当前位置:网站首页>Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
2022-07-02 07:41:00 【chenf0】
See the previous configuration and the messy problems encountered :https://blog.csdn.net/chenfang0529/article/details/115094036
One 、 export
Use mmdetection Train your own dataset , Dataset use VCAT Annotate , The marked file is a video file , Export image frames and annotation files as COCO Format . There are also PASCAL VOC
Include two files after Export
images and annotations
images Contains image frames 
annotations Include dimension files , We only need to modify the third file .
Two 、 Related codes
1. Batch modify the picture name
import os
class BatchRename():
def rename(self):
path="D:\\achenf\data\\taxi\\test\\task_2_9_car_test-2021_04_13_13_25_24-coco\images"
filelist=os.listdir(path)
total_num = len(filelist)
i=595
for item in filelist:
if item.endswith('.jpg'):
src=os.path.join(os.path.abspath(path),item)
dst=os.path.join(os.path.abspath(path),''+str(i)+'.jpg') # You can choose the format according to your needs
# dst=os.path.join(os.path.abspath(path),'00000'+format(str(i))+'.jpg') # You can choose the format according to your needs , Custom picture name
try:
os.rename(src,dst) #src: old name dst New name d
i+=1
except:
continue
print ('total %d to rename & converted %d png'%(total_num,i))
if __name__=='__main__':
demo = BatchRename()
demo.rename()
2. Bulk changes json The contents of the document
json in id Etc. need to correspond with the picture .
Needed json It contains five parts ,info,categories,licenses,annotations,images
We just need to modify it annotations and images Two parts .
import json
import os
path = 'D:\\achenf\data\\taxi\\train\\task_2_8_car_test-2021_04_13_13_25_07-coco\\annotations\\test'
dirs = os.listdir(path)
num_flag = 0
for file in dirs: # Loop to read the file under the path and filter the output
if os.path.splitext(file)[1] == ".json": # Screening csv file
num_flag = num_flag +1
print("path ===== ",file)
print(os.path.join(path,file))
with open(os.path.join(path,file),'r') as load_f:
load_dict = json.load(load_f)
# print(load_dict)
# n=len(load_dict["image_id"])
# print(type(load_dict))
# for i in load_dict:
# print(i)
for i in load_dict['annotations']:
i['image_id'] = i['image_id'] + 595
i['id']=i['id']+2032
# if i['image_id']>=595:
# i['id']=i['id']+3015
for i in load_dict['images']:
i['id'] = i['id'] + 595
i['file_name'] = ""+str(i['id'])+".jpg"
with open(os.path.join(path,file),'w') as dump_f:
json.dump(load_dict, dump_f)
if(num_flag == 0):
print(' The selected folder does not exist json file , Please re confirm the folder you want to select ')
else:
print(' common {} individual json file '.format(num_flag))
Finally, merge the corresponding parts
3、 ... and 、 other
1. analysis xml file , Check the number of annotations in the file
import os
import xml.dom.minidom
res=0
AnnoPath = r'./file_xml/0512/'
Annolist = os.listdir(AnnoPath)
for annotation in Annolist:
filename =AnnoPath + annotation
dom = xml.dom.minidom.parse(filename) # open XML file
collection = dom.documentElement # Get element object
objectlist = collection.getElementsByTagName('box') # s
count = objectlist.length
res =res+count
print(" file name :", filename," Number of dimensions :", count)
print(" Total labels :", res)
result :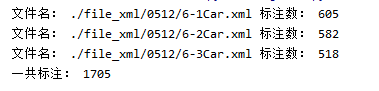
边栏推荐
- Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
- Find in laravel8_ in_ Usage of set and upsert
- Record of problems in the construction process of IOD and detectron2
- Win10 solves the problem that Internet Explorer cannot be installed
- One field in thinkphp5 corresponds to multiple fuzzy queries
- 【Paper Reading】
- 【信息检索导论】第六章 词项权重及向量空间模型
- Deep learning classification Optimization Practice
- Semi supervised mixpatch
- Sparksql data skew
猜你喜欢

Traditional target detection notes 1__ Viola Jones
![[model distillation] tinybert: distilling Bert for natural language understanding](/img/c1/e1c1a3cf039c4df1b59ef4b4afbcb2.png)
[model distillation] tinybert: distilling Bert for natural language understanding

Classloader and parental delegation mechanism

【信息检索导论】第三章 容错式检索
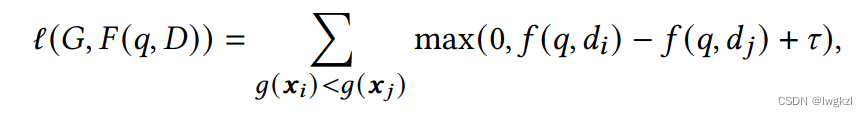
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
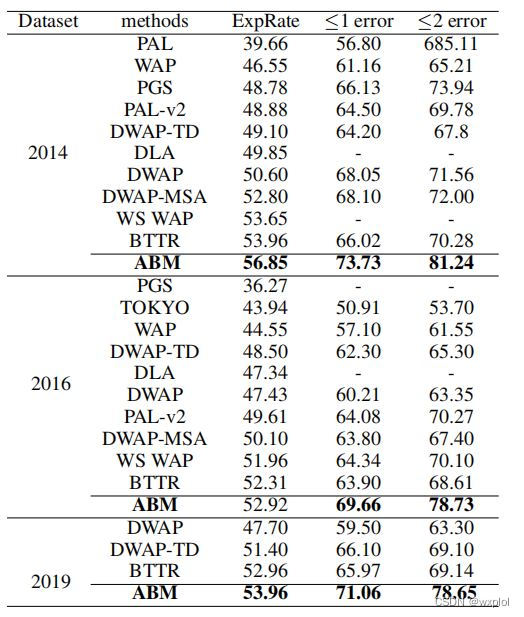
ABM thesis translation

Feeling after reading "agile and tidy way: return to origin"
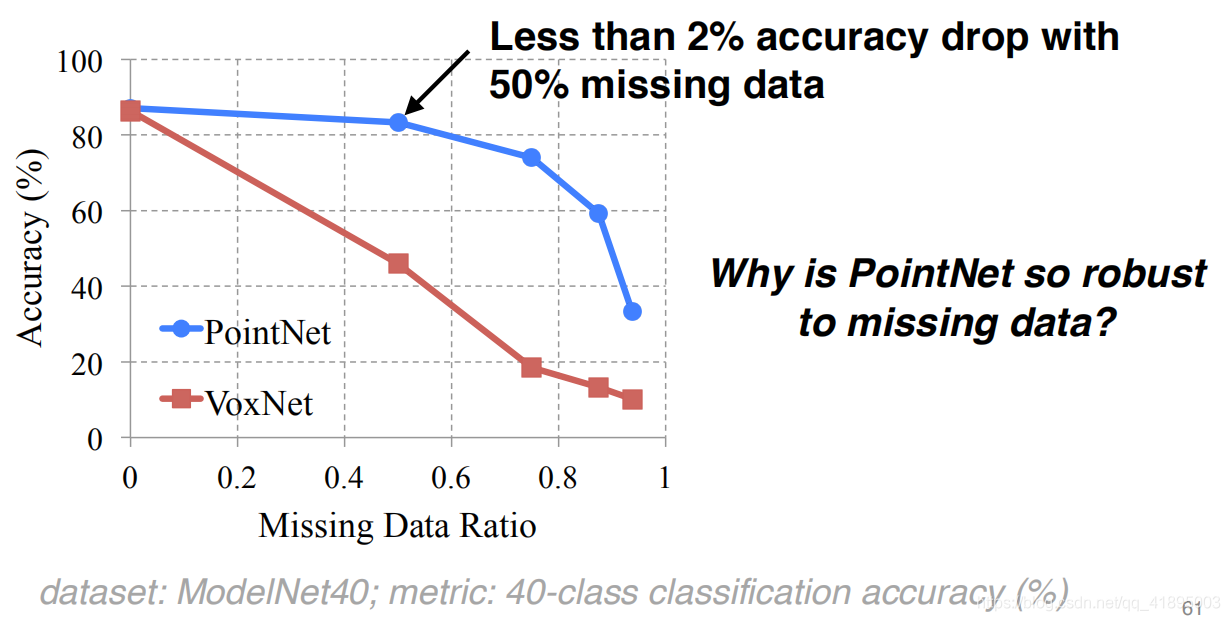
PointNet理解(PointNet实现第4步)
win10+vs2017+denseflow编译
常见CNN网络创新点
随机推荐
Win10+vs2017+denseflow compilation
【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》
《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
【TCDCN】《Facial landmark detection by deep multi-task learning》
Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
【信息检索导论】第三章 容错式检索
Drawing mechanism of view (II)
Open failed: enoent (no such file or directory) / (operation not permitted)
传统目标检测笔记1__ Viola Jones
Huawei machine test questions
常见的机器学习相关评价指标
使用百度网盘上传数据到服务器上
Using MATLAB to realize: power method, inverse power method (origin displacement)
Two dimensional array de duplication in PHP
Cognitive science popularization of middle-aged people
程序的内存模型
基于pytorch的YOLOv5单张图片检测实现
Delete the contents under the specified folder in PHP
【信息检索导论】第一章 布尔检索
CPU的寄存器