当前位置:网站首页>[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
2022-07-02 07:42:00 【Xiao Chen who wants money】
Title: Temporal Alignment Networks for Long-term Video
author :Tengda Han, Weidi Xie, and Andrew Zisserman
Publishing unit :Visual Geometry Group, University of Oxford and Shanghai Jiao Tong University
key word :clip、video
The paper :https://arxiv.org/pdf/2204.02968.pdf
First of all, I'm not in the direction of video , If there is a mistake , Welcome to correct .
Abstract
The goal of this paper is to establish a time aligned network , The network absorbs long-term video sequences and related text sentences , In order to :(1) Determine whether the sentence is aligned with the video ; and (2) If it can be aligned , Then determine its alignment . The challenge is from large-scale data sets ( Such as HowTo100M) Training such a network , The relevant text sentences have significant noise , And there is only weak alignment in Correlation .
In addition to proposing alignment Networks , We have also made four contributions :(i) We describe a new Collaborative training methods , This method can be used in the case of large noise , Do not use manual annotation to denoise and train the original teaching video ;(ii) To benchmark alignment performance , We Manual curate One. 10 Hours of HowTo100M A subset of , in total 80 A video , Its time description is very few . Our model , after HowTo100M Training for , Stronger than baseline on this aligned dataset (CLIP,MIL-NCE) There are great advantages ;(iii) We apply the zero shot training model to multiple downstream video understanding tasks , And realize the most Advanced results , Include YouCook2 Text video retrieval on , And weak supervised video action segmentation on breakfast action ;(iv) We use automaticallyaligned HowTo100M Notes fine tune the trunk model end-to-end , And get better performance in the downstream action recognition task .
Preliminary knowledge
Video alignment
As shown in the figure below , I just hope that words and pictures can correspond , Blue represents aligned text , Orange means that the text is not aligned ( Because this sentence may describe the taste of real objects , Time and so on ).

Task description
Given an untrimmed video X={I,S}, among I={I1,I2, ..., IT},T On behalf of T A frame .S={S1,...,Sk},K representative K A sentence ( Sort by time ). For the first k A sentence , We have the corresponding timestamp ([t_k^start, t_k^end]). Our goal is to pass a nonlinear function  obtain {y_hat, A_hat}.
obtain {y_hat, A_hat}.

among ,y_hat Is a binary number of all sentences , So the dimension is K*2. This binary number represents whether the sentence is an aligned text .A_hat Is an alignment matrix of image and text .
TAN
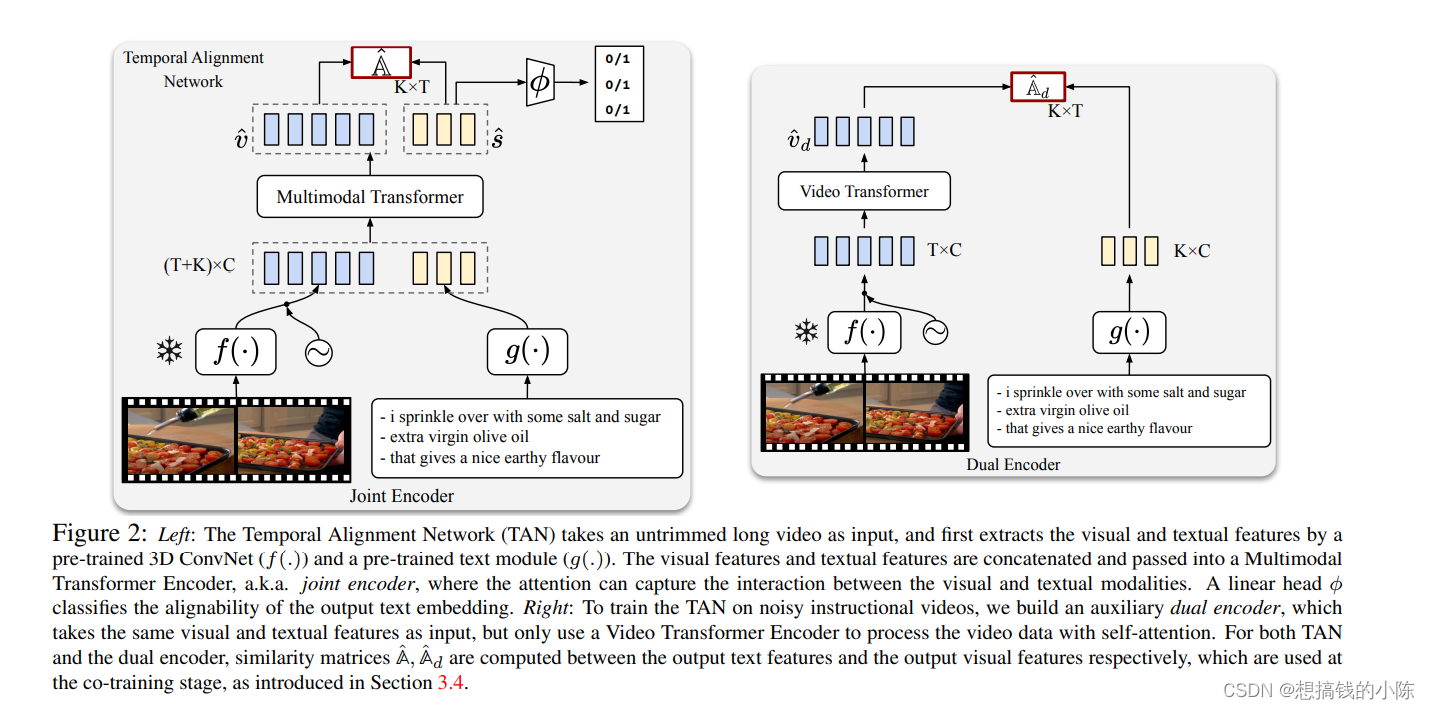
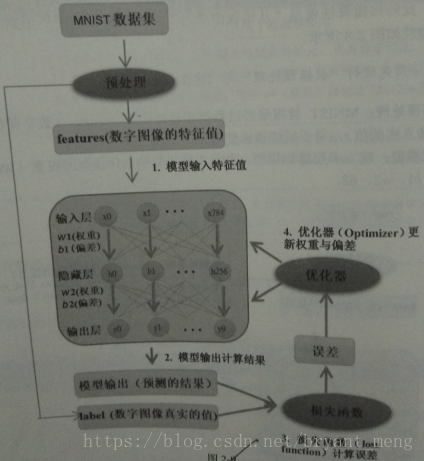
TAN The structure of is shown on the left of the above figure . The picture passes S3D-G backbone The extracted features , obtain vision token, Text through word2vec embedding+ 2 linear obtain text token, The two go through one multimodal transformer Get... With interactive information  and
and  . These two are passing cosine similarity Calculate an alignment matrix . meanwhile , use 1 individual linear layer To output y_hat. The formula is summarized as follows :
. These two are passing cosine similarity Calculate an alignment matrix . meanwhile , use 1 individual linear layer To output y_hat. The formula is summarized as follows :

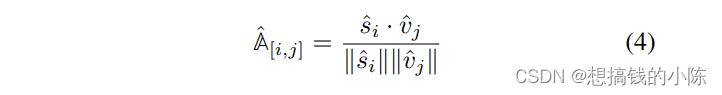

Training
Learn by contrast .InfoNCE. The formula is shown in figure .( This part is a little unclear )

Co-training
co-training Is the core , The author first puts forward a dual encoder, Pictured 2 Shown on the right of ,dual encoder There is no information interaction , There is information exchange only when the matrix is finally calculated . The author believes that this can make the model more sensitive .

Pictured 3(a) And graph 3(b) Shown , This is a TAN and dual encoder The similarity matrix of , union TAN and Dual encoder Output , take TAN The output of Dual-Encoder The output calculation of IoU, If a threshold is exceeded , Then we will 2 Make an output of the and pseudo-labels. If the threshold is not exceeded , Then keep the previous label .
边栏推荐
- [CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
- Faster-ILOD、maskrcnn_benchmark训练自己的voc数据集及问题汇总
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
- Ppt skills
- Implementation of yolov5 single image detection based on onnxruntime
- 【信息检索导论】第一章 布尔检索
- Tencent machine test questions
- Using MATLAB to realize: power method, inverse power method (origin displacement)
- Implementation of purchase, sales and inventory system with ssm+mysql
- 【Paper Reading】
猜你喜欢

Implementation of purchase, sales and inventory system with ssm+mysql

Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
Win10+vs2017+denseflow compilation
MySQL has no collation factor of order by

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
【Programming】

Label propagation

mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作

Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
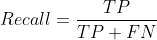
常见的机器学习相关评价指标
随机推荐
Calculate the difference in days, months, and years between two dates in PHP
MMDetection模型微调
[paper introduction] r-drop: regulated dropout for neural networks
Delete the contents under the specified folder in PHP
Jordan decomposition example of matrix
Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
【信息检索导论】第六章 词项权重及向量空间模型
PPT的技巧
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
MySQL has no collation factor of order by
Huawei machine test questions-20190417
Ding Dong, here comes the redis om object mapping framework
PointNet理解(PointNet实现第4步)
ABM论文翻译
生成模型与判别模型的区别与理解
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
[introduction to information retrieval] Chapter 7 scoring calculation in search system
One field in thinkphp5 corresponds to multiple fuzzy queries
Optimization method: meaning of common mathematical symbols
【Ranking】Pre-trained Language Model based Ranking in Baidu Search