当前位置:网站首页>[paper reading | deep reading] anrl: attributed network representation learning via deep neural networks
[paper reading | deep reading] anrl: attributed network representation learning via deep neural networks
2022-07-07 02:18:00 【Haihong Pro】
Catalog

Preface
Hello!
Thank you very much for reading Haihong's article , If there are mistakes in the text , You are welcome to point out ~
Self introduction. ଘ(੭ˊᵕˋ)੭
nickname : Sea boom
label : Program the ape |C++ player | Student
brief introduction : because C Language and programming , Then I turned to computer science , Won a National Scholarship , I was lucky to win some national awards in the competition 、 Provincial award … It has been insured .
Learning experience : Solid foundation + Take more notes + Knock more code + Think more + Learn English well !
Only hard work
Know what it is Know why !
This article only records what you are interested in
brief introduction
Link to the original text :https://dl.acm.org/doi/abs/10.5555/3304889.3305099
meeting :Twenty-Seventh International Joint Conference on Artificial Intelligence {IJCAI-18}(CCF A class )
year :2018
Abstract
The Internet means learning (RL) It aims to transform the nodes in the network into a low dimensional vector space , While maintaining the inherent nature of the network .
Although the Internet RL It's been extensively studied , But most of the existing work focuses on the network structure or node attribute information .
In this paper , We propose a new framework , be called ANRL, It combines network structure and node attribute information in principle .
To be specific , We propose a neighbor enhanced automatic encoder to model node attribute information , So as to rebuild its target neighbors rather than itself .
To capture the network structure , Based on the attribute coder, the attribute aware frame graph model is designed , Used to describe the association between each node and its direct or indirect neighbors .
We have conducted extensive experiments on six real-world networks , Including two social networks 、 Two citation networks and two user behavior networks .
Experimental results show that ,ANRL In node classification and link prediction tasks, we can get greater benefits .
1 Introduction
Network is a general data structure for exploring and simulating complex systems in the real world , Including social networks 、 Academic network and World Wide Web
In the age of big data , The network has become an important medium for efficiently storing and accessing relational knowledge of interactive entities
Knowledge mining in the network has been concerned by academia and industry , For example, online advertising positioning and recommendation
Most of these tasks require well-designed models , Many experts are involved in Feature Engineering , and RL It is an alternative to relatively automatic feature representation
With RL, Knowledge discovery in the network , Such as clustering [Narayanan wait forsomeone ,2007 year ], Link prediction [L̈u And Zhou ,2011 year ] And classification [Kazienko and Kajdanowicz,2012 year ], It can be greatly promoted by learning in low dimensional vector space
Network representation learning (RL)
The Internet RL The related work in can be traced back to the dimension reduction method based on graph , for example
- Local linear embedding (LLE)[Roweis and Saul,2000]
- Laplacian characteristic mapping (LE)[Belkin and Niyogi,2003]
LLE and LE Both maintain the local structure of the data space by constructing the nearest neighbor graph
- In order to keep the distance between connected nodes closer in the representation space , Calculate the corresponding eigenvector of the affinity graph as its representation
A major problem with these methods is
- Because the computational complexity of computing eigenvectors is very high
- It is difficult to expand to large networks
suffer word2vec Inspired by the recent success of the model [Mikolov wait forsomeone ,2013a;2013b], Many are based on network structure RL Methods have been proposed
And it shows good performance in various applications [Perozzi wait forsomeone ,2014; Cao et al ,2015;Tang wait forsomeone ,2015b;Grover and Leskovec,2016;Wang wait forsomeone ,2016]
However , Node attribute information may play an important role in many applications , But did not get enough attention
In what is known as Attribute information network (AINs) In the real world network , Nodes attached to various attributes are usually observed
for example , stay Facebook In social networks , User nodes usually include age 、 Gender 、 Education level and personalized profile information of published content
Some recent efforts have passed Integrate network topology and node attribute information To explore AINs, Show by learning better [Tang wait forsomeone ,2015a;Yang wait forsomeone ,2015; Pan et al ,2016].
stay AINs The in means that learning is still in its infancy , Ability is quite limited :
- (1) Network topology and node attributes are two heterogeneous information sources , It is difficult to keep their properties in a common vector space
- (2) The observed network data is often incomplete , Even noisy , This makes it more difficult to obtain information representation
To address these challenges , We put forward a unified framework , be called ANRL
- Learn by jointly integrating network structure and node attribute information AINs Robustness representation in
- More specifically , We use the powerful representation ability of deep neural network to capture the complex correlation between two information sources , These two information sources are composed of neighbor enhanced automatic encoder and attribute aware hop graph model
To make a long story short , Our main contributions are as follows :
- We propose a unified ANRL frame , The framework seamlessly integrates the network structure proximity and node attribute affinity into the low dimensional representation space . More specifically , We design a neighbor enhanced self encoder , It can better maintain the similarity between data samples in the representation space . We also propose an attribute aware skip graph model to capture structural dependencies . These two components share the connection to the encoder , The encoder captures node attributes and network structure information
- We do link prediction and node classification , stay 6 A large number of experiments have been carried out on data sets , The validity of the proposed model is verified by empirical results .
2 Related Work
Some early works and others Spectroscopic method The goal of is to preserve the local geometry of the data , And express them in a lower dimensional space
These methods are part of the dimensionality reduction technology , It can be considered as the pioneer of graph embedding .
In recent years , Network representation learning has received more and more attention in network analysis
They focus on embedding an existing network , Instead of building its affinity map
among
- DeepWalk [Perozzi et al., 2014] Generate a sequence of nodes by truncating random walks , Take the node sequence as a sentence , Enter the jump graph model to learn the representation
- Node2vec [Grover and Leskovec, 2016] By using width first (BFS) And depth first (DFS) Graph search to expand DeepWalk, To explore different neighborhoods
- LINE [Tang wait forsomeone ,2015b] Optimize the proximity of first-order and second-order graphs , Instead of performing random walks
- And then ,GraRep [Cao wait forsomeone ,2015] Propose capture k Order relation information is used for graph representation
- SDNE [Wanget al., 2016] Incorporate the graph structure into the depth self encoder , To maintain the highly nonlinear first-order and second-order proximity
Attribute information networks are ubiquitous in many fields , It also contains network structure and node attribute information , It is expected to achieve a better expression
Some existing algorithms have studied the possibility of embedding these two information sources into a unified space
- TADW [Yang wait forsomeone ,2015] take DeepWalk And relevant text features are incorporated into the matrix decomposition framework
- PTE [Tang wait forsomeone ,2015a] Using tag information and different levels of word co-occurrence information to generate predictive text representation
- TriDNR [Pan wait forsomeone ,2016] Use information from three parties , Including node structure 、 Node content and node label ( If any ), Common learning nodes represent
Although the above method does merge the node attribute information into the representation , But they are specifically designed for text data , Not suitable for many other types of features
for example , Continuous numerical characteristics
lately , Some feature type independent representation learning algorithms are proposed , Further enhance performance by unsupervised or semi supervised
These algorithms can handle various feature types , And capture structural proximity and attribute affinity [Huanget al., 2017; Liao et al ,2017;Rossi wait forsomeone ,2018]
- AANE [Huang wait forsomeone ,2017] It is a distributed embedding method , By decomposing the attribute affinity matrix , Network lasso regularization is used to punish the embedding difference between connecting nodes , Joint learning nodes represent
- Planetoid [Yang wait forsomeone ,2016] Developed transduction and induction methods , Class label and neighborhood context in common prediction graph
- SNE[ Liao et al ,2017] By using the end-to-end neural network model to capture the complex relationship between the network structure and the node attribute information to generate the embedding
- Another semi supervised learning framework SEANO [Liang et al., 2018] Input in the form of aggregation of input sample attributes and their average neighborhood attributes , To mitigate the negative impact of outliers in the learning process .
Representation learning in heterogeneous information networks has also been studied
- Metapath2vec [Dong wait forsomeone ,2017] Using random walk based on meta path to generate heterogeneous node sequences , And use the heterogeneous hop graph model to learn the node representation
- [Li wait forsomeone ,2017] A model is proposed , Representation learning can be handled in a dynamic environment rather than a static network
- [Wang et al., 2017] The representation learning problem in symbolic information network is studied . We leave these possible extensions for future work
3 Proposed Model
3.1 Notations and Problem Formulation
Attribute network G : G = ( V , ε , X ) G: G = (V, \varepsilon, X) G:G=(V,ε,X)
- V V V: Vertex set
- ε \varepsilon ε: Edge set , In fact, that is E E E
- X X X: X ∈ R n × m X\in R^{n \times m} X∈Rn×m, A matrix encoding all node attribute information , x i x_i xi Representations and nodes i i i Related properties
Definition 3.1
- Given network G = ( V , E , X ) G = (V, E, X) G=(V,E,X), Our goal is to learn mapping functions f : v i → y i ∈ R d f: v_i →y_i∈R^d f:vi→yi∈Rd
- Put each node i ∈ V i∈V i∈V Expressed as a low dimensional vector y i y_i yi, among d ≪ ∣ V ∣ d≪|V| d≪∣V∣
- Mapping function f f f Not only Maintain network structure , and Keep node attribute proximity
3.2 Neighbor Enhancement Autoencoder
In order to encode the attribute information of nodes , We designed a Neighborhood enhancement Self encoder model , To promote anti noise to represent the learning process
Again , The neighbor enhanced self encoder consists of an encoder and a decoder , And our goal is Rebuild its target neighbors Not the node itself
It is worth noting that , When our target neighbor is the input node itself , The proposed model degenerates into a traditional self encoder .
say concretely , For eigenvectors x i x_i xi The node of v i v_i vi And the target neighbor function T ( ⋅ ) T(·) T(⋅), The hidden representation of each layer is defined as follows :
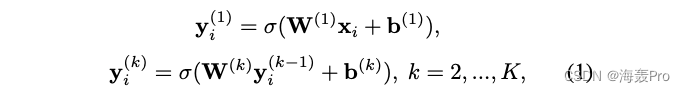
among
- K K K Is the number of layers of encoder and decoder
- σ ( ⋅ ) σ(·) σ(⋅) Indicates the possible activation function , Such as ReLU、sigmod or tanh
- W ( k ) W^{(k)} W(k) and b ( k ) b^{(k)} b(k) They are No k k k Layer transformation matrix and offset vector
- x i x_i xi Representations and nodes i i i Related properties
Our goal is to minimize the following loss function of the automatic encoder :
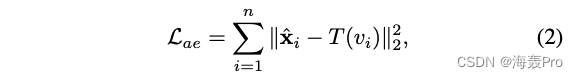
among
- x ^ i \hat x_i x^i For the reconstructed output of the decoder
- T ( v i ) T(v_i) T(vi) return v i v_i vi Target neighbors
T ( ⋅ ) T(·) T(⋅) Incorporate prior knowledge into the model , The following two formulas can be used :
- Weighted Average Neighbor
- Elementwise Median Neighbor
Weighted Average Neighbor
For a given node v i v_i vi, The target neighborhood can be calculated as the corresponding weighted average neighborhood , namely
T ( v i ) = 1 ∣ N ( i ) ∣ ∑ j ∈ N ( i ) w i j x j T(v_i) = \frac{1}{|N(i)|}\sum_{j \in N(i)} w_{ij}x_j T(vi)=∣N(i)∣1j∈N(i)∑wijxj
among
- N ( i ) N(i) N(i) For nodes in the network vi Neighbors of
- x j x_j xj For the node v j v_j vj Related properties of
- The weighted network is W i j > 0 W_{ij} > 0 Wij>0, The unweighted network is W i j = 1 W_{ij} = 1 Wij=1
Elementwise Median Neighbor
Similar to weighted average neighbors , node v i v_i vi Of Elementwise Median Neighbor Defined as :
T ( v i ) = x ~ i = [ x ~ 1 , x ~ 2 , . . . . , x ~ m ] T(v_i) = \widetilde x_i = [\widetilde x_1, \widetilde x_2, ...., \widetilde x_m] T(vi)=xi=[x1,x2,....,xm]
- x ~ k \widetilde x_k xk Is its relevant neighborhood eigenvector in k k k Median value of dimension
- for example : x ~ k = M e d i a n ( w i 1 x 1 k , w i 2 x 2 k , . . . . , w i ∣ N ( i ) ∣ x ∣ N ( i ) ∣ k ) \widetilde x_k = Median(w_{i1}x_{1k}, w_{i2}x_{2k}, .... , w_{i|N(i)|}x_{|N(i)|k}) xk=Median(wi1x1k,wi2x2k,....,wi∣N(i)∣x∣N(i)∣k)
- M e d a i n ( ⋅ ) Medain(·) Medain(⋅) Returns the median value of its input
Simple understanding : Take the median value in each dimension of each vector of nodes in the neighborhood
such as : The neighborhood node vector is expressed as 【1,2,3】【2,3,4】【3,4,5】
So the result is 【2,3,4】,【1,2,3】【2,3,4】【3,4,5】 The median of the first element of each vector
2 = mid【1,2,3】
3 = mid【2,3,4】
4 = mid 【3,4,5】
Our method is better than traditional automatic encoder There are more advantages in maintaining better proximity between nodes
Intuitively speaking
- The obtained representation is more robust to changes
- Because it constrains the closer nodes to have similar representations by forcing them to reconstruct similar target neighbors
- therefore , it Both capture the node attribute information , It also captures the local network structure information
- Besides , The proposed neighborhood enhanced self encoder model is a general framework
- It can be applied to self encoder variables such as de-noising self encoder and variational self encoder
3.3 Attribute-aware Skip-gram Model
In order to express the network structure information ,Skip-gram Models have been widely used in recent works [Perozziet al., 2014;Grover and Leskovec, 2016]
The algorithm It is assumed that nodes with similar context should be similar in the latent semantic space
On this basis , We put forward a kind of Attribute aware skipgram Model , This model Integrated attribute information , To achieve a smoother representation
say concretely , The objective function gives the current node v i v_i vi And its related properties x i x_i xi, Make all random walk contexts c ∈ C c∈C c∈C Of skip-gram The following logarithmic probability of the model is the smallest :
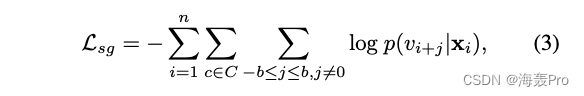
among
- v i + j v_{i+j} vi+j For the node context in the generated random sequence
- b b b For the window size
p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi) The conditional probability of is the probability of the target context of a given node attribute , We formally define p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi) by
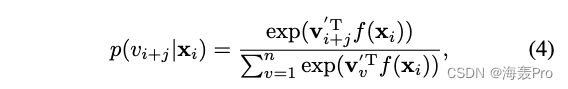
among
- x i x_i xi Is associated with the node v i v_i vi Associated attribute information
- f ( ⋅ ) f(·) f(⋅) It can be any attribute encoder function
- for example ,CNN For image data ,RNN For sequence data
- v i ′ v_i' vi′ Is the node v i v_i vi Be regarded as “ Context ” The corresponding representation of node
it Not only modeling node attributes , And modeling global structure information
Direct optimization (4) The cost of computing is high
Because it's calculating p ( v i + j ∣ x i ) p(v_{i+j}|x_i) p(vi+j∣xi) Conditional probability of , You need to sum the nodes of the whole set
We use [Mikolov et al., 2013b] Proposed in Negative sampling method : Sampling multiple negative samples according to some noise distribution
say concretely , For specific nodes - The context is right ( v i , v i + j ) (v_i, v_{i+j}) (vi,vi+j), We have the following goals :
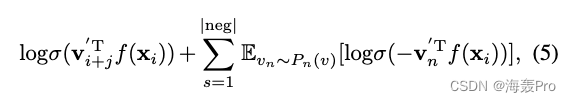
among
- σ ( x ) = 1 / ( 1 + e x p ( − x ) ) σ(x) = 1/(1 + exp(−x)) σ(x)=1/(1+exp(−x)) by sigmoid function
- ∣ n e g ∣ |neg| ∣neg∣ Is the number of negative samples
We are in accordance with the [Mikolov et al., 2013b] Recommended settings for P n ( v ) ∝ d v 3 / 4 P_n(v)∝d^{3/4}_v Pn(v)∝dv3/4, among d v d_v dv For the node v v v Degree
3.4 ANRL Model: A Joint Optimization Framework
In this section , We have put forward ANRL Model , Jointly use network structure and node attribute information to learn their potential representation
Pictured 1 Shown , The whole architecture consists of two coupling modules , namely
- Neighborhood enhanced self encoder
- Attribute aware skip graph model
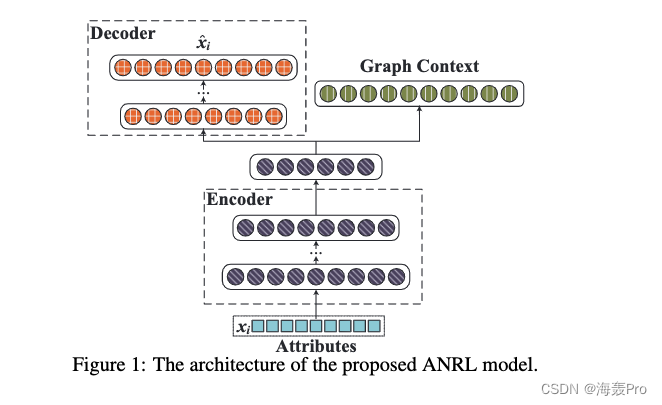
The encoder converts the input attributes into a low dimensional vector space , And expand two output branches
- The left output branch is a decoder , it Reconstruct the target neighbor of its input sample
- The output branch on the right Predict the context of the correlation graph for a given input
These two components are closely connected , Because they share the first few layers
In this way , y i K y^K_i yiK The final expression of Get the node attributes and network structure information
union ANRL The objective function of the model is expressed as L s g L_{sg} Lsg and L a e L_{ae} Lae Weighted combination of , Such as the type (2)、(3) Defined by :
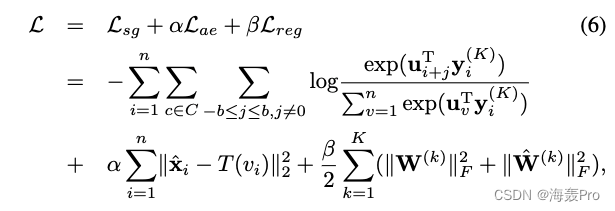
among
- n n n Is the total number of nodes
- C C C A set of node sequences generated for random walks
- b b b For the window size
- x i x_i xi Representation node v i v_i vi Eigenvector of
- y i ( K ) y^{(K)}_i yi(K) Representation node v i v_i vi after K K K Representation after layer coding
- W ( K ) W^{(K)} W(K)、 W ^ ( K ) \hat W^{(K)} W^(K) They are No K K K Weight matrix of layer encoder and decoder
- U U U Is the weight matrix of graph context prediction , u v u_v uv Corresponding U U U pass the civil examinations v v v Column
- α α α It is a super parameter to balance the loss of self encoder module and hopping module
- β β β yes ℓ 2 ℓ2 ℓ2 Norm regularization coefficient
such ,ANRL In a unified framework Node attributes are preserved 、 Local area network structure and global network structure information
It is worth noting that , Attribute awareness skip-gram Function of module f ( ⋅ ) f(·) f(⋅) It is the encoder part of the automatic encoder module , It converts node attribute information into representation space y i ( K ) y^{(K)}_i yi(K)
therefore , Network structure and node attribute information will jointly affect y i ( K ) y^{(K)}_i yi(K)
Besides , For the sake of simplicity , We only use one output layer to obtain the context information of the graph , It can be easily extended to multiple nonlinear conversion layers
In order to make L L L To minimize the , We use random gradient algorithm to solve (6) Optimize by the formula
We iteratively optimize these two coupling components , Until the model converges
All model parameters are recorded as Θ Θ Θ, Learning algorithm is summarized in Algorithm 1 in :

4 Experiments
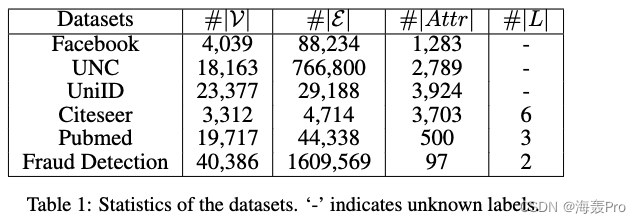
4.1 Datasets
4.2 Competitors
We will ANRL With several of the most advanced networks RL Algorithm comparison , These algorithms can be divided into the following groups :
- Attribute-only: SVM and autoencoder
- Structure-only:DeepWalk、 node2vec、 LINE、 SDNE
- Attribute + Structure:AANE、 SNE、Planetoid-T、 TriDNR、 SEANO
- ANRL Variants:ANRLWAN, Use weighted average neighbor function to construct its target neighbor ,ANRL-EMN, Use Elementwise Median neighbor function to generate its target neighbor , Such as chapter 3.2 As defined in , and ANRL-OWN, Rebuild yourself ( namely OWN) Like traditional automatic encoder
4.3 Link Prediction
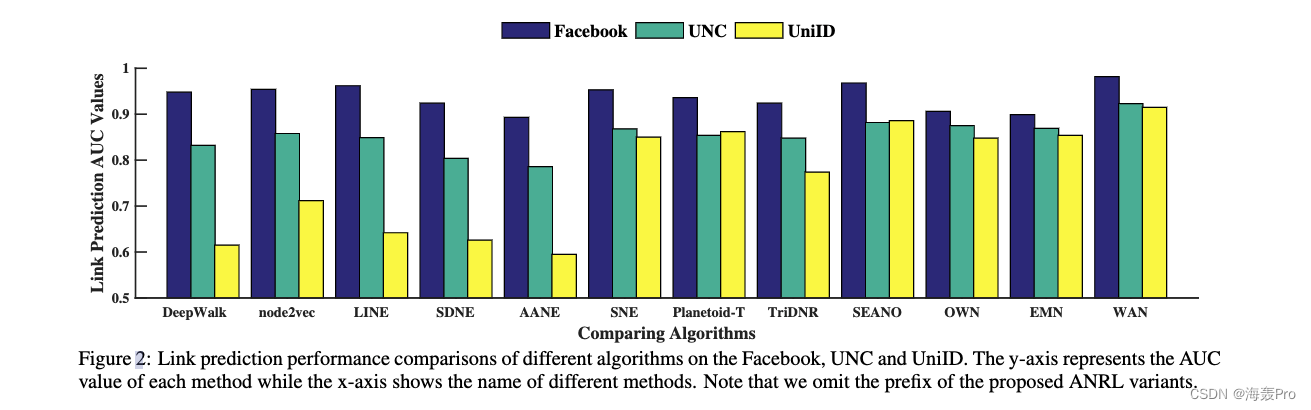
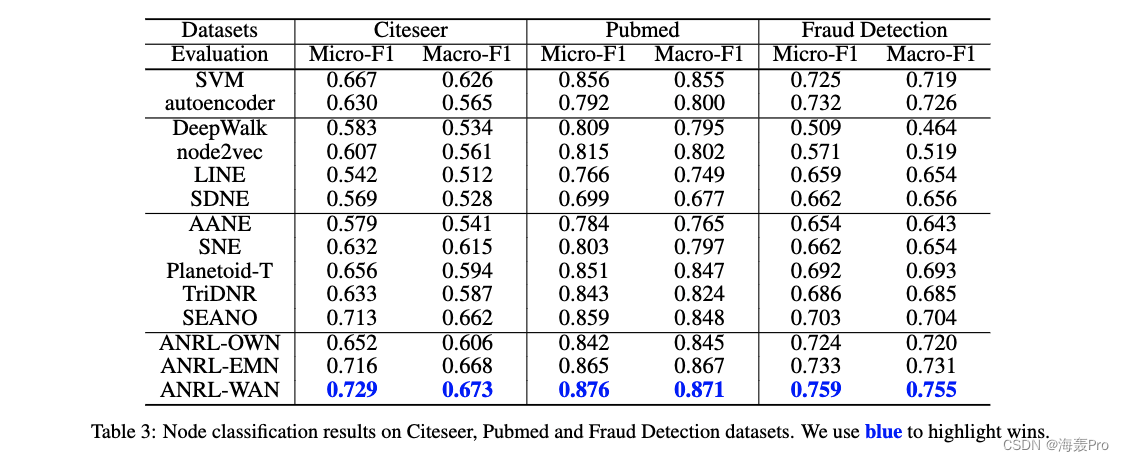
4.4 Node Classification
5 Conclusions
This paper studies representation learning in attributive information networks
Accordingly , We design a coupled deep neural network model , The model integrates node attributes and network structure information into embedding
In order to further solve the problem of maintaining structural proximity and attribute affinity , We develop a neighbor enhanced self encoder and attribute aware skip graph model to take advantage of the complex interrelationship between structural information and attributes
The experimental results on several real data sets show that , Proposed ANRL Better than the most advanced embedding method .
After reading the summary
The article generally adopts Encoder + skip-gram Model The way of combination
- Determine the parameters of random walk , Do random walks , obtain C C C( Similarly, we get a corpus )
- Then use the attribute characteristic matrix of nodes X X X, Calculation T ( ⋅ ) T(·) T(⋅) ( That is to operate the attribute vector of the neighborhood node of a node )
- Then start the iterative update
- basis AE Reconstructed vector x ^ \hat x x^ And T ( ⋅ ) T(·) T(⋅) Conduct loss calculation , Calculate the gradient , to update AE Parameters of
- Re basis x ^ \hat x x^, Use skip-gram Model , According to the context , to update skip-gram Parameters of the model
- Until it reaches the optimum
Algorithm flow chart is also very important , You need to read it carefully
analysis :
- Use attribute matrix X X X → \rightarrow → Keep node attributes
- Use neighborhood to optimize losses → \rightarrow → Preserve local neighborhood structure
- utilize skip-gram Model → \rightarrow → Keep the global network structure
Conclusion
The article is only used as a personal study note , Record from 0 To 1 A process of
Hope to help you a little bit , If you have any mistakes, you are welcome to correct them

边栏推荐
- Livox激光雷达硬件时间同步---PPS方法
- Redis configuration class redisconfig
- Freeswitch dials extension number source code tracking
- FLIR blackfly s usb3 industrial camera: white balance setting method
- ROS learning (23) action communication mechanism
- Centos8 install MySQL 8.0 using yum x
- 【论文阅读|深读】RolNE: Improving the Quality of Network Embedding with Structural Role Proximity
- go swagger使用
- ROS learning (26) dynamic parameter configuration
- How can reinforcement learning be used in medical imaging? A review of Emory University's latest "reinforcement learning medical image analysis", which expounds the latest RL medical image analysis co
猜你喜欢

Make DIY welding smoke extractor with lighting
@Before, @after, @around, @afterreturning execution sequence

张平安:加快云上数字创新,共建产业智慧生态

阿里云中间件开源往事

How can reinforcement learning be used in medical imaging? A review of Emory University's latest "reinforcement learning medical image analysis", which expounds the latest RL medical image analysis co
ROS learning (XX) robot slam function package -- installation and testing of rgbdslam
Cisp-pte practice explanation (II)
CISP-PTE实操练习讲解(二)
Shell script quickly counts the number of lines of project code
ROS学习(25)rviz plugin插件
随机推荐
LeetCode. Sword finger offer 62 The last remaining number in the circle
Analyze "C language" [advanced] paid knowledge [i]
3D laser slam: time synchronization of livox lidar hardware
传感器:DS1302时钟芯片及驱动代码
Cisp-pte practice explanation (II)
BigDecimal 的正确使用方式
The foreground downloads network pictures without background processing
Domestic images of various languages, software and systems. It is enough to collect this warehouse: Thanks mirror
String or binary data will be truncated
Correct use of BigDecimal
Flir Blackfly S 工业相机 介绍
Flir Blackfly S USB3 工业相机:计数器和定时器的使用方法
Errors made in the development of merging the quantity of data in the set according to attributes
云原生混部最后一道防线:节点水位线设计
Chang'an chain learning notes - certificate model of certificate research
go swagger使用
ROS learning (XX) robot slam function package -- installation and testing of rgbdslam
Command injection of cisp-pte
Redis configuration class redisconfig
Sensor: introduction of soil moisture sensor (xh-m214) and STM32 drive code