100 billion model of knowledge enhancement , The parameter scale reaches 2600 Billion , It was the largest Chinese monomer model in the world at that time , The same goes for Paddle Serving Multi machine multi card distributed reasoning framework , Realize its service-oriented deployment .
design scheme
Paddle Serving Framework support RESTful、gRPC、bRPC Other protocols , Access to a variety of high-performance reasoning engines , Adapt to a variety of computing chips 、Docker as well as Kubernetes Cloud environment , Offer based on DAG pipeline Design , Provide synchronous and asynchronous 2 A processing framework , Including thread concurrency 、 Automatic batch 、 High performance concurrent processing capabilities such as request caching . Through the above perfect basic functions 、 High performance reasoning ability ,Paddle Serving It lays a solid foundation for the realization of large model distributed reasoning .
Solve the bottleneck of single card video memory
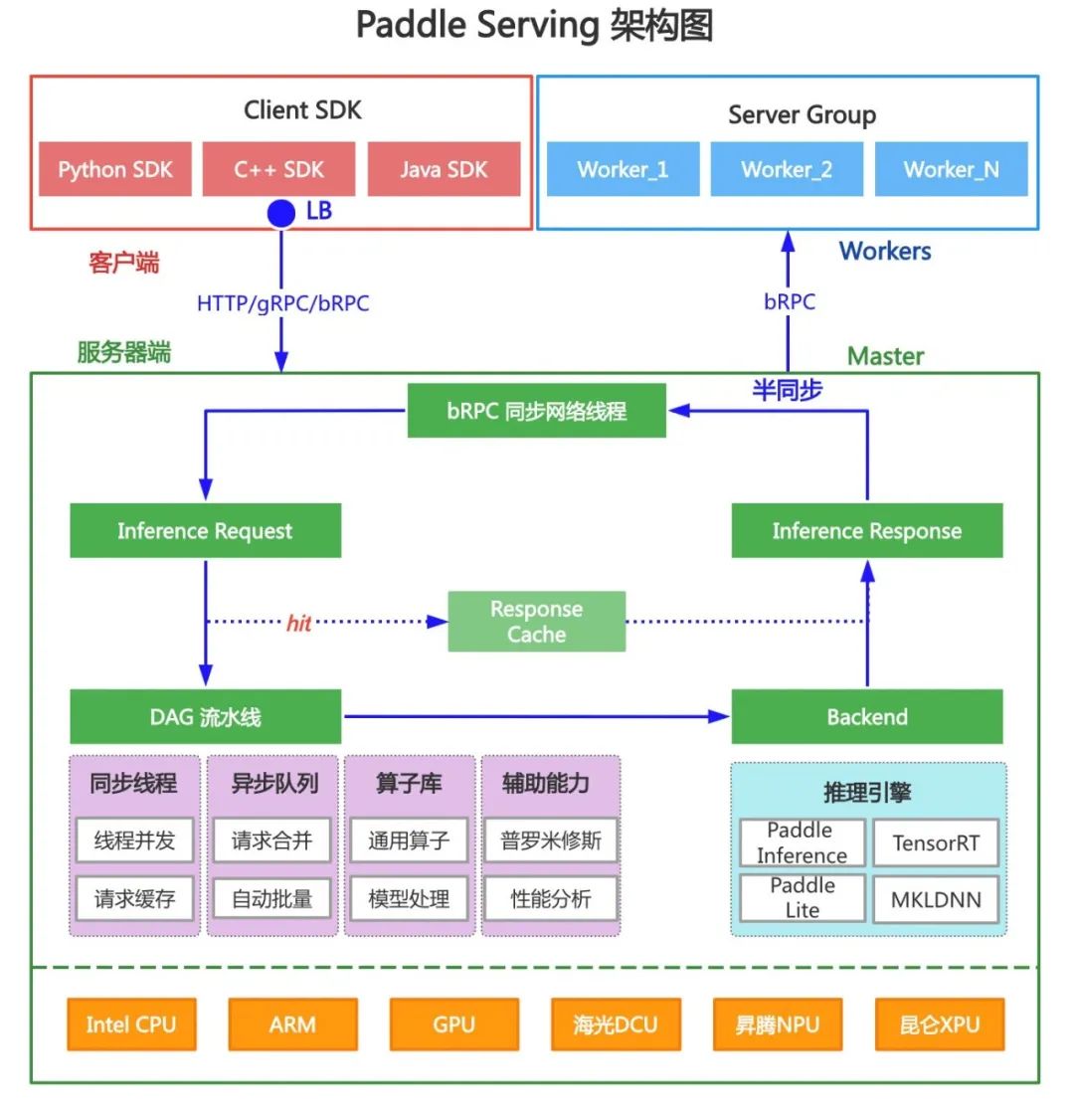
For large models, the occupied video memory exceeds GPU Upper limit of single card video memory , Even exceeding the upper limit of single machine multi card video memory , Learn from model parallelism in distributed training 、 Pipeline parallel technology , Divide the large model structure into several subgraphs , The video memory occupied by each sub image does not exceed the upper limit of single card video memory , take Tensor Calculation and calculation of different layers are divided into multiple GPU obstruct , And insert the set communication operator to realize the parameter synchronization between subgraphs . therefore , Large model reasoning calculation is deduced into multi machine and multi card distributed reasoning based on subgraph topology .
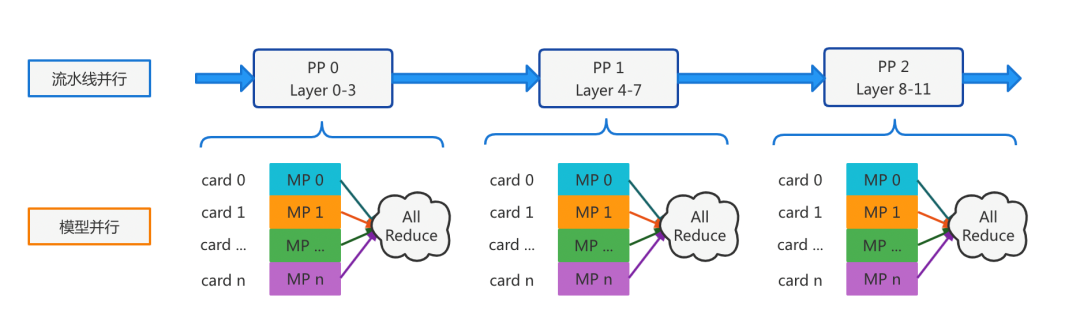
Paddle Serving Follow the principle of distributed reasoning technology to expand the distributed ability of multi machine and multi card , Designed the first version . As shown in the figure below , from 1 individual Master Nodes and multiple Worker Node structure .Master The node receives user requests , Support RESTful、gRPC、bRPC agreement , be based on Serving Directed acyclic graph of constructs loop control 、 Subgraph topology management , There are 4 Class operator , Include Request、Response、Loop and PP( Pipeline parallel ) operator . The memory reference method is used to exchange data between operators ,PP Pipeline parallel computing between ,PP Parallel computation of internal implementation model ,PP Operators and Worker Use RPC Interaction , be aboard the same plane Worker A collective communication library is used between NCCL Synchronous data .
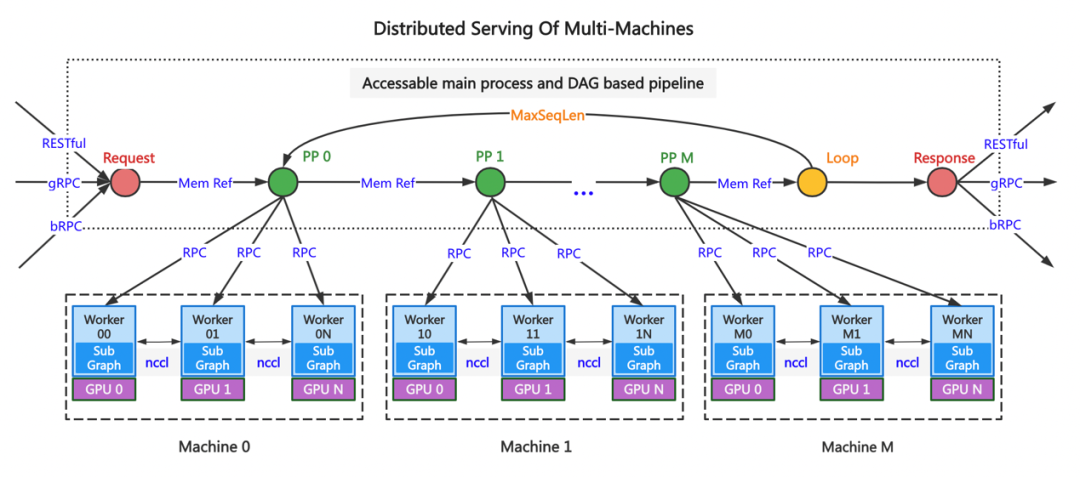
The plan is made by Serving The framework controls the topology and data flow of subgraphs , Support complex topologies ,PP Pipeline parallel processing can be realized between . The disadvantage is poor performance , Every round Loop in Worker The parallel calculation results of inter model should be copied from video memory to memory , Return to Master, Again by PP 0 Issue to PP 1 All of the Worker, many times RPC pack 、 Unpacking operation , It's very time consuming .
Move the subgraph topology down to the reasoning engine layer
For the performance problems of the above scheme , The subgraph topology and computational control logic are transformed from Serving Move down to the reasoning engine layer , Every round Loop The calculation results are saved in GPU Cache in video memory , No need to copy Host Memory .PP Insert between nodes Send、Recv operator , Realize high-performance data communication . When the new scheme is started , Pass the subgraph topology into the inference engine in the form of configuration file , Each node has a complete subgraph topology , The position of the current node in the topology 、 Of adjacent nodes IP and Port, And complete handshake with adjacent nodes .Master The node receives user requests , adopt RemoteOp Send data to 0 Layer subgraph Worker Serving Node , All calculations and data synchronization control are completed in the reasoning engine , The final calculation result is determined by 0 Layer subgraph Worker Serving The node returns to Master Serving node , Return to the user .
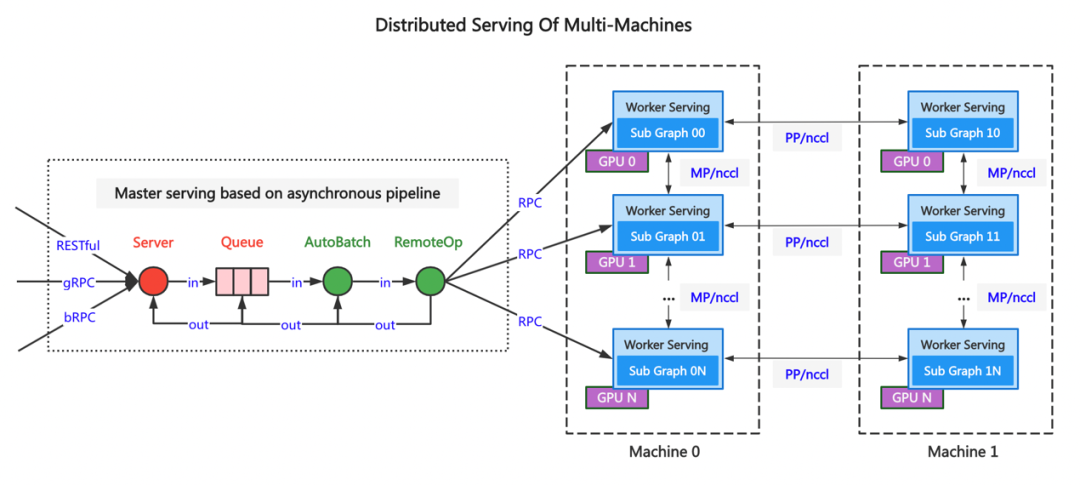
Through the above improvements , The larger the scale of the new framework reasoning model, the more obvious the performance improvement , Compared with the original scheme , Infer hundreds of billions of parameters ERNIE Model time decreases 70%.
Improve service concurrent throughput
Usually , Large model distributed reasoning optimization technology includes dynamic batch 、 Low precision fp16、TensorRT Speed up 、fused Optimization and video memory Cache etc. ,Paddle Serving Not only these optimization methods are used , At the same time, it also made improvements and upgrades . For example, dynamic batch technology is implemented in many service-oriented reasoning frameworks , The principle is that multiple requests shape Those with the same dimension but different values Tensor Automatically Padding repair 0 alignment , Merge into a large matrix for batch reasoning , make the best of GPU Kernel many Block、 Multithreading features , Improve computing throughput .
Paddle Serving The differences of dynamic batch technology are 2 spot .
First of all , Realize complex two-dimensional variable length Tensor Automatic batch , Such as Transformer The input parameters of the model structure have two-dimensional variable length Tensor.
second , Put forward 2 Dynamic batch Padding Merge Batch The strategy of ( Meet any 1 One strategy can merge data ), Solve completely Padding Problems that lead to degradation of computing performance .
Strategy 1: Evaluate the difference in the absolute length of the data , When the number of bytes of the absolute value difference of the length of two batches of data is less than 1024 Byte time ( Configurable ), Automatically Padding Merge after completion Batch.
Strategy 2: Evaluate the similarity of data , With two sets of data Shape The product of each dimension is taken as the similarity , When the similarity is greater than 50%( Configurable ), Automatically Padding Merge after completion Batch.
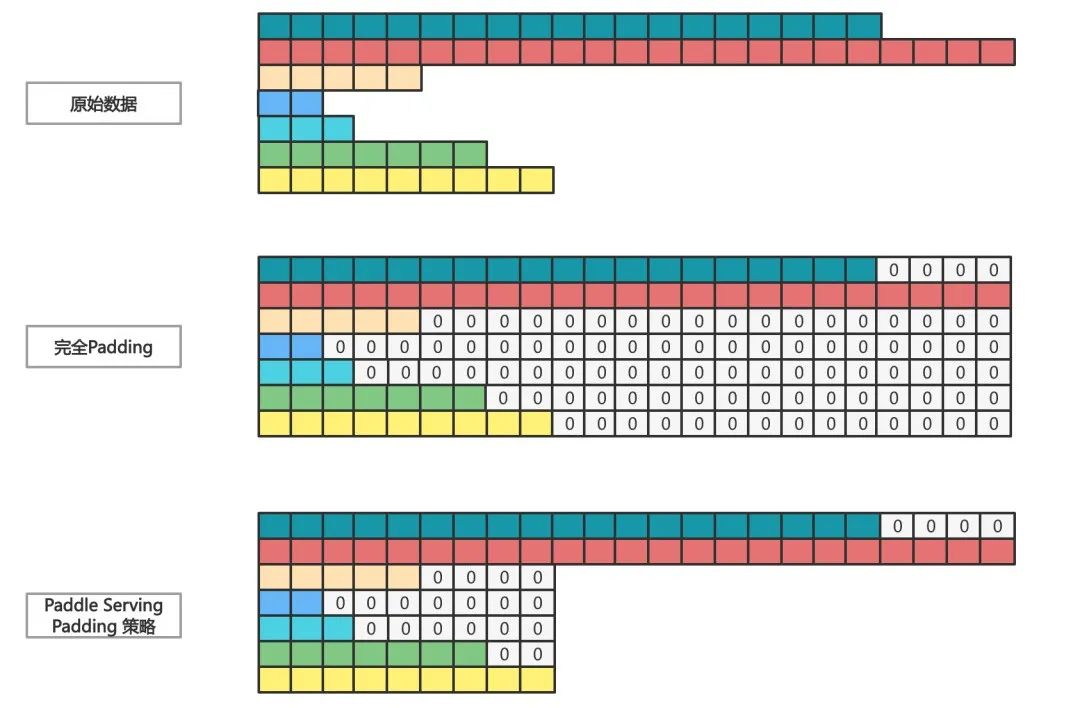
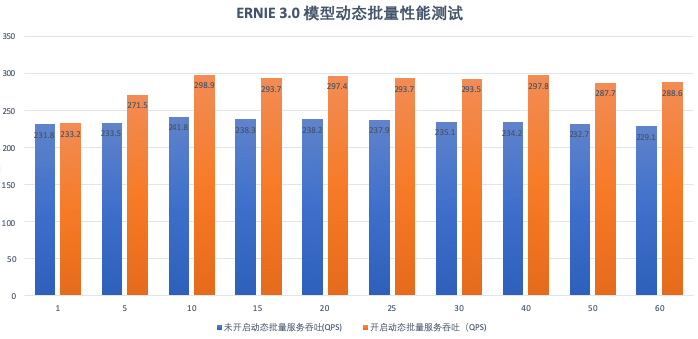
The above strategy values are obtained through a variety of model tests , For different business scenarios and request data , The best configuration is also different , The effect will be more obvious in large traffic and high concurrency scenarios . stay ERNIE 3.0 There is 25% The throughput of .
exception handling
The abnormal problems faced by the deployment of large models are 3 individual : Hardware failure 、 Network anomalies 、 Service exception, etc . The overall exception handling plan is as follows :
Hardware failure
Single card failure : Service instance migration , Other fault free cards can be reused .
Single machine failure : Service instance migration
Network anomalies
The stand-alone network is abnormal : Service instance migration
Master And Worker Abnormal link between : Use short links , Semi synchronous and anomaly detection .
Service exception
Health check : Timed port detection & Prediction result detection
Service tamps / Hang up : Service to restart &supervise Pull up
Due to a group of services Master Serving And Worker Serving Communicate with each other , Exception handling within services is different from exception handling between services .Master Serving And Worker Serving The data communication between them adopts bRPC Semi synchronous mechanism , Wait for multiple asynchronous operations to return . from Master Serving Initiate the call and wait for multiple RPC Wake up after all , So as to achieve the effect of broadcasting and synchronous waiting . Due to network or abnormal processing , part Worker Serving The return value of the node fails , Because each floor MP The calculation results of nodes are all the same , therefore , When not all requests fail , We believe that the request reasoning calculation is successful , Will be the first 0 layer MP The calculation result of the node returns . The low-cost migration scheme for single card and single machine multi card failures will be the focus of the next stage .
Benchmark
- Test environment
8*A100-SXM4-40GB, 160 core Intel Xeon Gold 6148 CPU @ 2.40GHz, 10000Gbps network
- Model parameter scale : Ten billion
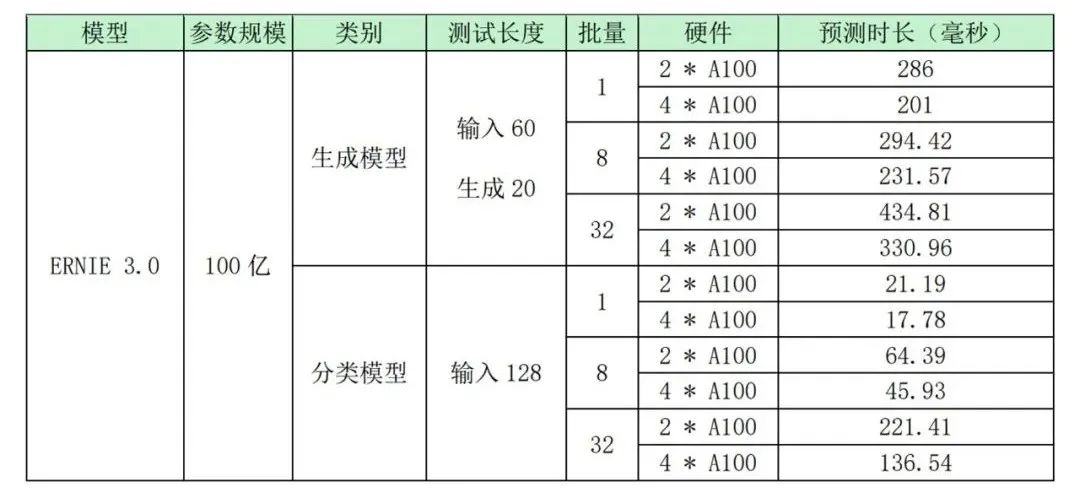
- Test conclusion
stand-alone 4 card A100 The single request prediction delay of deploying the ten billion generation model is 201 millisecond ,batch=32 when , The prediction time is 330ms, stand-alone 4 card A100 The single request prediction delay of deploying the ten billion classification model is 17.7ms, Not only meet the delay requirements of online services , It has advantages over other distributed reasoning frameworks , It has the technical conditions for large-scale industrial application .
summary
Paddle Serving The multi machine and multi card distributed reasoning scheme has good versatility and scalability , It can widely support different kinds of model structures , Realize high-speed reasoning , At present, it has been supported, such as natural language understanding 、 dialogue 、 Real time online application of large-scale models such as cross modal generation . Use this scheme to realize large-scale service deployment , Let the big model really be applied .
Deployment plan
As China's AI enters the industrial scale application 「 Deep Water 」, Baidu has built a system to meet the needs of the scene on the big model , Provide tools and deployment schemes to support the implementation of the whole process , Let the big model technology empower the industry , Give Way AI Boost industrial production .
Online deployment
stay 2022WAVE SUMMIT 2022 During the deep learning developer Summit , Wenxin big model the big model application of mingu community adopts Paddle Serving The distributed reasoning framework is deployed online , It lays a foundation for large-scale application of large-scale models .Paddle Serving The overall deployment scheme design of multi machine and multi card distributed reasoning framework is complex , Many places, many centers 、 Multi machine and multi card combination 、 Multilevel load balancing 、 Traffic scheduling and abnormal fault handling . The overall deployment idea is shown in the figure below , The difference from conventional service deployment lies in the structured idea of building distributed deployment .
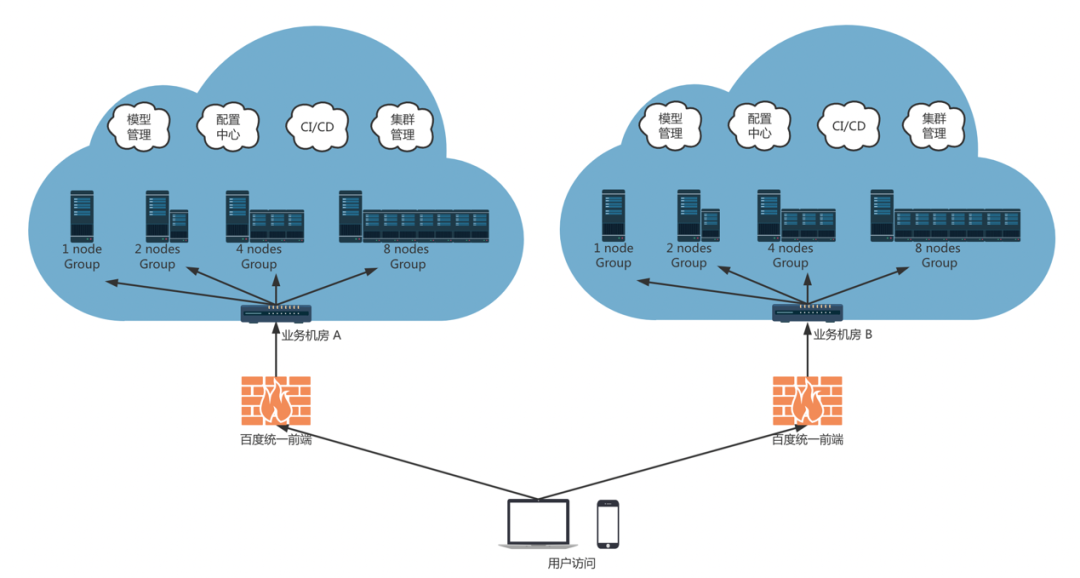
First , The big model service is based on Group In units of , Every Group By multiple Node form ,Node It is a virtualized deployment container , Every Node Deploy Master The process and Worker process . secondly , Every Group Only one of them Node Deploy Master process , Be responsible for receiving external request traffic . According to the scale of the model 、 Segmentation method 、 Factors such as the number of single card video memory and single machine video memory , Decide on each Group On Node The number of , Such as single machine with multiple cards 、2 Machine multi card 、4 Jiduoka and 8 Jiduoka, etc . Last ,Paddle Serving Provides multi machine adaptive configuration generation and startup script , According to the global configuration information ; In the same way Group Different Node Automatically generate deployment configuration and startup scripts , Simplify manual setup , Improved deployment efficiency .
Through the above scheme, we can realize the deployment of multi machine and multi card large model .
Deployment case
Next , Take the ten billion parameter scale Knowledge Q & a task as an example , Provide you with a complete deployment case , Explain in detail Paddle Serving Deployment scheme of distributed reasoning , For details, please click to read the original .
Click to get
ERNIE 3.0 10 billion parameter model deployment cases

Examples of Knowledge Q & A tasks
Read more
Go to the official website
Follow the following official website , More technical content is available .
Paddle Serving Official website :
The official website of the flying oar Wenxin big model :
Join the community
If you want to communicate with more developers or other users , Welcome to scan the code to join Paddle Serving Technology exchange group , And from major enterprises 、 University Service Deployment developers talk about technology .
Focus on 【 Flying propeller PaddlePaddle】 official account
Get more technical content ~
边栏推荐
- Metasploit(msf)利用ms17_010(永恒之蓝)出现Encoding::UndefinedConversionError问题
- 如何快速体验OneOS
- 请求二进制数据和base64格式数据的预览显示
- Performance testing of software testing
- Post-90s tester: "after joining Ali, this time, I decided not to change jobs."
- The statistics of leetcode simple question is the public string that has appeared once
- 2022软件测试工程师涨薪攻略,3年如何达到30K
- [groovy] mop meta object protocol and meta programming (execute groovy methods through metamethod invoke)
- [groovy] groovy dynamic language features (automatic type inference of function arguments in groovy | precautions for function dynamic parameters)
- Pl/sql basic case
猜你喜欢
![[error record] file search strategy in groovy project (src/main/groovy/script.groovy needs to be used in the main function | groovy script directly uses the relative path of code)](/img/b6/b2036444255b7cd42b34eaed74c5ed.jpg)
[error record] file search strategy in groovy project (src/main/groovy/script.groovy needs to be used in the main function | groovy script directly uses the relative path of code)

关于MySQL的30条优化技巧,超实用

What about data leakage? " Watson k'7 moves to eliminate security threats

Technology cloud report: how many hurdles does the computing power network need to cross?

Wonderful review of the digital Expo | highlight scientific research strength, and Zhongchuang computing power won the digital influence enterprise award
Postman核心功能解析-参数化和测试报告
My experience and summary of the new Zhongtai model
Oracle triggers
分布式解决方案之TCC
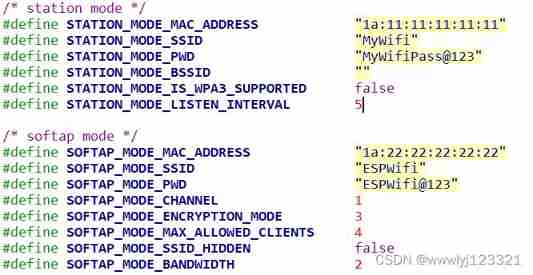
ESP32 hosted
随机推荐
[error record] groovy function parameter dynamic type error (guess: groovy.lang.missingmethodexception: no signature of method)
Postman核心功能解析-参数化和测试报告
Performance testing of software testing
Solutions for unexplained downtime of MySQL services
Function default parameters, function placeholder parameters, function overloading and precautions
关于MySQL的30条优化技巧,超实用
Metaverse Ape猿界应邀出席2022·粤港澳大湾区元宇宙和web3.0主题峰会,分享猿界在Web3时代从技术到应用的文明进化历程
MCU case -int0 and INT1 interrupt count
344. Reverse String. Sol
Win11 runs CMD to prompt the solution of "the requested operation needs to be promoted"
Usage Summary of scriptable object in unity
Distance entre les points et les lignes
Solve the problem of "no input file specified" when ThinkPHP starts
Pinctrl subsystem and GPIO subsystem
实战:fabric 用户证书吊销操作流程
等到产业互联网时代真正发展成熟,我们将会看待一系列的新产业巨头的出现
Thinkphp5.1 cross domain problem solving
The code generator has deoptimised the styling of xx/typescript.js as it exceeds the max of 500kb
Navigation day answer applet: preliminary competition of navigation knowledge competition
Promql demo service