当前位置:网站首页>理解格式化原理
理解格式化原理
2020-11-06 21:04:00 【张彦飞allen】
在前文《磁盘开篇:扒开机械硬盘坚硬的外壳!》和《拆解固态硬盘结构》中,我们了解到了硬盘基本单位是扇区。在《磁盘分区也是隐含了技术技巧的》中我们也了解了磁盘分区是怎么回事,但刚分完区的硬盘也是不能直接被被操作系统使用的,必须还得要经过格式化。那么今天我们就简单聊一聊,Linux下的格式化到底都干了些啥。
Linux下的格式化命令是mkfs,mkfs在格式化的时候需要制定分区以及文件系统类型。该命令其实就是把我们的连续的磁盘空间进行划分和管理。我在我的机器上执行了一下,输出如下:
# mkfs -t ext4 /dev/vdb
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
6553600 inodes, 26214400 blocks
1310720 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2174746624
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
接下来让我们深入理解一下上面输出里携带的信息。
inode与block
在上面的结果中我们看到了几个重要信息
- 块大小:4096字节
- inode数量:6553600
- block数量:26214400
块大小设置的是4096字节,我们来分析两种场景
- 假如你的文件系统全部都用来存储1KB以下的小文件,这个时候你的磁盘1/3的空间将会被浪费无法使用。
- 假如你的文件全都是GB以上的大文件,这个时候你的inode索引节点里就需要直接或间接维护许许多多的block索引号
很明显,以上这两种情况下4096字节的块大小是不合适的。你需要自己根据情况选择自己的块大小进行重新格式化。
我们再看另外的两个数据,inode数量和block数量。我们用block数量除一下inode,26214400/6553600=4,也就是说平均4个block会有一个inode。再举两个极端的例子:
- 第一种情况,假如说我们的文件都是4KB以下的,那么我们的文件系统用到最后出现的情况就是inode全部用光了,还有1/3的block空闲,而且再也没有办法创建新文件了。
- 第二种情况,假如我们的文件都特别大,每一个文件需要1000个block,最后的情况就是block全部都用光了,但是inode又都空闲下来了,这个时候也是没办法再建文件的。
这些情况下,block和inode的配比也都是不符合你使用的,你需要根据自己的业务重新配置。mkfs傻瓜格式出来的结果无法满足你的业务需求,你就需要使用另外一些格式化命令了,比如mke2fs,这个命令允许你输入更详细的格式化选项,demo如下:
mke2fs -j -L "卷标" -b 2048 -i 8192 /dev/sdb1
块组
我们再回头看格式化后的结果,结果中显示了一些和groups相关的东东,如下:
800 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
那么这个groups到底说的是啥呢?其实呀,格式化后的所有inode并不是挨着一起放的,同样block也不是。而是分成了一个个的group,每一个group里都有一些inode和block。逻辑图如下:
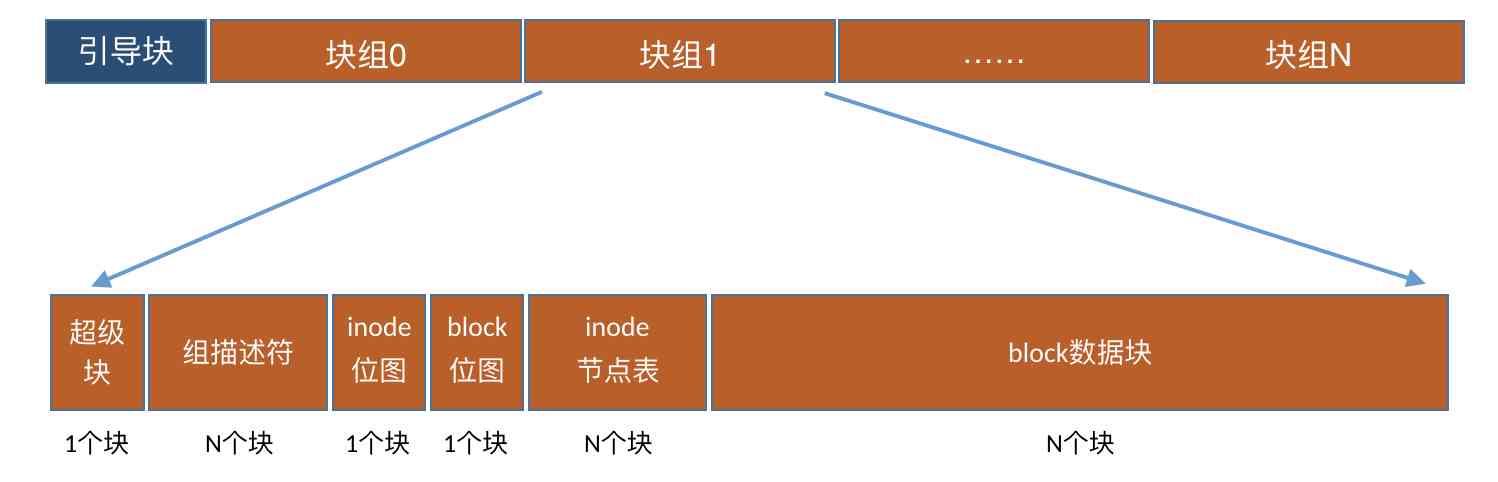
这个块组一般是多大呢?注意每个块中的数据块位图只有一个,假如你的块大小为4KB,这样一个bit代表一个数据块,4KB可以有32KB个bit,可以管理32K*4K=128M的数据块。来让我们实际动手验证一下,如下:
# dumpe2fs /dev/vdb
......
Block size: 4096
Inode size: 256
Inode count: 6553600
Block count: 26214400
......
Group 16: (Blocks 524288-557055) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0xe838, unused inodes 8192
Block bitmap at 524288 (+0), Inode bitmap at 524304 (+16)
Inode表位于 524320-524831 (+32)
24544 free blocks, 8192 free inodes, 0 directories, 8192个未使用的inodes
可用块数: 532512-557055
可用inode数: 131073-139264
......
Group 799: (Blocks 26181632-26214399) [INODE_UNINIT, ITABLE_ZEROED]
......
上述结果中包含信息如下:
- 该分区总共格式化好了800个块组
- 块组16共有32K个block(第524288-557055),
- block位图在524288这个块上
- inode位图在524304这个块上
- inode table占用了612个block(524320-524831)
- 剩下的其它的block(32K-1-1-612)就都真的是给用户准备的了,目前空闲未分配的在Free blocks可以查看到。
再次理解目录
好了,了解了以上原理以后,让我们回头在来看看目录使用的数据是怎么在磁盘上组织的。创建目录的时候,操作系统会在inode位图上寻找尚未使用的inode编号,找到后把inode分配给你。目录会默认分配一个block,所以还需要查询block位图,找到后分配一个block。在block里面,存储的就是文件系统自己定义的desty结构了,每一个结构里会保存其下的文件名,文件的inode编号等信息。某个实际文件夹在磁盘上最终使用的空间如下图所示:
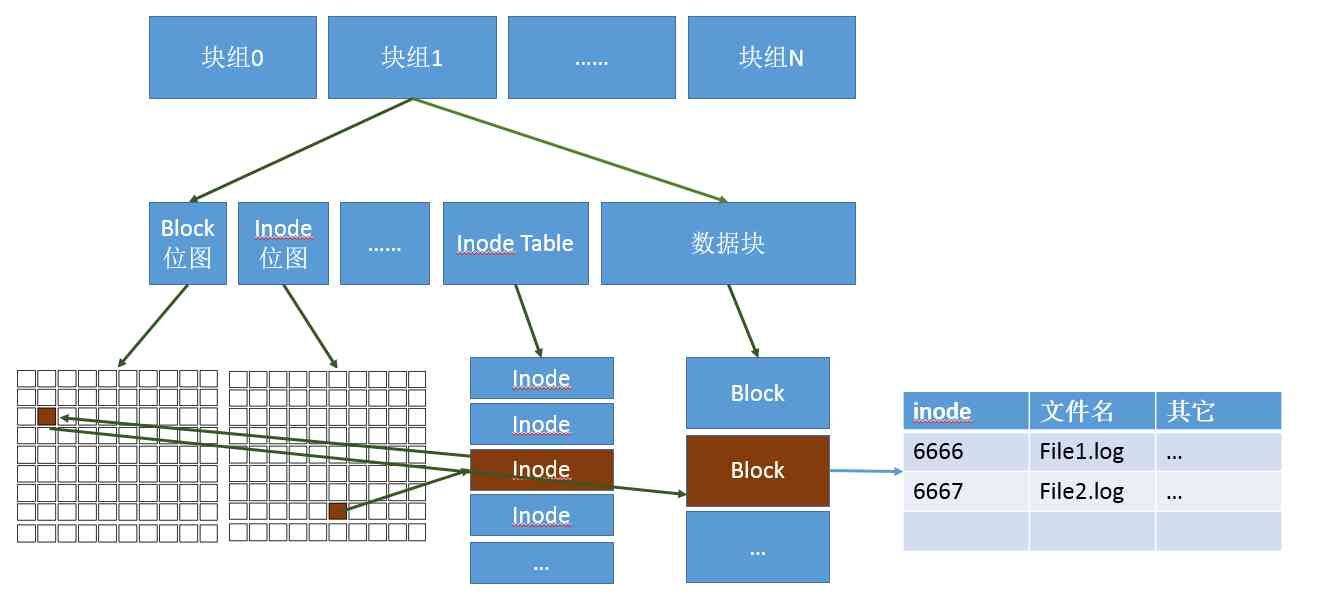
目录的block中保存的是其下面的文件和子目录的desty结构体,保存着它们的文件名和inode号。理解了目录,对于文件也是一样的。也需要消耗inode,当有数据写入的时候,再去申请block。
结论
硬盘就是一个扇区组成的大数组,是无法被我们使用的,需要经过分区、格式化和挂载三个步骤。分区是把所有的扇区按照柱面分割成不同的大块,格式化就把原始的扇区数组变成了可被Linux文件系统使用的inode、block等基本元素了。感觉格式化程序有点像是厨师团队里的那个切墩的,把原材料变成了可被厨师直接使用的葱花,肉段。格式化完后再经过最后一步挂载,对应的命令是mount,然后你就可以在它下面创建和保存文件了。
再扩展一下其实刚分完区的设备也是可以使用的,这个时候的分区叫裸分区,也叫裸设备。比如oracle就是绕开操作系统直接使用裸设备的。但是这个时候你就无法利用Linux文件系统里为你封装好的inode、block组成的文件与目录了,开发工作量会增加。
发现写文章的过程中最费时的是画图,眼睛快瞎了,路过就给个赞把,谢了!

开发内功修炼之硬盘篇专辑:
- 1.磁盘开篇:扒开机械硬盘坚硬的外衣!
- 2.磁盘分区也是隐含了技术技巧的
- 3.我们怎么解决机械硬盘既慢又容易坏的问题?
- 4.拆解固态硬盘结构
- 5.新建一个空文件占用多少磁盘空间?
- 6.只有1个字节的文件实际占用多少磁盘空间
- 7.文件过多时ls命令为什么会卡住?
- 8.理解格式化原理
- 9.read文件一个字节实际会发生多大的磁盘IO?
- 10.write文件一个字节后何时发起写磁盘IO?
- 11.机械硬盘随机IO慢的超乎你的想象
- 12.搭载固态硬盘的服务器究竟比搭机械硬盘快多少?
我的公众号是「开发内功修炼」,在这里我不是单纯介绍技术理论,也不只介绍实践经验。而是把理论与实践结合起来,用实践加深对理论的理解、用理论提高你的技术实践能力。欢迎你来关注我的公众号,也请分享给你的好友~~~
版权声明
本文为[张彦飞allen]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4746202/blog/4703284
边栏推荐
- Deep understanding of common methods of JS array
- Windows 10 tensorflow (2) regression analysis of principles, deep learning framework (gradient descent method to solve regression parameters)
- Using consult to realize service discovery: instance ID customization
- Analysis of partial source codes of qthread
- Classical dynamic programming: complete knapsack problem
- 前端都应懂的入门基础-github基础
- Named entity recognition in natural language processing: tanford core LP ner (1)
- After reading this article, I understand a lot of webpack scaffolding
- Summary of common algorithms of binary tree
- 一篇文章带你了解CSS 渐变知识
猜你喜欢

How to customize sorting for pandas dataframe
NLP model Bert: from introduction to mastery (2)
What to do if you are squeezed by old programmers? I don't want to quit

Python download module to accelerate the implementation of recording

Just now, I popularized two unique skills of login to Xuemei
vue-codemirror基本用法:实现搜索功能、代码折叠功能、获取编辑器值及时验证
Python基础数据类型——tuple浅析
01. SSH Remote terminal and websocket of go language

Summary of common algorithms of linked list
Python Jieba segmentation (stuttering segmentation), extracting words, loading words, modifying word frequency, defining thesaurus
随机推荐
Our best practices for writing react components
Save the file directly to Google drive and download it back ten times faster
axios学习笔记(二):轻松弄懂XHR的使用及如何封装简易axios
Filecoin的经济模型与未来价值是如何支撑FIL币价格破千的
Elasticsearch数据库 | Elasticsearch-7.5.0应用搭建实战
5.4 static resource mapping
Analysis of etcd core mechanism
带你学习ES5中新增的方法
[C / C + + 1] clion configuration and running C language
Python基础数据类型——tuple浅析
Skywalking series blog 2-skywalking using
Advanced Vue component pattern (3)
Analysis of react high order components
It's so embarrassing, fans broke ten thousand, used for a year!
Python filtering sensitive word records
Linked blocking Queue Analysis of blocking queue
vue-codemirror基本用法:实现搜索功能、代码折叠功能、获取编辑器值及时验证
百万年薪,国内工作6年的前辈想和你分享这四点
Natural language processing - wrong word recognition (based on Python) kenlm, pycorrector
6.3 handlerexceptionresolver exception handling (in-depth analysis of SSM and project practice)