当前位置:网站首页>用MLP代替掉Self-Attention
用MLP代替掉Self-Attention
2022-07-02 07:51:00 【MezereonXP】
用MLP代替掉Self-Attention
這次介紹的清華的一個工作 “Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”
用兩個線性層代替掉Self-Attention機制,最終實現了在保持精度的同時實現速度的提昇。
這個工作讓人意外的是,我們可以使用MLP代替掉Attention機制,這使我們應該重新好好考慮Attention帶來的性能提昇的本質。
Transformer中的Self-Attention機制
首先,如下圖所示:

我們給出其形式化的結果:
A = softmax ( Q K T d k ) F o u t = A V A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\\ F_{out} = AV A=softmax(dkQKT)Fout=AV
其中, Q , K ∈ R N × d ′ Q,K \in \mathbb{R}^{N\times d'} Q,K∈RN×d′ 同時 V ∈ R N × d V\in \mathbb{R}^{N\times d} V∈RN×d
這裏,我們給出一個簡化版本,如下圖所示:
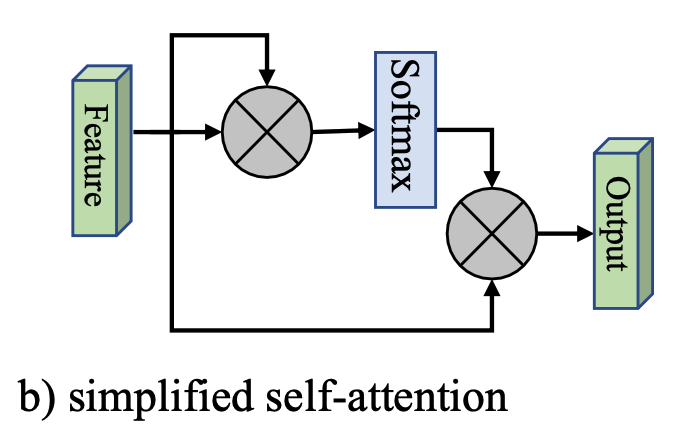
也就是將 Q , K , V Q,K,V Q,K,V 都以輸入特征 F F F 代替掉,其形式化為:
A = softmax ( F F T ) F o u t = A F A = \text{softmax}(FF^T)\\ F_{out} = AF A=softmax(FFT)Fout=AF
然而,這裏面的計算複雜度為 O ( d N 2 ) O(dN^2) O(dN2),這是Attention機制的一個較大的缺點。
外部注意力 (External Attention)
如下圖所示:
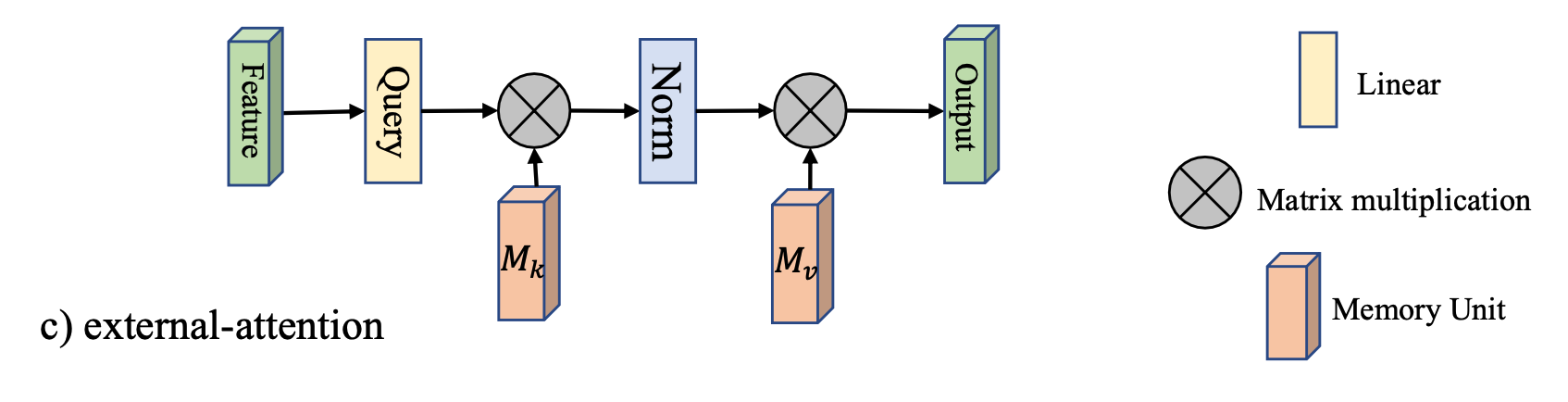
引入了兩個矩陣 M k ∈ R S × d M_k\in \mathbb{R}^{S\times d} Mk∈RS×d 以及 $M_v \in\mathbb{R}^{S\times d} $, 代替掉原來的 K , V K,V K,V
這裏直接給出其形式化:
A = Norm ( F M k T ) F o u t = A M v A = \text{Norm}(FM_k^T)\\ F_{out} = AM_v A=Norm(FMkT)Fout=AMv
這種設計,將複雜度降低到 O ( d S N ) O(dSN) O(dSN), 該工作發現,當 S ≪ N S\ll N S≪N 的時候,仍然能够保持足够的精度。
其中的 Norm ( ⋅ ) \text{Norm}(\cdot) Norm(⋅) 操作是先對列進行Softmax,然後對行進行歸一化。
實驗分析
首先,文章將Transformer中的Attention機制替換掉,然後在各類任務上進行測試,包括:
- 圖像分類
- 語義分割
- 圖像生成
- 點雲分類
- 點雲分割
這裏只給出部分結果,簡單說明一下替換後的精度損失情况。
圖像分類

語義分割

圖像生成

可以看到,在不同的任務上,基本上不會有精度損失。
边栏推荐
- Using compose to realize visible scrollbar
- C#与MySQL数据库连接
- Win10 solves the problem that Internet Explorer cannot be installed
- 《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
- Solve the problem of latex picture floating
- Conversion of numerical amount into capital figures in PHP
- Generate random 6-bit invitation code in PHP
- MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
- Ppt skills
- 【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
猜你喜欢

【Random Erasing】《Random Erasing Data Augmentation》

【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
![[Sparse to Dense] Sparse to Dense: Depth Prediction from Sparse Depth samples and a Single Image](/img/05/bf131a9e2716c9147a5473db4d0a5b.png)
[Sparse to Dense] Sparse to Dense: Depth Prediction from Sparse Depth samples and a Single Image
【Batch】learning notes

【Paper Reading】
![[mixup] mixup: Beyond Imperial Risk Minimization](/img/14/8d6a76b79a2317fa619e6b7bf87f88.png)
[mixup] mixup: Beyond Imperial Risk Minimization

机器学习理论学习:感知机
常见CNN网络创新点
Use Baidu network disk to upload data to the server
【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
随机推荐
Timeout docking video generation
[binocular vision] binocular correction
【MobileNet V3】《Searching for MobileNetV3》
【Programming】
C#与MySQL数据库连接
Using MATLAB to realize: power method, inverse power method (origin displacement)
Use Baidu network disk to upload data to the server
Handwritten call, apply, bind
Drawing mechanism of view (I)
What if a new window always pops up when opening a folder on a laptop
生成模型与判别模型的区别与理解
【双目视觉】双目立体匹配
【学习笔记】Matlab自编高斯平滑器+Sobel算子求导
【Programming】
Implement interface Iterable & lt; T>
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
常见CNN网络创新点
What if the notebook computer cannot run the CMD command
The difference and understanding between generative model and discriminant model
【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》