当前位置:网站首页>透彻理解LRU算法——详解力扣146题及Redis中LRU缓存淘汰
透彻理解LRU算法——详解力扣146题及Redis中LRU缓存淘汰
2022-07-06 09:21:00 【李孛欢】
LRU(Least Recently Used,最近最久未使用)是一种常见的页面置换算法,其思想很朴素:它认为刚刚被访问的数据,肯定还会被再次访问,而长久未背访问的数据,肯定就不会再被访问了,在缓存满时,就优先删除它。
这种是数据结构题 用简单数据结构拼接 这里用双向链表加哈希表(key存数据的key value存节点(数据key和value打包为一个节点)) 保证put get的时间复杂度都是O(1)。用一个哈希表和一个双向链表维护所有在缓存中的键值对。双向链表按照被使用的顺序存储了这些键值对,靠近尾部的键值对是最近使用的,而靠近头部的键值对是最久未使用的。
Leetcode146:

代码实现:
首先我们将双向链表的节点类写出来:包括key,value(默认是int类型),以及前驱节点和后继节点
public static class Node{
public int key;
public int value;
public Node pre;
public Node next;
public Node(int key, int value){
this.key = key;
this.value = value;
}
}再根据节点类构建双向链表:
public static class NodeDoubleLinkedList{
private Node head;
private Node tail;
public NodeDoubleLinkedList(){
//无参构造
head = null;
tail = null;
}
//LRU缓存需要的三个方法 一个添加节点到尾部 一个将节点更新到尾部(调整优先级) 一个删除头节点的方法(对应着逐出最久未使用的关键字)
public void addNode(Node node){
if(node == null){
return;
}
if(head == null){
//也就是双向链表还没有节点
head = node;
tail = node;
}else{
//否则放入尾部 左边是头,右边是尾
tail.next = node;
node.pre = tail;
tail = node;
}
}
//node入参 一定保证node在双向链表里
//node原始位置左右重新连好再把node分离出来挂到尾巴上
//这里需要结合题目调整优先级 因为get操作后 这个节点是被操作了 那么他就要放在双向链表的尾巴上表示最近被操作的节点
public void moveNodeTotail(Node node){
//分离
if(node == tail){
return;
}
if(head == node){
//头部节点和中间节点的调整是不一样的 中间节点前后都有节点
head = head.next;//头要移动到尾了 所以头先后移一位
head.pre = null;//再指向空,断开指向head的指针
}else{
//将指向node的指针断开!!
node.pre.next = node.next;
node.next.pre = node.pre;
}
//添加
node.pre = tail;
node.next = null;
tail.next = node;
tail = node;
}
public Node removeHead(){
if(head == null){
return null;
}
Node res = head;
if(head == tail){
head = null;
tail = null;
}else{
head = res.next;
//讲头节点分离
res.next = null;
head.pre = null;
}
return res;
}
}有了双向链表的实现,我们只需要在 LRU 算法中把它和哈希表结合起来即可:
private HashMap<Integer,Node> map;
private NodeDoubleLinkedList nodelist;
int cap;
public LRUCache(int capacity) {
map = new HashMap<>();
nodelist = new NodeDoubleLinkedList();
cap = capacity;
}
public int get(int key) {
if(map.containsKey(key)){
Node res = map.get(key);
nodelist.moveNodeTotail(res);
return res.value;
}
return -1;
}
public void put(int key, int value) {
//同时put进map和双向链表内
if(map.containsKey(key)){//更新
Node node = map.get(key);
node.value = value;
//最近操作了 放入尾部
nodelist.moveNodeTotail(node);
}else{
//新增操作
Node newNode = new Node(key,value);
map.put(key,newNode);
nodelist.addNode(newNode);
if(map.size() == cap + 1){
//超出了容量 删除头
Node remove = nodelist.removeHead();
//哈希表的也要删了
map.remove(remove.key);
}
}
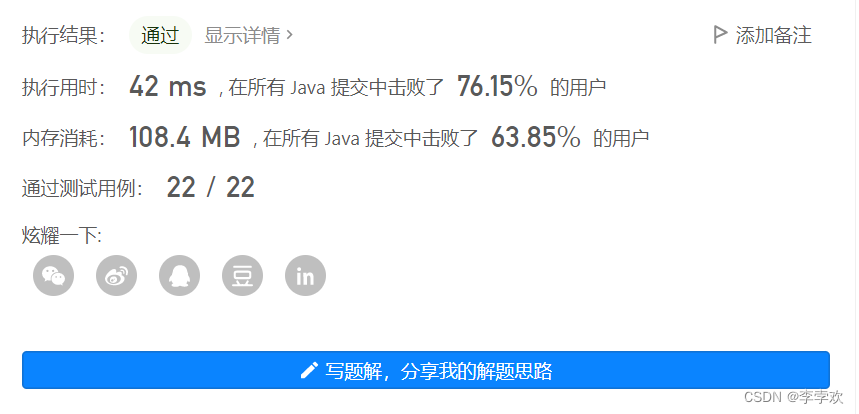
}执行结果:
接下来我们来看Redis中的lru缓存!!
Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略。我们可以按照是否会进行数据淘汰把它们分成两类:不进行数据淘汰的策略,只有 noeviction 这一种。会进行淘汰的 7 种其他策略。会进行淘汰的 7 种策略,我们可以再进一步根据淘汰候选数据集的范围把它们分成两类:在设置了过期时间的数据中进行淘汰,包括 volatile-random、volatile-ttl、volatile-lru、volatile-lfu(Redis 4.0 后新增)四种。在所有数据范围内进行淘汰,包括 allkeys-lru、allkeys-random、allkeys-lfu(Redis 4.0 后新增)三种。
可以看到,redis有两种缓存淘汰策略均用到了LRU算法,不过,LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到尾端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
所以,在 Redis 中,LRU 算法被做了简化,以减轻数据淘汰对缓存性能的影响。具体来说,Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)。然后,Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。
Redis 提供了一个配置参数 maxmemory-samples,这个参数就是 Redis 选出的数据个数 N。例如,我们执行如下命令,可以让 Redis 选出 100 个数据作为候选数据集:
CONFIG SET maxmemory-samples 100当需要再次淘汰数据时,Redis 需要挑选数据进入第一次淘汰时创建的候选集合。这时的挑选标准是:能进入候选集合的数据的 lru 字段值必须小于候选集合中最小的 lru 值。当有新数据进入候选数据集后,如果候选数据集中的数据个数达到了 maxmemory-samples,Redis 就把候选数据集中 lru 字段值最小的数据淘汰出去。
这样一来,Redis 缓存不用为所有的数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能。
边栏推荐
猜你喜欢

13 power map
C语言入门指南
3.输入和输出函数(printf、scanf、getchar和putchar)

8. C language - bit operator and displacement operator
(超详细onenet TCP协议接入)arduino+esp8266-01s接入物联网平台,上传实时采集数据/TCP透传(以及lua脚本如何获取和编写)
Pit avoidance Guide: Thirteen characteristics of garbage NFT project
Conceptual model design of the 2022 database of tyut Taiyuan University of Technology
一段用蜂鸣器编的音乐(成都)
3.C语言用代数余子式计算行列式
Redis的两种持久化机制RDB和AOF的原理和优缺点
随机推荐
vector
5.函数递归练习
TYUT太原理工大学2022数据库大题之数据库操作
arduino+DS18B20温度传感器(蜂鸣器报警)+LCD1602显示(IIC驱动)
(超详细onenet TCP协议接入)arduino+esp8266-01s接入物联网平台,上传实时采集数据/TCP透传(以及lua脚本如何获取和编写)
9. Pointer (upper)
8.C语言——位操作符与位移操作符
Alibaba cloud microservices (III) sentinel open source flow control fuse degradation component
Cloud native trend in 2022
Service ability of Hongmeng harmonyos learning notes to realize cross end communication
Cookie和Session的区别
【手撕代码】单例模式及生产者/消费者模式
C language Getting Started Guide
【九阳神功】2018复旦大学应用统计真题+解析
ROS machine voice
View UI Plus 发布 1.2.0 版本,新增 Image、Skeleton、Typography组件
View UI Plus 发布 1.3.0 版本,新增 Space、$ImagePreview 组件
Relational algebra of tyut Taiyuan University of technology 2022 database
最新坦克大战2022-全程开发笔记-3
View UI Plus 发布 1.1.0 版本,支持 SSR、支持 Nuxt、增加 TS 声明文件