当前位置:网站首页>Single machine high concurrency model design
Single machine high concurrency model design
2022-07-08 00:10:00 【Abbot's temple】
background
In the microservices architecture , We are used to using multiple machines 、 Distributed storage 、 Cache to support a highly concurrent request model , It ignores how the single machine high concurrency model works . This article deconstructs the process of establishing connection and data transmission between client and server , Explain how to design a single machine high concurrency model .
classic C10K problem
How to serve on a physical machine at the same time 10K user , And 10000 Users , about java For the programmer , It's not difficult , Use netty It can be built to support concurrency more than 10000 The server of . that netty How is it realized ? First we forget netty, Analyze from the beginning . One connection per user , There are two things about the server
Manage this 10000 A connection
Handle 10000 Connected data transmission
TCP Connection and data transmission
Connection is established
We take common TCP For example, connection .
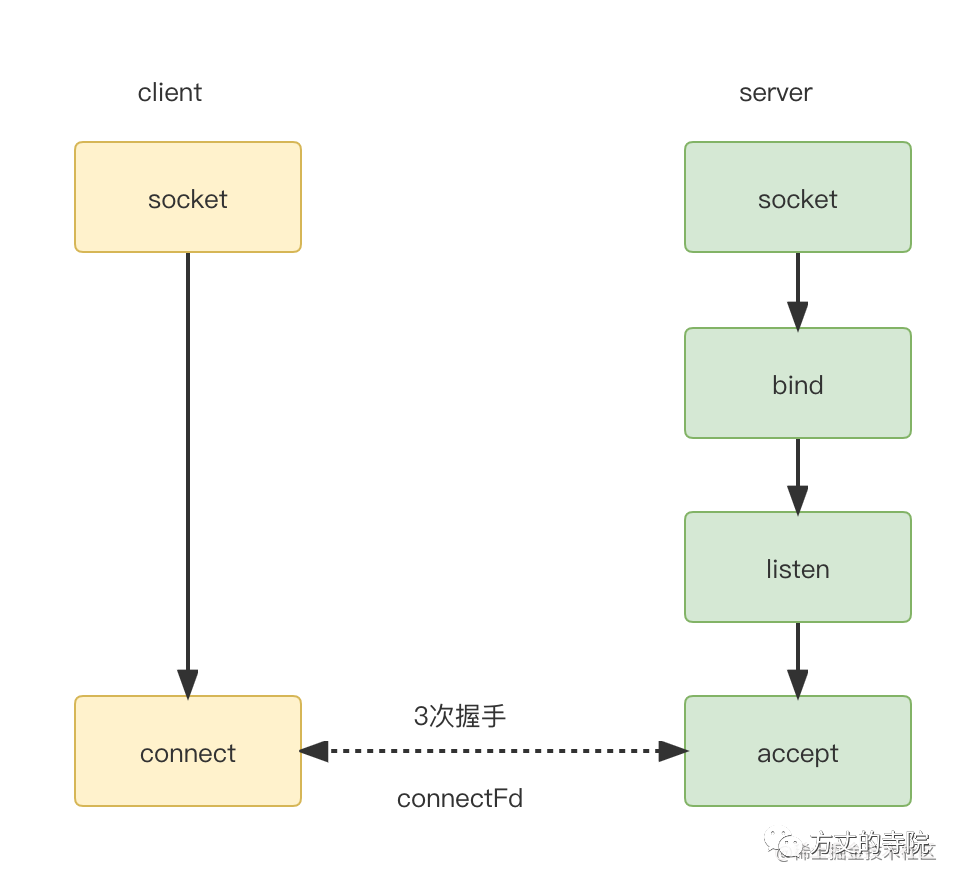
A familiar picture . This article focuses on the analysis of the server , So ignore the client details first . On the server side, create socket,bind port ,listen Be on it . Finally through accept Establish a connection with the client . Get one connectFd, namely Connect socket ( stay Linux Are file descriptors ), Used to uniquely identify a connection . After that, data transmission is based on this .
The data transfer
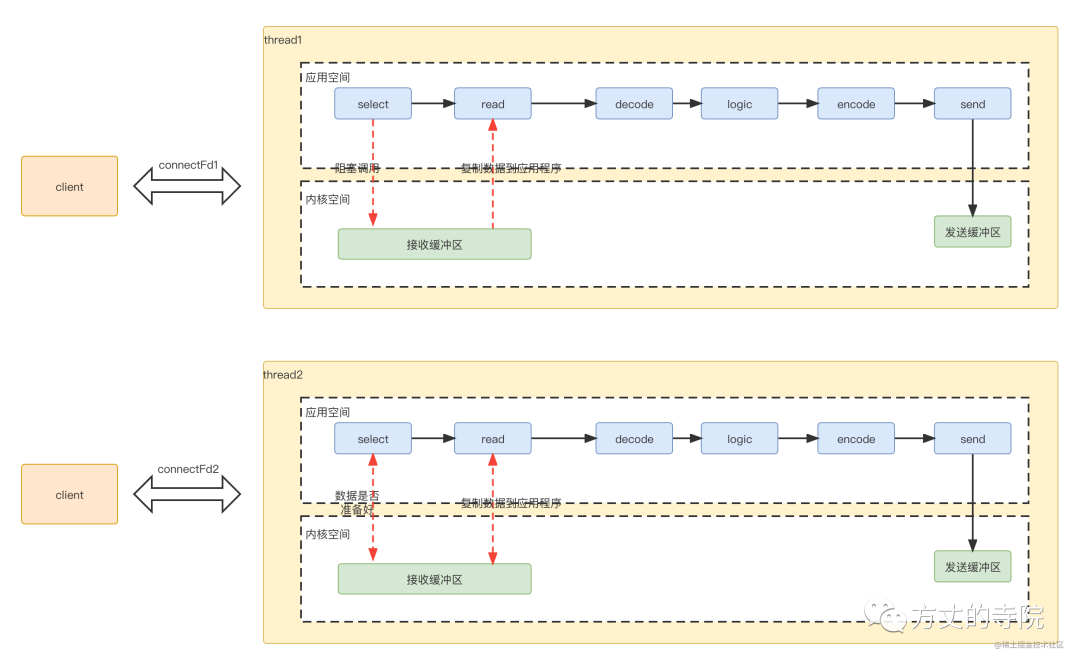 For data transmission , The server opens a thread to process data . The specific process is as follows
For data transmission , The server opens a thread to process data . The specific process is as follows
selectApplication program to system kernel space , Ask if the data is ready ( Because there is a window size limit , There is no data , You can read ), The data is not ready , The application has been blocked , Waiting for an answer .readThe kernel judges that the data is ready , Copy data from the kernel to the application , After completion , Successfully returns .The application goes on decode, Business logic processing , Last encode, Send it out , Return to the client
Because a thread processes a connection data , The corresponding threading model is like this
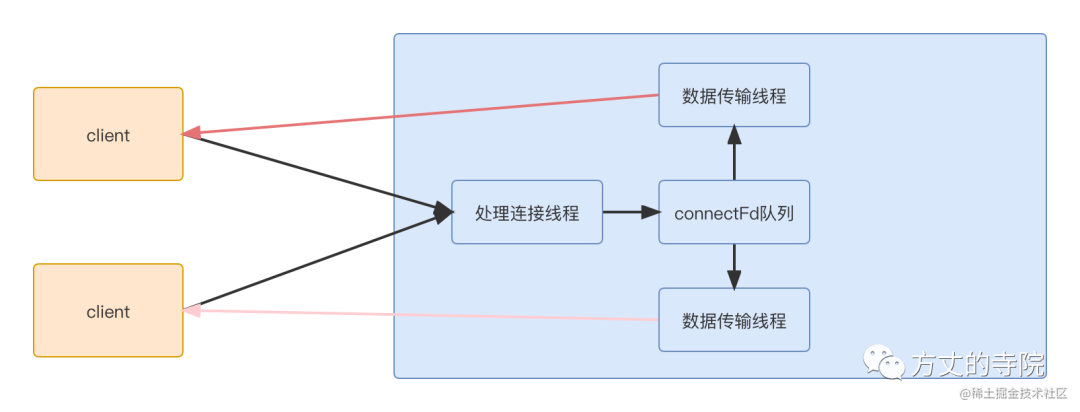
Multiplexing
Blocking vs Non blocking
Because a connection transmits , One thread , Too many threads are required , It takes up a lot of resources . At the same time, the connection ends , Resource destruction . You have to re create the connection . So a natural idea is to reuse threads . That is, multiple connections use the same thread . This raises a problem , Originally, the entrance where we carried out data transmission ,, Suppose the thread is processing the data of a connection , But the data has never been in good time , because select It's blocked , In this way, even if other connections have data readable , I can't read . So it can't be blocked , Otherwise, multiple connections cannot share a thread . So it must be non blocking .
polling VS Event notification
After changing to non blocking , Applications need to constantly poll the kernel space , Determine whether a connection ready.
for (connectfd fd: connectFds) {
if (fd.ready) {
process();
}
}
Polling is inefficient , Extraordinary consumption CPU, So a common practice is that the callee sends an event notification to inform the caller , Instead of the caller polling . This is it. IO Multiplexing , All the way refers to standard input and connection socket . Register a batch of sockets into a group in advance , When there is any one in this group IO When an event is , Go to inform the blocking object that it is ready .
select/poll/epoll
IO The common realization of multiplexing technology is select,poll.select And poll Not much difference , Mainly poll There is no limit to the maximum file descriptor .
From polling to event notification , Use multiplexing IO After optimization , Although the application does not have to poll the kernel space all the time . But after receiving the event notification in kernel space , The application does not know which corresponding connection event , You have to traverse
onEvent() {
// Listening for events
for (connectfd fd: registerConnectFds) {
if (fd.ready) {
process();
}
}
}
Foreseeable , As the number of connections increases , The time consumption increases in proportion . Comparison poll The number of events returned ,epoll There is an event to return connectFd Array , This avoids application polling .
onEvent() {
// Listening for events
for (connectfd fd: readyConnectFds) {
process();
}
}
Of course epoll The high performance of is more than that , There are also edge triggers (edge-triggered), I will not elaborate in this article .
Non blocking IO+ The multiplexing process is as follows :
selectApplication program to system kernel space , Ask if the data is ready ( Because there is a window size limit , There is no data , You can read ), Go straight back to , Nonblocking call .Data is ready in kernel space , send out ready read Feed the application
The application reads data , Conduct decode, Business logic processing , Last encode, Send it out , Return to the client
Thread pool division
Above we mainly through non blocking + Multiplexing IO To solve local select and read problem . Let's re sort out the overall process , See how the whole data processing process can be grouped . Each stage uses a different thread pool to handle , Increase of efficiency . First of all, there are two kinds of events
Connection event
acceptAction to deal withTransport events
select,read,sendAction to deal with .The connection event processing flow is relatively fixed , No additional logic , No further splitting is required . Transport events
read,sendIt is relatively fixed , The processing logic of each connection is similar , It can be processed in a thread pool . And concrete logicdecode,logic,encodeEach connection processing logic is different . The whole can be processed in a thread pool .
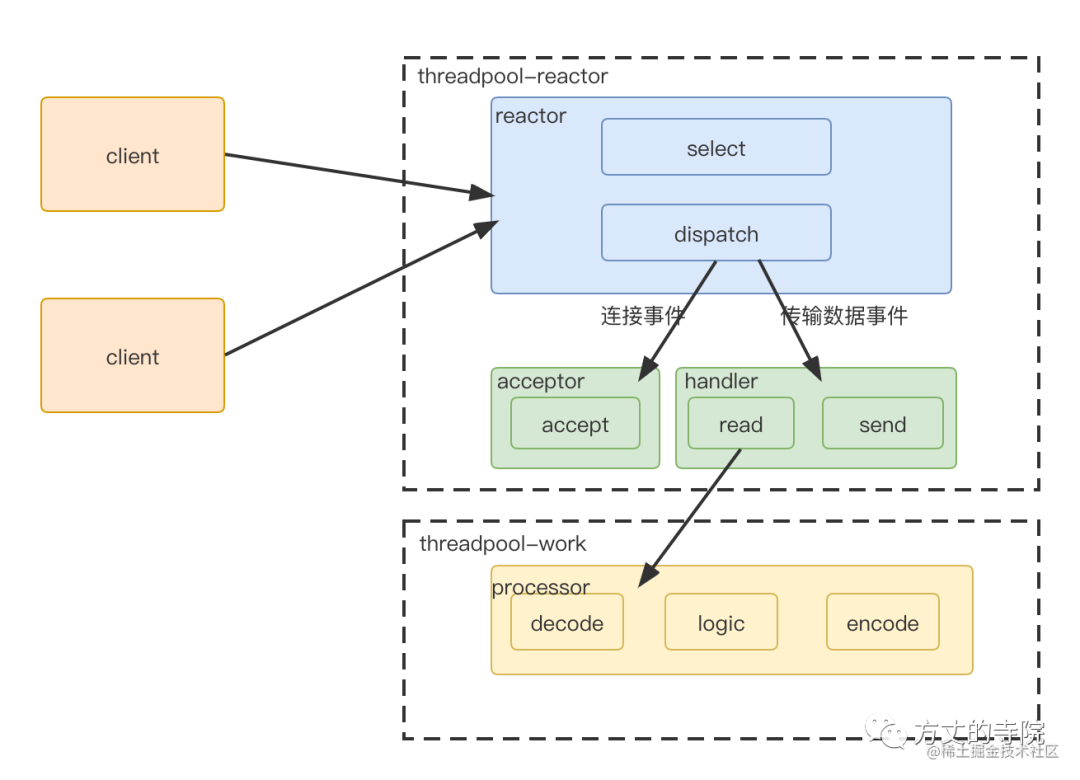
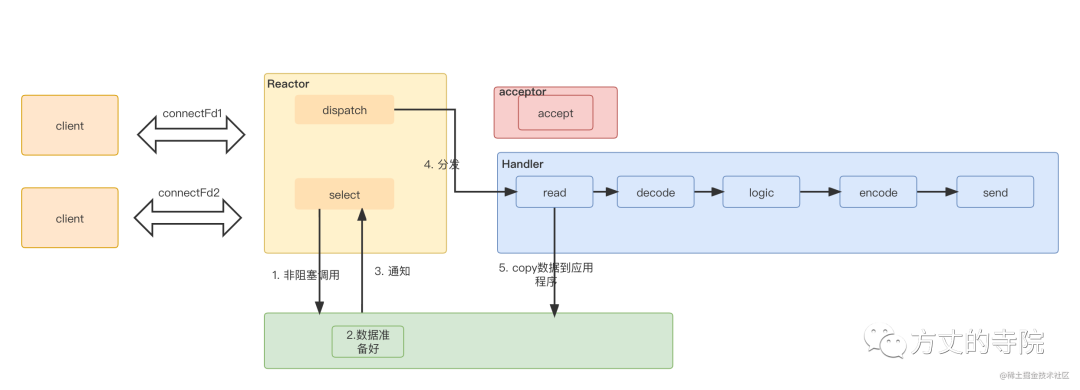
The server is split into 3 part
reactor part , Unified handling of events , Then distribute according to the type
Connection events are distributed to acceptor, Data transmission events are distributed to handler
If it is data transmission type ,handler read Give it to me after processorc Handle
because 1,2 It's faster to handle , Put it into the process pool for treatment , The business logic is processed in another thread pool .
The above is the famous reactor High concurrency model .
I am participating in the recruitment of nuggets technology community creator signing program
边栏推荐
- 在网页中打开展示pdf文件
- Pigsty: out of the box database distribution
- Robomaster visual tutorial (0) Introduction
- 【编程题】【Scratch二级】2019.03 绘制方形螺旋
- Redis caching tool class, worth owning~
- Tools for debugging makefiles - tool for debugging makefiles
- Resolve the URL of token
- 95. (cesium chapter) cesium dynamic monomer-3d building (building)
- Ping error: unknown name or service
- Sqlite数据库存储目录结构邻接表的实现2-目录树的构建
猜你喜欢

Is 35 really a career crisis? No, my skills are accumulating, and the more I eat, the better
Seven years' experience of a test engineer -- to you who walk alone all the way (don't give up)

光流传感器初步测试:GL9306
快速上手使用本地测试工具postman
智慧监管入场,美团等互联网服务平台何去何从
![[programming problem] [scratch Level 2] December 2019 flying birds](/img/5e/a105f8615f3991635c9ffd3a8e5836.png)
[programming problem] [scratch Level 2] December 2019 flying birds
蓝桥ROS中使用fishros一键安装
2022-07-07:原本数组中都是大于0、小于等于k的数字,是一个单调不减的数组, 其中可能有相等的数字,总体趋势是递增的。 但是其中有些位置的数被替换成了0,我们需要求出所有的把0替换的方案数量:
单机高并发模型设计

Laser slam learning (2d/3d, partial practice)
随机推荐
一个测试工程师的7年感悟 ---- 致在一路独行的你(别放弃)
One click free translation of more than 300 pages of PDF documents
Robomaster visual tutorial (0) Introduction
用語雀寫文章了,功能真心强大!
Restricted linear table
某马旅游网站开发(对servlet的优化)
Anaconda+pycharm+pyqt5 configuration problem: pyuic5 cannot be found exe
Uic564-2 Appendix 4 - flame retardant fire test: flame diffusion
Is 35 really a career crisis? No, my skills are accumulating, and the more I eat, the better
Resolve the URL of token
CoinDesk评波场去中心化进程:让人们看到互联网的未来
BSS 7230 flame retardant performance test of aviation interior materials
腾讯安全发布《BOT管理白皮书》|解读BOT攻击,探索防护之道
SQL knowledge summary 004: Postgres terminal command summary
DataGuard active / standby cleanup archive settings
2022-07-07:原本数组中都是大于0、小于等于k的数字,是一个单调不减的数组, 其中可能有相等的数字,总体趋势是递增的。 但是其中有些位置的数被替换成了0,我们需要求出所有的把0替换的方案数量:
Is it safe to buy funds online?
35岁那年,我做了一个面临失业的决定
【编程题】【Scratch二级】2019.09 制作蝙蝠冲关游戏
Data Lake (XV): spark and iceberg integrate write operations