当前位置:网站首页>Data Lake (XIV): spark and iceberg integrated query operation
Data Lake (XIV): spark and iceberg integrated query operation
2022-07-05 16:07:00 【Lansonli】

List of articles
Spark And Iceberg Integrate query operations
One 、DataFrame API load Iceberg Data in
3、 ... and 、 Query table history
Four 、 Query table data files
5、 ... and 、 Inquire about Manifests
6、 ... and 、 Query the specified snapshot data
7、 ... and 、 Query data according to timestamp
8、 ... and 、 Rollback snapshot
Nine 、 Merge Iceberg Data files for tables
Ten 、 Delete historical snapshot
Spark And Iceberg Integrate query operations
One 、DataFrame API load Iceberg Data in
Spark operation Iceberg Not only can you use SQL Mode query Iceberg Data in , You can also use DataFrame Mode load Iceberg Table data , Can pass spark.table(Iceberg Table name ) perhaps spark.read.format("iceberg").load("iceberg data path") To load the corresponding Iceberg Table data , The operation is as follows :
val spark: SparkSession = SparkSession.builder().master("local").appName("test")
// Appoint hadoop catalog,catalog The name is hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//1. establish Iceberg surface , And insert data
spark.sql(
"""
|create table hadoop_prod.mydb.mytest (id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.mydb.mytest values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)
//1.SQL Mode reading Iceberg Data in
spark.sql("select * from hadoop_prod.mydb.mytest").show()
/**
* 2. Use Spark Inquire about Iceberg In addition to using sql Out of the way , You can also use DataFrame The way , It is recommended to use SQL The way
*/
// The first way is to use DataFrame Mode query Iceberg Table data
val frame1: DataFrame = spark.table("hadoop_prod.mydb.mytest")
frame1.show()
// The second way to use DataFrame load Iceberg Table data
val frame2: DataFrame = spark.read.format("iceberg").load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
frame2.show()Two 、 Query table snapshot
Each direction Iceberg In the table commit The data will generate a corresponding snapshot , We can check “${catalog name }.${ Library name }.${Iceberg surface }.snapshots” To query the corresponding Iceberg All snapshots owned in the table , The operation is as follows :
// To watch hadoop_prod.mydb.mytest Insert the following data again
spark.sql(
"""
|insert into hadoop_prod.mydb.mytest values (4,"ml",18),(5,"tq",19),(6,"gb",20)
""".stripMargin)
//3. see Iceberg Table snapshot information
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.snapshots
""".stripMargin).show(false)give the result as follows :

3、 ... and 、 Query table history
Yes Iceberg Table query table history is query Iceberg Table snapshot information content , Similar to query table snapshot , adopt “${catalog name }.${ Library name }.${Iceberg surface }.history” Command to query , The operation is as follows :
//4. Query table history , In fact, it is part of the table snapshot
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.history
""".stripMargin).show(false)give the result as follows :

Four 、 Query table data files
We can go through ”${catalog name }.${ Library name }.${Iceberg surface }.files” Order to inquire Iceberg Table corresponding to the data files Information , The operation is as follows :
//5. View the corresponding table data files
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.files
""".stripMargin).show(false)give the result as follows :

5、 ... and 、 Inquire about Manifests
We can go through “${catalog name }.${ Library name }.${Iceberg surface }.manifests” To query the corresponding manifests Information , The specific operation is as follows :
//6. View the corresponding table Manifests
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest.manifests
""".stripMargin).show(false)give the result as follows :

6、 ... and 、 Query the specified snapshot data
Inquire about Iceberg Table data can also be specified snapshot-id To query the data of the specified snapshot , This way you can use DataFrame Api How to query ,Spark3.x After version, you can also pass SQL How to query , The operation is as follows :
//7. Query the specified snapshot data , snapshot ID Can be read through json Metadata file acquisition
spark.read
.option("snapshot-id",3368002881426159310L)
.format("iceberg")
.load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
.show()give the result as follows :

Spark3.x After the version ,SQL Specify the snapshot syntax as :
CALL ${Catalog name }.system.set_current_snapshot("${ Library name . Table name }", snapshot ID)
The operation is as follows :
//SQL Specify the query snapshot ID data
spark.sql(
"""
|call hadoop_prod.system.set_current_snapshot('mydb.mytest',3368002881426159310)
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show()give the result as follows :

7、 ... and 、 Query data according to timestamp
Spark Read Iceberg Table can specify “as-of-timestamp” Parameters , Query by specifying a millisecond time parameter Iceberg The data in the table ,iceberg Will find out according to metadata timestamp-ms <= as-of-timestamp Corresponding snapshot-id , Only through DataFrame Api Look up the data ,Spark3.x Support for SQL Specify timestamp query data . The specific operation is as follows :
//8. Query data according to timestamp , The timestamp is specified in milliseconds ,iceberg Will find out according to metadata timestamp-ms <= as-of-timestamp Corresponding snapshot-id , Look up the data
spark.read.option("as-of-timestamp","1640066148000")
.format("iceberg")
.load("hdfs://mycluster/sparkoperateiceberg/mydb/mytest")
.show()give the result as follows :

Spark3.x After the version ,SQL The syntax of querying the latest snapshot according to the timestamp is :
CALL ${Catalog name }.system.rollback_to_timestamp("${ Library name . Table name }",TIMESTAMP ' Date data ')
The operation is as follows :
// Omit recreating the table mytest, Insert data twice
//SQL Method query specifies Time stamp Snapshot data
spark.sql(
"""
|CALL hadoop_prod.system.rollback_to_timestamp('mydb.mytest', TIMESTAMP '2021-12-23 16:56:40.000')
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show()give the result as follows :

8、 ... and 、 Rollback snapshot
stay Iceberg You can rollback snapshots , With the aid of Java Code implementation ,Spark DataFrame Api Cannot rollback snapshot , stay Spark3.x After the version , Support SQL Rollback snapshot . After rolling back the snapshot ,Iceberg A new... Will be generated in the corresponding table Snapshot-id, Reexamine , Rollback takes effect , The specific operation is as follows :
//9. Rollback to a snapshot ,rollbackTo(snapshot-id), What is specified is a fixed snapshot ID, After rollback , Will create a new Snapshot-id, Re query takes effect .
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
catalog.setConf(conf)
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
table.manageSnapshots().rollbackTo(3368002881426159310L).commit()Be careful : After rolling back the snapshot , In the corresponding Iceberg A new... Will be generated in the table Snapshot-id, After querying again , You will see that the data is the data after rolling back the snapshot .
// Query table hadoop_prod.mydb.mytest data , It is already historical data
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show(100)give the result as follows :

Spark3.x After the version ,SQL Rollback snapshot syntax is :
CALL ${Catalog name }.system.rollback_to_snapshot("${ Library name . Table name }", snapshot ID)
The operation is as follows :
// Omit recreating the table mytest, Insert data twice
//SQL Method rollback snapshot ID, The operation is as follows :
spark.sql(
"""
|Call hadoop_prod.system.rollback_to_snapshot("mydb.mytest",5440886662709904549)
""".stripMargin)
// Query table hadoop_prod.mydb.mytest data , It is already historical data
spark.sql(
"""
|select * from hadoop_prod.mydb.mytest
""".stripMargin).show(100)give the result as follows :

Nine 、 Merge Iceberg Data files for tables
in the light of Iceberg Table every time commit Will generate a parquet Data files , Maybe one Iceberg There are many data files corresponding to the table , So we go through Java Api Way to Iceberg Tables can be merged into data files , After data files are merged , Will create a new Snapshot And the original data will not be deleted , If you want to delete the corresponding data file, you need to go through “Expire Snapshots To achieve ”, The specific operation is as follows :
//10. Merge Iceberg Data files for tables
// 1) First, to the table mytest Insert a batch of data , Write data to table mytest in
import spark.implicits._
val df: DataFrame = spark.read.textFile("D:\\2018IDEA_space\\Iceberg-Spark-Flink\\SparkIcebergOperate\\data\\nameinfo")
.map(line => {
val arr: Array[String] = line.split(",")
(arr(0).toInt, arr(1), arr(2).toInt)
}).toDF("id","name","age")
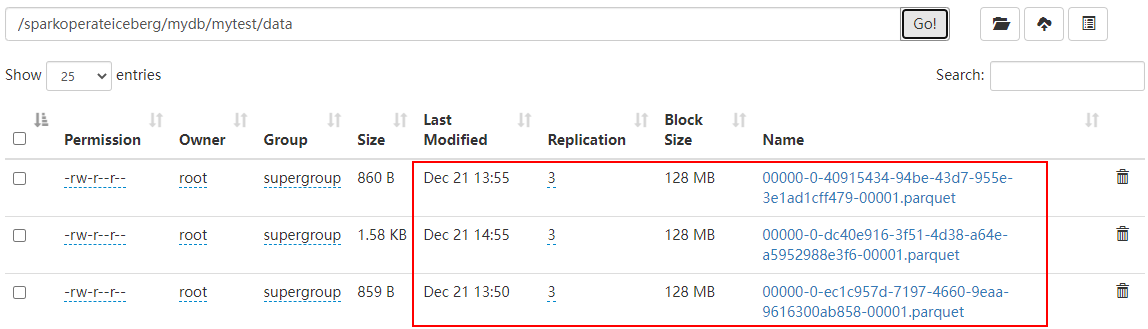
df.writeTo("hadoop_prod.mydb.mytest").append()After inserting data above , We can see Iceberg The table metadata directory is as follows :
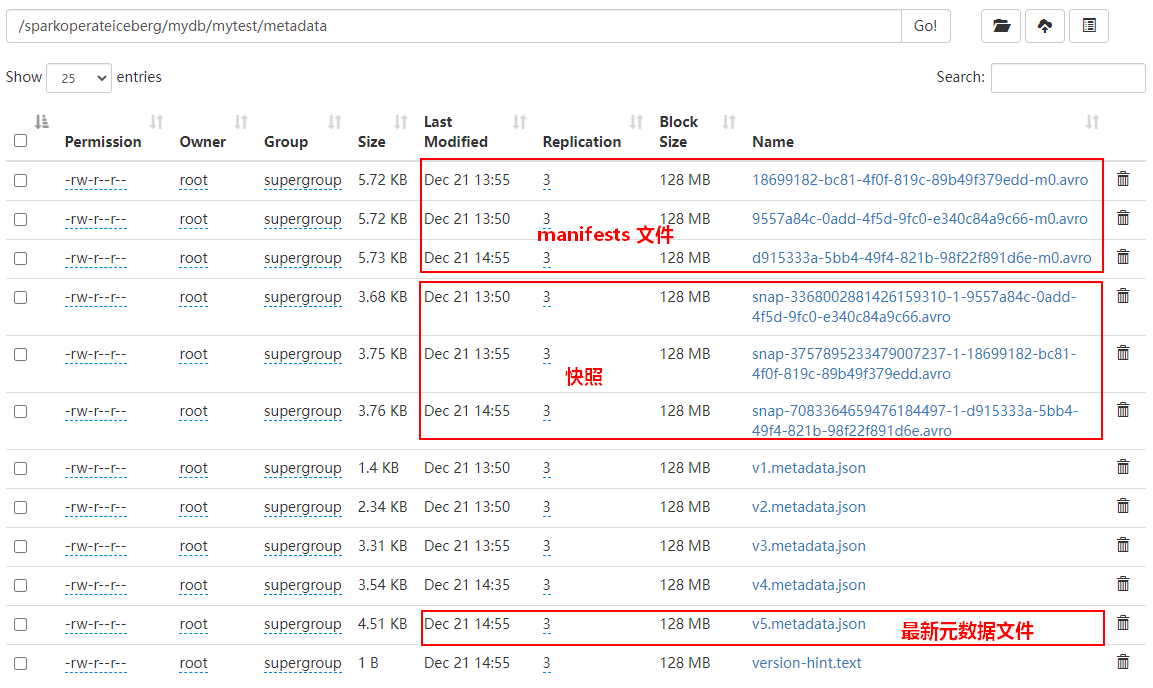
The data directory is as follows :
//2) Merge small file data ,Iceberg Merging small files does not delete the merged files ,Compact Is to merge small files into large files and create new Snapshot. If you want to delete a file, you need to go through Expire Snapshots To achieve ,targetSizeInBytes Specify the size of each file after merging
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
Actions.forTable(table).rewriteDataFiles().targetSizeInBytes(1024)//1kb, Specify the file size after the merge
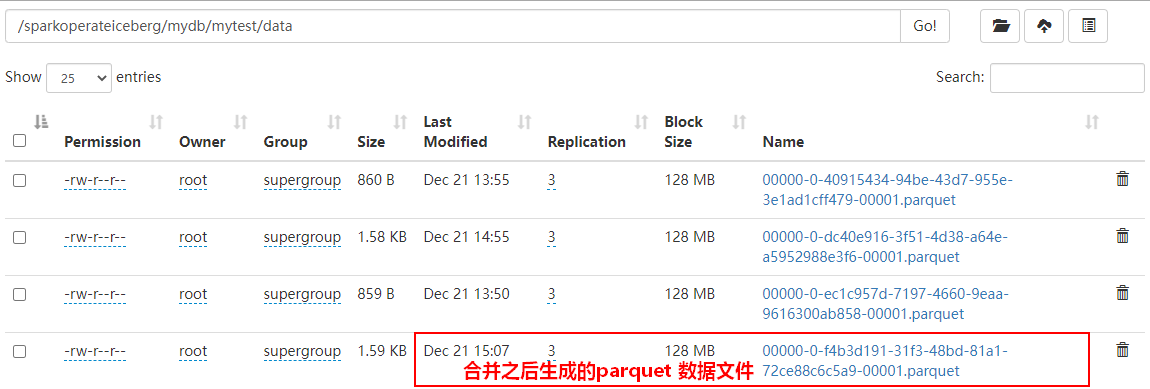
.execute()After merging small files ,Iceberg The metadata directory of the corresponding table is as follows :
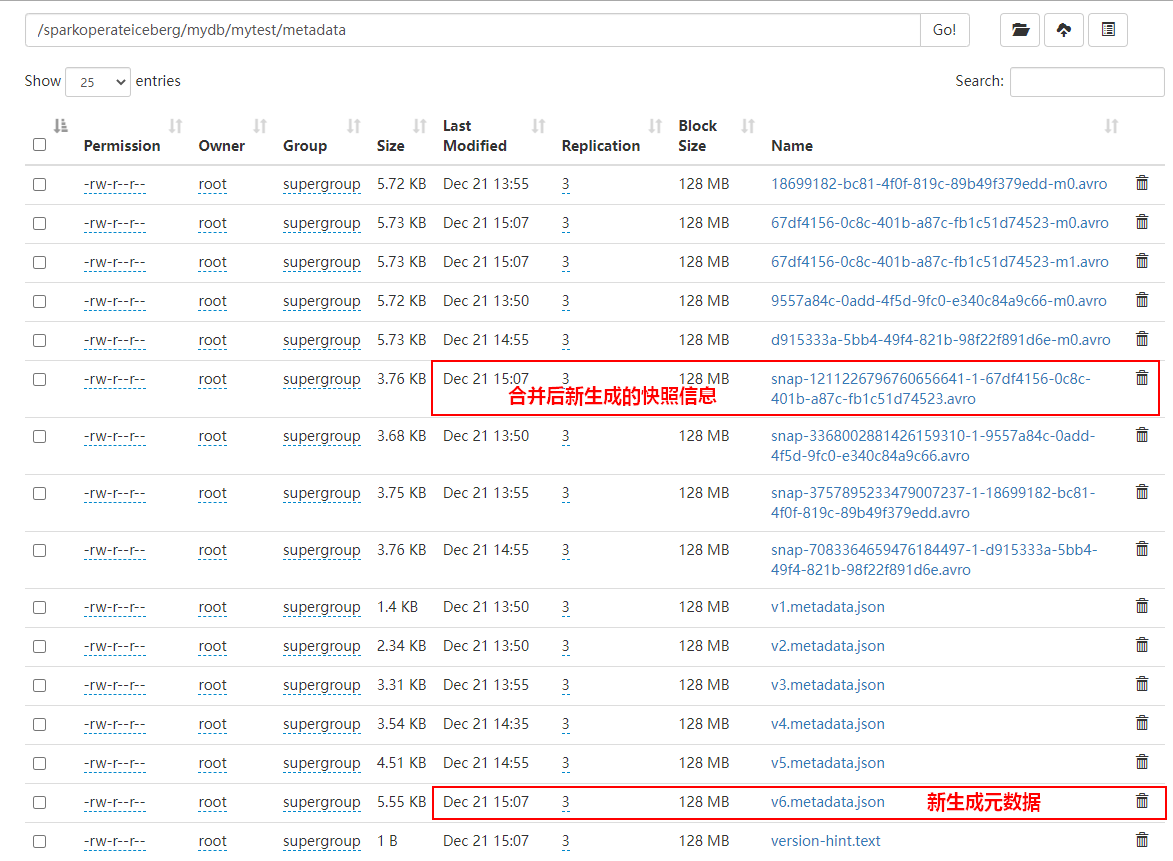
The data directory is as follows :
Ten 、 Delete historical snapshot
At present, we can pass the Java Api Delete historical snapshot , You can specify a timestamp , All snapshots before the current timestamp will be deleted ( If the specified time is greater than the last snapshot time , The latest snapshot data will be retained ), You can view the latest metadata json File to find the time to specify . for example , surface mytest Abreast of the times json The metadata file information is as follows :
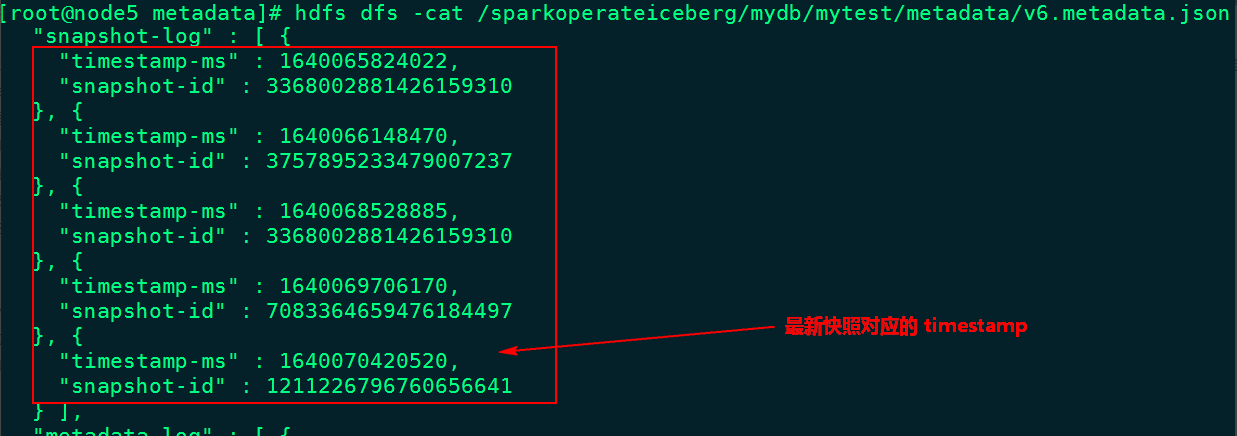
The deletion time here is “1640070000000” All previous snapshot information , When deleting a snapshot , data data Expired data in the directory parquet Files will also be deleted ( for example : Files that are no longer needed after snapshot rollback ), The code operation is as follows :
//11. Delete historical snapshot , Historical snapshot is through ExpireSnapshot To achieve , Set how long historical snapshots need to be deleted
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/sparkoperateiceberg")
val table: Table = catalog.loadTable(TableIdentifier.of("mydb","mytest"))
table.expireSnapshots().expireOlderThan(1640070000000L).commit()After the above code is executed , You can see that only the last snapshot information is left :
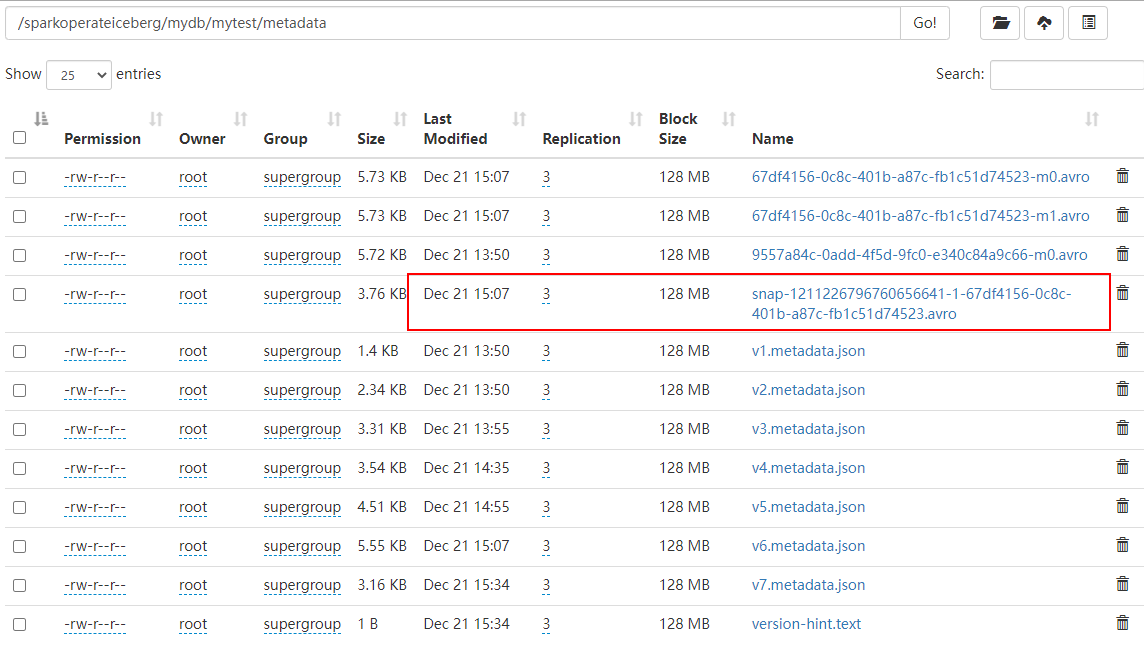
The data directory is as follows :
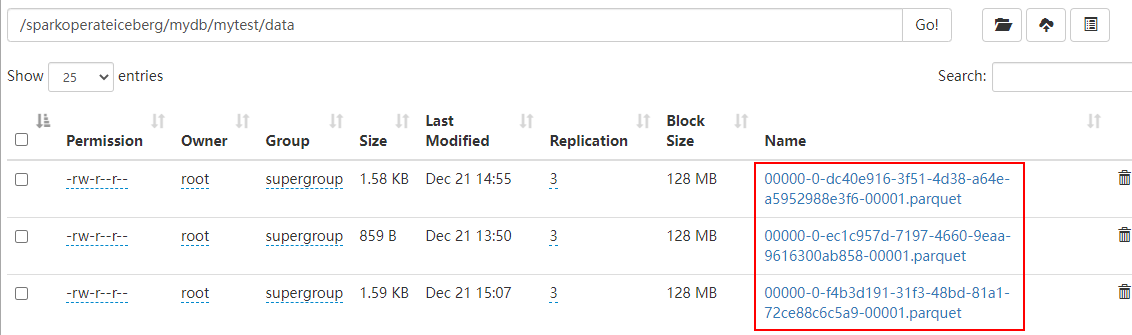
Be careful : When deleting the corresponding snapshot data ,Iceberg Table corresponding to the Parquet Format data will also be deleted , What exactly parquet The deletion of file data depends on the last “snap-xx.avro” Corresponding manifest list Data corresponds to parquet data , As shown in the figure below :

With constant deletion snapshot, stay Iceberg The table no longer has manifest File corresponding parquet Files will also be deleted .
In addition to the above use Java Api Method to delete the old snapshot of the table , stay Spark3.x After the version , We can also use SQL Method to delete the snapshot method ,SQL Delete snapshot syntax is :
Delete snapshots older than a certain time , But keep it recent N A snapshot
CALL ${Catalog name }.system.expire_snapshots("${ Library name . Table name }",TIMESTAMP ' year - month - Japan when - branch - second .000',N)
Be careful : Above use SQL Mode when operating in the above way ,SparkSQL The execution will get stuck , Finally, error broadcasting variable broadcasting problem ( There is no good solution , Visual inspection is a bug problem )
Every time Commit Generate corresponding Snapshot outside , There will also be a metadata file “Vx-metadata.json” Document generation , We can create Iceberg Table when executing the corresponding attribute decision Iceberg The table retains several metadata files , Properties are as follows :
Property | Description |
write.metadata.delete-after-commit.enabled | Whether to delete the old metadata file after each table submission |
write.metadata.previous-version-max | Keep the number of old metadata files |
for example , stay Spark Create a table test , Specify the above two properties , Build the predicative sentence as follows :
CREATE TABLE ${CataLog name }.${ Library name }.${ Table name } (
id bigint,
name string
) using iceberg
PARTITIONED BY (
loc string
) TBLPROPERTIES (
'write.metadata.delete-after-commit.enabled'= true,
'write.metadata.previous-version-max' = 3
)- Blog home page :https://lansonli.blog.csdn.net
- Welcome to thumb up Collection Leaving a message. Please correct any mistakes !
- This paper is written by Lansonli original , First appeared in CSDN Blog
- When you stop to rest, don't forget that others are still running , I hope you will seize the time to learn , Go all out for a better life
边栏推荐
- 单商户 V4.4,初心未变,实力依旧!
- 程序员如何提升自己的格局?
- Verilog realizes the calculation of the maximum common divisor and the minimum common multiple
- Exception com alibaba. fastjson. JSONException: not match : - =
- Data communication foundation - dynamic routing protocol rip
- 21. [STM32] I don't understand the I2C protocol. Dig deep into the sequence diagram to help you write the underlying driver
- 示例项目:简单的六足步行者
- 六种常用事务解决方案,你方唱罢,我登场(没有最好只有更好)
- MySQL giant pit: update updates should be judged with caution by affecting the number of rows!!!
- Noi / 1.4 07: collect bottle caps to win awards
猜你喜欢

D-snow halo solution

示例项目:简单的六足步行者

vlunhub- BoredHackerBlog Social Network

F. Min cost string problem solving Report

vulnhub-Root_ this_ box
![18.[STM32]读取DS18B20温度传感器的ROM并实现多点测量温度](/img/e7/4f682814ae899917c8ee981c05edb8.jpg)
18.[STM32]读取DS18B20温度传感器的ROM并实现多点测量温度

Arduino控制微小的六足3D打印机器人
Mistakes made when writing unit tests
Data communication foundation - Ethernet port mirroring and link aggregation
Data communication foundation - dynamic routing protocol rip
随机推荐
abstract关键字和哪些关键字会发生冲突呢
六种常用事务解决方案,你方唱罢,我登场(没有最好只有更好)
10分钟帮你搞定Zabbix监控平台告警推送到钉钉群
事务回滚异常
Appium automation test foundation - appium basic operation API (I)
vulnhub-Root_ this_ box
ES6 drill down - Async functions and symbol types
Data communication foundation - Ethernet port mirroring and link aggregation
obj集合转为实体集合
程序员如何提升自己的格局?
Summary of the third class
vant tabbar遮挡内容的解决方式
Parameter type setting error during batch update in project SQL
Clock switching with multiple relationship
The list set is summed up according to a certain attribute of the object, the maximum value, etc
项目中批量update
Six common transaction solutions, you sing, I come on stage (no best, only better)
【网易云信】超分辨率技术在实时音视频领域的研究与实践
【毕业季】作为一名大二计科在校生,我有话想说
MySQL table field adjustment