当前位置:网站首页>Strengthen basic learning records
Strengthen basic learning records
2022-07-06 13:53:00 【I like the strengthened Xiaobai in Curie】
DDPG Strengthen learning record
DDPG(Deep Deterministic Policy Gradient), be based on Actor-Critic frame , It is proposed to solve the problem of continuous action control . The algorithm is aimed at deterministic strategies , I.e. given state , Choose the definite action , Not like a random strategy , Take a sample .
One 、 Introduction to the environment
What we use here is gym Environmental ’Pendulum-v1’, Give a brief introduction , Detailed introduction with links .
link : OpenAI Gym Introduction to classic control environment ——Pendulum-v1
(1) The rules of the game : The rod rotates , Through training , Make the pole face up .
(2) The state space :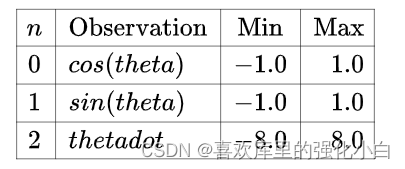
(3) Action space :
I used it here [-1,1] Action space , If you want to change to the same configuration as the environment , Only need to Actor Network implementation tanh Front ride 2, And will choose_action You can also modify it accordingly .
(4) Reward :
(5) Initial state and termination state :
Two 、 A brief introduction to the algorithm
Actor-Critic
DDPG It can be simply regarded as DQN Algorithm plus Actor-Critic frame ,DDPG Used in the algorithm AC The framework is based on the action value function Q Framework .Actor Learning strategy function ,Critic Learn the action value function Q; The learning ideas in the above figure look very convoluted , But it's easy to understand , Take an easy to understand metaphor :Actor Equivalent to an athlete ,Critic Equivalent to a referee ; Athletes Actor To do action , Athletes must want to do better and better , So as to improve their own technology , The referee graded the athletes , Athletes improve their movements according to this score , Get a higher score , So as to achieve the purpose of improving their own technology ; The referee Critic Also improve yourself , Make your scoring more and more accurate , Only in this way can athletes' skills become higher and higher ,Critic It is the reward given by the environment reward To improve yourself and improve your level .
link : DDPG Reference articleOff-Policy:
Here we use Off-Policy Thought , The idea of experience playback is adopted , Break the correlation between samples .DDPG Characteristics :
<1> Use of experience playback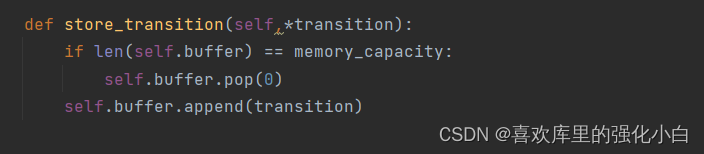
<2> Use of dual target Networks :
stay DQN in , Through to Q Network set target network and behavior network , To stabilize learning . stay DDPG in , Whether it's Actor Internet or Critic The Internet , Both have target Networks , This is also what many bloggers call the four network way .
<3> The use of soft updates :
And DQN The methods of feeding parameters directly to the target network are different , Here, the target network is updated by soft update , Make learning more stable . The target network does not carry out reverse transmission , Equivalent to a reference , Behavioral networks through training , Back propagation , To approach the target network .
<4> Exploratory :
Due to deterministic action , Make learning less exploratory , So when choosing actions , You can use greedy strategies to increase exploratory , At the same time, Gaussian noise can also be added , Increase randomness . ad locum , Just use greedy tactics .Pseudo code

Realization
The implementation refers to the online code , It's been modified , The effect is not good at first , The reward never goes up , Later, I consulted my senior brother in the Laboratory , Found some problems , Finally, the problem was solved by changing around .
The reasons may be summarized as follows :
<1> The experience pool is full batch_size It's about to be updated , It is not updated only when it is full ;
<2> The soft update must be carried out after the training of the two networks ;
<3> Too few steps per game .
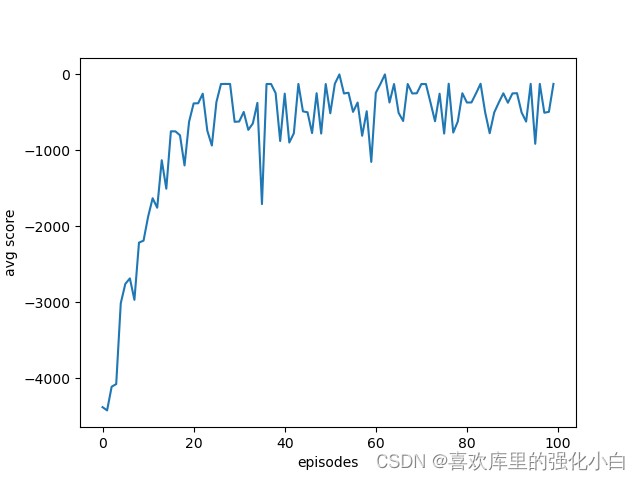
Through the curve, you can see , Reward increases , Gradually tend to 0, Because the training is too slow , It just went on 100 Sub iteration , Therefore, the best effect is not achieved .
import random
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
batch_size = 32
lr_actor = 0.001
lr_critic = 0.001
gamma = 0.90
epsilon = 0.9
episodes = 100
memory_capacity = 10000
#target_replace_iter = 100
tau = 0.02
env = gym.make('Pendulum-v1')
n_actions = env.action_space.shape[0]
n_states = env.observation_space.shape[0]
class Actor(nn.Module):
def __init__(self):
super(Actor, self).__init__()
self.fc1 = nn.Linear(n_states,256)
self.fc2 = nn.Linear(256,256)
self.out = nn.Linear(256,n_actions)
def forward(self,x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
actions = torch.tanh(self.out(x))
return actions
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.fc1 = nn.Linear(n_states + n_actions,256)
self.fc2 = nn.Linear(256,256)
self.q_out = nn.Linear(256,1)
def forward(self,state,aciton):
x = torch.cat([state,aciton],dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
q_value = self.q_out(x)
return q_value
class AC():
def __init__(self):
self.eval_actor,self.target_actor = Actor(),Actor()
self.eval_critic,self.target_critic = Critic(),Critic()
#self.learn_step_counter = 0
self.memory_counter = 0
self.buffer = []
self.target_actor.load_state_dict(self.eval_actor.state_dict())
self.target_critic.load_state_dict(self.eval_critic.state_dict())
self.actor_optim = torch.optim.Adam(self.eval_actor.parameters(),lr = lr_actor)
self.critic_optim = torch.optim.Adam(self.eval_critic.parameters(),lr = lr_critic)
def choose_action(self,state):
if np.random.uniform() > epsilon:
action = np.random.uniform(-1,1,1)
else:
inputs = torch.tensor(state, dtype=torch.float).unsqueeze(0)
action = self.eval_actor(inputs).squeeze(0)
action = action.detach().numpy()
return action
def store_transition(self,*transition):
if len(self.buffer) == memory_capacity:
self.buffer.pop(0)
self.buffer.append(transition)
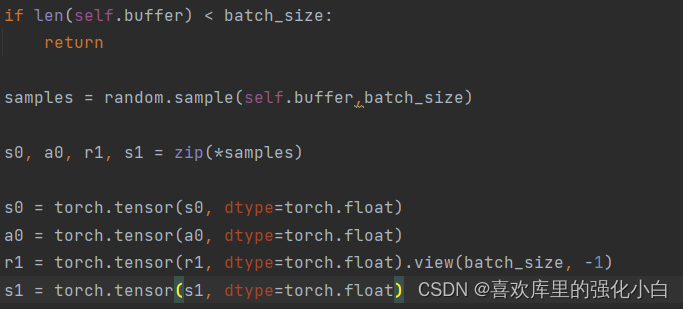
def learn(self):
if len(self.buffer) < batch_size:
return
samples = random.sample(self.buffer,batch_size)
s0, a0, r1, s1 = zip(*samples)
s0 = torch.tensor(s0, dtype=torch.float)
a0 = torch.tensor(a0, dtype=torch.float)
r1 = torch.tensor(r1, dtype=torch.float).view(batch_size, -1)
s1 = torch.tensor(s1, dtype=torch.float)
def critic_learn():
a1 = self.target_actor(s1).detach()
y_true = r1 + gamma * self.target_critic(s1, a1).detach()
y_pred = self.eval_critic(s0, a0)
loss_fn = nn.MSELoss()
loss = loss_fn(y_pred, y_true)
self.critic_optim.zero_grad()
loss.backward()
self.critic_optim.step()
def actor_learn():
loss = -torch.mean(self.eval_critic(s0, self.eval_actor(s0)))
self.actor_optim.zero_grad()
loss.backward()
self.actor_optim.step()
def soft_update(net_target, net, tau):
for target_param, param in zip(net_target.parameters(), net.parameters()):
target_param.data.copy_(target_param.data * (1.0 - tau) + param.data * tau)
critic_learn()
actor_learn()
soft_update(self.target_critic, self.eval_critic, tau)
soft_update(self.target_actor, self.eval_actor, tau)
ac = AC()
returns = []
for i in range(episodes):
s = env.reset()
episode_reward_sum = 0
for step in range(500):
# Start a episode ( Each cycle represents a step )
#env.render()
a = ac.choose_action(s)
s_, r, done, info = env.step(a)
ac.store_transition(s, a, r, s_)
episode_reward_sum += r
s = s_
ac.learn()
returns.append(episode_reward_sum)
print('episode%s---reward_sum: %s' % (i, round(episode_reward_sum, 2)))
plt.figure()
plt.plot(range(len(returns)),returns)
plt.xlabel('episodes')
plt.ylabel('avg score')
plt.savefig('./plt_ddpg.png',format= 'png')
边栏推荐
猜你喜欢


随机推荐
Beautified table style
[面试时]——我如何讲清楚TCP实现可靠传输的机制
Implementation principle of automatic capacity expansion mechanism of ArrayList
强化学习基础记录
2022泰迪杯数据挖掘挑战赛C题思路及赛后总结
Wechat applet
canvas基础2 - arc - 画弧线
A piece of music composed by buzzer (Chengdu)
使用Spacedesk实现局域网内任意设备作为电脑拓展屏
仿牛客技术博客项目常见问题及解答(三)
ABA问题遇到过吗,详细说以下,如何避免ABA问题
3. Input and output functions (printf, scanf, getchar and putchar)
Difference and understanding between detected and non detected anomalies
MySQL事务及实现原理全面总结,再也不用担心面试
【九阳神功】2017复旦大学应用统计真题+解析
[modern Chinese history] Chapter 9 test
7-9 制作门牌号3.0(PTA程序设计)
Read only error handling
7-1 输出2到n之间的全部素数(PTA程序设计)
Record a penetration of the cat shed from outside to inside. Library operation extraction flag