> Java And C++ There is a high wall surrounded by dynamic memory allocation and garbage collection technology ---《 In depth understanding of Java Virtual machines 》 We know that managing memory manually means freedom 、 Finely control , But it's highly dependent on the level and care of developers . If you forget to free up memory space after use, a memory leak will occur , If you release the wrong memory space or use the overhang index, you will have unpredictable problems . Now Java With GC Here we are (GC,Garbage Collection garbage collection , Before Java Put forward ), Leave the management of memory to GC To do , It lightens the burden of programmers , Improved development efficiency . So it's not using Java You don't need memory management , Just because GC Carrying weight for us . however GC It's not that omnipotent , Different scenarios are applicable to different GC Algorithm , You need to set different arguments , So we can't just let it go , Only by deeply understanding it can we make good use of it . About GC I believe many people know the content . I was the first to learn about GC Knowledge comes from 《 In depth understanding of Java Virtual machines 》,** But it's about GC It is not enough to read this book alone .** I thought I knew a lot about it , Later, after a period of education, I learned what the ignorant are fearless .  And over a period of time, a lot about GC I can't even say the content of , In fact, many students reflect that some knowledge will be forgotten , Some of the contents were understood at that time , After a while, I don't remember anything . Most of the time it's because it's in your head ** There is no system , Didn't understand the cause and effect , Put some knowledge together without **. Recently, I've sorted out GC Relevant knowledge , I want to expand from point to surface GC Content of , By the way, I'll take a look at my own ideas , So output this article , I hope it will help you . About GC In fact, there are a lot of , But for our general development, it doesn't need to be too deep , So I picked out some that I thought were important to sort out , I also deleted some original codes , It doesn't feel necessary , It's important to clarify conceptually . I was going to analyze JVM Of the garbage collectors , But the article is too long , So it's divided into two parts , The next one will be sent again . This article is organized by GC The content is not limited to JVM But on the whole, it's still partial JVM, If we talk about concrete realization, presupposition means HotSpot. ## Text First of all, we know that according to 「Java Virtual machine specification 」,Java When the virtual machine is running, the data is divided into program counters 、 Virtual machine stack 、 Local method stack 、 Pile up 、 Method area . 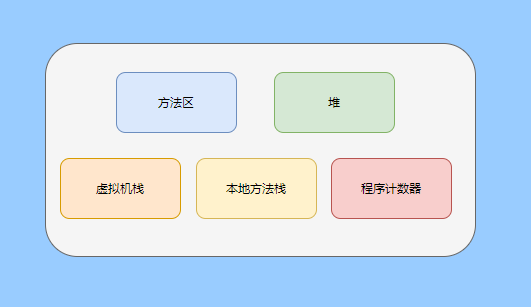 And the program counter 、 Virtual machine stack 、 Local method stack this 3 Regions are thread private , It will automatically recycle as the thread dies , So there's no need to manage . therefore ** Garbage collection only needs to focus on the heap and method area .** And the recycling of the method area , Often the price effect is low , Because the judgment can be recycled under more stringent conditions . For example, to uninstall a class, all instances of this class have been recycled , Include subclasses . Then the class loader that needs to be loaded is also recycled , Only when the corresponding class object is not referenced can it be recycled . As far as class loaders are concerned , Unless it's like a specially designed OSGI You can replace the class loader , Otherwise, it can't be recycled . The high rate of return of garbage collection is the collection of memory in the heap , So we focus on that ** Garbage collection **. ## How to judge whether an object has become garbage ? Since it's garbage collection , We have to determine which items are rubbish first , And then we'll see when to clean up , How to clean up . There are two common garbage collection strategies : One is direct recycling , That's the reference count ; The other is indirect recycling , That's tracking recycling ( Accessibility analysis ). We all know that reference counting has a fatal flaw -** Circle back to quote **, therefore Java Using accessibility analysis . ** So why are there so many languages using counting references with obvious defects ?** such as CPython , From this point of view, reference counting is still useful , So let's start with the reference count . ## Quote count Reference counting is actually setting a counter for each memory unit , When referenced, the counter adds one , When the counter is reduced to 0 This means that the unit can no longer be referenced , So you can release memory immediately . 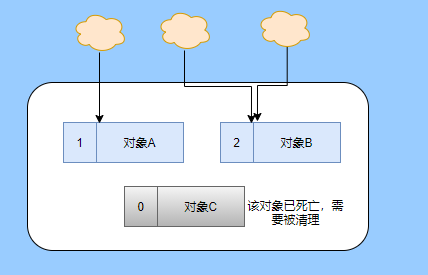 As shown in the figure above , The cloud stands for quotation , At this point the object A Yes 1 A quote , So the value of the counter is 1. thing B There are two external references , So the value of the counter is 2, And objects C Not quoted , So it means that the object is rubbish , So you can free memory immediately . From this, we can know the reference counting needs ** Take up extra storage space **, If the memory unit is small, the space occupied by the counter becomes obvious . Secondly, the memory release of the reference count is equivalent to this ** The overhead is spread evenly into the daily execution of the application **, Because the count is 0 At the moment , It's the moment when the memory is released , This is actually good for memory sensitive scenarios . If it's the recovery of accessibility analysis , Things that become rubbish don't get rid of immediately , Need to wait for the next time GC Will be cleared . The concept of reference counting is relatively simple , But the flaw is the loop reference mentioned above . ## It's like CPython How to solve the problem of loop reference ? First of all, we know things like integers 、 There is no reference to other objects inside the string , So there's no question of circular references , So there's no problem using reference counting . It's like List、dictionaries、instances This kind of container object may have the problem of loop dependency , therefore Python On the basis of reference counting, we introduce the tag - Clear for backup processing . But the concrete method and the traditional mark - Clearing is not the same ,** What it takes is to find objects that are not accessible , Not accessible objects .** Python Use a bidirectional concatenation to link container objects , When a container object is created , It's inserted into the link string , Remove when it is deleted . Then a field will be added to the container object gc_refs, Now let's take a look at how to deal with loop references : 1. For each container object , Will gc_refs Set to the reference count of the object . 2. For each container object , Query the container object it refers to , And reduce the number of references to container objects found gc_refs Hurdles . 3. At this point gc_refs Bigger than 0 Container objects are moved to different collections , Because gc_refs Bigger than 0 Indicates that there is an external reference to it , So you can't release these objects . 4. Then find out gc_refs Bigger than 0 The object referenced by the container object of , They can't be cleared either . 5. The last remaining object description is referenced only by the object in the linked string , No external references , So garbage can be removed . The details are shown in the following figure ,A and B Object loop reference , C Object references D thing . 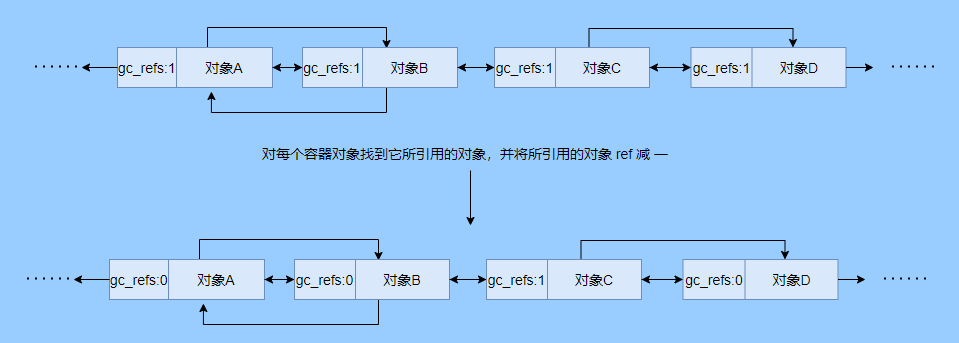 To make the picture clearer , I've taken a separate screenshot of the steps , The picture above is 1-2 Steps , Below is 3-4 Steps . 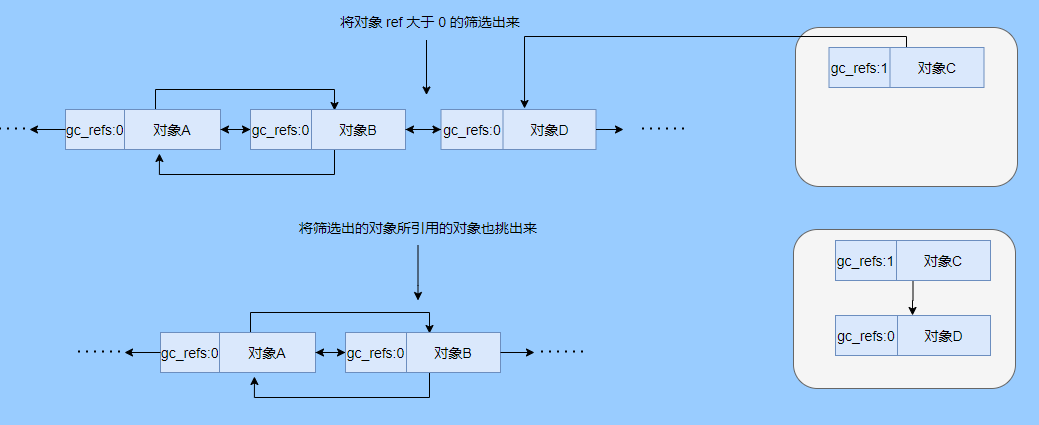 Finally, the circle quotes A and B Can be cleaned up , But there is no free lunch , One of the biggest expenses is ** Each container object requires additional fields .** And ** The cost of maintaining the concatenation of container Links **. According to pybench, This cost takes up ** About 4% Slow down **. So far we know that the advantage of reference counting is that it's easy to implement , And the memory is cleaned up in time , The disadvantage is that you can't handle loop references , But it can be combined with markers - Clean up and so on , Ensure the integrity of garbage collection . ** therefore Python The looping reference problem of reference counting is not solved , It's just a combination of unconventional markers - Clear the plan to cover the bottom , It's a curve to save the country .**  In fact ** In extreme cases, reference counting is not so timely **, You think if there is an object that references another object now , And another object references another , Quote it in turn . So when the first object is to be recycled , It will trigger a chain reaction , If there are many objects, the delay will be highlighted . 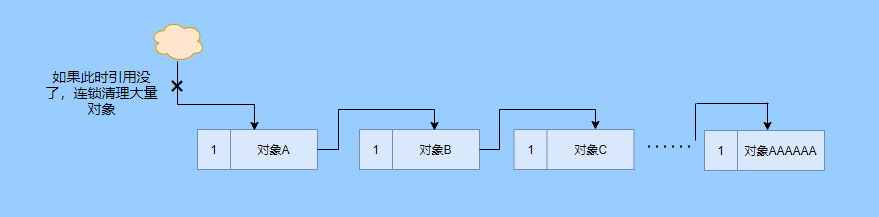 ## Accessibility analysis Accessibility analysis is actually the use of markers - eliminate (mark-sweep), Namely ** Mark reachable objects , Remove inaccessible objects **. As to how to clear , Do you want to sort it out after clearing it . Mark - The specific method of cleaning is garbage collection on a regular basis or when there is insufficient memory , Reference from root (GC Roots) Start traversing the scan , Mark all scanned objects as reachable , Then all the inaccessible objects are recycled . So called root references include global variables 、 Reference on stack 、 Etc. on the register . 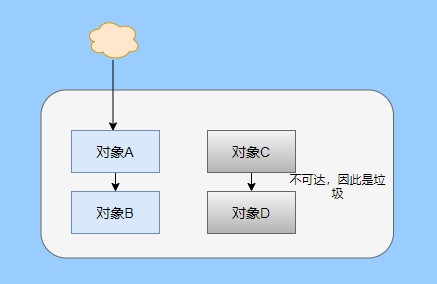 You don't know if you feel a little bit , We do it when we run out of memory GC, When there is not enough memory, it is also when there are many objects , Most objects, so it takes a long time to scan markers . So mark - To remove is to accumulate rubbish , And then remove it all at once , This will consume a lot of resources in garbage collection , Affect the normal execution of the application . ** Therefore, there will be generational garbage collection and only the objects that are directly connected to the root node will be marked before concurrency tracing The means of .** But it can only alleviate the inability to eradicate . I think it's a sign - The biggest ideological difference between clearing and reference counting ,** One saved up to deal with , One is to spread this consumption equally in the daily execution of the application .** And no matter what the mark - Clear or reference count , It's all about reference types , Like some integers, you don't need to worry about . therefore JVM And there is a need to judge ** What type of data is on the stack **, It can be divided into conservative type GC、 Semi conservative GC、 And accurate GC. ### Conservative GC Conservative GC refer to JVM Types that do not record data ,** In other words, it is impossible to distinguish whether the data at a certain location in memory is a reference type or a non reference type .** Therefore, we can only rely on some conditions to guess whether there is an indicator pointing to . For example, scanning on the stack depends on whether the address is in GC Within the upper and lower bounds of the heap , Whether the byte alignment and other means to determine whether this is pointing to GC Indicators in the heap . It's called conservative GC It's because what doesn't meet the guessing condition is definitely not pointing to GC Indicators in the heap , So that piece of memory is not referenced , And what is in line with is not necessarily an indicator , So it's a conservative guess . I'll draw another picture to explain , After looking at the picture, it should be clear . 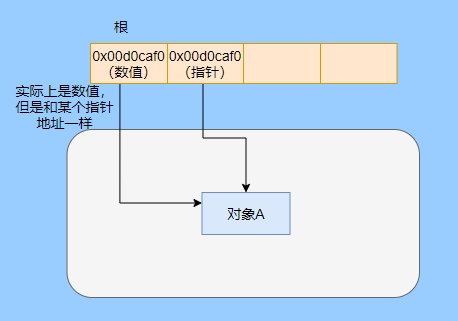 We know that we can judge according to the index pointing to the address , For example, whether the bytes are aligned , Is it within the range of the heap , However, it is possible that the value with exactly numerical value is the value of address . This is chaos , So it's not certain that this is an indicator , It can only be conservatively regarded as an indicator . So there's definitely no case of killing objects by mistake . There will only be objects that are dead , But there are suspected indicators pointing to it , It happens when you mistakenly think it's still alive and let it go . therefore ** Conservative GC There's going to be a little bit off “ The garbage ”, Not very memory friendly .** And because of the suspected indicators , So we can't confirm whether it's a real indicator , So it's just ** Can't move objects , Because moving objects requires changing the indicator **. One way is to add an intermediate layer , That is to control the code layer , The reference will first refer to the control code , Then find the actual object from the control code table . So direct references don't need to change , If you want to move an object, you just need to modify the control code table . But that's one more level of access ,** It's less efficient .** ### Semi conservative GC Semi conservative GC,** Type information is recorded on the object ** And there are still no records in other places , So scanning from the root is the same , It's up to guessing . But when you get the objects in the heap , You can know exactly what the object contains , So after tracing It's all accurate , So it's called semi conservative GC. Now you can see the semi conservative GC Only objects scanned directly by the root cannot be moved , Objects traced back from direct objects can be moved , So semi conservative GC You can use algorithms that move parts of objects , You can also use tags - The algorithm to remove this immobile object . And conservative GC Only tags can be used - Clear algorithm . ### Exact form GC I believe you already know the exact meaning of JVM You need to know the type of object clearly , Including references on the stack, you can also know types and so on . What you can think of can be marked on the index , To indicate the type , Or record the type information externally to form a map table . **HotSpot It's a mirror , This watch is called OopMap.** stay HotSpot in , The type information of an object will record its own OopMap, Records the type data at what offset is in the object of that type , Methods executed in the translator can be automatically generated by the functions in the translator OopMap Come out and give it to GC use . By JIT Compiled methods , It will also be generated in a specific location OopMap, It records which positions on the stack and in the register are references when executing an instruction to the method . These specific locations are mainly in : 1. At the end of the loop (** Not counted Turn around **) 2. Methods before returning / Call method call After the instruction 3. It's possible to throw an abnormal position These positions are called ** Be safe (safepoint)**. So why choose these positions to insert ? Because if you record one for each instruction OopMap The space cost is too much , So just select these key positions to record . ** So in HotSpot in GC It's not accessible anywhere , You can only enter at safe points .** So far, we know that we can calculate the... In the object type when the class is loaded OopMap, The translator generates OopMap and JIT Generated OopMap , therefore GC There are sufficient conditions to accurately determine the object type . So it's called the exact form GC. There's actually another one JNI call , They are not executed in the literal translator , It won't pass by JIT Compile build , So there will be a lack of OopMap. stay HotSpot Is through the control of code packaging to solve the accuracy problem , image JNI The input and return value references are wrapped up in control code , That is to access the real object through the control code . In this way GC You don't have to scan JNI The stack frame of , Scan the control code list directly to know JNI Refer to the GC What's in the pile . ## Be safe We've talked about safety , Safety is not just for records OopMap With , Because GC Need a consistent snapshot , So the application thread needs to pause , And the choice of pause point is safety point . Let's go through the train of thought . First, give it GC Noun , In a garbage collection scenario, the application is called mutator . One can be mutator The object visited is alive , That is to say mutator The context of contains data that can be accessed to live objects . This context actually refers to the stack 、 Register and other information above , For GC In other words, it only cares about the stack 、 Where is the reference, such as the register , Because it only needs to focus on references . But the context is mutator It's always changing during execution , therefore GC You need to get one ** Uniformity ** Context snapshot to list all the root objects . And snapshot acquisition needs to stop mutator All threads , Otherwise, there will be no consistent data , Causing some living objects to be lost , The consistency here is just like the consistency of transactions . and mutator In all threads, these points that have the chance to become pause positions are called safepoint That is, safety point . openjdk The official website defines security point as : > A point during program execution at which all GC roots are known and all heap object contents are consistent. From a global point of view, all threads must block at a safepoint before the GC can run. But safepoint It's not just GC Useful , such as deoptimization、Class redefinition There are , It's just GC safepoint Well known . Let's think about where we can put this safety point . For a literal translator, in fact, each bit group code boundary can become a security point , For JIT Compiled code can also insert security points in many places , But the implementation will only insert security points in some specific locations . Because safety is needed check Of , and check It takes expenses , If there are too many security points, the cost will be high , It is necessary to check whether it is necessary to enter the safety point every few steps . The second is that we mentioned above will record OopMap , So there's extra space overhead . ** that mutator How do you know that you need to pause at a safe point ?** In fact, as mentioned above, it is check, More specifically, there are differences between interpretation execution and compilation execution check. In explaining the execution of check It's at safety polling A flag bit , If you want to enter GC This flag bit will be set . The compiler execution is polling page Unreadable , In need of access safepoint Make the memory page inaccessible , Then the compile code access will have an exception , Then catch the exception, hang it and pause . There may be students here asking , What about the blocked thread ? It can't get to safety , You can't wait for it ? Here we're going to introduce ** Safe area ** The concept of , The region in a code segment in which the reference relationship does not change is called a security zone . Start anywhere in the area GC It's all safe , These threads that run to the safe zone also identify themselves as entering the safe zone , So it will GC You don't have to wait , And if these threads want to go out of the security zone, they will also check whether they are in GC , If you're there, you're stuck waiting , If GC When it's over, go ahead with it . Maybe some students are right about **counted Turn around ** There is a little doubt , image `for (int i...)` This is counted Turn around , There's no safe place to bury . So suppose you have one counted loop And then there are some very slow operations inside , therefore ** It's very likely that other threads will enter the security point and block and wait for this loop End of thread for **, This is the Caton . ## Generational collection We mentioned earlier that marks - Clear the way GC In fact, it's just collecting garbage , In this way, centralized recycling will affect the normal execution of the application , So we took ** Generational collection ** Thought . Because ** Research has found that some objects don't die , It's been around for a long time , And some objects will be snapped soon after they come out **. These are the weak generational hypothesis and the strong generational hypothesis . therefore ** Divide the heap into the new generation and the old generation **, In this way, different areas can be treated according to different recycling strategies , Improve recycling efficiency .  For example, the new generation of objects have the characteristics of life and death , So the return on garbage collection is high , There are also very few living objects that need to be traced back , So the collection is fast , You can arrange garbage collection more frequently . If there are very few objects left in each garbage collection of the new generation , If ** Mark with - The cleanup algorithm needs to clear a lot of objects at a time **, So you can use a marker - Copy algorithm , Copy live objects to one area at a time , The rest can be removed directly . But the simple mark - The replication algorithm is to split the heap in half , But this memory utilization is too low , Only 50%. therefore HotSpot The virtual machine is divided into two parts Eden District and two Survivor, The default size ratio is 8∶1:1, So the utilization rate is 90%. Each recycle copies the surviving object to a Survivor District , Then empty the other areas , If Survivor If you can't put it down, you can put it in Old people go , This is ** Distribution guarantee mechanism .**  And the objects of the old age are basically not rubbish , therefore ** It takes a long time to trace the mark **, The return rate of collection is also relatively low , So the collection frequency is arranged lower . This area is due to the fact that very few objects are removed at each time , So you can use the tag - Clear algorithm , But if you just clear the non moving objects, there will be a lot of memory fragmentation , So there's another kind of marker - Sorting algorithm , After each erase, the memory needs to be organized , Need to move objects , It's time consuming . So you can use markers - Clear and mark - Put the two together to collect the older generation , For example, we use marks on weekdays - eliminate , When you detect that there are too many memory fragments, use the tag - To use in combination with . There may be a lot of marks from my classmates - eliminate , Mark - Arrangement , Mark - The replication algorithm is not very clear , It's okay , Let's have a plate . ## Mark - eliminate There are two stages : Marking stage :tracing Stage , From the root ( Stack 、 register 、 Global variables, etc ) Start traversing the object graph , Mark every object encountered . Removal phase : Scanning objects in the heap , Recycle marked objects as garbage . It's basically the process shown in the figure below : 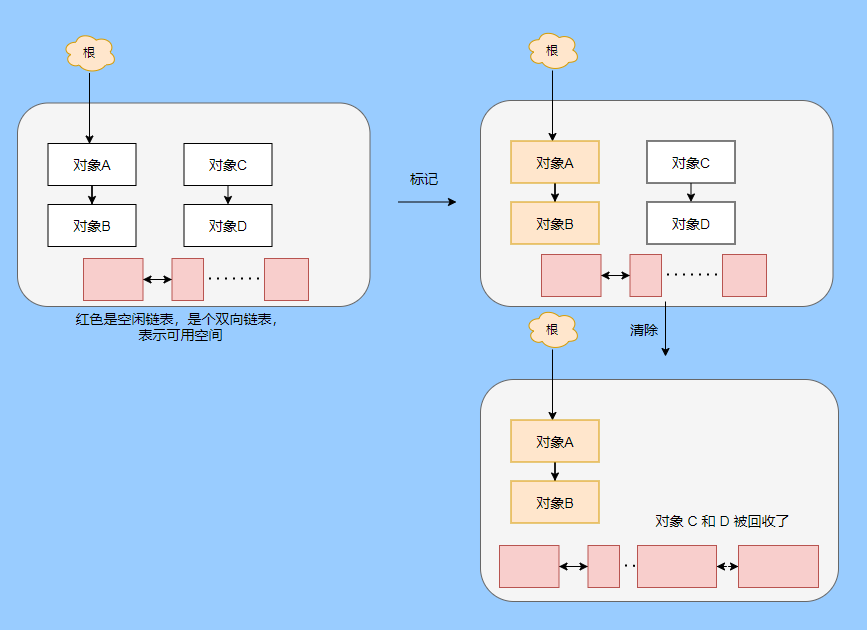 ** Cleanup does not move and clean up memory space **, It is usually concatenated through idle links ( Two way concatenation ) To mark which piece of memory is available , So it leads to a situation :** Space debris **. This will make it clear that the total memory is enough , But the application memory is insufficient . 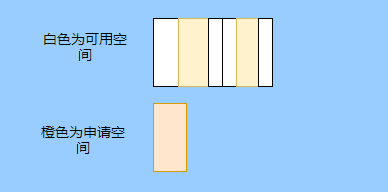 And it's a bit of a hassle when it comes to applying for memory , You need to traverse the linked columns to find the appropriate block of memory , It's going to take a lot of time . So there will be ** The implementation of multiple idle link serialization **, In other words, according to the size of the memory block, different concatenation columns are formed , For example, it can be divided into large block connection column and small block connection column , In this way, according to the memory block size of the application, different link strings are traversed , Speed up the efficiency of your application . 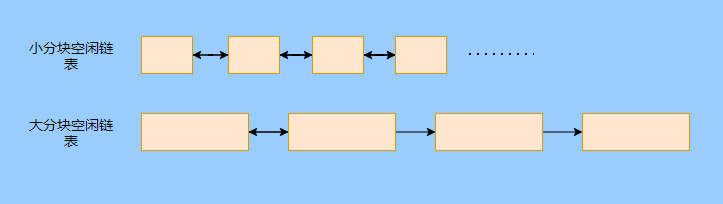 Of course, there are more links in the list . And there are signs , Generally speaking, we think it should be marked on the object , For example, the tag bit is placed in the object head , But this is incompatible with copy on write . Wait for every time GC You need to modify the object , Suppose it is fork It came out , It's actually sharing a piece of memory , That modification must lead to duplication . So there's a kind of ** Dot matrix notation **, In fact, a block of memory in the heap is marked with a bit . It's like our memory is page by page , The memory in the heap can be divided into blocks , And objects are all together , Or multiple blocks of memory . According to the address of the object and the starting address of the heap, we can calculate which block the object is on , Then set the bit number in a bitmap to 1 , Indicates that the object on this address has been marked . 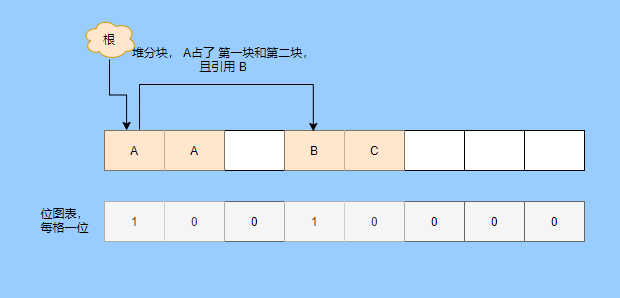 And using bitmap table method can not only use copy while writing , Cleaning is also more efficient , If it's marked on the head of the object , Then you need to traverse the entire heap to scan the object , Now there's a dot matrix , Can quickly traverse and clear objects . But whether it's marking the head of an object or using a bitmap , Mark - We still can't deal with the debris . So that leads to the marker - Copy and tag - Arrangement . ## Mark - Copy First, this algorithm divides the heap into two parts , One is From、 One is To. The object will only be in From Generate on , It happened GC After that, all the living objects will be found , Then copy it to To District , And then it's recycled as a whole From District . And then To District and From District identity swap , namely To Become From , From Become To, I'll explain a wave of . 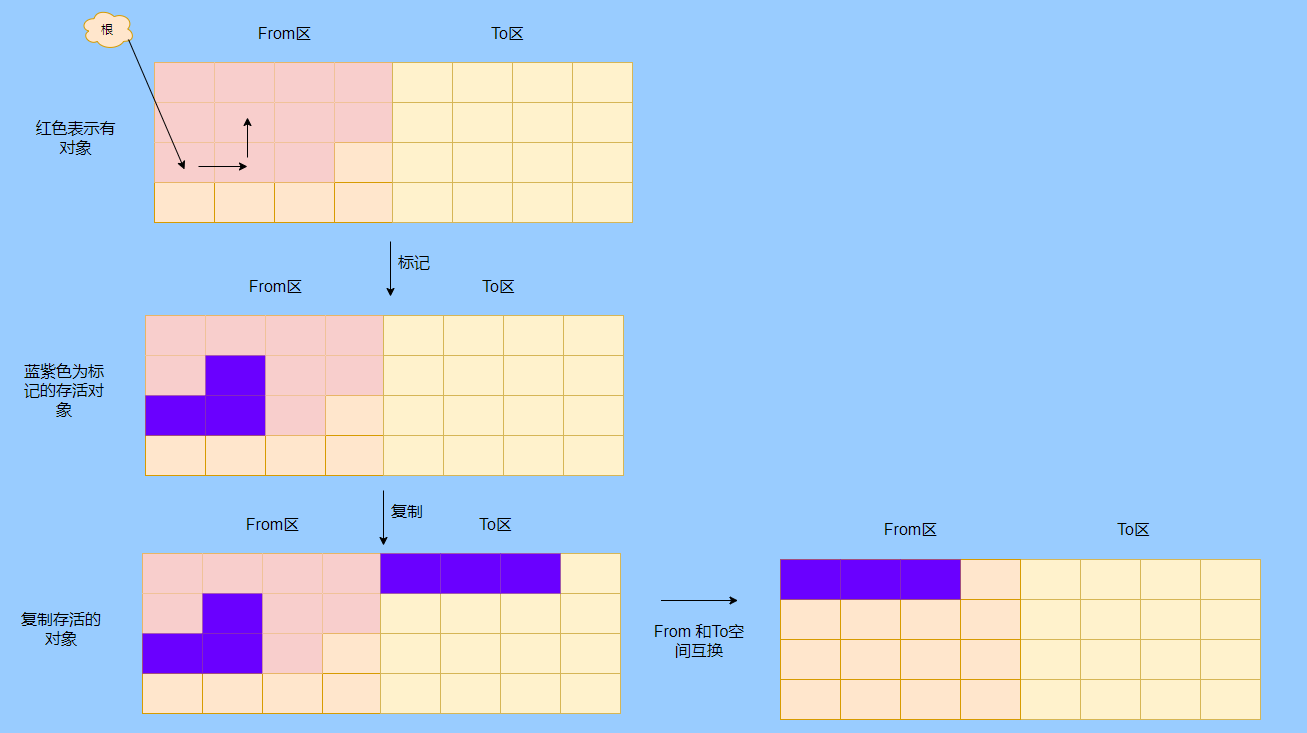 You can see that the allocation of memory is compact ,** There will be no memory fragmentation **. There is no need to have a free link string ,** Move the pointer directly to allocate memory **, It's very efficient . ** Yes CPU Cache affinity is high **, Because traversing a node from the root , It's depth first traversal , Find the associated objects , Then the memory is allocated in similar places . So according to the principle of regionalism , When an object is loaded, the object it references is also loaded , So the access cache hits directly .、 Of course, it has its disadvantages , Because objects can only be allocated in From District , and From The zone is only half the size of the heap , therefore ** The utilization of memory is 50%.** Second, if ** There are a lot of things alive , So the pressure of replication is still great **, It will be slower . And then because of the need to move the object , therefore ** Not applicable to the conservative type mentioned above GC.** Of course, what I described above is depth first, which is to send back calls , There is a risk of stack overflow , There's another one Cheney Of GC Copy algorithm , Is the use of iterative breadth first traversal , I don't want to analyze it in detail , Interested in self searching . ## Mark - Arrangement Mark - Organize the fact and mark - Copy is almost , The difference is that the replication algorithm is divided into two areas to copy back and forth , And finishing does not split the slot , Sort it out directly . 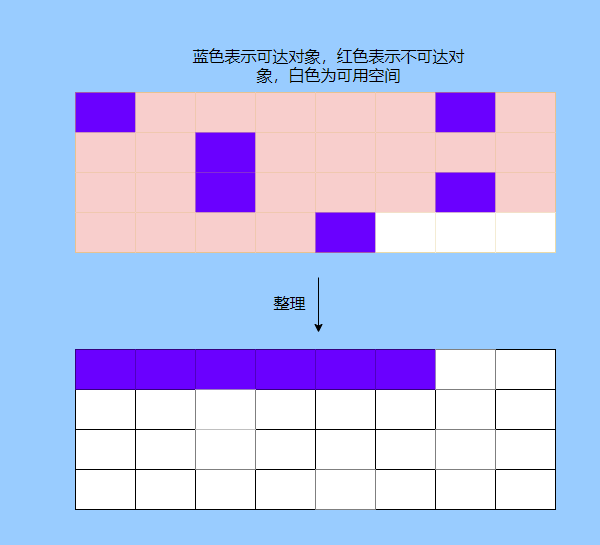 The algorithm is still very clear , Organize the living objects to the boundary , And there's no memory fragmentation , And you don't need to make up half of the space that replication algorithms do , So memory utilization is high . The disadvantage is that the heap needs to be searched many times , After all, it's marked in a space , Moving again , So on the whole, it takes more time , And if the pile is large , Then the time consumed will be more prominent . At this point, I believe you have a good idea of the mark - eliminate 、 Mark - Copy and tag - It's all clear , Let's go back to the generational collection mentioned earlier . ## Cross generational quotation We've divided generations according to the characteristics of object survival , Improve the efficiency of garbage collection , But like in the recycling of the new generation , It is possible that objects of the old age refer to the new generation of objects , So the old age also needs to be the root , But if you scan the whole old age, it's less efficient . So we created a memory set (Remembered Set) Of things , Come ** Record references across generations without scanning the entire non collection area .** Therefore, memory set is an abstract data structure used to record the index set from non collection area to collection area . According to the accuracy of the record, it is divided into - Word length precision , Each record is accurate to the machine word length . - Object precision , Every record is accurate to the object . - Card accuracy , Each record is accurate to a memory area . ** The most common is to use card precision to achieve memory sets , Call it card watch .** Let me explain what a card is . Take the accuracy of the object to distance , Suppose the new generation of objects A Old generation objects D Refer to the , Then we need to record the older generation D The address refers to a new generation of objects . That card means dividing memory space into many cards . Suppose the new generation of objects A By the old age D Refer to the , Then we need to record the older generation D The memory chip in which it is located refers to a new generation of objects . 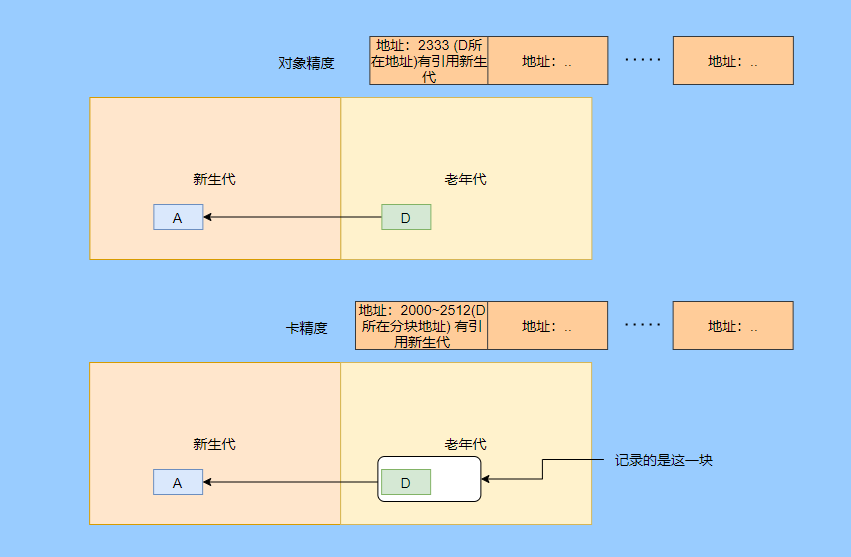 That is to say, the pile is cut by the card , Suppose the size of the card is 2, The pile is 20, That pile can be divided into 10 Cards . Because of the wide range of cards , If at this time D Next to the objects in the same card, there are also references to the new generation of objects , Then just one record is needed . A byte array is usually used to implement the card table , The card range is also set to 2 Of N The size of the power . Take a look at the figure below to make it clear . 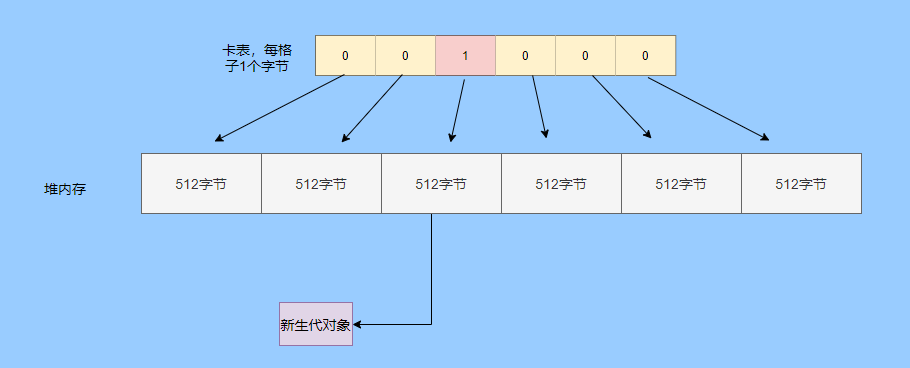 Suppose the address is from 0x0000 Start , So the byte array of 0 The number element represents 0x0000~0x01FF,1 No. stands for 0x0200~0x03FF, And so on . And then it's time to recycle the next generation , Just scan the card table , Mark as 1 The memory block where the dirty table is located is added to GC Roots Medium scan , So you don't have to scan the whole old generation . The card table uses less memory , But the relative word length 、 The accuracy of the object is not accurate , You need to scan a piece of . So it's also a trade-off , How big is the card . There's another one ** A multi card watch **, To put it simply, there are multiple card lists , Here I'll draw two cards to show my meaning . 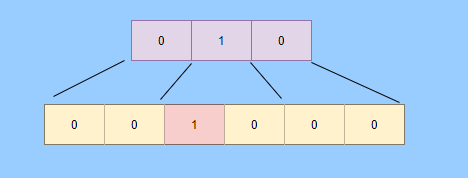 The card list above shows a wider range of addresses , This allows you to scan a wide range of tables first , Found the middle piece dirty , And then through the subscript calculation directly get more specific address range . This kind of multi card table has larger heap memory , And when there are fewer cross generational references , Scanning efficiency is high . Card lists are generally maintained through a write barrier ,** Writing a barrier is actually equivalent to a AOP**, Add code to update the card table when the object reference field is assigned . It's very understandable , To put it bluntly, when referring to the field assignment, the current object is judged to be an old age object , The referenced object is a new generation object , Therefore, the card position corresponding to the old generation object is set to 1, It means dirty , Need to add root scan later . ** But this kind of scanning with the old age as the root will have floating garbage **, Because the objects of the old generation may have become rubbish , So if you take garbage as a root, the new generation of objects scanned out are likely to be garbage . ** But it's a sacrifice that generational collection has to make .** ## Incremental GC The so-called incremental GC In fact, it is in the application thread , Interspersed with a little bit of completion GC, Take a look at the picture to make it clear 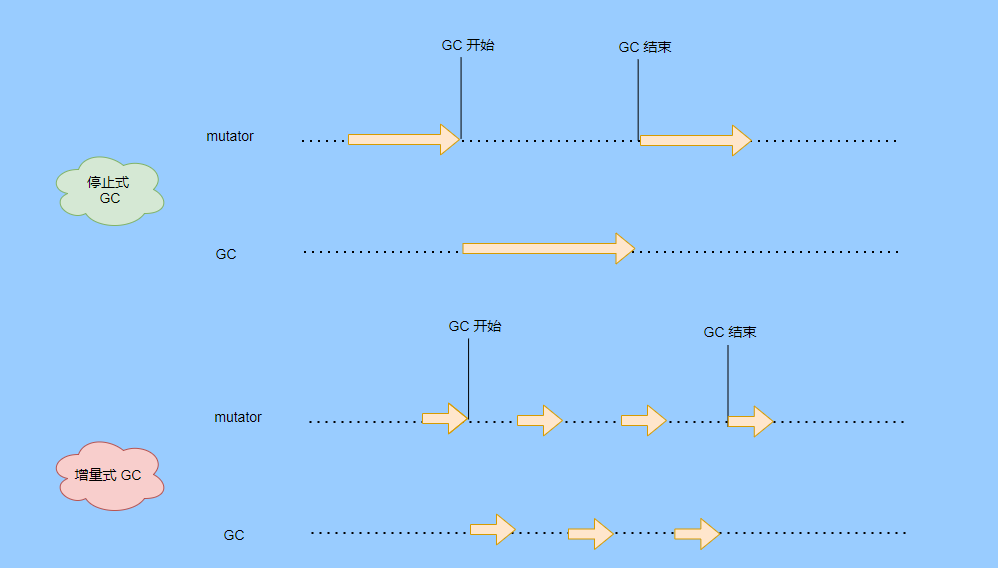 It looks like GC The time span of time is getting bigger , however mutator The pause is shorter . In the case of incremental GC ,Dijkstra People are abstract except ** Three color mark algorithm **, To represent GC There are three different states of objects . ### Three color mark algorithm white : Indicates an object that has not been found . gray : Indicates that you are searching for an object that has not yet been searched . black : Indicates that the search is complete . Here's a picture from Wikipedia , Although the color is not on , But it means right (black It was painted blue ,grey It was painted yellow ). 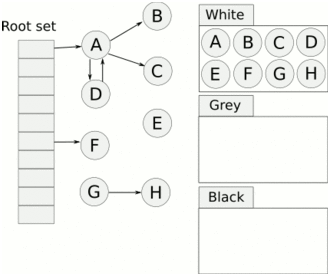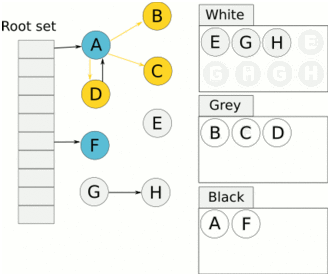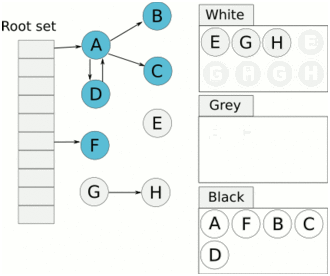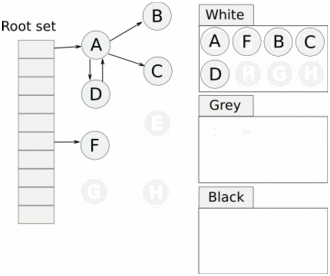 I'll use the text to outline the conversion of three colors . GC Before we start, everything is white ,GC At first, all the objects that root can reach are pushed into the stack , To be searched , Now the color is gray . Then the gray objects are taken out of the stack to search for sub objects , Sub objects are also painted gray , Into the stack . When all of its children are painted gray, the object is painted black . When GC When it's over, all the gray objects will be gone , The remaining black ones are living objects , The white ones are rubbish . General incremental notation - There will be three stages of clearance : 1. Root query , You need to pause the application thread , Find the object directly referenced by the root . 2. Marking stage , Concurrent execution with the application thread . 3. Removal phase . Here's an explanation GC The meaning of the two nouns in . Concurrent : Application threads and GC Threads run together . Parallel : Multiple GC Threads run together . It looks like there's nothing wrong with the tricolor logo ? Take a look at the picture below . 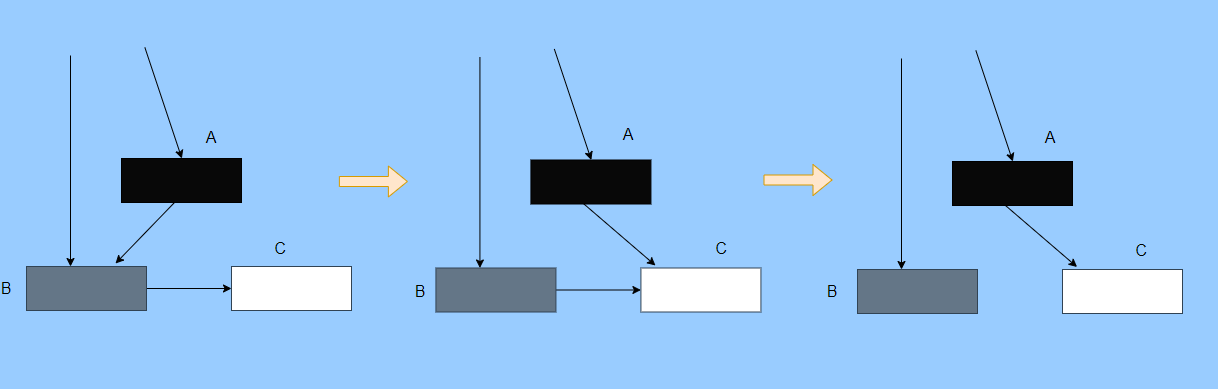 The first stage is to find A The children of B 了 , therefore A Dyed black ,B It's gray . You need to search for B. But in B When the search begins ,A The reference to is mutator For C, And then at this point B To C The reference to the is also deleted . And then we started searching for B , Now B There is no reference, so the search ends , Now C It's just trash , therefore A It's already black , So we won't find C 了 . That's what happened ** Missing mark ** Situation of , Remove the objects that are still in use as garbage , It's very serious , This is GC Not allowed ,** I prefer to let go of , You can't kill the wrong .** There's another situation ** Multi label **, such as A When it turns black , The root reference is mutator Deleted , Well, actually A It's rubbish , But it's already marked black , Then we have to wait for the next time GC wipe out . This is that there is no pause in the tagging process mutator Caused by , But it's also to make GC Reduce impact on application execution . In fact, multi criteria can be accepted , If you miss the mark, you have to deal with it , We can sum up the reasons for the omission : 1. mutator Insert a black object A To white objects C A quote from 2. mutator Removed gray objects B To white objects C A quote from As long as one of these two conditions is broken, there will be no omission of bid . At this time, two conditions can be broken by the following means : Use the write barrier when black references white objects , Set the white object to gray , It's called ** Incremental updating .** Use the write barrier to remove references to white objects from gray objects , Gray the white object , It's just storing old references . It's called **STAB(snapshot-at-the-beginning)**. ## Summary So far, the key points and ideas about garbage collection are almost the same , It is about JVM The garbage collector will be analyzed in the next chapter . Now let's do it again ** To summarize .** When it comes to garbage collection, we have to find the garbage first , There are two schools to find garbage , One is reference counting , One is accessibility analysis . Reference count garbage collection in time , More memory friendly , But loop references cannot be handled . Accessibility analysis is basically the core choice of modern garbage collection , However, due to the need for unified recycling, it is time-consuming , It is easy to affect the normal execution of the application . So the research direction of reachability analysis is how to reduce the impact on application execution STW(stop the world) Time for . Therefore, according to the object generational hypothesis, generational collection has been developed , According to the characteristics of objects, the new generation and the old generation are divided , Take different collection algorithms , Improve the efficiency of recycling . Break it down by any means GC To enable concurrency with the application thread , And take parallel collection , Speed up the collection . There's also a delay in the direction of assessment, or recycling part of the garbage, to reduce STW Time for . Generally speaking, garbage collection is very complicated , Because there are so many details , My article is just plain talk , Don't be fooled by my title . ## Finally This article has been written for a long time , The main thing is that it's a lot of content. How to arrange it is a little difficult , I also selectively cut a lot of , But it's still close 1W word . During this period, I also consulted a lot of materials , But personal ability is limited , If there are any mistakes, please contact me as soon as possible . ## The shoulders of giants http://arctrix.com/nas/python/gc/ https://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html 《The Garbage Collection Handbook 》 https://www.iteye.com/blog/user/rednaxelafx R Big blog https://www.jianshu.com/u/90ab66c248e6 Take up wolf's blog --- > Wechat search 【yes Training strategy of 】, Concern yes, From a little bit to a billion , Let's go
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢

![Network security engineer Demo: the original * * is to get your computer administrator rights! [maintain]](/img/14/ede1ffa7811dbc2a5b15b9a7b17a5e.jpg)