当前位置:网站首页>Hudi data management and storage overview
Hudi data management and storage overview
2022-07-03 09:25:00 【Did Xiao Hu get stronger today】
List of articles
Data management
**Hudi How to manage data ? **
Use table Table Formal organization data , And the data class in each table like Hive Partition table , Divide data into different directories according to partition fields , Each data has a primary key PrimaryKey, Identify data uniqueness .
Hudi Data management
Hudi Data files for tables , You can use the operating system's file system storage , You can also use HDFS This kind of distributed file system storage . In order to share Analyze the reliability of performance and data , In general use HDFS For storage . With HDFS In terms of storage , One Hudi Table storage files are divided into two categories .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-YvuTlmxp-1654782269035)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609205143126.png)]](/img/f7/64c17ef5e0e77fbced43acdf29932a.png)
.hoodie
(1).hoodie file : because CRUD The fragility of , Each operation generates a file , When these little files get more and more , Can have a serious impact HDFS Of performance ,Hudi A set of file merging mechanism is designed . .hoodie The corresponding log files related to the file merge operation are stored in the folder .
Hudi As time goes by , A series of CRUD The operation is called Timeline,Timeline A certain operation in , be called Instant.
- Instant Action, Record this operation is a data submission (COMMITS), Or file merging (COMPACTION), Or file cleaning (CLEANS);
- Instant Time, The time of this operation ;
- State, State of operation , launch (REQUESTED), Have in hand (INFLIGHT), It's still done (COMPLETED);
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-8Glv0pMg-1654782269036)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609205512376.png)]](/img/d3/73c20c5a366fc53aa17b42e9f80a94.png)
amricas and asia
(2)amricas and asia The relevant path is the actual data file , Storage by partition , The path of the partition key It can be specified .
- Hudi Real data files use Parquet File format storage ;
- There is one metadata Metadata files and data files parquet The column type storage .
- Hudi In order to realize the data CRUD, Need to be able to uniquely identify a record ,Hudi The only field in the dataset will be (record key ) + Where the data is Partition (partitionPath) Unite as the only key to the data .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-vkMLkqhU-1654782269037)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609205849955.png)]](/img/18/286d66b6538b04e1e54e2aefc6ca16.png)
Hudi Storage overview
Hudi The organization directory structure of the data set and Hive Very similar , A data set corresponds to this root directory . The dataset is fragmented into multiple partitions , Partition Fields exist as folders , This folder contains all the files in this partition .
In the root directory , Each partition has a unique partition path , Each partition data is stored in multiple files .
Each file has a unique fileId And generate files commit Marked . If an update operation occurs , Multiple files share the same fileId, But it will Different commit.
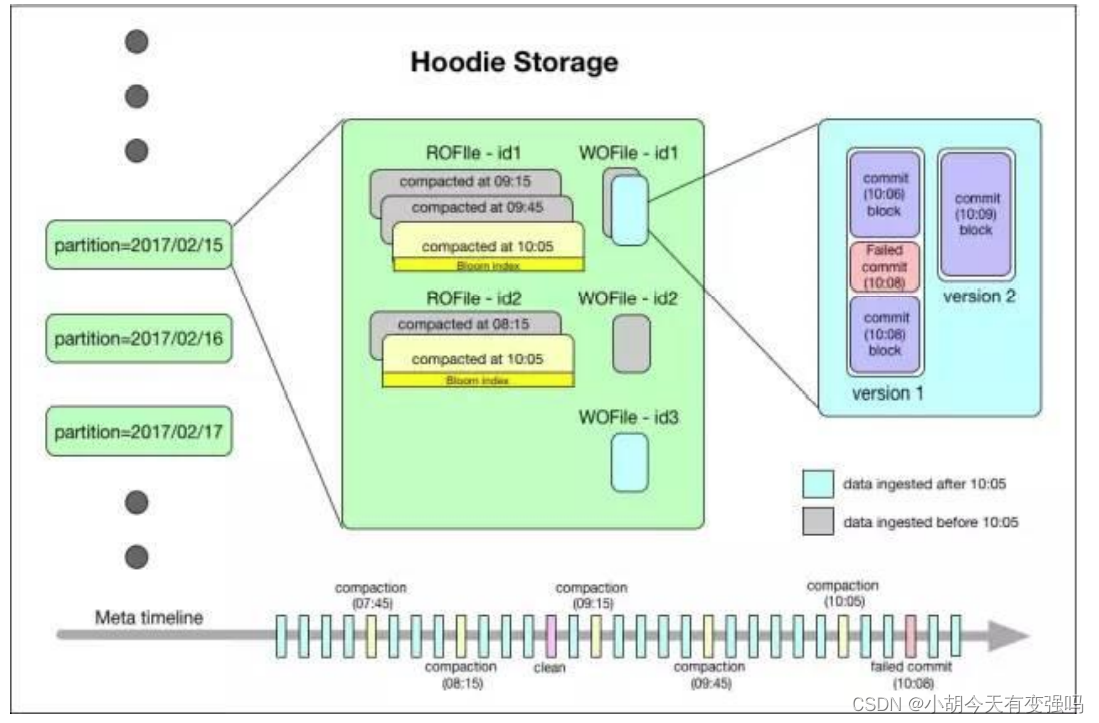
Metadata Metadata
- Time axis (timeline) Maintain the metadata of various operations on the dataset in the form of , To support the transient view of the dataset , This part of metadata is stored Metadata directory stored in the root directory . There are three types of metadata :
- Commits: A single commit Contains information about an atomic write operation to a batch of data on the dataset . We use monotonically increasing timestamps to identify commits, Calibration is the beginning of a write operation .
- Cleans: The background activity used to clear the old version files in the dataset that are no longer used by the query .
- Compactions: To coordinate Hudi Internal data structure differences in background activities . for example , Collect the update operation from the log file based on row storage to the column storage data .
Index Indexes
- Hudi Maintain an index , To support in recording key In the presence of , The newly recorded key Quickly map to the corresponding fileId.
- Bloom filter: Stored in the footer of the data file . The default option , Independent of external system implementation . The data and index are always consistent .
- Apache HBase : It can efficiently find a small batch of key. During index marking , This option may be a few seconds faster .

Data data
Hudi Store all ingested data in two different storage formats , The user can choose any data format that meets the following conditions :
Read optimized column format (ROFormat): The default value is Apache Parquet;
Write optimized line storage format (WOFormat): The default value is Apache Avro
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-asupbZiT-1654782269037)(C:\Users\Husheng\Desktop\ Big data framework learning \image-20220609210931450.png)]](/img/8a/3d47d4d4b72136410d510d32c88758.png)
Reference material :
边栏推荐
- Logstash+jdbc data synchronization +head display problems
- CATIA automation object architecture - detailed explanation of application objects (I) document/settingcontrollers
- With low code prospect, jnpf is flexible and easy to use, and uses intelligence to define a new office mode
- 2022-2-14 learning xiangniuke project - Session Management
- Bert install no package metadata was found for the 'sacraments' distribution
- [point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points
- LeetCode每日一题(931. Minimum Falling Path Sum)
- 【点云处理之论文狂读经典版10】—— PointCNN: Convolution On X-Transformed Points
- 用Redis实现分布式锁
- [kotlin learning] classes, objects and interfaces - classes with non default construction methods or attributes, data classes and class delegates, object keywords
猜你喜欢

Hudi 集成 Spark 数据分析示例(含代码流程与测试结果)
![[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?](/img/fc/5c71e6457b836be04583365edbe08d.png)
[kotlin puzzle] what happens if you overload an arithmetic operator in the kotlin class and declare the operator as an extension function?
Build a solo blog from scratch
Hudi integrated spark data analysis example (including code flow and test results)

Jenkins learning (III) -- setting scheduled tasks
Spark structured stream writing Hudi practice
Flask+supervisor installation realizes background process resident

Digital management medium + low code, jnpf opens a new engine for enterprise digital transformation

About the configuration of vs2008+rade CATIA v5r22

Digital statistics DP acwing 338 Counting problem
随机推荐
Pic16f648a-e/ss PIC16 8-bit microcontroller, 7KB (4kx14)
【毕业季|进击的技术er】又到一年毕业季,一毕业就转行,从动物科学到程序员,10年程序员有话说
【点云处理之论文狂读经典版7】—— Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs
Explanation of the answers to the three questions
CATIA automation object architecture - detailed explanation of application objects (I) document/settingcontrollers
[solution to the new version of Flink without bat startup file]
【点云处理之论文狂读经典版10】—— PointCNN: Convolution On X-Transformed Points
Modify idea code
WARNING: You are using pip version 21.3.1; however, version 22.0.3 is available. Prompt to upgrade pip
[point cloud processing paper crazy reading cutting-edge version 12] - adaptive graph revolution for point cloud analysis
【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds
Jenkins learning (II) -- setting up Chinese
LeetCode每日一题(1996. The Number of Weak Characters in the Game)
About the configuration of vs2008+rade CATIA v5r22
Apply for domain name binding IP to open port 80 record
The less successful implementation and lessons of RESNET
2022-2-14 learning xiangniuke project - Session Management
Flink学习笔记(九)状态编程
The idea of compiling VBA Encyclopedia