当前位置:网站首页>浅谈JVM(面试常考)
浅谈JVM(面试常考)
2022-07-05 05:21:00 【粉色的志明】
JVM 简介
JVM 是 Java Virtual Machine 的简称,意为 Java虚拟机。
虚拟机是指通过软件模拟的具有完整硬件功能的、运行在一个完全隔离的环境中的完整计算机系统。
常见的虚拟机:JVM、VMwave、Virtual Box。
JVM 和其他两个虚拟机的区别:
- VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统中会有很多的寄存器;
- JVM则是通过软件模拟Java字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进
行了裁剪。
JVM 是一台被定制过的现实当中不存在的计算机。
日常开发中,Java 程序员一般不会使用到 JVM 内部的东西,想要深入理解,可以读一下这本书,干货非常多

1. JVM 内存区域划分
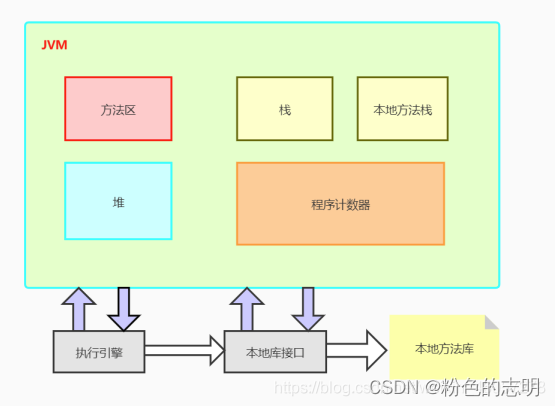
JVM 内存是从操作系统这里申请的,划分了不同的区域,不同的区域完成不同的功能
什么是线程私有?
由于JVM的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现,因此在任何一个确定的时刻,一个处理器(多核处理器则指的是一个内核)都只会执行一条线程中的指令。因此为了切换线程后能恢复到正确的执行位置,每条线程都需要独立的程序计数器,各条线程之间计数器互不影响,独立存储。我们就把类似这类区域称之为"线程私有"的内存
1.1 程序计数器(线程私有)
程序计数器的作用:用来记录当前线程执行的行号的。
它是内存中最小的区域,保存了下一条要执行的指令的地址在哪…
指令就是字节码,程序要想运行,JVM 就得把字节码加载起来,放到内存中,程序就会一条一条把指令从内存中取出来,放到 CPU 上执行,也就是需要随时记住,当前执行到哪一条了.
CPU 是并发式的执行过程,它不是只给一个进程提供服务的,它要伺候所有的进程,正因为操作系统是以线程为单位进行调度执行的,每一个线程都得记录自己的执行位置,即程序计数器,每个线程都有一个.
1.2 Java 虚拟机栈(线程私有)
描述了局部变量和方法调用信息,方法调用的时候,每次调用一个新的方法,就涉及到"入栈"操作,每次执行完了一个方法,都涉及到"出栈"操作.
栈空间是比较小的,在 JVM 中可以配置栈空间的大小,但是一般也就几 M 或 几十 M,因此栈是很有可能会满的(正常我们写代码一般没事,就怕递归,一旦递归条件没设好,就会出现栈溢出:StackOverflowException)
Java 虚拟机栈的作用:Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是 Java 方法执行的
内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈。
Java 虚拟机栈中包含了以下 4 部分:1. 局部变量表: 存放了编译器可知的各种基本数据类型(8大基本数据类型)、对象引用。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在执行期间不会改变局部变量表大小。简单来说就是存放方法参数和局部变量。
2. 操作栈:每个方法会生成一个先进后出的操作栈。
3. 动态链接:指向运行时常量池的方法引用。
4. 方法返回地址:PC 寄存器的地址
1.3 本地方法栈(线程私有)
本地方法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的。
1.4 堆(线程共享)
堆的作用:程序中创建的所有对象都在保存在堆中
一个进程只有一份,多个线程共用一个堆,也是内存中空间最大的区域,我们 new 出来的对象,就是在堆中,对象的成员变量,自然也在堆中.
注意:
内置类型的变量在栈上,引用类型的变量在堆上,这个说法是错误的
应该是局部变量在栈上,成员变量和new 的对象在堆上

1.5 方法区(线程共享)
方法区的作用:用来存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据的。
方法区中,放的是"类对象",所谓的"类对象":我们所写的.java这样的代码会变成.class(二进制字节码),.class会被加载到内存中,也就是 JVM 构造成的类对象(加载的过程就称为"类加载"),"类对象"就描述了这个类长啥样,类的名字是啥,里面有哪些成员,有哪些方法,每个成员叫啥名字是啥类型(public/private…),每个方法叫啥名字,是啥类型(public/private…),方法里面包含的指令…
"类对象"里面还有一个很重要的东西,静态成员(static)
被static 修饰的成员,成为了"类属性",而普通成员,叫做"实例属性"
2. JVM 类加载机制
类加载,其实是设计一个 运行时环境 的一个重要的核心功能,类加载是干啥的?他是把 .class文件,加载到内存中,构建成类对象
2.1 类加载过程
类加载生命周期:
其中前 5 步是固定的顺序并且也是类加载的过程,其中中间的 3 步我们都属于连接,所以对于类加载来说,分成了三大步骤:
Loading,Linking,Initialization(回答别人的时候尽量用英文)
2.1.1 加载(Loading)
“加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载 Class Loading 是不同的,一个是加载 Loading 另一个是类加载 Class Loading,所以不要把二者搞混了
在加载 Loading 阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
总结就是先找到对应的
.class文件,然后打开并读取.class文件(字节流),同时初步生成一个类对象
在 Loading 中一个关键环节,
.class文件里面到底啥样?详细信息可查阅官方文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html
会根据上面图中的格式,把读取并解析到的信息,初步的填写到类对象中
2.1.2 连接(Linking)
连接一般就是建立好多个实体之间的联系
一: 验证(Verification)
主要就是验证读到的内容是不是和规范中规定的格式完全匹配,如果发现这里读到的数据格式不符合规范,就会类加载失败,并且抛出异常
二: 准备(Preparation)
准备阶段是正式 为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段比如:
public static int value = 123;
他是初始化 value 的 int 值为 0,而非 123
三: 解析(Resolution)
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
意思是由于在.class文件中,常量是集中放置的,每个常量有一个编号,.class文件的结构体里初始情况只是记录了编号,所以就需要根据编号找到对应的内容,填充到类对象中。
2.1.3 初始化(Initializing)
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程,就是真正对类对象进行初始化,尤其是针对静态成员
典型面试题:什么时候会触发某个类的加载(代码举例)?
他的打印顺序是什么?
结果:
只要这个类被用到了,就要先加载这个类(像实例化,调用方法,调用静态方法,被继承…都算被用到)
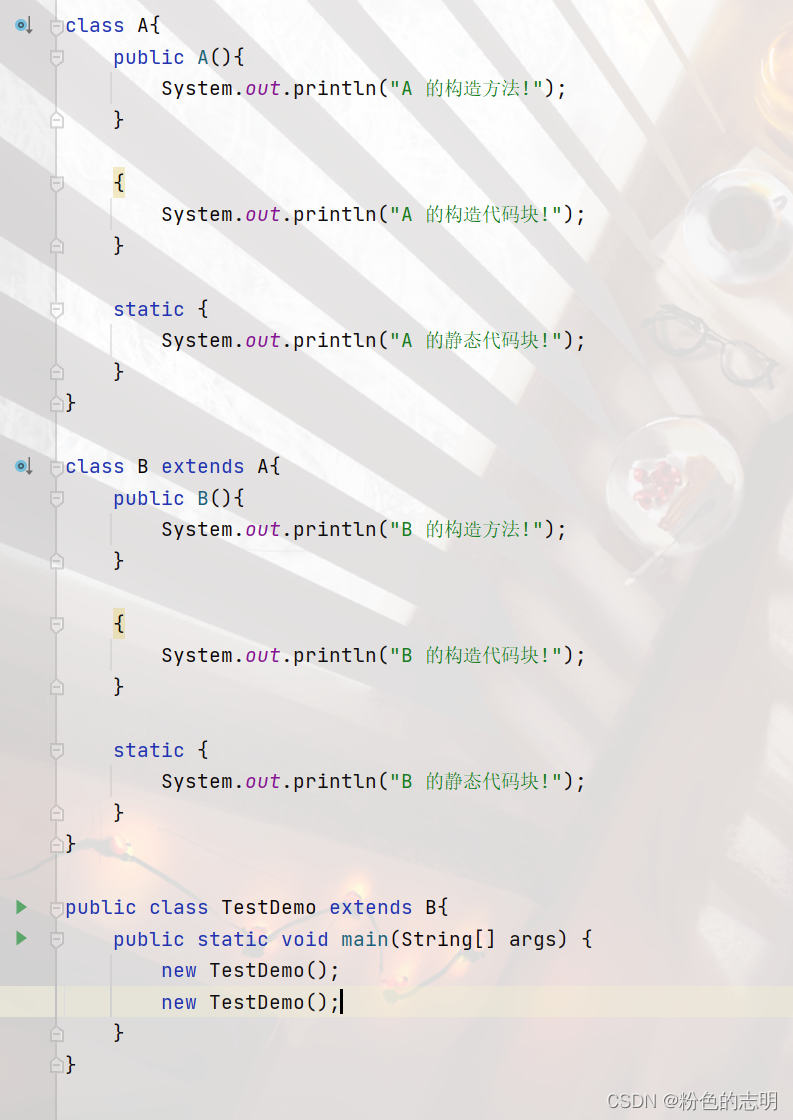
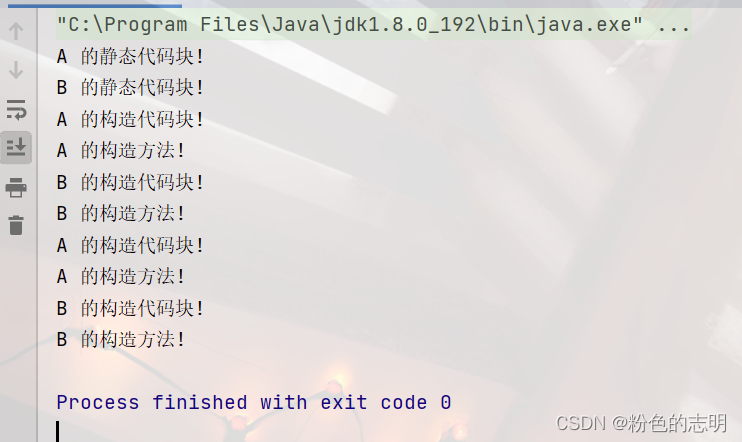
大的原则:
1: 类加载阶段会进行静态代码块的执行,要想创建实例,势必要先进行类加载;
2: 静态代码块只是类加载阶段执行一次
3: 构造方法和构造代码块,每次实例化都会执行,构造代码块在构造方法前面
4: 父类执行在前,子类执行在后
5: 咱们的程序是从main开始执行,main这里是Test的方法,因此要执行main就需要先加载TestDemo
咱们的程序是从 main 方法开始执行的,main 这里是 TestDemo 这个类的方法,因此要先执行 main,就需要先加载 TestDemo,而 TestDemo 继承 B,要加载 TestDemo,就要先加载 B,B 又 继承 A,又要先加载 A
2.2 双亲委派模型
这个东西在我们工作中用处不大,但是面试的时候可是经常被问到…
这个东西就是类加载中的一个环节,这个环节处于 Loading 阶段的(比较靠前的部分),双亲委派模型,其实就是 JVM 中的类加载器,如何根据全限定名(java.lang.String)来找到 .class文件的过程
类加载器:JVM 里面提供了专门的对象,叫做类加载器,负责进行类加载,当然,找文件的过程也是类加载器来负责的….class文件,可能放的位置有很多,有的是放在 JDK 目录里,有的是放在项目目录里,还有的放在其他的特定位置等,因此,JVM 里面提供了多个类加载器,每个类加载器负责一个片区…
默认的类加载器,主要有 3 个:
1: BootstrapClassLoader
负责加载标准库中的类(String,ArrayList,Random,Scanner…)2: ExtensionClassLoader
负责加载 JDK 扩展的类(现在很少会用到)3: ApplicationClassLoader
负责加载当前项目目录中的类
此外,程序员还可以自定义类的加载器,来加载其他目录中的类,像 Tomcat 就自定义了类加载器,用来专门加载 webapps 里面的
.class…
我们的双亲委派模型,就描述了这个找目录过程,也就是上述类加载器是如何配合的…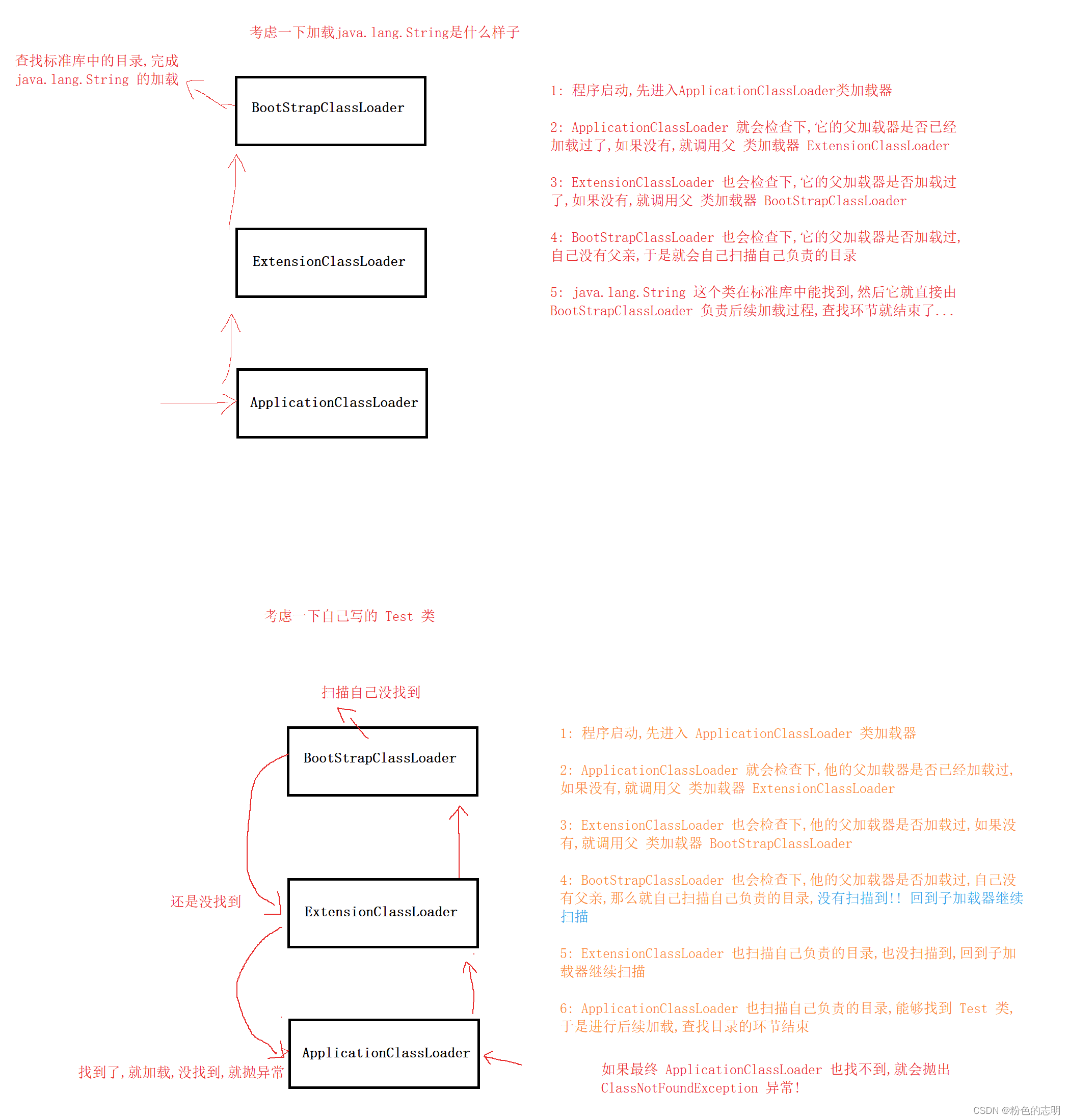
这一套查找规则,就称为"双亲委派模型"(这是音译过来的,parent 既可以是父亲也可以是母亲,按规矩,叫他"单亲委派模型"也不是不可以,当然,起名字这回事不是我们能决定的)
为啥 JVM 要这么设计?
理由就是,一旦程序员自己写的类和标准库中的类,全限定类名重复了,也能够顺利的加载到标准库中的类!!
就像是 java.lang.String 这样的类,我们自己定义的,程序加载的话还是 标准库中的类,这样就不会冲突了,安全性得到了保证
如果自定义的类加载器,是否也要遵守双亲委派模型?
可以遵守,也可以不遵守,看需求.
就像 Tomcat 加载 webapps 中的类,就没有遵守(因为遵守了也没啥意义)
3. JVM 垃圾回收机制(GC)
3.1 什么是垃圾回收
垃圾回收(GarbageCollection,GC),我们在写代码的时候,经常会申请内存的,创建变量,new 对象,加载类…这些都是在申请内存,都是从操作系统申请,既然申请了内存,那我们在不用的时候肯定也是要归还内存的。
一般来说,申请内存的时机都是明确的,(需要保存某些数据,就需要申请内存),而释放内存的时期,就不是那么清楚了.我们也不清楚自己还用不用这块内存
举个例子:假设下午回到家就把你身上的衣服随手一扔,就不管不顾了,这时你妈妈发现了,就把你的衣服给整理好收拾起来了,放到了衣柜里,第二天,如果你不穿还好,但是你还要穿着这件衣服出门,你去原来的位置找,诶?不见了,这不就尴尬了吗…
(这就是内存释放早了)
那释放晚点可以吗?也不太好,就像你在图书馆占座,你一大早就把位置给占了,结果你一天都没去,这不也很尴尬吗,占着位置不用,别人也用不到(这就是内存释放迟了)
而我们想要的是能够不早也不迟
3.2 为啥会出现垃圾回收机制
像 C 语言: "内存释放这事我不管,你们程序员自己看着办吧,反正又不扣我的钱…"因此,在 C 语言中,就会遇到一个常见的令人头疼的问题 => "内存泄露"(申请之后,忘了释放) => 可用的内存越来越少,最终无内存可用了!!所以,"内存泄露"是C/C++ 程序员的头疼的问题,有的泄露快,有的泄露慢,暴露的时机不确定,如果出现了,是很难排查的.C++后来就提出了一个智能指针(大概就只是简单依赖了一下 C++ 中的 RAII机制,其实一点也不智能..)这样的机制,通过它就可以一定程度上降低"内存泄露"的风险…但它在 java 众多机制面前就是个弟中弟(滑稽)
所以,像 Java,GO,PHP…现在市面上的大部分主流编程语言,都采取了一个方案,就是垃圾回收机制!!
大概就是有运行时环境(像JVM,Python 解释器,Go 运行时…)来通过更复杂的策略判定内存是否可以回收,并执行回收动作…垃圾回收,本质上是靠运行时环境,额外做了很多的工作,来完成自动释放内存的操作的,让程序员心智负担大大降低了
但是,垃圾回收也是有劣势的:
1: 消耗额外的开销(消耗资源更多了)
2: 可能会影响程序的流畅运行(垃圾回收经常会引入 STW(Stop The World,就像是时间静止) 问题)
垃圾回收这么香,为啥 C++ 不引入 GC?
其实也有大佬提出过这个方案,但是并没有实施,因为 C++ 语言有两条高压线,是他的核心原则:1:和 C 语言兼容,也能够和各种硬件各种操作系统做到最大化的兼容2:最求性能的极致…
像人工智能,游戏引擎,高性能服务器,操作系统内核…对于兼容性/性能要求极高的场景还是得 C/C++ 来干
3.3 垃圾回收要回收啥
回收的是内存,但内存有包括:程序计数器,栈,堆和方法,有些回收,有些不回收:
程序计数器:固定大小,不涉及释放,也就不需要 GC栈:函数执行完毕,对应的栈帧就自动释放了,也就不需要 GC堆:需要GC,代码中大量的内存都在堆上方法区:类对象,类加载来的,进行"类卸载"就需要释放内存,卸载操作其实是一个非常低频的操作(很少涉及垃圾回收)
我们这里就讨论堆上的垃圾回收
首先看一下这张图:
上面这张图可以把它理解为三个派别:积极派,消极派,中间摇摆派,
积极派:正在使用的内存就不释放消极派:不再使用的内存肯定要释放中间摇摆派:位于红色和蓝色之间的代表一部分在使用,一部分不用了,针对这种情况是不释放的,等到用完了不用了才释放
GC 中就不会出现"半个对象"的情况,主要是为了让垃圾回收起来更方便,更简单,记住:垃圾回收的基本单位是"对象",而不是字节
3.4 具体是如何实现垃圾回收的
就分为两个大阶段,第一阶段: 找垃圾/判定垃圾.., 第二阶段: 释放垃圾..
就像打扫房间,先把垃圾都清理到垃圾桶里,然后再统一丢出房间…
3.4.1 如何找垃圾/判定垃圾
我们当下主流的思路有两种方案:1: 基于引用计数(不是Java中采取的方案,这是别的语言,像Python采取的方案)2:基于可达性分析(这个是Java采取的方案)
注意别人问你:
1: 谈谈垃圾回收机制中如何判定是不是垃圾
2: 谈谈 Java 的垃圾回收机制中如何判定是不是垃圾
这俩问题可是有坑的,这个基于可达性分析才是 Java 的,可不要别人问 Java的 你说的却是 基于引用计数的
① 基于引用计数
针对每个对象,都会额外引入一小块内存,保存这个对象有多少个引用指向他
例如: Test t = new Test(); t 是指向这个对象的引用,因此 Test 对象有一个引用,引用计数为 1
如果再写个:Test t2 = t ,那么就说明 t 和 t2 都是指向这个对象的引用,此时我们的引用计数就变成了2
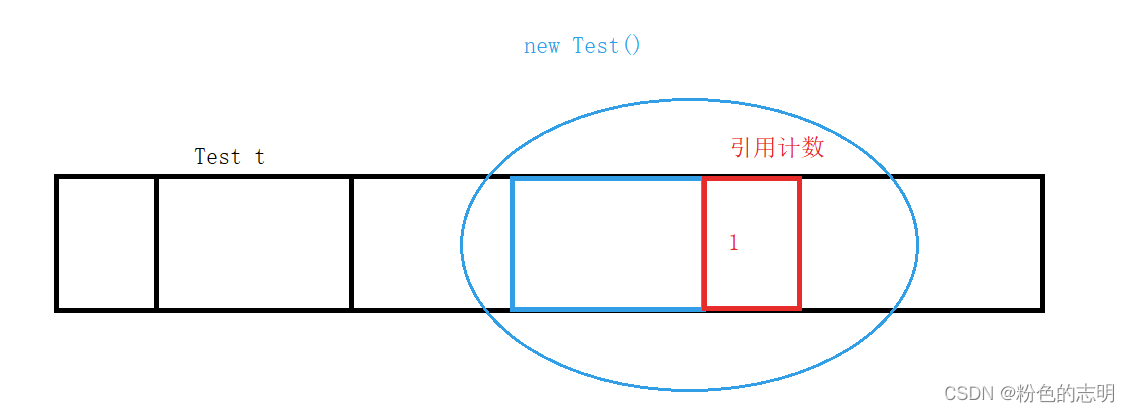
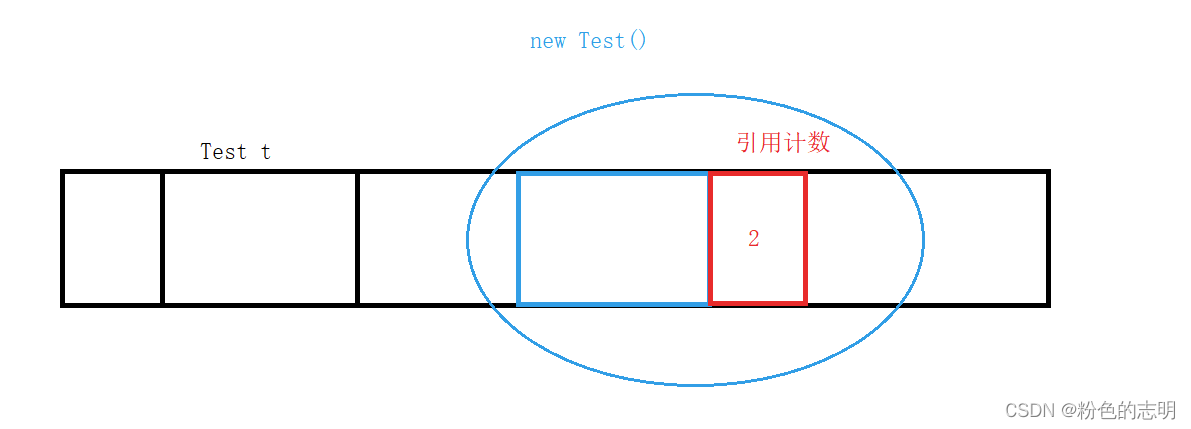
当引用计数为 0 的时候,就不在使用,就认为是垃圾,就释放掉内存
引用计数的缺点:
1:空间利用率比较低!!每个 new 的对象都得搭配个计数器(计数器假设 4个字节),如果对象本身很大(几百个字节),多出来4个字节,就不算什么,但是如果本身对象很小(自己才4个字节),多出4个字节,相当于空间被浪费了一半2:会有循环引用的问题
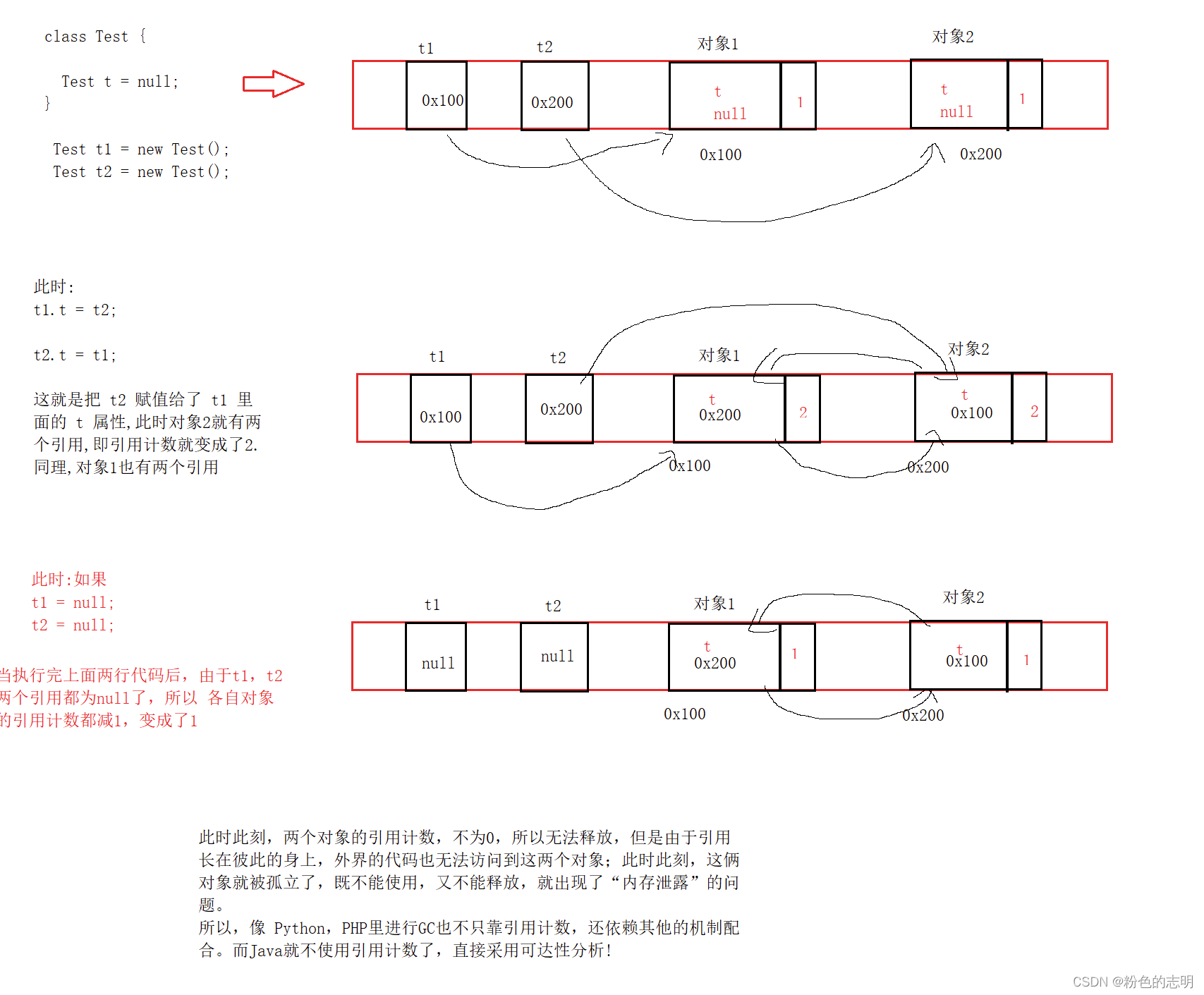
② 基于可达性分析
就是通过额外的线程,定期的针对整个内存空间的对象进行扫描,有一些起始位置(称为 GCRoots),会类似于深度优先遍历一样,把可以访问到的对象都标记一遍.(带有标记的对象就是可达的对象),没有被标记的对象,就是不可达的,也就是垃圾…
GCRoots:指栈上的局部变量,常量池中的引用指向的对象,方法区中的静态成员指向的对象…
举个例子:
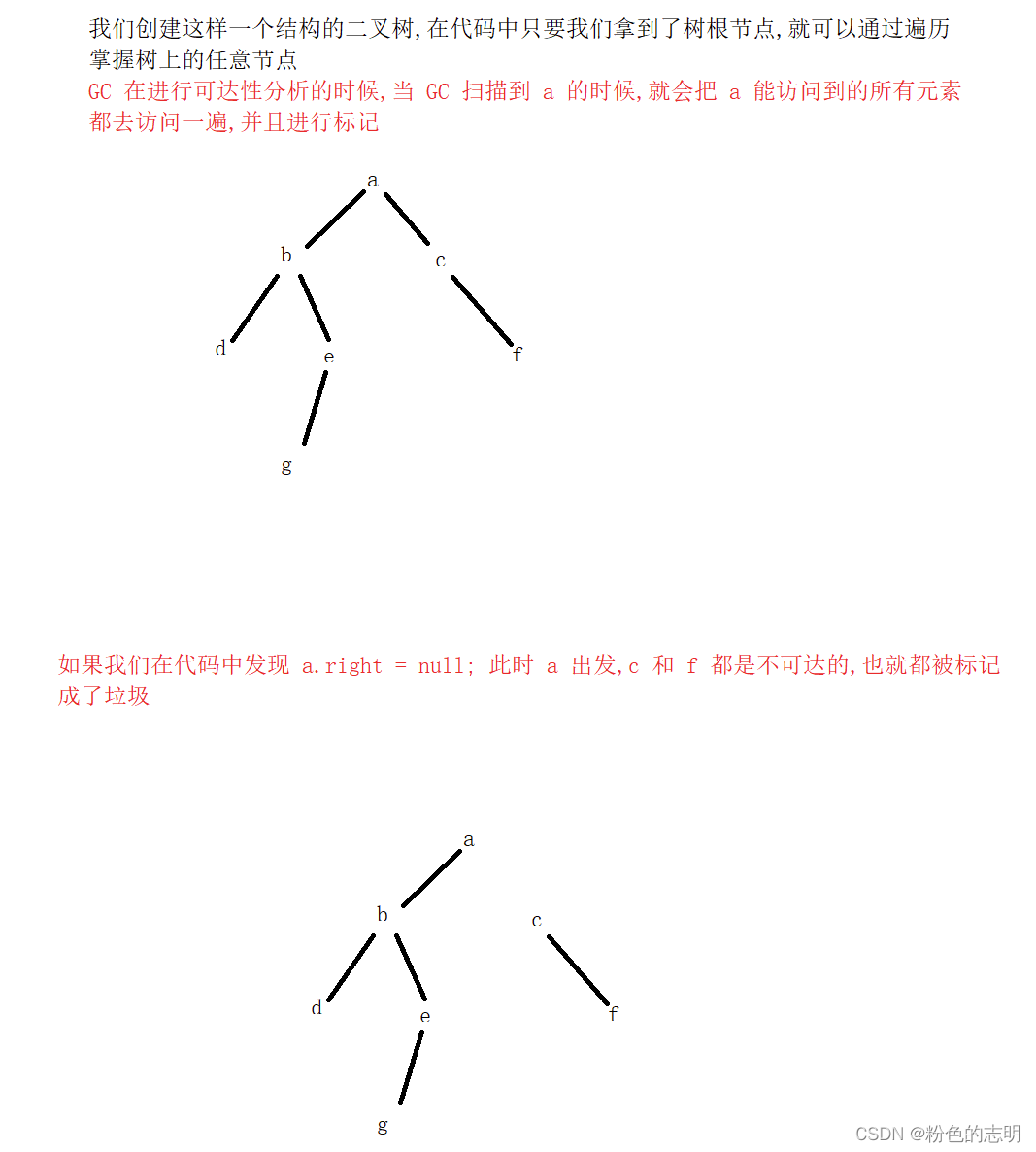
优点:克服了引用计数的两个缺点,空间利用率低,循环引用的问题缺点:系统开销大,如果内存中对象特别多,遍历一次可能比较慢,消耗时间和系统资源
总之,找垃圾,核心就是确认这个对象未来是否还会使用,那什么算不使用?就是没有了引用指向,就不使用
3.4.2 垃圾回收算法
① 标记 - 清除 算法
标记就是可达性分析的过程,清除就是直接释放内存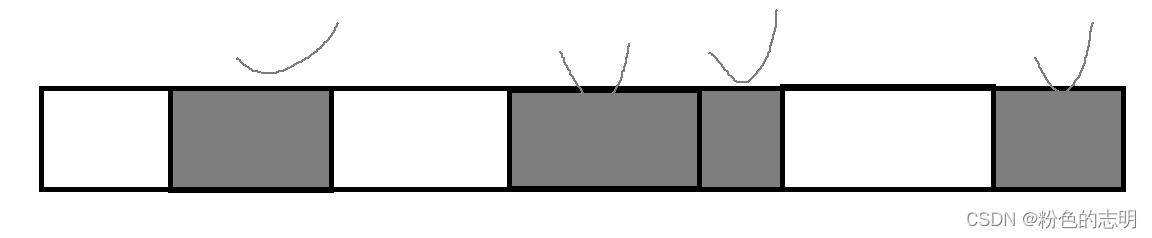
此时如果直接释放,虽然内存是还给了系统,但是我们发现被释放的内存是离散的,并不连续,给我们带来的问题就是"内存碎片"
空闲的内存有很多,如果我们假设内存一共是 1G,如果我们申请 500M 内存,他也是有可能申请失败的(因为申请的 500M 是连续的内存),而每次申请,内存都得是连续的空间,而这里的 1G 空闲内存可能只是"内存碎片",加在一起才有 1G
② 复制 算法
为了解决"内存碎片的问题",引入了复制算法,总体来说,就是"用一半,丢一半"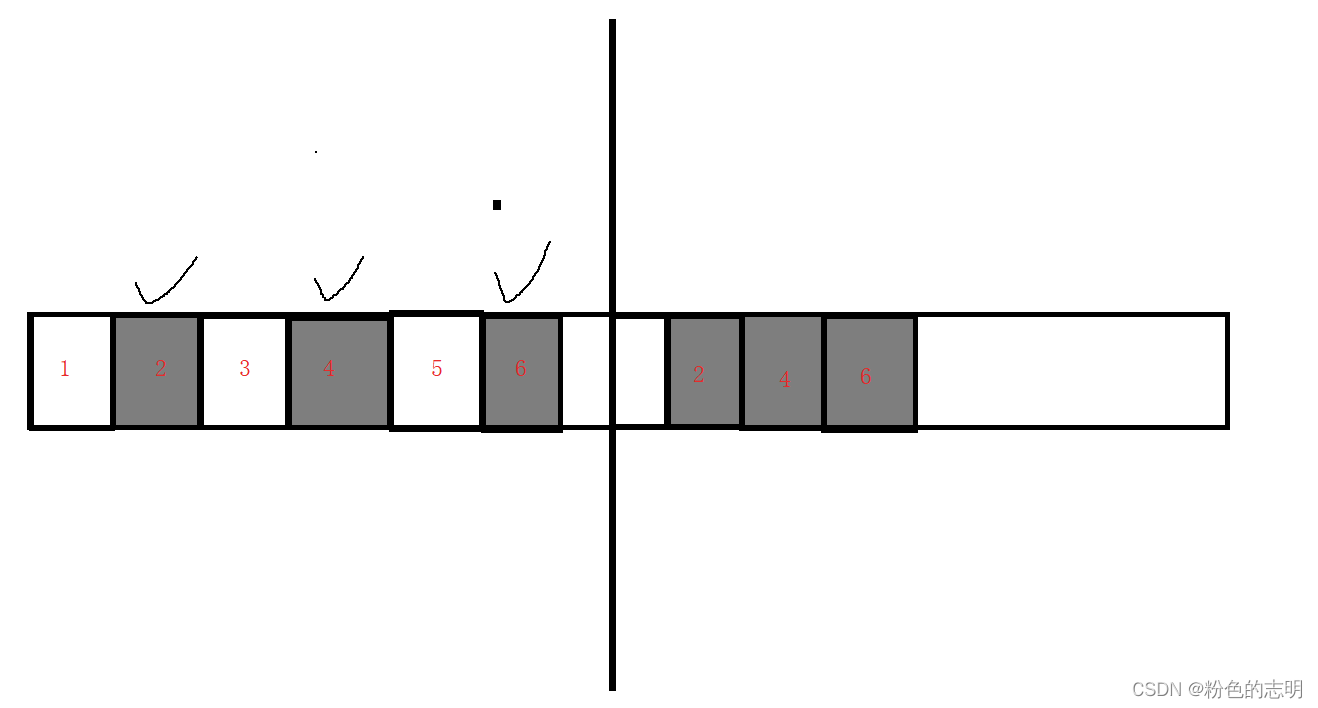
直接把不是垃圾的,拷贝到另一半,把原本这个空间整体都释放掉!!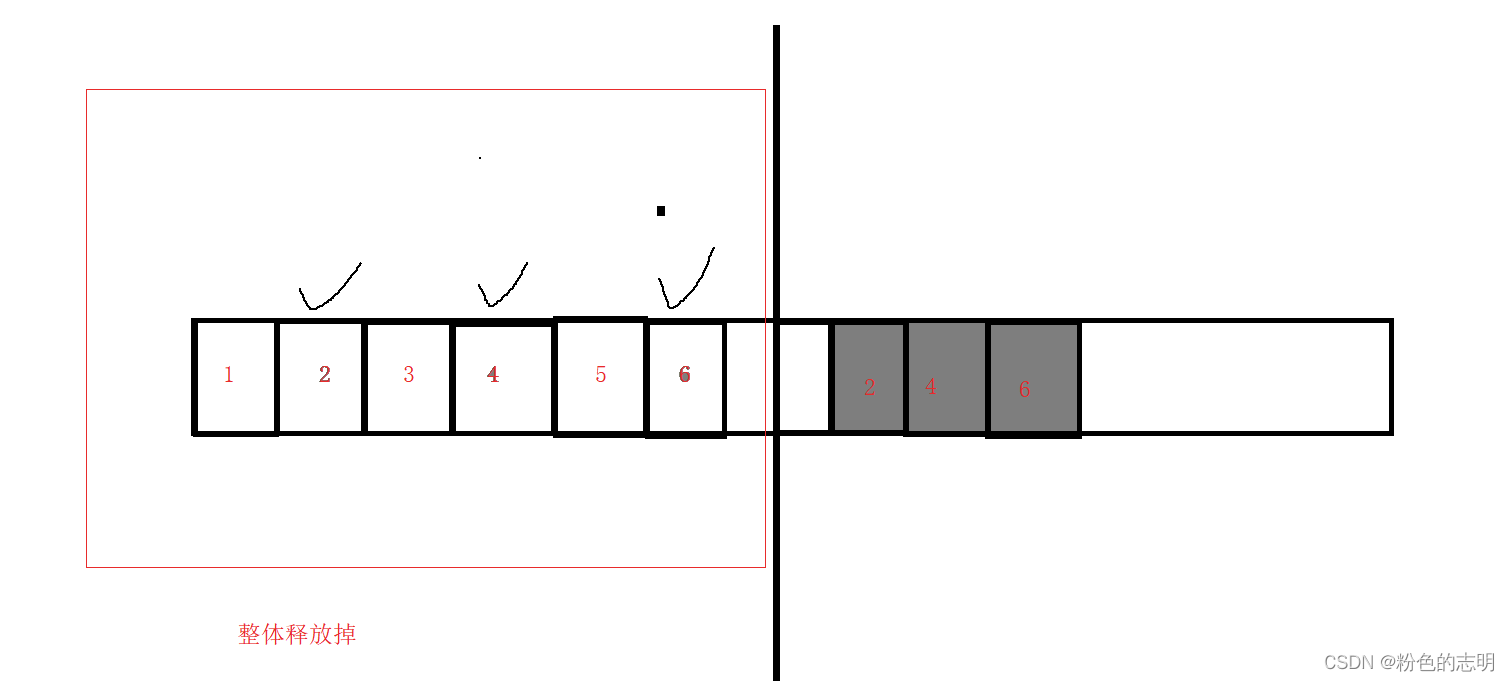
优点:解决了"内存碎片"的问题缺点:1. 内存空间利用率低 2. 如果要保留的对象多,要释放的的对象少,此时复制开销就很大.
③ 标记 - 整理 算法
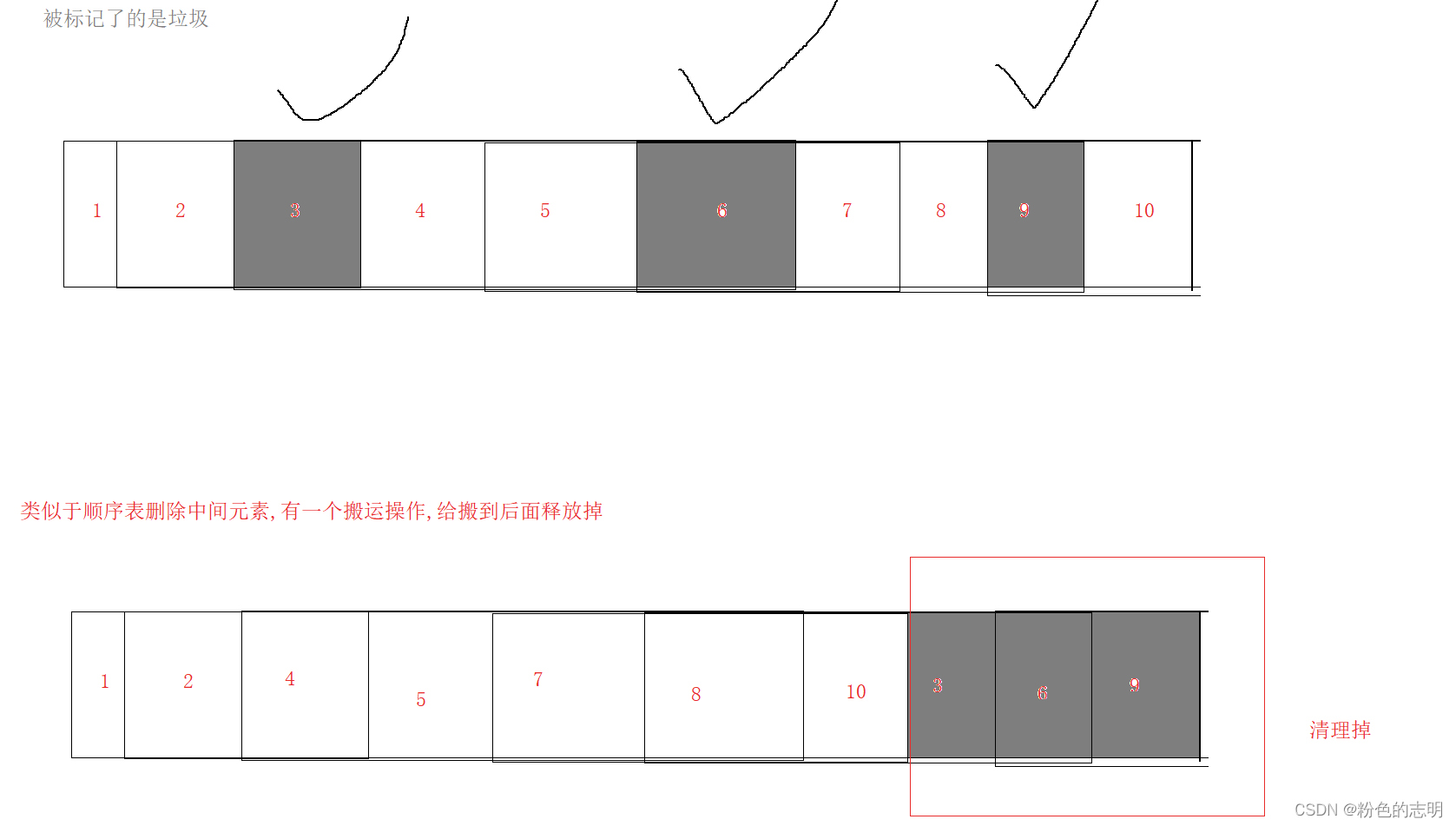
优点:空间利用率高了缺点:仍然没有解决复制/搬运元素开销大的问题
虽然上面说的都有缺陷,但在 JVM 中的实现,会把多种方案结合起来使用
④ 分代回收 算法
针对把对象进行分类(根据对象的"年龄"分类),一个对象熬过了一轮 GC 扫描,就称为"长了一岁",针对不同年龄的对象,采取不同的方案…
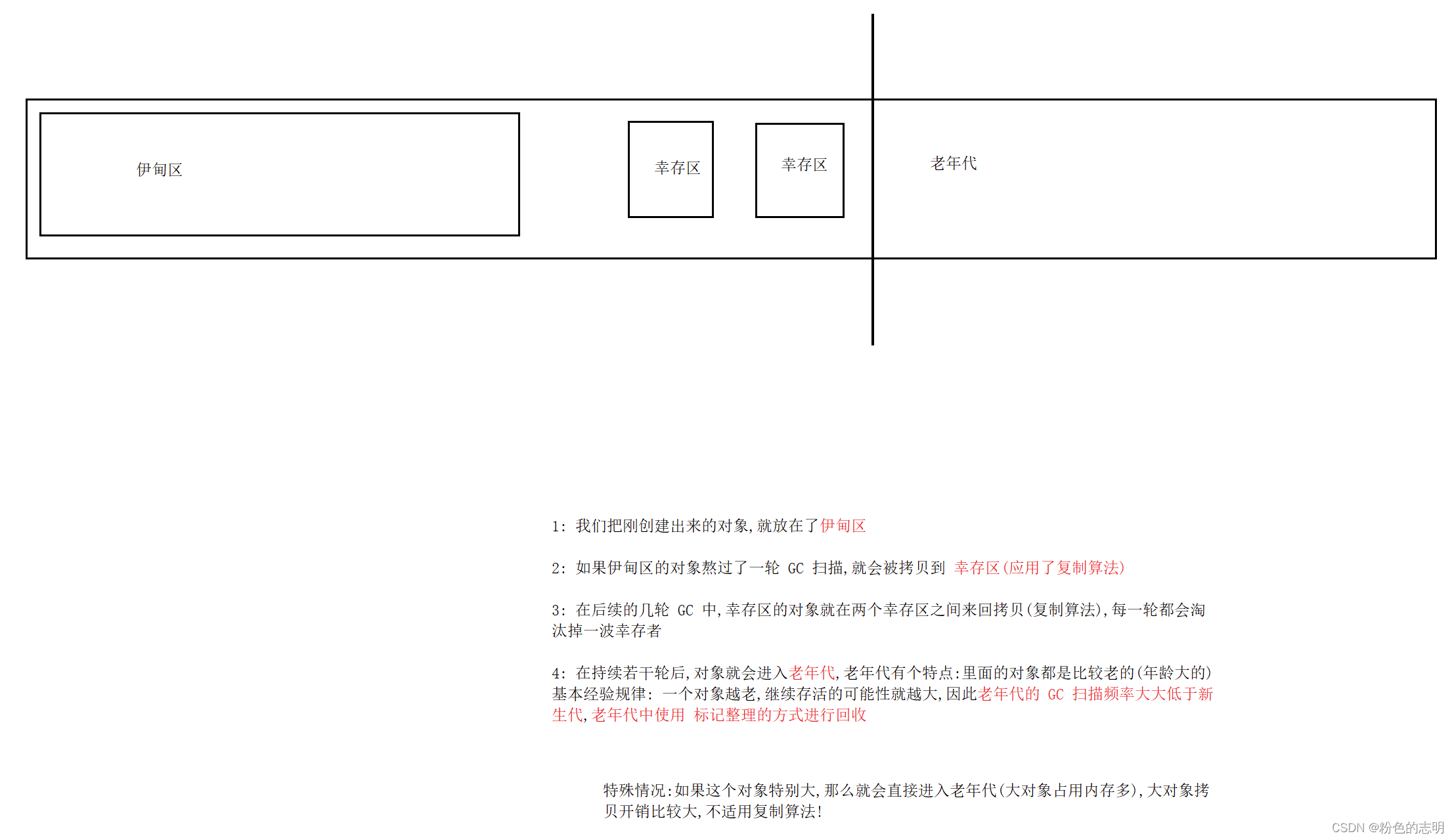
注意:网上可能有种说法: 98% 的新对象是熬不过一轮 GC 的,2% 的新对象会进入幸存区,这个数字其实是不靠谱的,如果别人问的话最好不要这样说,就说大多数对象熬不过一轮 GC 就行了
边栏推荐
- Yolov5 ajouter un mécanisme d'attention
- Django reports an error when connecting to the database. What is the reason
- Yolov5 adds attention mechanism
- Data is stored in the form of table
- Add level control and logger level control of Solon logging plug-in
- YOLOv5添加注意力機制
- ssh免密登录设置及使用脚本进行ssh登录并执行指令
- Under the national teacher qualification certificate in the first half of 2022
- Zheng Qing 21 ACM is fun. (3) part of the problem solution and summary
- 远程升级怕截胡?详解FOTA安全升级
猜你喜欢
YOLOv5-Shufflenetv2

Embedded database development programming (VI) -- C API

GBase数据库助力湾区数字金融发展
Reverse one-way linked list of interview questions
![[paper notes] multi goal reinforcement learning: challenging robotics environments and request for research](/img/17/db8614b177f33ee4f67b7d65a8430f.png)
[paper notes] multi goal reinforcement learning: challenging robotics environments and request for research

十年不用一次的JVM调用

Download and use of font icons
Service fusing hystrix

Django reports an error when connecting to the database. What is the reason
UE fantasy engine, project structure
随机推荐
Programmers' experience of delivering takeout
嵌入式数据库开发编程(五)——DQL
Haut OJ 1350: choice sends candy
Es module and commonjs learning notes
Zzulioj 1673: b: clever characters???
To the distance we have been looking for -- film review of "flying house journey"
Grail layout and double wing layout
【论文笔记】Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
[转]MySQL操作实战(一):关键字 & 函数
object serialization
被舆论盯上的蔚来,何时再次“起高楼”?
2022/7/1 learning summary
C语言杂谈1
Haut OJ 1352: string of choice
Stm32cubemx (8): RTC and RTC wake-up interrupt
Research on the value of background repeat of background tiling
Add level control and logger level control of Solon logging plug-in
使用Room数据库报警告: Schema export directory is not provided to the annotation processor so we cannot expor
[to be continued] [depth first search] 547 Number of provinces
远程升级怕截胡?详解FOTA安全升级