当前位置:网站首页>【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
2022-07-02 06:26:00 【bryant_meng】


ICRA-2019
文章目录
1 Background and Motivation
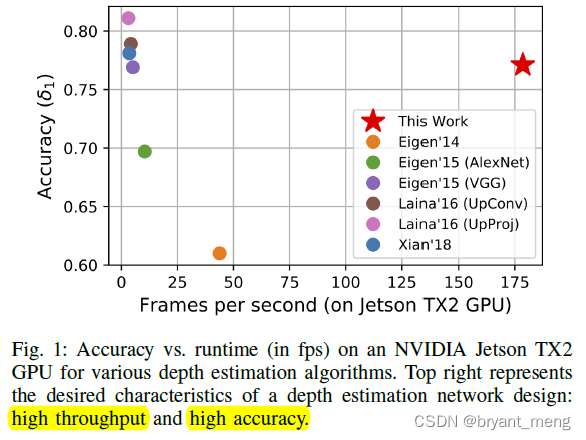
加速现有单目深度估计模型,使其不太损失精度的同时有较低延迟,能在 micro aerial vehicle 部署运行,辅助 mapping, localization, and obstacle avoidance 等 robotic tasks
2 Related Work
- Monocular Depth Estimation
- Efficient Neural Networks
- Network Pruning
3 Advantages / Contributions
加速单目深度估计模型:
- a low-complexity and low-latency decoder design
- a state-of-the-art pruning algorithm(NetAdapt 剪枝)
- Hardware-specific compilation(TVM 部署 DWConv 优化)
4 Method
1)整体结构
朴实无华的 U-Net 结构,skip connection 用的 add(没用 concat,avoid increasing the number of feature map channels)
upsample layer 细节如下

conv5(深度可分离卷积) + linear interpolation(相比于双线性,底层实现简单通用)
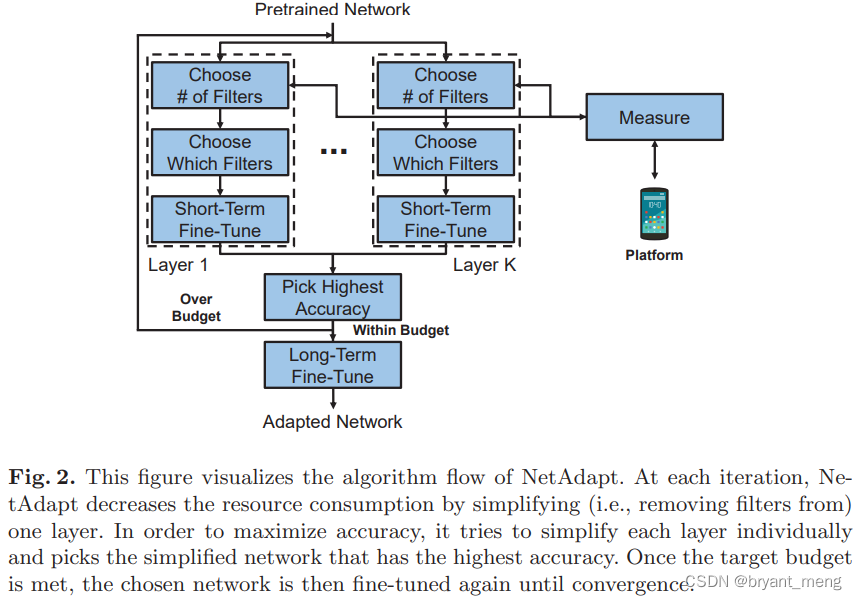
2)Network Pruning
用的 NetAdapt 方法来剪枝
《NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications》

就比较暴力和直接,下面的图更直观一些
3)Network Compilation
用 TVM 来加速 DWConv
参考:
TVM是一个支持 GPU、CPU、FPGA指令生成的开源编译器框架
TVM最大的特点是基于图和算符结构来优化指令生成,最大化硬件执行效率,它向上对接Tensorflow、Pytorch等深度学习框架,向下兼容GPU、CPU、ARM、TPU等硬件设备
TVM是一个端到端的指令生成器。它从深度学习框架中接收模型输入,然后进行图的转化和基本的优化,最后生成指令完成到硬件的部署。
TVM有两个主要特性:
- 支持将Keras、MxNet、PyTorch、Tensorflow、CoreML、DarkNet框架的深度学习模型编译为多种硬件后端的最小可部署模型。
- 能够自动生成和优化多个后端的张量操作并达到更好的性能。
下面感受下整体框架

再感受一下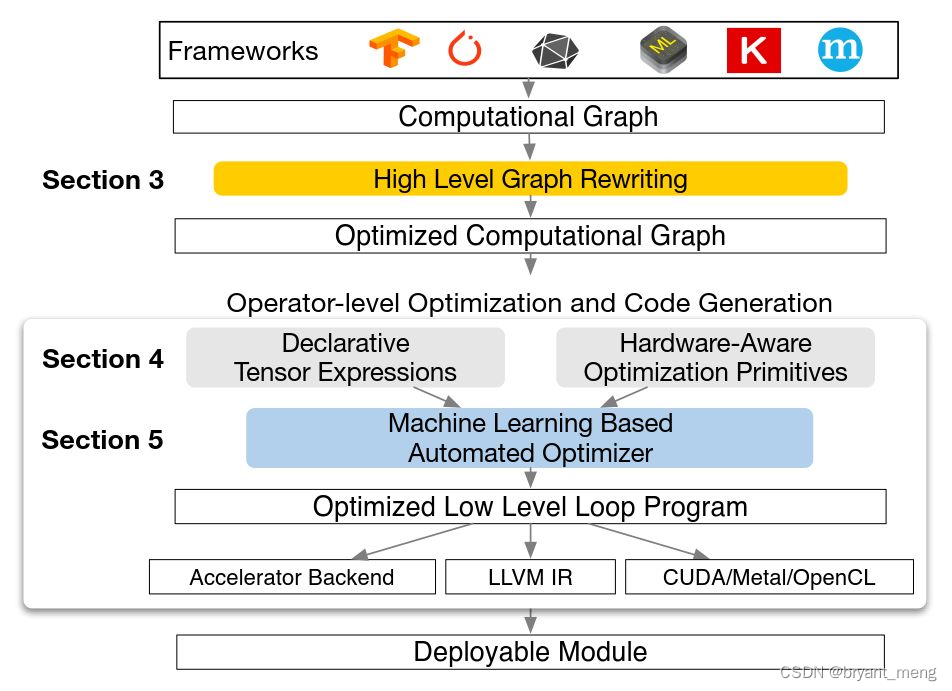
再再再感受一下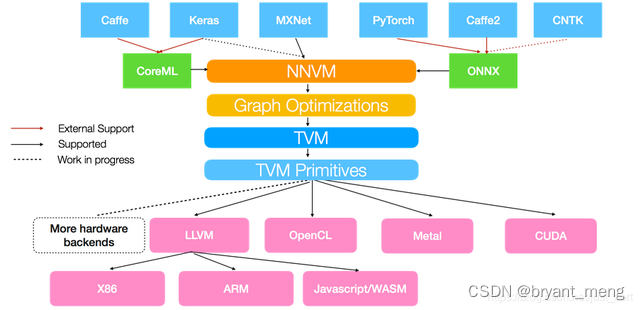
5 Experiments
5.1 Datasets

评价指标
δ 1 \delta1 δ1 (the percentage of predicted pixels where the relative error is within 25%),越大越好
RMSE (root mean squared error),越小越好
5.2 Final Results and Comparison With Prior Work
实验平台

NVIDIA Jetson TX2 系列模组可为嵌入式 AI 计算设备提供出色的速度与能效。配备NVIDIA Pascal GPU、高达 8 GB 内存、59.7 GB/s 的显存带宽以及各种标准硬件接口,每款超级计算机模组将真正的AI计算带到边缘端。
相比 encoder,decoder占了更多 runtime,需要重点优化
Jetson TX2 in high performance (max-N) 模式下,和其他方法对比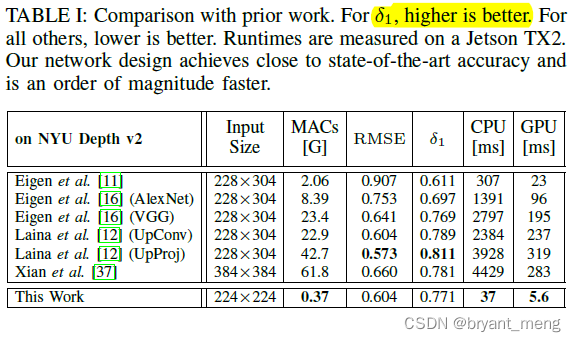
Jetson TX2 in high energy-efficiency (max-Q) 模式下的结果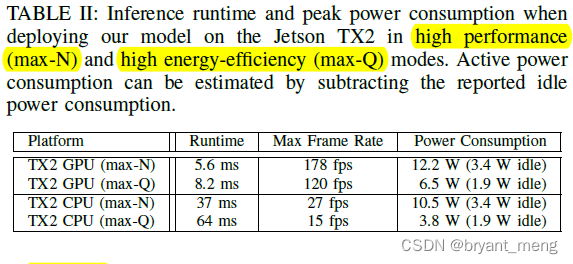
可视化结果如下,the error is highest at boundaries and at distant objects.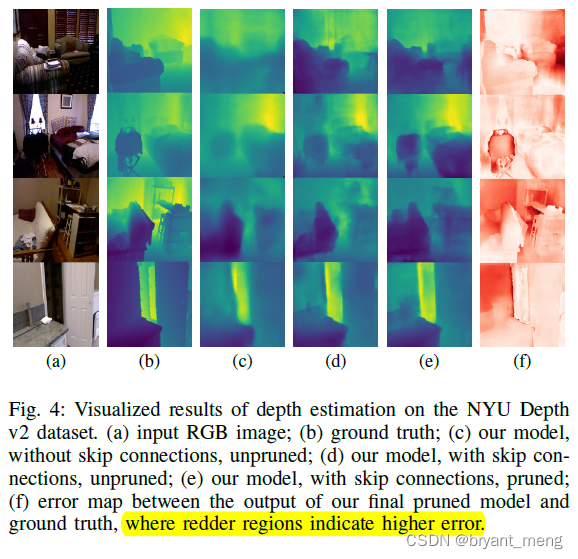
(c) 和(d)区别是 skip connection,(d)精细化了很多
5.3 Ablation Study
1)Encoder Design Space
选择的是 MobileNet,速度精度最好的权衡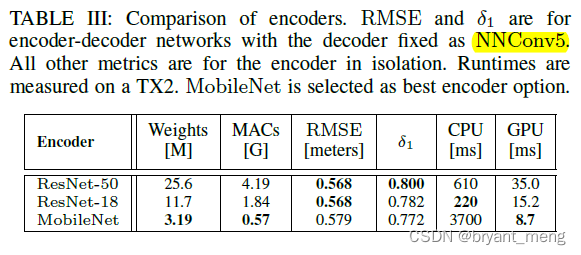
2)Decoder Design Space
Upsample Operation,也即图 2 中的 upsample layer

(a)和(b)中的上采样操作是补零了 zero-insertion,(d)是 nearest neighbor interpolation

Depthwise Separable Convolution and Skip Connections

3)Hardware-Specific Optimization
把 DWConv 发挥到了进一步逼近理论压缩率的程度
4)Network Pruning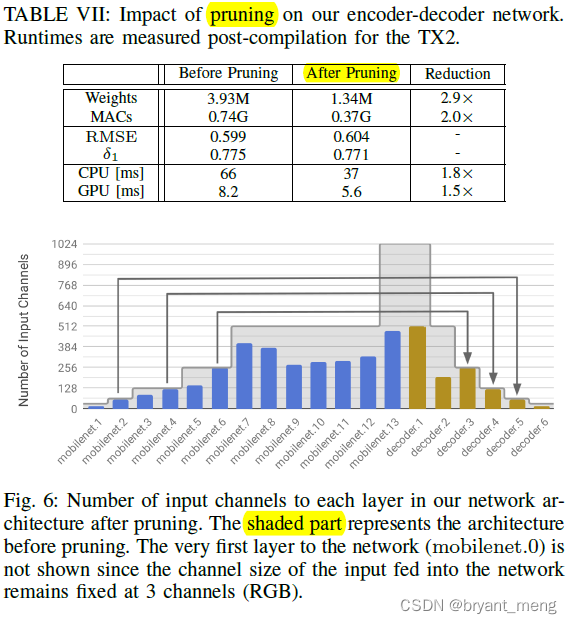
6 Conclusion(own) / Future work
更像是竞赛的技术报告!!!
code:https://github.com/dwofk/fast-depth
边栏推荐
- [torch] some ideas to solve the problem that the tensor parameters have gradients and the weight is not updated
- Conda 创建,复制,分享虚拟环境
- Play online games with mame32k
- [introduction to information retrieval] Chapter 3 fault tolerant retrieval
- SSM student achievement information management system
- 解决latex图片浮动的问题
- 常见CNN网络创新点
- Sparksql data skew
- Feeling after reading "agile and tidy way: return to origin"
- SSM supermarket order management system
猜你喜欢
图片数据爬取工具Image-Downloader的安装和使用
Agile development of software development pattern (scrum)
SSM laboratory equipment management

基于pytorch的YOLOv5单张图片检测实现
Alpha Beta Pruning in Adversarial Search

腾讯机试题

How do vision transformer work?【论文解读】

超时停靠视频生成
【Ranking】Pre-trained Language Model based Ranking in Baidu Search

A slide with two tables will help you quickly understand the target detection
随机推荐
Three principles of architecture design
使用Matlab实现:幂法、反幂法(原点位移)
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
Using compose to realize visible scrollbar
PHP returns the abbreviation of the month according to the numerical month
Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
win10解决IE浏览器安装不上的问题
How do vision transformer work?【论文解读】
机器学习理论学习:感知机
论文tips
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
Huawei machine test questions-20190417
SSM personnel management system
Using MATLAB to realize: power method, inverse power method (origin displacement)
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
[model distillation] tinybert: distilling Bert for natural language understanding
label propagation 标签传播
使用Matlab实现:弦截法、二分法、CG法,求零点、解方程
Common CNN network innovations
Delete the contents under the specified folder in PHP