当前位置:网站首页>【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
2022-07-02 06:26:00 【bryant_meng】


CVPR-2019
文章目录
1 Background and Motivation
作者旨在设计一个新的 resource-constrained mobile model 让其在 resource-constrained platforms 跑的更加欢快
2 Related Work
现有网络的基础上压缩:量化,pruning ,NetAdapt 等,do not focus on learning novel compositions of CNN operations
hand-crafted 设计,usually take significant human efforts
NAS,基于各种 learning algorithms,例如 reinforcement learning / evolutionary search / differentiable search
3 Advantages / Contributions
NAS 出 MnasNet,两个主要创新点
incorporate model latency into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency(不单单是 ACC)
a novel factorized hierarchical search space that encourages layer diversity throughout the network.(不像 NasNet 那样是 cell 级别的,而是 block 级别的)
achieve new state-of-the-art results on both ImageNet classification and COCO object detection under typical mobile inference latency constraints
4 Method
4.1 Problem Formulation
以前方法的 objective function
m m m 是 model, A C C ACC ACC 是 accuracy, L A T LAT LAT 是 inference latency, T T T 是 target latency
上面的 objective 仅考虑了精度,没有考虑速度
作者 more interested in finding multiple Pareto-optimal solutions in a single architecture search(速度和精度的 trade-off)
设计了如下的 objective function

根据 α \alpha α 和 β \beta β 取值的不同,有如下的 soft 和 hard 版
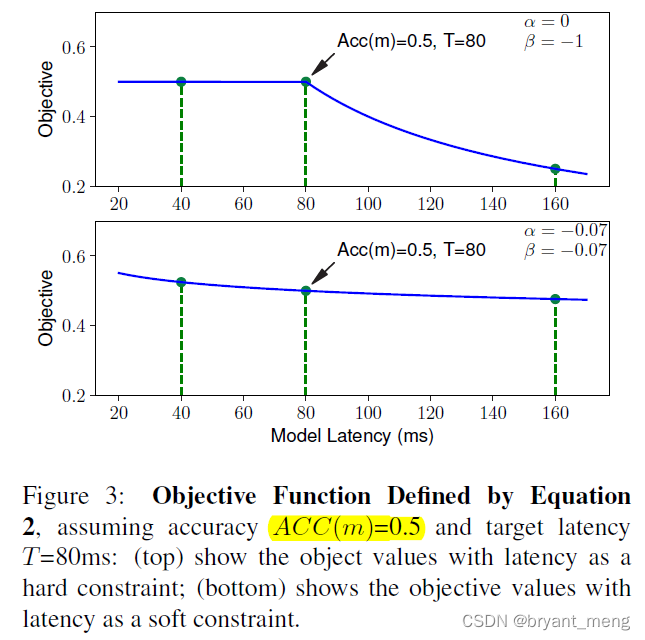
横坐标是 latency,纵坐标为 objective
soft 版本 − 0.07 -0.07 −0.07 的由来如下:
we empirically observed doubling the latency usually brings about 5% relative accuracy gain
R e w a r d ( M 2 ) = a ⋅ ( 1 + % 5 ) ⋅ ( 2 l / T ) β ≈ R e w a r d ( M 1 ) = a ⋅ ( l / T ) β Reward(M2) = a \cdot (1 + %5 ) \cdot (2l/T )^{\beta}\approx Reward(M1) = a \cdot (l/T )^{\beta} Reward(M2)=a⋅(1+%5)⋅(2l/T)β≈Reward(M1)=a⋅(l/T)β
根据上面公式求出来 β ≈ − 0.07 \beta \approx -0.07 β≈−0.07
4.2 Factorized Hierarchical Search Space
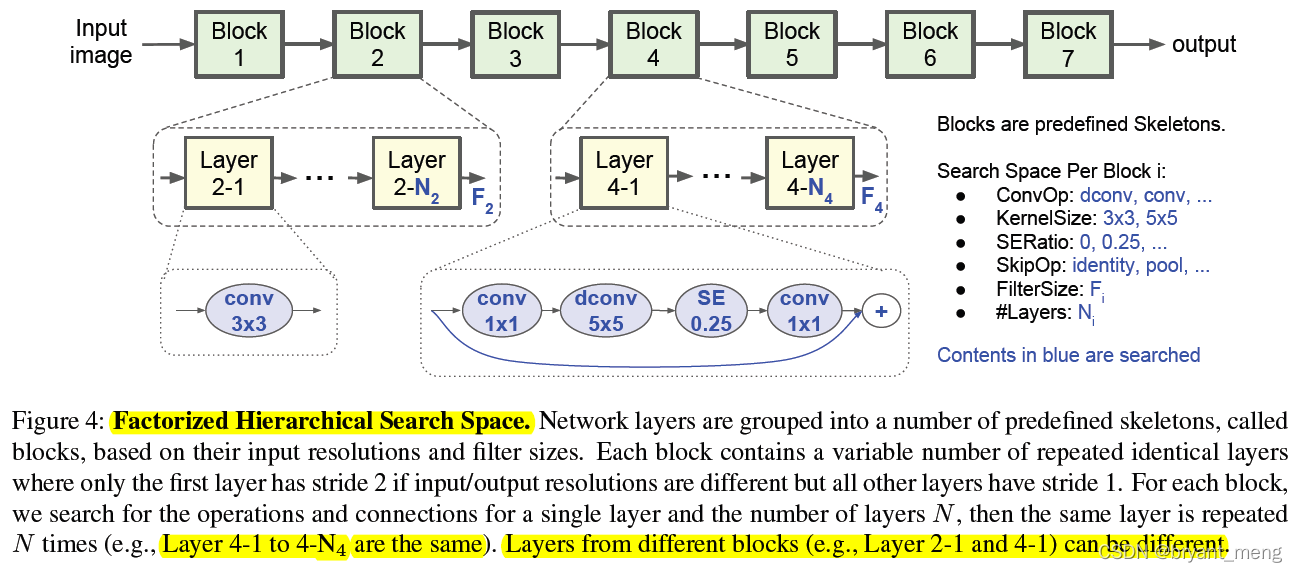
allowing different layer architectures in different blocks
同一个 block 中的 N 个 layer 是一样的,layer 里面的操作如下

搜索的时候 using MobileNetV2 as a reference
每个 layers 数量 {0, +1, -1} based on MobileNetV2
filter size per layer {0.75, 1.0, 1.25} to MobileNetV2
成品结构之一


搜索空间的大小如下:
假设 B B B blocks,and each block has a sub search space of size S S S with average N N N layers per block
搜索空间大小为 S B S^B SB
每个 layer 都不同的话,则为 S B ∗ N S^{B*N} SB∗N
4.3 Search Algorithm

sample-eval-update loop,maximize the expected reward: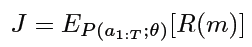
reward value R(m) 用的是 objective function
5 Experiments
5.1 Datasets
directly perform our architecture search on the ImageNet training set but with fewer training steps (5 epochs)
区别于 NasNet 的 Cifar10
5.2 Results
1)ImageNet Classification Performance
T = 75 ms,一次搜索,多个 model A1 / A2 / A3
相比 mobileNet v2,引入了 SE 模块,探讨下 SE 模块的影响
2)Model Scaling Performance
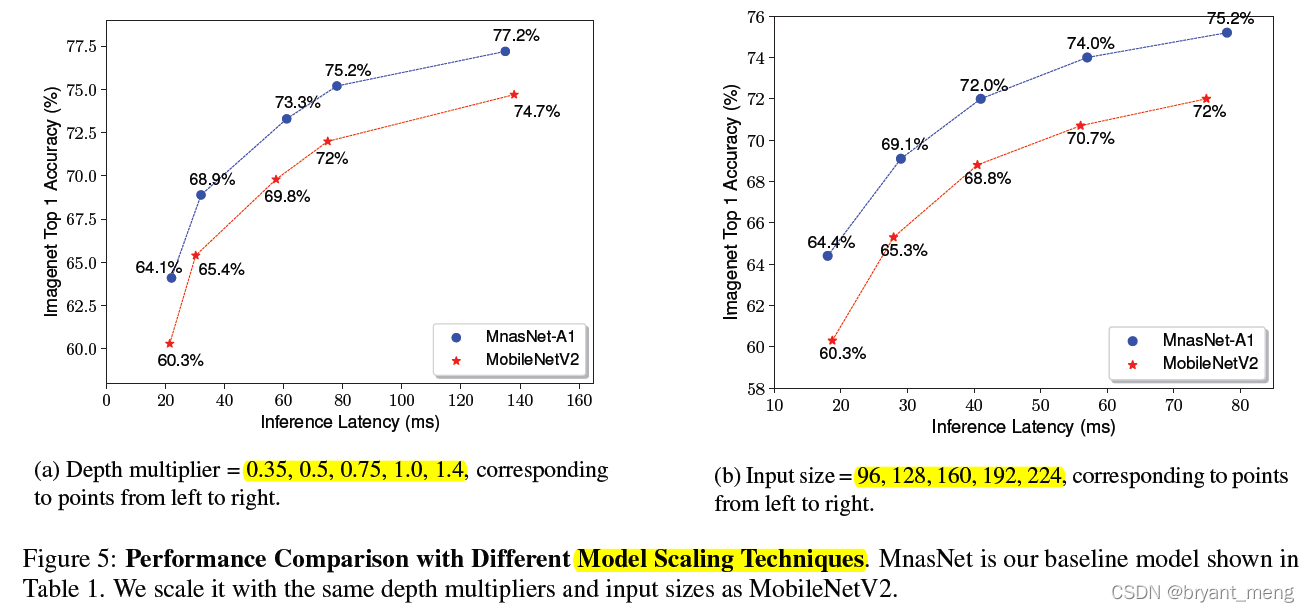
这里的 depth multiplier 指的是 channels,可以看出全方位领先 mobilenet v2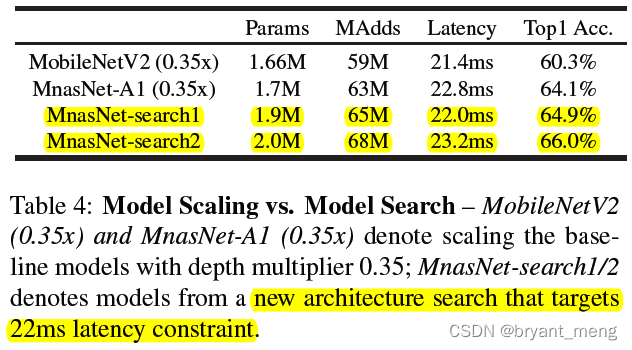
作者也可以灵活的通过改变 NAS 时 T 的值来控制模型的大小,上表可以看出,比在大模型上砍通道数效果更猛
3)COCO Object Detection Performance
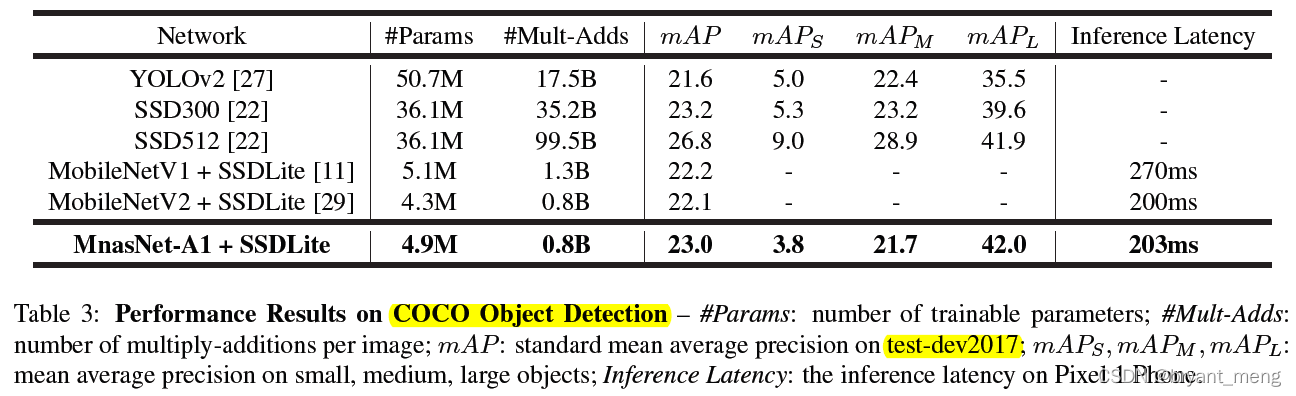
没什么好评论的,都是菜鸡互啄,哈哈,开玩笑哒,有一定提升
5.3 Ablation Study and Discussion
1)Soft vs. Hard Latency Constraint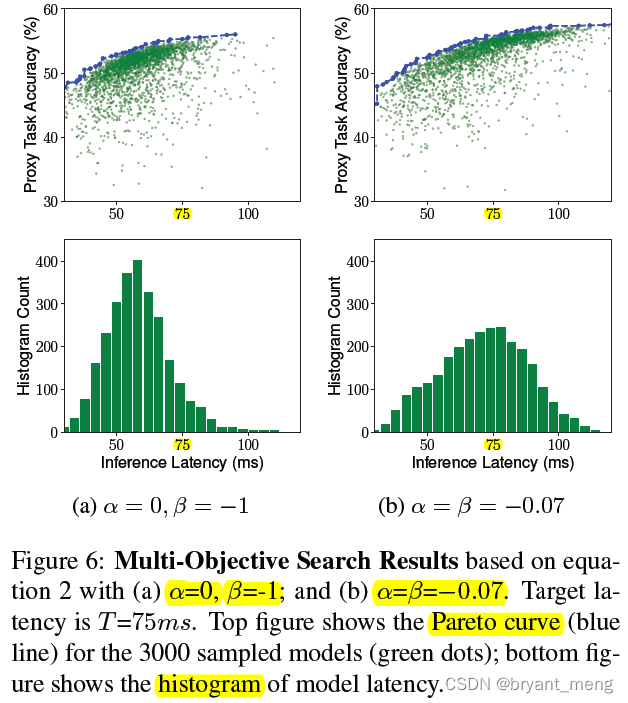
hard 版 focus more on faster models to avoid the latency penalty(objective function 也可以看出)
soft 版 tries to search for models across a wider latency range
2)Disentangling Search Space and Reward

解耦探讨下两个创新点的作用
3)Layer Diversity

6 Conclusion(own)
在 mobilenet v2 基础上搜
Pareto-optimal,帕累托最优(来自百度百科)
帕累托最优(Pareto Optimality),也称为帕累托效率(Pareto efficiency),是指资源分配的一种理想状态,假定固有的一群人和可分配的资源,从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化。
帕累托最优状态就是不可能再有更多的帕累托改进的余地;换句话说,帕累托改进是达到帕累托最优的路径和方法。 帕累托最优是公平与效率的“理想王国”。是由帕累托提出的。
边栏推荐
- Implement interface Iterable & lt; T>
- Drawing mechanism of view (I)
- CONDA common commands
- PHP returns the abbreviation of the month according to the numerical month
- 【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
- Determine whether the version number is continuous in PHP
- Find in laravel8_ in_ Usage of set and upsert
- 《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
- ModuleNotFoundError: No module named ‘pytest‘
- 机器学习理论学习:感知机
猜你喜欢
Memory model of program

SSM student achievement information management system
Cognitive science popularization of middle-aged people

SSM garbage classification management system
SSM personnel management system

Label propagation
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Common CNN network innovations
Implementation of yolov5 single image detection based on onnxruntime

【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
随机推荐
Delete the contents under the specified folder in PHP
Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
[in depth learning series (8)]: principles of transform and actual combat
Proof and understanding of pointnet principle
Win10 solves the problem that Internet Explorer cannot be installed
[introduction to information retrieval] Chapter 1 Boolean retrieval
程序的执行
深度学习分类优化实战
传统目标检测笔记1__ Viola Jones
半监督之mixmatch
[Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
MySQL has no collation factor of order by
Label propagation
Alpha Beta Pruning in Adversarial Search
CPU register
Typeerror in allenlp: object of type tensor is not JSON serializable error
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
Thesis tips
Memory model of program
Latex formula normal and italic