当前位置:网站首页>深度强化文献阅读系列(一):Courier routing and assignment for food delivery service using reinforcement learning
深度强化文献阅读系列(一):Courier routing and assignment for food delivery service using reinforcement learning
2022-07-06 09:21:00 【zhugby】
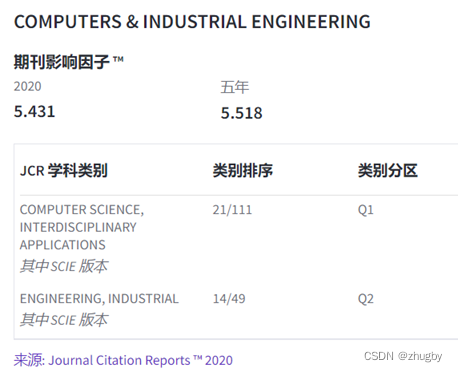
来源:文章于2022年发表于期刊COMPUTERS & INDUSTRIAL ENGINEERING ,期刊基本信息及影响因子如下图所示:
目录
摘要
使用马尔可夫决策过程表示现实世界的外卖送餐服务,将外卖配送问题表示成深度强化学习问腿。系统分配订单给外卖员,外卖员在指定餐厅提取订单配送至目的地,目标是在有限时间和有限外卖员的条件下,最大化总送餐收入。本文使用三种方法尝试解决这个问题:1.Q-learning_单agent 2.DDQN_单agent 3.DDQN_多agent,使用仿真实验将三种算法学习到的policy并与rule_based policy进行对比。结果发现,1.允许外卖员拒绝订单和空闲状态下移动能有效提高收益;2.三种方法中DDQN_单agent算法性能最好,RL_based的方法均优于rule_based Policy。
1.研究贡献
- 与最短化路路径VRP问题不同,本文通过减少交付时间来最大化总的期望回报;与传统的货物交付问题不同,事先不知道订单信息,订单随机生成;
- 问题中外卖员空闲状态时可以选择留在原地或者前往餐馆,有望缩短下一个订单的交货时间;允许外卖员拒绝配送分配的订单,有望系统的总收益;
- 尝试使用机器学习的方法解决外卖员配送路径问题,有利于未来扩展到其他问题的研究上;
- 针对大规模问题,简化Q-learning算法利用单agent训练能够显著加快训练速度并得到更好的结果。
2.文献综述
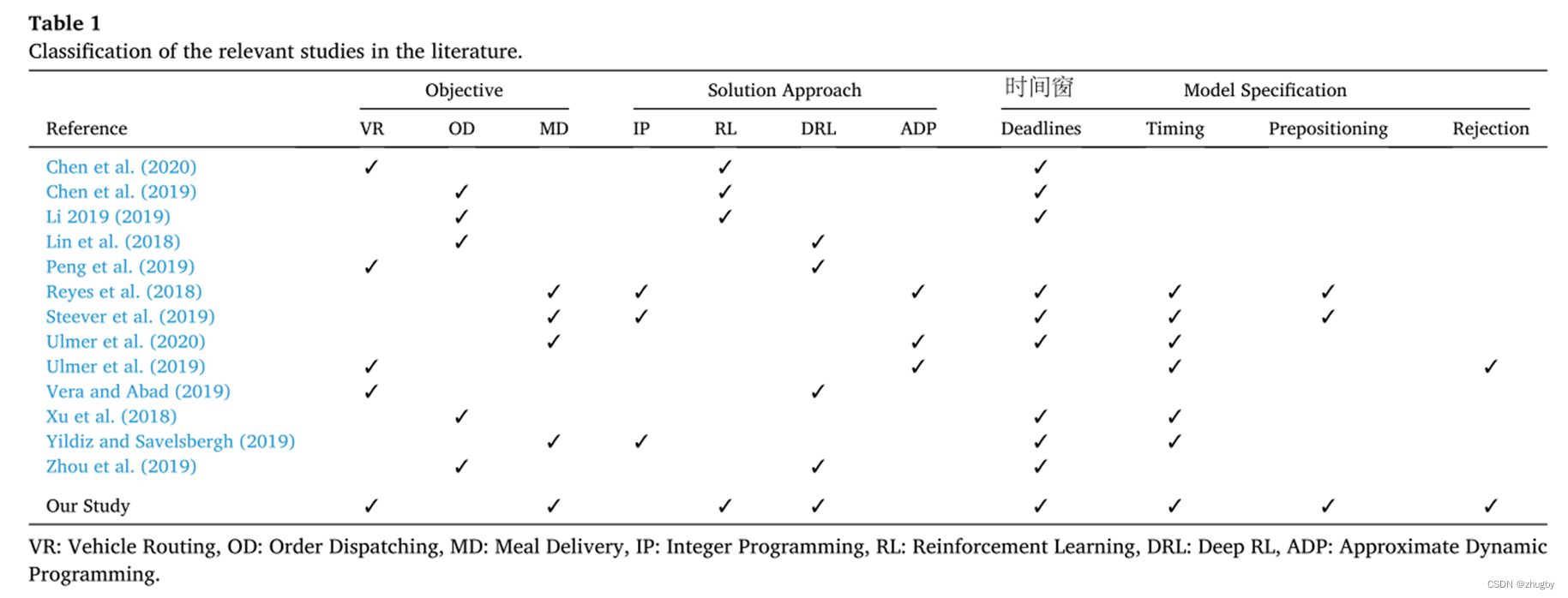
现有文献中解决食品配送问题常用方法是线性规划和近似动态规划(ADP),RL算法使用的很少,本文中同时使用强化学习和深度强化的方法并对比不同方法的性能;拒绝订单和与预位性(预测下一个订单生成位置,外卖员空闲时移动到该餐厅)在文献中考虑的极少,本文同时考虑四个属性,完善模型。
3.问题描述
3.1 问题描述
N个外卖员从餐馆取餐通过 m*m的网格地图送给客户,目标是找到一个使得外卖员总收益最大的的行动policy指导外卖员的决策行为。
3.2 问题假设/前提条件
订单是环境的一部分,根据最小化sum(外卖员与订单之间的距离)原则将订单分配给外卖员
订单分配给外卖员之后外卖员可以拒绝配送订单
被拒绝的订单返回订单列表重新分配给其他外卖员
如果订单在一定时间内被所有分配的外卖员拒绝,订单离开系统不再配送。
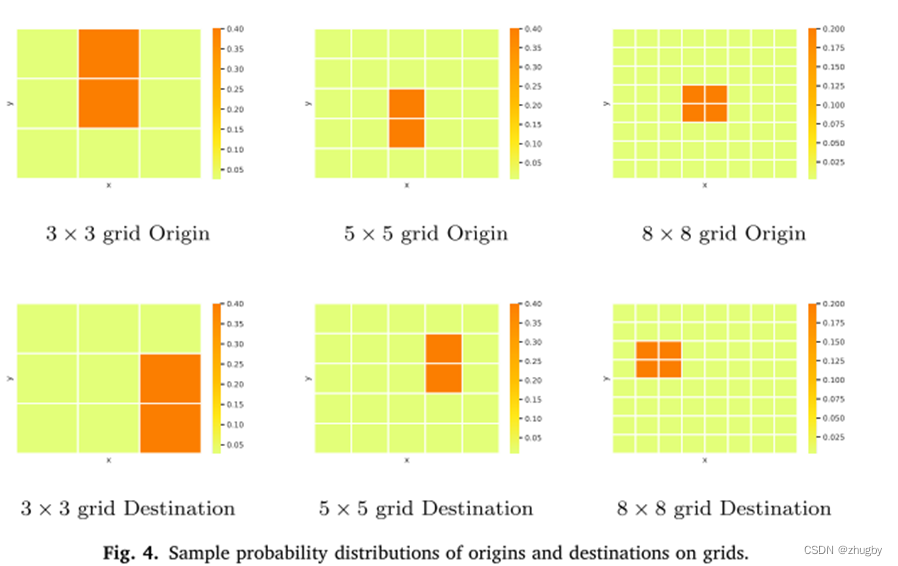
地图上每个网格成为订单起点(餐馆)和目的地(客户点)的概率不同,(1)餐馆大多集中分布在某个区域(2)订单数量多的目的地倾向于集中在某个区域(大学)
3.3 问题定义
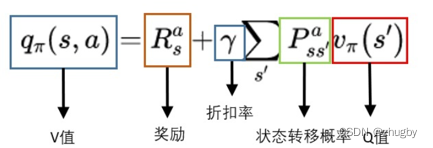
要使用RL的方法解决外卖员配送路径问题,就需要将该问题转化为RL问题,定义RL的各要素:
State
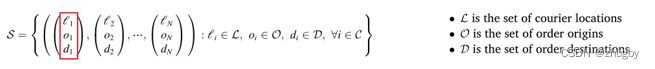

针对 ,每个三元组记录了第i个外卖员当前位置,外卖员i配送的订单的起点(餐馆),以及订单的目的地。、
,每个三元组记录了第i个外卖员当前位置,外卖员i配送的订单的起点(餐馆),以及订单的目的地。、
状态空间的大小:
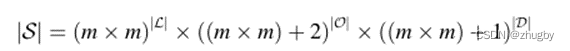
订单起点空间+2:订单起点位置除了属于m*m个网格点位置空间外,新增了两个状态:1)取餐/送餐的路上;2)空闲无订单状态
订单目的地空间+1:订单起点位置除了属于m*m个网格点位置空间外,新增了一个状态,外卖员处于空闲无订单配送状态无目的地。
此外,外卖订单包括五个属性:订单起点、订单目的地、订单持续时间、被拒次数、配送该订单外卖员ID
Actions
针对每个外卖员,动作可选
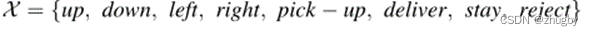
Rewards <state,action>--reward
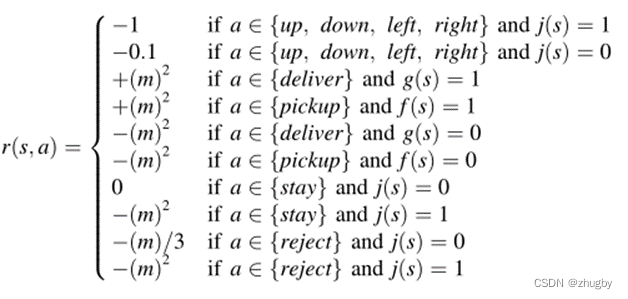

外卖员在接受订单之后每移动一步的reward是-1,空闲状态移动一步-0.1;每次成功提取和交付订单得到正的reward为m2;没有成功提取和交付订单(提错货、送错货)得到负的reward/penalty为-m2;原地空闲等待无reward;分配订单选择原地等待不移动得到负的reward/penalty为-m2;订单一经分配就拒绝-m/3; 在配送订单过程中拒绝该订单得到负的reward/penalty为-m2;
除此之外,如果订单在服务时间内未被有效分配给外卖员离开系统,额外增加惩罚。现实生活中,每个客户通常都有耐心等级,如果他/她没有在一定的时间内得到服务,他/她就会离开系统。
4.解决方法
4.1 强化学习基本框架
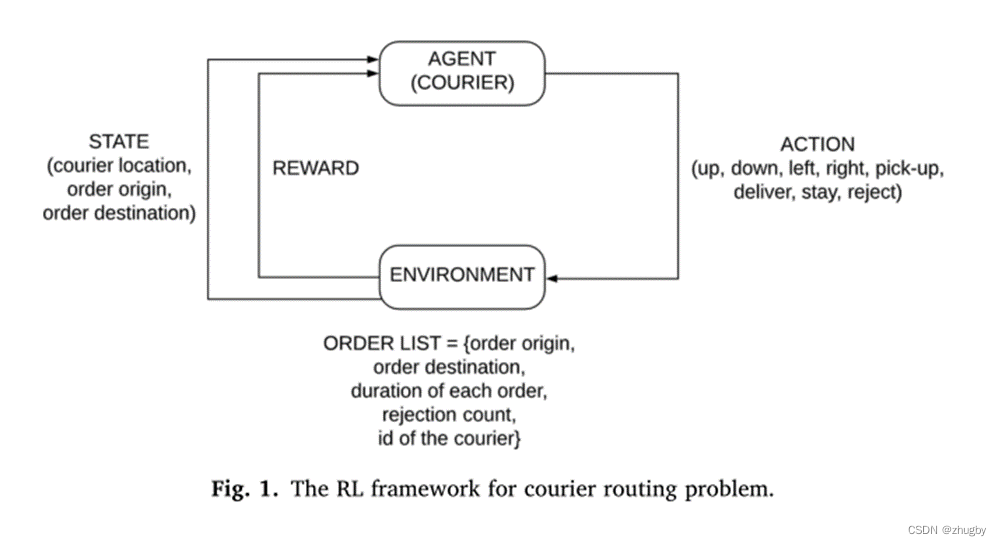
强化学习是agent在与环境的互动过程中为了达成一个目标而进行的学习过程。agent观察环境environment变化根据当前自己所处的state做出action每做出一个action,environment都会发生变化,agent会得到一个新的state,然后选择新的action不断执行下去。
4.2 Q-learning

Q-learning算法的详细介绍可见blog强化学习系列(二):Q learning算法简介及python实现Q learning求解TSP问题
Q-learning算法缺点:只适用于小规模问题,大规模问题Q表存在状态爆炸的灾难;
Trick:简化问题,同质化外卖员,Q-Learning只训练一个agent/外卖员的行动选择策略,应用到全部外卖员上;即Q-learning单agent。
4.3 DDQN
为弥补Q-learning算法的缺点,用两个深度神经网络代替Q表,神经网络输入state值,输出对应动作action的Q值。
两个网络分为在线预测网络Eval Network得到Q的预测值和目标网络得到Q的真实值。
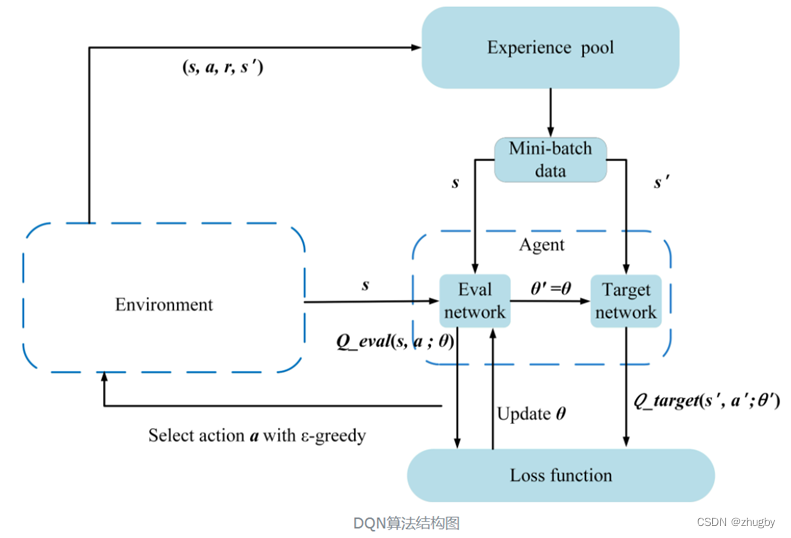
借鉴,算法流程大概总结如下:
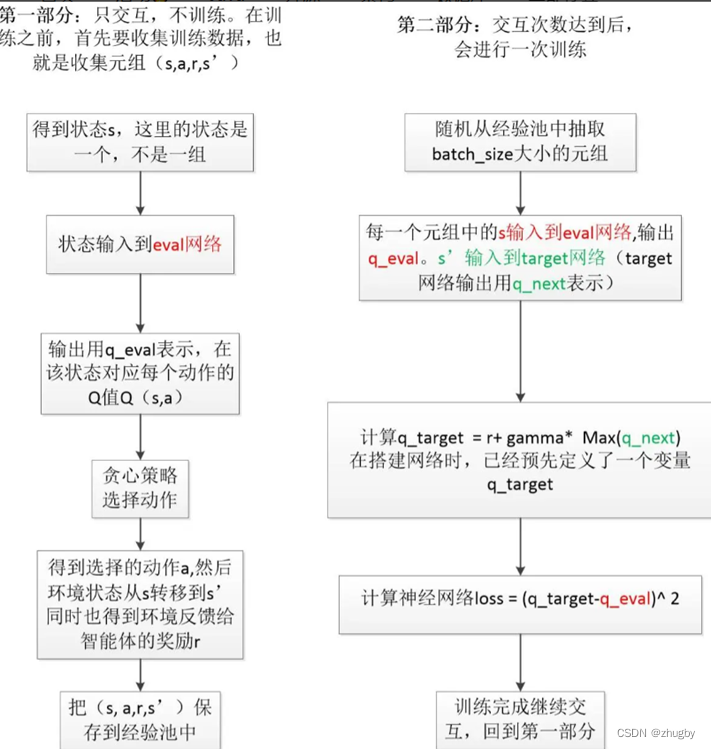
使用随机梯度下降算法更新网络参数,可能会带来的问题是,当梯度太大的话,网络参数变动太大,网络很不稳定;因此,本文采取了梯度裁剪策略,将梯度向量归一化到0-1之间,使得DDQN模型更加稳定。
4.4 Rule Based algorithm
用于对比评价RL算法的性能。 外卖员根据最短路径的原则移动提取和配送货物,没有分配任务时候选择原地等待,不允许拒绝订单,为了算法对比时重点分析强调有无stay、reject动作的影响。
5.仿真评估
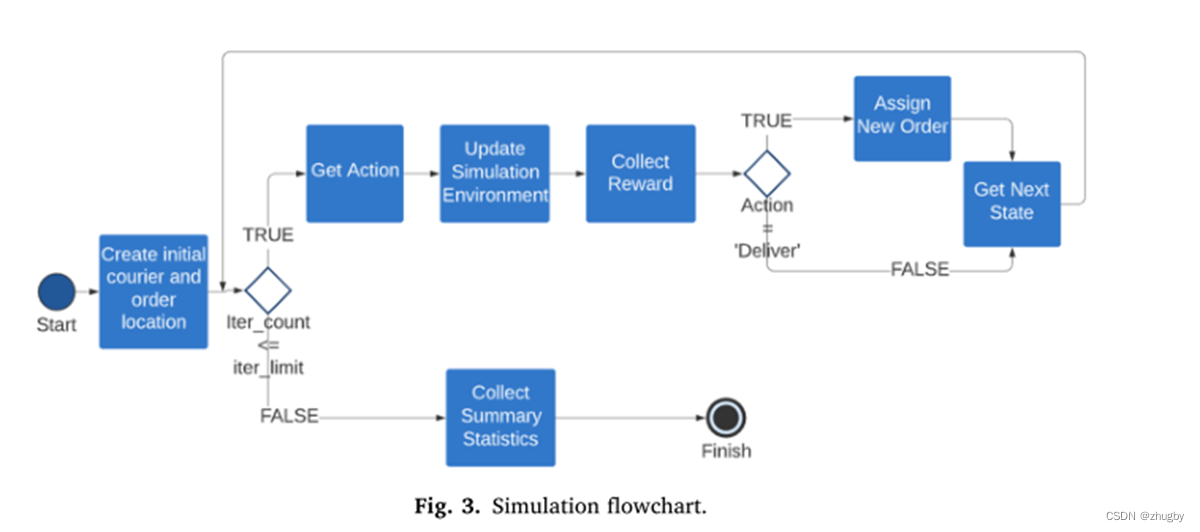
按照仿真流程图进行仿真实验:
•生成初始外卖员位置和订单位置(state)
•外卖员根据Policy选择action移动
•更新环境变化【订单list及所有订单的服务时间】
•计算reward
•该订单一旦交付,派发新的订单
•达到迭代次数后,收集数据(派送订单数、reward总和) 衡量算法性能好坏的标准
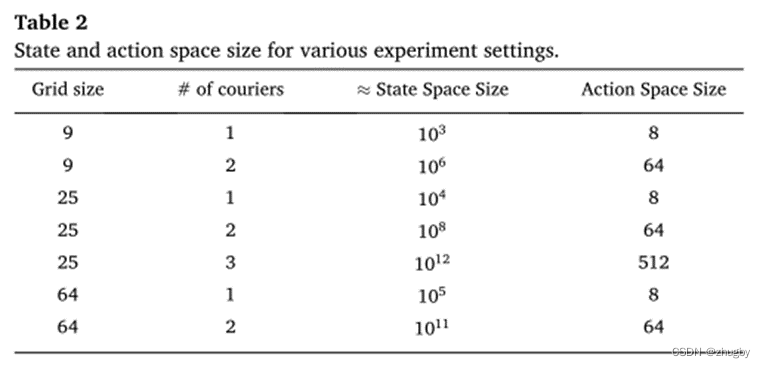
问题规模
不同问题规模(网格大小、外卖员数量、状态空间和动作空间大小)下进行实验
餐馆及订单目的地分布热力图
6.实验结果
三种方法对比:
1.Q-learning :训练单agent的Policy,将应用到所有外卖员;
2.DDQN:训练单agent的Policy,应用到所有外卖员;
3.DDQN:直接训练多agent的Policy;
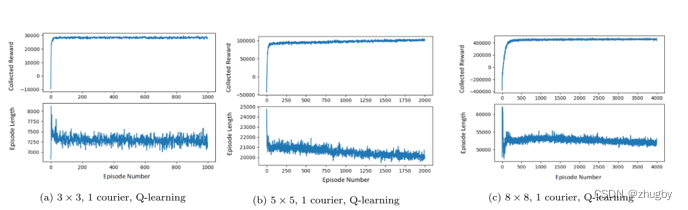
6.1 Q-learning单agent
针对Q-learning单agent,随着状态空间/问题规模的增大,算法收敛速度会逐渐变慢。
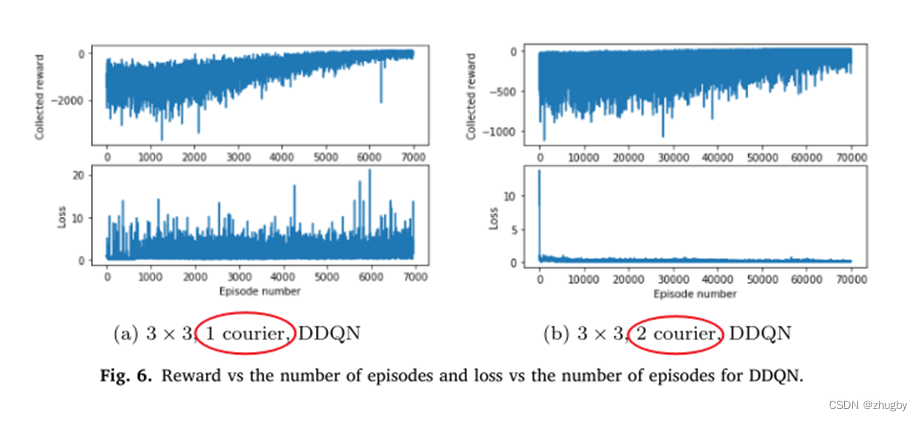
6.2 DDQN单agent vs DDQN
单agent的reward值收敛速度更快
6.3 平均收获报酬对比结果
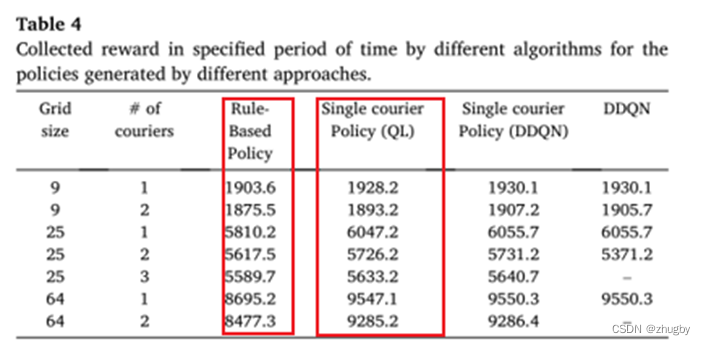
1)DDQN_单agent>QL>Rule based learning
2)DDQN_多agent在大规模问题上训练太耗时
6.4 平均交付订单数对比结果
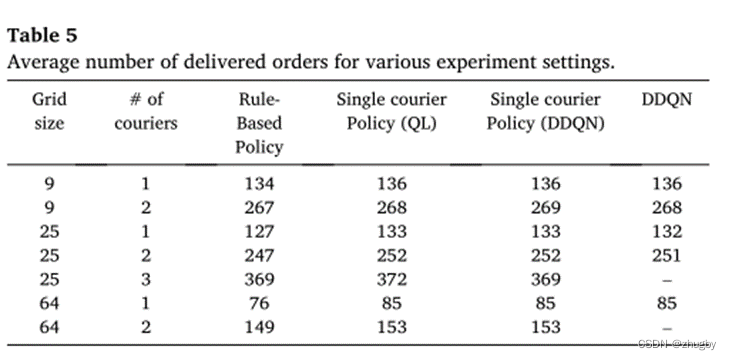
几种方法平均交付订单数对比差别不大
6.5 可视化展示
场景一:外卖员空闲一段时间后接到订单
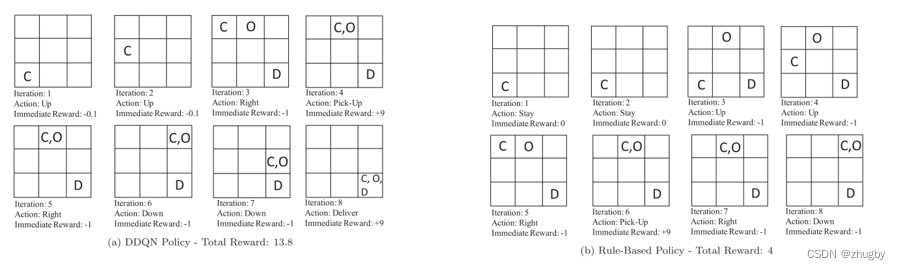
图a使用DDQN允许外卖员空闲时候移动,与使用规则的对比,可以看出,空闲时候允许外卖员移动的惩罚更小,得到的奖励越高,且迭代次数更少/时间更短到达目的地。
场景二:允许外卖员拒绝订单
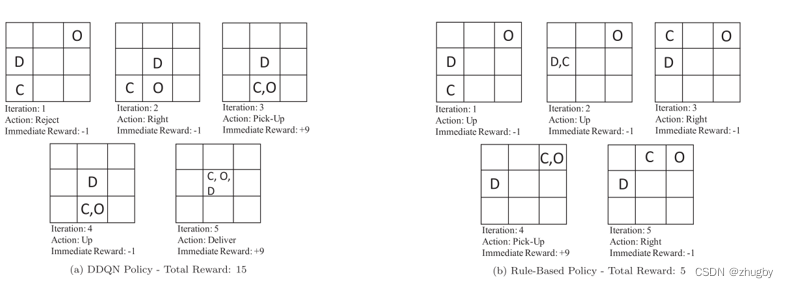
图a的DDQN,外卖员拒绝距离自己很远的订单,等候新的更近的订单,与传统的不允许拒绝的rule相比,Reward值更大,迭代次数更少/时间更短到达目的地。
7.不足与展望
状态空间只考虑订单和外卖员位置信息,可以加入外卖员工作时间、订单准备时间等等属性改进模型
本文考虑的外卖员数量太少,每增加一个外卖员,状态空间呈指数式增长;可以对外卖员和订单的属性特征进行聚合降维,缩减状态空间
边栏推荐
- Mortal immortal cultivation pointer-2
- Wei Pai: the product is applauded, but why is the sales volume still frustrated
- 【九阳神功】2021复旦大学应用统计真题+解析
- [modern Chinese history] Chapter V test
- 6. Function recursion
- 4.二分查找
- MySQL Database Constraints
- The overseas sales of Xiaomi mobile phones are nearly 140million, which may explain why Xiaomi ov doesn't need Hongmeng
- string
- 3.输入和输出函数(printf、scanf、getchar和putchar)
猜你喜欢







随机推荐
【手撕代码】单例模式及生产者/消费者模式
7. Relationship between array, pointer and array
13 power map
PriorityQueue (large root heap / small root heap /topk problem)
Floating point comparison, CMP, tabulation ideas
[面試時]——我如何講清楚TCP實現可靠傳輸的機制
[modern Chinese history] Chapter 9 test
Zatan 0516
3. C language uses algebraic cofactor to calculate determinant
(ultra detailed onenet TCP protocol access) arduino+esp8266-01s access to the Internet of things platform, upload real-time data collection /tcp transparent transmission (and how to obtain and write L
FAQs and answers to the imitation Niuke technology blog project (II)
[modern Chinese history] Chapter 6 test
5.MSDN的下载和使用
5. Download and use of MSDN
Thoroughly understand LRU algorithm - explain 146 questions in detail and eliminate LRU cache in redis
3.输入和输出函数(printf、scanf、getchar和putchar)
The latest tank battle 2022 full development notes-1
仿牛客技术博客项目常见问题及解答(三)
View UI Plus 发布 1.1.0 版本,支持 SSR、支持 Nuxt、增加 TS 声明文件
Miscellaneous talk on May 14