当前位置:网站首页>Depth residual network
Depth residual network
2022-07-06 06:54:00 【Programming bear】
AlexNet、 VGG、 GoogLeNet The emergence of neural network model has brought the development of neural network into the stage of dozens of layers , The deeper the layers of the network , The more likely you are to get better generalization ability . But when the model deepens , The Internet is becoming more and more difficult to train , This is mainly due to Gradient dispersion and Gradient explosion Caused by . In deeper layers of neural networks , When the gradient information is transmitted layer by layer from the end layer of the network to the first layer of the network , In the process of transmission The gradient is close to 0 Or a very large gradient
How to solve the phenomenon of gradient dispersion and gradient explosion of deep neural network ? Since the shallow neural network is not prone to gradient phenomenon , that We can try to add a mechanism to the deep neural network to fall back to the shallow neural network . When the deep neural network can easily retreat to the shallow neural network , The deep neural network can obtain the same model performance as the shallow neural network
One 、 Residual network model
By adding a direct connection between input and output Skip Connection It can make the neural network have the ability of fallback 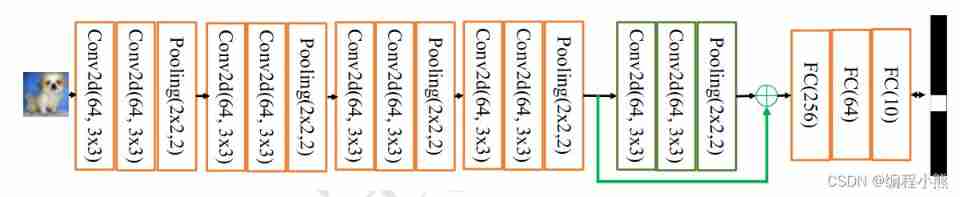
With VGG13 Take deep neural network as an example , Suppose that VGG13 The gradient dispersion phenomenon appears in the model , and 10 The gradient dispersion phenomenon is not observed in the layer network model , Then consider adding... To the last two convolution layers SkipConnection, In this way , The network model can Automatically select whether to pass These two convolution layers complete the feature transformation , still Just skip These two convolution layers are selected Skip Connection, Or combine two convolution layers and Skip Connection Output
be based on Skip Connection Of Deep residual network (Residual Neural Network, abbreviation ResNet) Algorithm , And put forward 18 layer 、 34 layer 、 50 layer 、 101 layer 、 152 Layer of ResNet-18、 ResNet-34、 ResNet-50、 ResNet-101 and ResNet-152 Wait for the model
ResNet By adding Skip Connection Realize the layer fallback mechanism , Input 𝒙 Through two convolution layers , Get the output after feature transformation ℱ(𝒙), With the input 𝒙 Add the corresponding elements , Get the final output ℋ(𝒙):
ℋ(𝒙) = 𝒙 + ℱ(𝒙),ℋ(𝒙) It's called the residual module (Residual Block, abbreviation ResBlock). Because of being Skip Connection Surrounding convolutional neural networks need to learn mapping ℱ(𝒙) = ℋ(𝒙) - 𝒙, So it is called Residual network 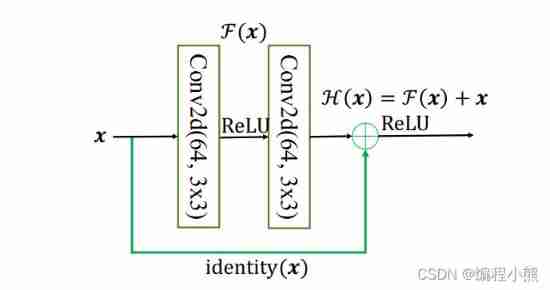
To be able to Satisfy input 𝒙 And the output of the convolution layer ℱ(𝒙) Be able to add , Need to enter 𝒙 Of shape And ℱ(𝒙) Of shape Exactly the same . When there is a shape When not in agreement , Usually through Skip Connection Add an additional convolution operation link on the input 𝒙 Change to and ℱ(𝒙) same shape, Pictured identity(𝒙) Function , among identity(𝒙) With 1×1 Most of the convolution operations , It is mainly used to adjust the number of input channels
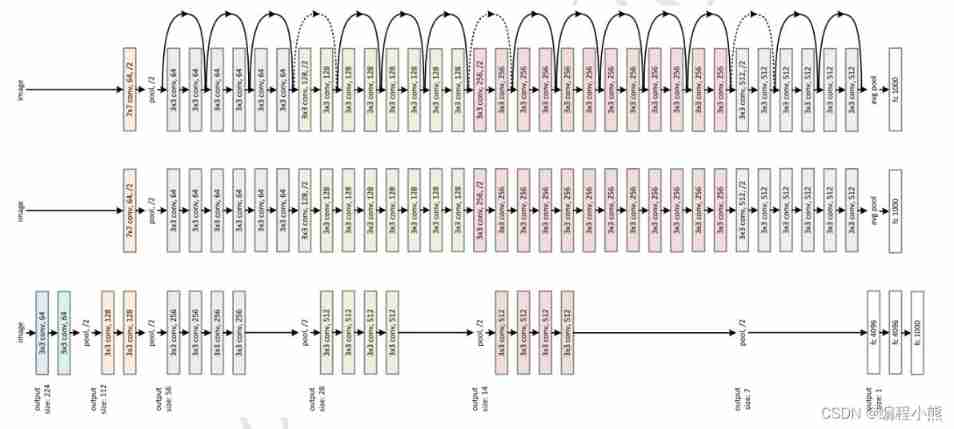
The depth residual network passes through the stack Residual module , Reached a deeper number of network layers , Thus, the training stability is obtained 、 Deep network model with superior performance
Two 、ResBlock Realization
The deep residual network does not add new network layer types , Just by adding a line between input and output Skip Connection, Not for ResNet The underlying implementation of . stay TensorFlow The residual module can be realized by calling the ordinary convolution layer .
First create a new class , Create the convolution layer needed in the residual block in the initialization phase 、 Activate the function layer
# Residual module class
class BasicBlock(layers.Layer):
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# f(x) It contains two ordinary convolution layers
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn2 = layers.BatchNormalization()
# f(x) And x Different shapes , Cannot add
if stride != 1: # It's not equal , Insert identity layer
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # Direct additive
self.downsample = lambda x: x
# Forward propagation function
def call(self, inputs, training=None):
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# Input through identity() transformation
identity = self.downsample(inputs)
# f(x) + x
output = layers.add([out, identity])
# Then activate the function , It's OK to put it in front
output = tf.nn.relu(output)
return output First new ℱ(𝑥) Convolution layer , When ℱ(𝒙) The shape and shape of 𝒙 Different time , Cannot add directly , We need new identity(𝒙) Convolution layer , To complete 𝒙 Shape conversion . In forward propagation , Only need to ℱ(𝒙) And identity(𝒙) Add up , And add ReLU Activate the function
RseNet By stacking multiple ResBlock It can form a complex deep neural network , Such as ResNet18,ResNet34......
3、 ... and 、DenseNet
DenseNet take Feature map information of all previous layers adopt Skip Connection Aggregate with the current layer output , And ResNet The corresponding positions of are added in different ways , DenseNet Used in the channel shaft 𝑐 Join dimensions , Aggregate feature information
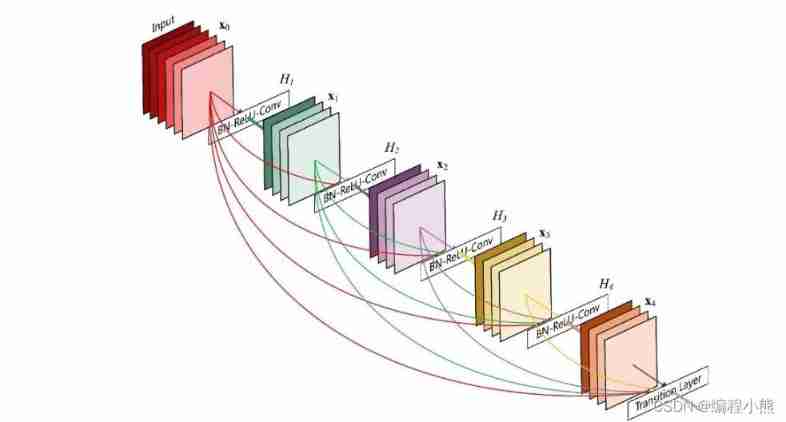
Input 𝑿0 adopt H1 The convolution layer obtains the output 𝑿1, 𝑿1 And 𝑿0 Splice on the channel shaft , Get the characteristic tensor after aggregation , Send in H2 Convolution layer , Get the output 𝑿2, Same method , 𝑿2 Characteristic information of all previous layers 𝑿1 And 𝑿0 Aggregate , Into the next layer . So circular , Until the output of the last layer 𝑿4 And the characteristic information of all previous layers : {𝑿𝑖}𝑖=0, 1, 2, 3 Aggregate to get the final output of the module , Such a be based on Skip Connection Densely connected modules are called Dense Block
DenseNet By stacking multiple Dense Block It can form a complex deep neural network
边栏推荐
- [unity] how to export FBX in untiy
- Delete external table source data
- My seven years with NLP
- librosa音频处理教程
- pymongo获取一列数据
- AttributeError: Can‘t get attribute ‘SPPF‘ on <module ‘models.common‘ from ‘/home/yolov5/models/comm
- LeetCode每日一题(1997. First Day Where You Have Been in All the Rooms)
- Supporting title of the book from 0 to 1: ctfer's growth road (Zhou Geng)
- 我的创作纪念日
- Bitcoinwin (BCW): the lending platform Celsius conceals losses of 35000 eth or insolvency
猜你喜欢

The internationalization of domestic games is inseparable from professional translation companies
同事上了个厕所,我帮产品妹子轻松完成BI数据产品顺便得到奶茶奖励
At the age of 26, I changed my career from finance to software testing. After four years of precipitation, I have been a 25K Test Development Engineer

【服务器数据恢复】IBM服务器raid5两块硬盘离线数据恢复案例
【每日一题】729. 我的日程安排表 I
26岁从财务转行软件测试,4年沉淀我已经是25k的测开工程师...
LeetCode每日一题(971. Flip Binary Tree To Match Preorder Traversal)
ROS learning_ Basics
机器人类专业不同层次院校课程差异性简述-ROS1/ROS2-

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
随机推荐
Windows Server 2016 standard installing Oracle
UniPro甘特图“初体验”:关注细节背后的多场景探索
我的创作纪念日
Number of query fields
A method to measure the similarity of time series: from Euclidean distance to DTW and its variants
SAP SD发货流程中托盘的管理
Brief introduction to the curriculum differences of colleges and universities at different levels of machine human major -ros1/ros2-
Fast target recognition based on pytorch and fast RCNN
On the first day of clock in, click to open a surprise, and the switch statement is explained in detail
Do you really know the use of idea?
Misc of BUU (update from time to time)
Due to high network costs, arbitrum Odyssey activities are suspended, and nitro release is imminent
ROS学习_基础
The registration password of day 239/300 is 8~14 alphanumeric and punctuation, and at least 2 checks are included
Market segmentation of supermarket customers based on purchase behavior data (RFM model)
BIO模型实现多人聊天
My seven years with NLP
Simple query cost estimation
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Office doc add in - Online CS